最近在苦恼为我的数据决定分组问题,在查找资料时,恰好看到机器学习中的无监督学习的聚类分析,正好适用于我的问题,但是我之前学机器学习时。正好没有学习无监督部分,因为我认为绝大多数问题都是有标签的监督学习,正是大意了,这不巧了正好遇上了,那就赶紧学习一下吧。
最近正在苦恼为我的数据决定分组问题,在查找资料时,恰好看到机器学习中的无监督学习的聚类分析,正好适用于我的问题,但是我之前学机器学习时。正好没有学习无监督部分,因为我认为绝大多数问题都是有标签的监督学习,真是大意了,这不巧了正好遇上了,那就赶紧学习一下吧。

说到无监督学习,还真是强大,无监督学习的优点是可以处理没有标签的数据,发现数据的潜在规律和特征,适用于探索性的数据分析。就好像不需要老师教,就可以自己根据数据之间的关系对数据进行分组。

因为我的问题比较适合K-means和DBSCAN解决,这篇文章我主要介绍这两种算法。
DBSCAN聚类分析是一种基于密度的聚类算法,它可以发现任意形状的簇,并且能够识别出噪声点。与之相比,K-means聚类算法是一种基于距离的聚类算法,它将数据划分为K个球形的簇,但是对噪声点和非球形的簇不太适合。下面我将用Python代码和图片来展示这两种算法的原理和效果。
首先,我们导入一些必要的库,如numpy, matplotlib, sklearn等,并生成一些随机的数据点,其中有四个簇和一些噪声点。
import os
os.environ["OMP_NUM_THREADS"] = "1"
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans, DBSCAN
# 生成随机数据
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)
# 添加一些噪声点
X = np.r_[X, np.random.randn(10, 2) + [2, 2]]
plt.scatter(X[:, 0], X[:, 1], s=10, c='k')
plt.title('Raw data')
plt.show()
通过肉眼看到原始数据,还是比较聚集的,但是处于边界的这些点属于哪一个组(簇)呢,还是得通过聚类算法来确定。
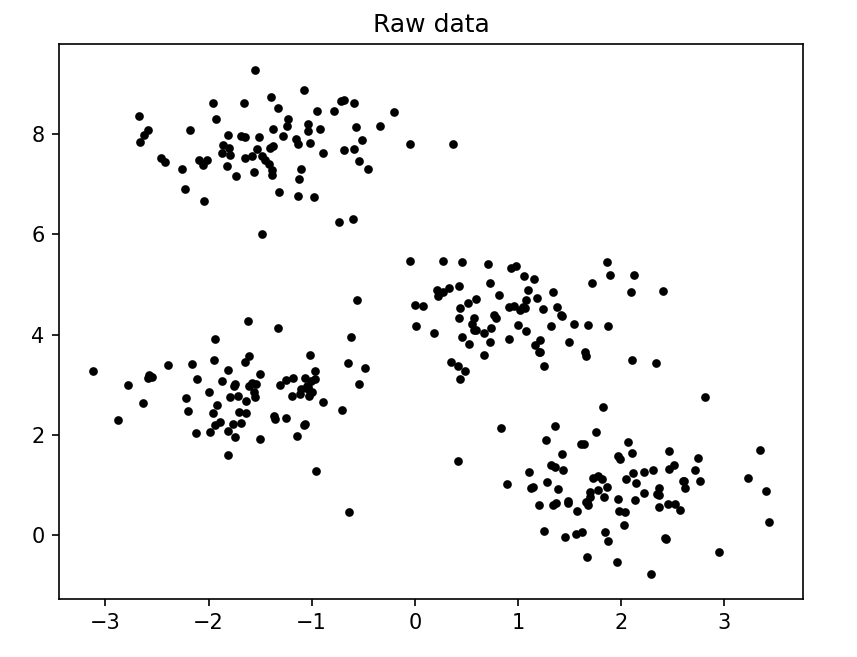
k-means聚类分析
接下来,我们用K-means算法来对数据进行聚类,设置K=4,即我们想要得到四个簇。我们可以用sklearn库中的KMeans类来实现,它有以下几个重要的参数:
- n_clusters: 聚类的个数,即K值
- init: 初始质心的选择方法,可以是’random’或’k-means++',后者是一种优化的方法,可以加速收敛,但是是选择优化方法啦。🤭
- n_init: 随机初始化的次数,算法会选择其中最好的一次作为最终结果
- max_iter: 最大迭代次数,当迭代达到这个次数时,算法会停止,即使没有收敛
- tol: 容忍度,当质心的移动小于这个值时,算法会认为已经收敛,停止迭代
我们可以用fit函数来训练模型,用predict函数来对数据进行预测,用inertia_属性来获取误差平方和,用cluster_centers_属性来获取质心的坐标。代码如下:
# K-means聚类
kmeans = KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300, tol=1e-4, random_state=0)
y_pred = kmeans.fit_predict(X)
sse = kmeans.inertia_
centers = kmeans.cluster_centers_
print('K-means SSE:', sse)
plt.scatter(X[:, 0], X[:, 1], s=10, c=y_pred)
plt.scatter(centers[:, 0], centers[:, 1], s=100, c='r', marker='*')
plt.title('K-means clustering')
plt.show()
k-means的均方差和为232.678,这个结果表示聚类效果还不错。

