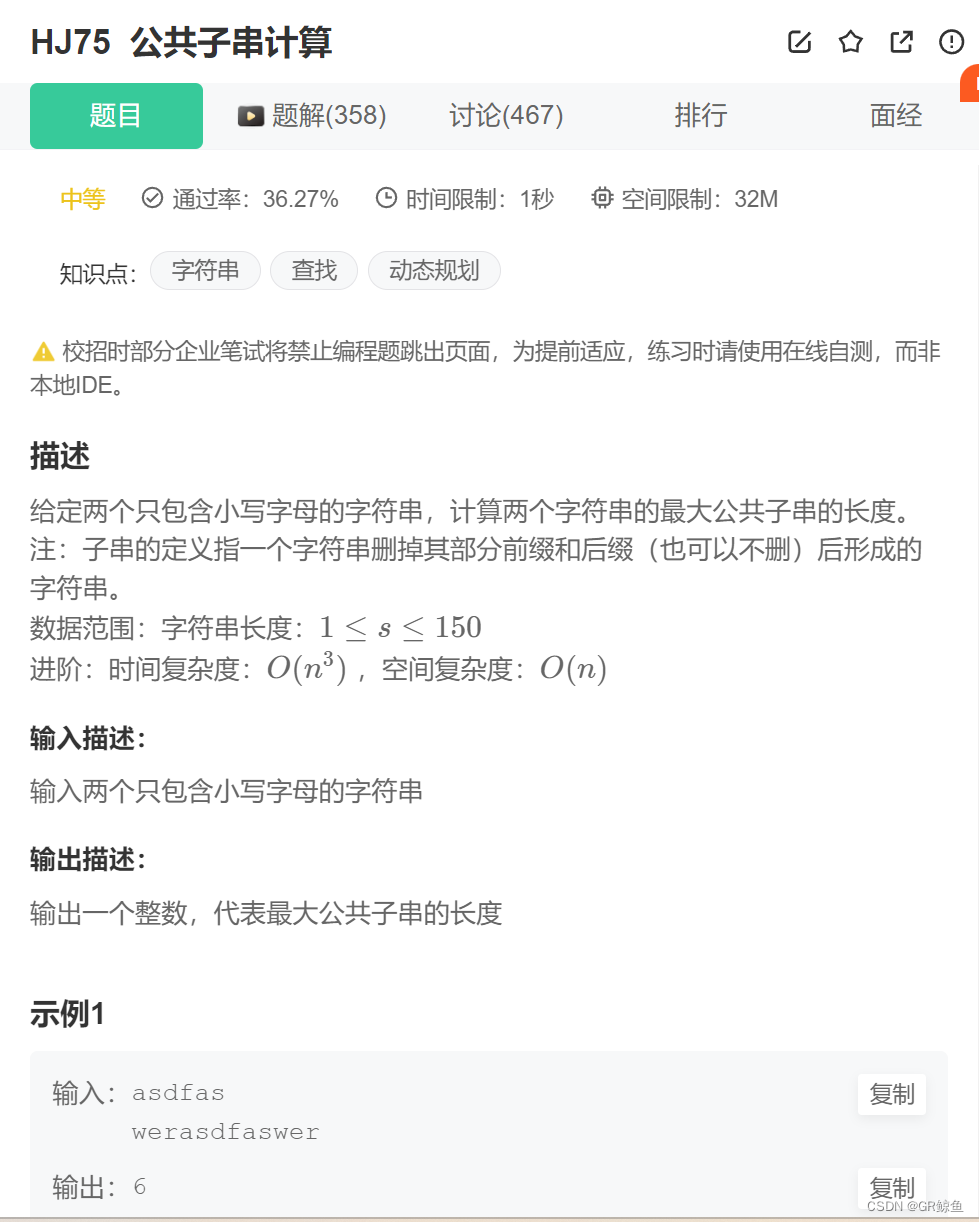
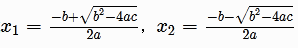欢迎来到MindGraph,这是一个概念验证、开源的、以API为先的基于图形的项目,旨在通过自然语言的交互(输入和输出)来构建和定制CRM解决方案。该原型旨在便于集成和扩展。以下是关于X的公告,提供更多背景信息。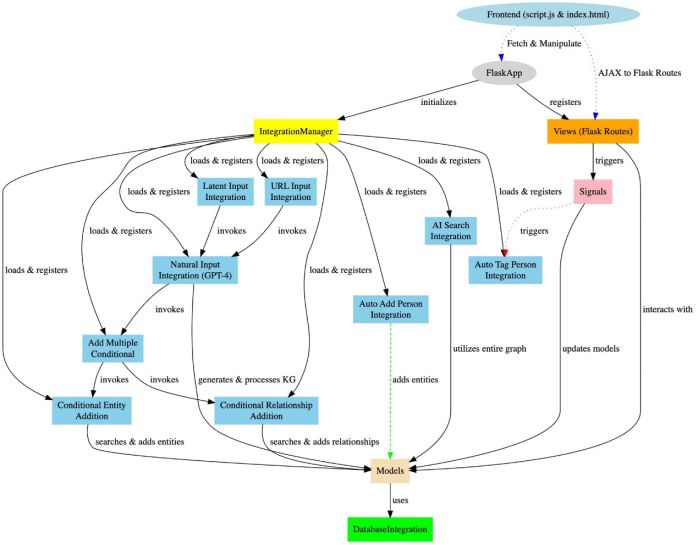 开始之前,请确保已安装以下内容:
开始之前,请确保已安装以下内容:
- Python 3.6或更高版本
- Flask,可通过pip安装:
pip install Flask
运行应用程序
克隆存储库后,请导航到根目录,并使用以下命令启动Flask服务器:python main.py服务器将在http://0.0.0.0:81 上启动。
项目结构
- MindGraph分为几个关键组件:
- main.py:应用程序的入口点。
- app/init.py:设置Flask应用程序并集成蓝图。
- models.py:管理内存中的图形数据结构,用于实体和关系。
- views.py:托管API路由的定义。
- integration_manager.py:处理集成函数的动态注册和管理。
- signals.py:设置用于创建、更新和删除实体的信号。
集成系统
MindGraph采用了一个复杂的集成系统,旨在动态扩展应用程序的基本功能。这个系统的核心是integration_manager.py,它充当各种集成函数的注册表和执行器。这种模块化架构使MindGraph能够无缝地整合AI驱动的功能,例如通过natural_input.py等集成将自然语言输入处理成结构化的知识图谱。进一步的集成,包括add_multiple_conditional、conditional_entity_addition和conditional_relationship_addition,协同工作,以确保应用程序数据模型的完整性和增强。
特性
实体管理:实体存储在内存图中,以便快速访问和操作,允许对人员、组织及其相互关系进行CRUD操作。集成触发器:可以通过HTTP请求触发自定义集成函数,从而使CRM能够与外部系统交互或运行其他处理。搜索功能:可以使用自定义查询参数轻松搜索实体及其关系。AI准备:设计时考虑了AI集成,便于整合智能数据处理和决策。
API端点
MindGraph提供一系列RESTful端点:POST /<entity_type>:创建一个实体。GET /<entity_type>/int:entity_id:检索一个实体。GET /<entity_type>:列出某类型的所有实体。PUT /<entity_type>/int:entity_id:更新一个实体。DELETE /<entity_type>/int:entity_id:删除一个实体。POST /relationship:建立一个新的关系。GET /search/entities/<entity_type>:搜索实体。GET /search/relationships:查找关系。自定义集成端点POST /trigger-integration/<integration_name>:激活预定义的集成函数。
