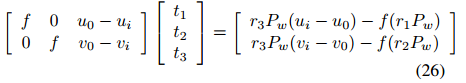Mixtral-8x7B是最好的开源llm之一。但是消费级硬件上对其进行微调也是非常具有挑战性的。因为模型需要96.8 GB内存。而微调则需要更多的内存来存储状态和训练数据。比如说80gb RAM的H100 GPU是不够的。
这时我们就想到了QLoRA,它将模型大小除以4,同时通过仅调整LoRA适配器进行微调来减小优化器状态的大小。但是即使使用QLoRA,然需要32 GB的GPU内存来微调Mixtral-8x7B。
如果我们可以将Mixtral-8x7B量化到更低的精度呢?
例如我们可以用AQLM将Mixtral-8x7B量化为2位,同时最小化模型性能的下降。

在本文中,我将展示如何仅使用16 GB的GPU RAM对使用AQLM进行量化的Mixtral-8x7B进行微调。我还讨论了如何优化微调超参数,以进一步减少内存消耗,同时保持良好的性能。对2位的Mixtral进行微调是很快的,并且可能产生比QLoRA更好的模型,同时使用的内存减少了两倍。
用AQLM对2位LLM量化进行微调
AQLM的作者已经在Hugging Face发布了量化版本的Mixtral-8x7B:
ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf
我们使用这个模型进行微调。它只占用12.6 GB的内存。
首先安装AQLM和最新版本的PEFT、Transformers、Accelerate和TRL。我还安装了bitsandbytes来使用分页AdamW 8位,因为这将进一步减少内存消耗。
pip install git+https://github.com/huggingface/transformers.git
pip install git+https://github.com/huggingface/peft
pip install git+https://github.com/huggingface/trl.git
pip install git+https://github.com/huggingface/accelerate.git
pip install aqlm[gpu,cpu]
然后引用库
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
)
from trl import SFTTrainer
加载模型
model = AutoModelForCausalLM.from_pretrained(
"ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf",
trust_remote_code=True, torch_dtype="auto", device_map="cuda", low_cpu_mem_usage=True
)
tokenizer
tokenizer = AutoTokenizer.from_pretrained("ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf")
tokenizer.pad_token = tokenizer.eos_token
这里使用了prepare_model_for_kbit_training为微调准备模型,它与AQLM一起工作得很好。
model = prepare_model_for_kbit_training(model)
通过微调,我们将把Mixtral-8x7B变成一个指示/聊天模型。我使用了timdettmers/openassistant-guanaco,因为它小而好,适合本教程。由于它有一个名为“text”的列,因此它的格式也可以使用TRL进行微调。
dataset = load_dataset("timdettmers/openassistant-guanaco")
LoraConfig定义如下:
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate", "w1", "w2", "w3"]
)
我们的配置会产生一个242M参数的巨大适配器。这是因为我的目标是模块w1、w2和w3。这些模块都在Mixtral的8位专家内部,总共24个模块。其他模块(自注意力和门控模块)由8位专家共享。它们对可训练参数总数的影响可以忽略不计。
对于训练超参数,我选择如下:
training_arguments = TrainingArguments(
output_dir="./fine-tuned_MixtralAQLM_2bit/",
evaluation_strategy="steps",
do_eval=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
per_device_eval_batch_size=4,
log_level="debug",
logging_steps=25,
learning_rate=1e-4,
eval_steps=25,
save_strategy='steps',
max_steps=100,
warmup_steps=25,
lr_scheduler_type="linear",
)
这里重要的超参数是:
per_device_train_batch_size和gradient_accumulation_steps:我将它们设置为4和4,这将产生总批大小为16(4*4)。
learning_rate:我把它设置为1e-4,因为它看起来很好用。这绝对不是最好的值。
lr_scheduler_type:我将其设置为“linear”。
optim: paged_adamw_8bit性能良好,同时比原始AdamW实现消耗的内存少得多。缺点是它减慢了微调速度,特别是如果你有一个旧的CPU。如果您有足够的内存,比如24G,可以将其替换为“adamw_torch”或“adamw_8bit”。
我们将max_steps设置为100。来证实模型在学习,但时这还不足以训练出一个好的模型。因为至少训练1到2个epoch,才能获得一个相当好的适配器。
使用TRL的SFTTrainer进行培训:
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=256,
tokenizer=tokenizer,
args=training_arguments,
)
trainer.train()
根据任务,可以增加“max_seq_length”,我将其设置为256。这是一个较低的值,但它有助于消耗更少的内存。
根据训练和验证损失,微调进展顺利:
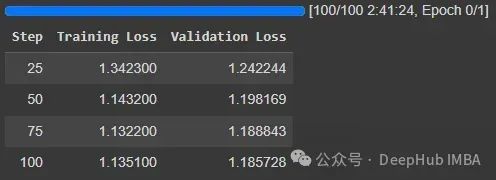
整个过程耗时2小时41分钟。我用的是Google Colab的A100。如果使用RTX GPU,预计训练时间类似。如果你使用较旧的GPU,例如T4或RTX 20xx,它可能会慢2到4倍。
对AQLM模型进行微调的效果出奇地好。当我尝试使用标准QLoRA对Mixtral进行微调时,在相同的数据集上,它消耗了32 GB的VRAM,并且困惑并没有减少得那么好。
减少内存消耗
如果你只有一个带有16gb VRAM的GPU,微调Mixtral仍然是可能的。
减少per_device_train_batch_size并按比例增加gradient_accumulation_steps。训练批大小的最小值为1。如果您将其从4减少到1(小4倍),那么应该将gradient_accumulation_steps从4增加到16(大4倍)。
通过从LoraConfig中删除w1、w2、w3和可能的gate,只针对自注意力模块。、
将LoRA rank (LoraConfig中的r参数)降低到8或4。
总结
AQLM已经被PEFT和Transformers很好地支持。正如我们在本文中看到的,对AQLM模型进行微调既快速又节省内存。由于我只对几个训练步骤进行了微调,所以我没有使用基准测试来评估经过微调的适配器,但是查看在100个微调步骤之后所达到的困惑(或验证损失)是有很不错的。
这种方法的一个缺点是,由于模型已经量子化了,所以不能合并微调的适配器。并且由于使用AQLM量化llm的成本非常高,因此AQLM模型并不是很多。
https://avoid.overfit.cn/post/2e5820701d9c4da2afe82b696999be72
作者:Benjamin Marie

![[C语言]指针详解一、数组指针、二维数组传参、函数指针](https://img-blog.csdnimg.cn/direct/9e750ae0636e49f8882e4e52c3416845.png)