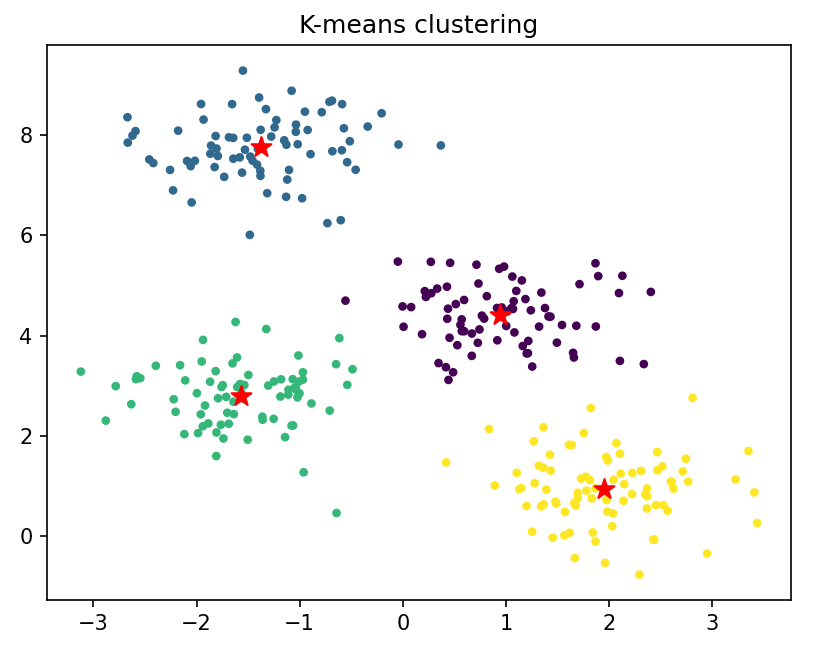
从-means聚类图中可以看出,K-means算法可以大致将数据分为四个簇,但是对于一些噪声点和边界点,它的划分效果不太理想,因为它只考虑了距离,而没有考虑密度。另外,K-means算法需要事先指定K值,如果K值不合适,可能会导致聚类效果很差。
DBSCAN聚类分析
下面,使用DBSCAN算法来对数据进行聚类,它不需要指定簇的个数,而是根据数据的密度来划分簇。我们可以用sklearn库中的DBSCAN类来实现,它有以下几个重要的参数:
- eps: 邻域半径,即判断一个点是否为核心点的距离阈值;
- min_samples: 邻域内的最小样本数,即判断一个点是否为核心点的密度阈值;
- metric: 距离度量方式,可以是’euclidean’,‘manhattan’,'cosine’等;
- algorithm: 邻域查询的算法,可以是’auto’,‘ball_tree’,‘kd_tree’,'brute’等,不同的算法有不同的时间和空间复杂度
然后可以用fit方法来训练模型,用fit_predict方法来对数据进行预测,用labels_属性来获取每个点的簇标签,用core_sample_indices_属性来获取核心点的索引。代码如下:
# DBSCAN聚类
dbscan = DBSCAN(eps=0.5, min_samples=5, metric='euclidean', algorithm='auto')
y_pred = dbscan.fit_predict(X)
labels = dbscan.labels_
core_indices = dbscan.core_sample_indices_
n_clusters = len(set(labels)) - (1 if -1 in labels else 0) # 去掉噪声点的簇个数
print('DBSCAN clusters:', n_clusters)
plt.scatter(X[:, 0], X[:, 1], s=10, c=y_pred)
plt.scatter(X[core_indices, 0], X[core_indices, 1], s=100, c='r', marker='*')
plt.title('DBSCAN clustering')
plt.show()
k-DBSCAN聚类分析总共是聚类了4个簇。


从图中可以看出,DBSCAN算法可以更好地将数据分为四个簇,并且能够识别出噪声点(黑色的点),因为它考虑了距离和密度,而且不需要事先指定簇的个数。另外,DBSCAN算法可以处理任意形状的簇,而不局限于球形的簇。
总结
总结一下,K-means和DBSCAN是两种常用的聚类算法,它们各有优缺点,适用于不同的场景。
K-means算法简单易懂,运行速度快,但是需要指定簇的个数,对噪声点和非球形的簇不太适合。DBSCAN算法不需要指定簇的个数,可以发现任意形状的簇,并且能够识别出噪声点,但是运行速度慢一些,对于不同密度的簇可能效果不好。
在实际应用中,还是需要根据数据的特点和需求来选择合适的聚类算法,不过如果愿意耐心多次对比参数,训练聚类分析算法,还是推荐DBSCAN算法。