前端概览
MindGraph的前端具有轻量级的交互式、基于Web的界面,可以动态可视化和管理基于图形的数据模型。虽然MindGraph旨在作为API使用,但前端在演示目的上很有帮助。它利用HTML、CSS、JavaScript进行开发,使用Cytoscape.js进行图形可视化,并使用jQuery处理AJAX请求。
特性
图形可视化:使用Cytoscape.js进行交互式图形渲染。动态数据交互:支持实时数据获取、添加和图形更新,无需重新加载页面。搜索和高亮:允许用户搜索节点,高亮显示并列出匹配项。搜索表单目前被双重使用于自然语言查询,这实际上并不合理,但这是展示功能的一种快速方式。(这是用作API的,前端仅用于演示目的)数据提交表单:包括用于自然语言、URL输入和CSV文件上传的表单。响应式设计:适应各种设备和屏幕大小。
工作流程
初始化:在页面加载时,使用样式和布局初始化图形。用户交互:通过界面,用户可以:搜索节点,结果在图形中高亮显示,并列在侧边栏中。使用支持各种输入方法的表单添加数据。刷新图形以反映最新的后端数据。数据处理:用户输入被发送到后端进行处理和集成,前端图形可视化相应更新。
基于模式的知识图创建
MindGraph利用schema.json文件来定义其知识图中实体的结构和关系。这个模式作为解释和结构化自然语言输入为连贯图形格式的蓝图。它详细说明了节点类型(例如,Person、Organization、Concept)以及它们之间可能的关系,确保生成的知识图符合一致的格式。这种方法允许自动化、基于AI的处理自然语言输入,生成反映输入文本中固有复杂相互关系的结构化数据。
在AI集成中使用schema.json
当create_knowledge_graph函数处理输入时,它会查阅schema.json,了解如何将识别的实体及其关系映射到图形中。这包括:根据模式定义识别节点类型和属性。确定有效的关系类型及其特征。结构化输出以匹配预期的图形格式,便于与应用程序的数据模型无缝集成。模式确保由AI生成的知识图不仅与应用程序的数据模型一致,而且丰富详细,捕捉输入文本中描述的实体之间的微妙关系。
优势
一致性:确保所有从自然语言输入生成的知识图都遵循相同的结构规则,使数据集成和解释更加简单。
灵活性:允许通过修改schema.json轻松更新和扩展知识图结构,无需更改代码库。AI集成:通过为预期输出提供清晰的结构,促进了使用先进的AI模型进行自然语言处理,增强了应用程序从非结构化数据中提取有意义见解的能力。
开发与扩展
添加新的集成要将新的集成整合到MindGraph中,创建一个Python模块,放在integrations目录下。该模块应定义集成的逻辑,并包含一个register函数,将集成连接到IntegrationManager。确保您的集成与应用程序的组件正确交互,例如models.py用于数据操作,views.py用于通过API端点激活。通过模块化和可重用的代码,这种方法允许MindGraph通过动态和可重用的代码扩展其功能。利用信号对于实体生命周期事件,发出信号提供了扩展功能或与其他系统同步的钩子。
数据库集成和使用
MindGraph支持灵活的数据库集成,以增强其数据存储和检索能力。Out of the box,MindGraph支持一个简单的内存数据库和一个更强大的基于云的选项,NexusDB。这种灵活性使得可以轻松适应不同的部署环境和用例。
支持的数据库
InMemoryDatabase:用于快速原型设计和测试的简单内存图形数据结构。由于其不持久化的性质,不建议用于生产环境。NexusDB:一个全方位的云数据库,设计用于存储图形、表格、文档、文件、向量等等。提供一个共享的知识图,用于全面的数据管理和分析。
配置数据库
数据库集成通过DATABASE_TYPE环境变量进行控制。要选择数据库,请将此变量设置为memory以选择内存数据库,或设置为nexusdb以进行NexusDB集成。
添加新的数据库集成
要将新的数据库系统集成到MindGraph中:实现数据库集成:在base.py中定义的抽象基类DatabaseIntegration下创建一个新的Python模块,位于app/integrations/database下。您的实现应该为基类中的所有抽象方法提供具体的方法。注册您的集成:修改app/integrations/database/init.py中的数据库类型检测逻辑,以包含您的新数据库类型。这涉及添加一个额外的elif语句,以检查您的数据库类型,并相应地设置CurrentDBIntegration。配置环境变量:如果您的集成需要自定义环境变量(例如,用于连接字符串、身份验证),请确保它们在MindGraph部署环境中得到适当设置和文档化。
模式管理
对于需要模式定义的数据库(如NexusDB),在您的集成模块中包含一个模式管理策略。这可能涉及在启动时检查和更新数据库模式,以确保与当前版本的MindGraph兼容。
示例命令
通过curl创建一个人:curl -X POST http://0.0.0.0:81/people-H "Content-Type: application/json"-d '{"name":"Jane Doe","age":28}'
示例用例
为了展示MindGraph集成系统的强大功能,以下是一些示例命令:触发自然语言输入集成curl -X POST http://0.0.0.0:81/trigger-integration/natural_input-H "Content-Type: application/json"-d '{"input":"Company XYZ organized an event attended by John Doe and Jane Smith."}'