课后作业2:数据管理2
一:上机实验2
# 编写函数stat,要求该函数同时计算均值,最大值,最小值,标准差,峰度和偏度。
| install.packages("timeDate") library(timeDate) stat <- function(x) { result <- c( mean_value = mean(x), max_value = max(x), min_value = min(x), sd_value = sd(x), kurtosis_value = kurtosis(x), skewness_value = skewness(x) ) return(result) } |

# 设置随机种子
| set.seed(66) |
# 生成自由度为2的t分布的100个随机数t
| (t_values <- rt(100, df = 2)) |

# 通过函数stat计算t的均值,最大值,最小值,标准差,峰度和偏度。
| (result <- stat(t_values)) |

二:思考与实验总结
1:如何通过数据管理得到实际情况中需要的数据集格式?
主要通过以下数据管理方面的操作手段,获得实际情况的数据集格式。
| 编号 | 操作概念 | 操作内容 |
| 1 | 变量重命名 | 修改数据库和列表的变量名,或修改矩阵的行名和列名 |
| 2 | 缺失值分析 | 识别包含缺失值的观测,判断数据中是否存在缺失值,删除含有缺失值的观测 |
| 3 | 数据排序 | 按照降序或升序排序数据,返回排序后的向量、向量中每个数值对应的秩、或排序数据所在向量中的索引 |
| 4 | 随机抽样 | 实现放回简单或不放回简单随机抽样,对数据进行随机分组 |
| 5 | 字符串处理 | 从文本型数据中抽取信息,为打印输出和生成报告重设文本的格式 |
| 6 | 文本分词 | 对文本进行合理的分割,便捷地获取关键信息 |
操作流程主要为:创建新变量——缺失值分析——函数构建与使用——字符串处理——控制流设置语句的执行顺序。
2:merge函数的自行实现
Merge函数的主要功能是:通过共同列或者行名合并数据框,或者执行其他合并操作。
Merge函数的语法主要为:
| merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE, incomparables = NULL, ...) |
其中,x和y参数表示要合并的数据框或对象;by、by.x和by.y指定合并的列;all、all.x和all.y是控制填充的逻辑值;sort决定结果是否按照公共列排序;suffixes标明后缀出处。
(1)当合并所用到的共同列在数据框中的列名称相同时
【1】构建数据框
| 名称 <- c('郭靖','黄蓉','华筝','梅超风','杨康','穆念慈') 性别 <- c('M','F','F','F','M','F') 亲属 <- c('郭啸天','黄药师','铁木真','陈玄风','完颜洪烈','杨铁心') data <- data.frame(名称,性别,亲属,stringsAsFactors = F) data 名称 <- c('郭靖','黄蓉','王重阳','梅超风','欧阳锋','一灯大师') 身份 <- c('侠之大者','女中诸葛','全真教掌门','黑风双煞','白驼山庄主','大理高僧') 武功 <- c('降龙十八掌',' 落英神剑掌','全真剑法','九阴白骨爪','蛤蟆功','一阳指') pd <- data.frame(名称,身份,武功,stringsAsFactors = F) pd |

【2】按照默认方式合并,即有共同属性的列被合并(此处为名称)
| merge(data, pd) |

(2)当合并所用到的共同列在数据框中的列名称相同时
【1】构建数据框
| # merge()函数 名称 <- c('郭靖','黄蓉','华筝','梅超风','杨康','穆念慈') 性别 <- c('M','F','F','F','M','F') 亲属 <- c('郭啸天','黄药师','铁木真','陈玄风','完颜洪烈','杨铁心') data <- data.frame(名称,性别,亲属,stringsAsFactors = F) data 姓名 <- c('郭靖','黄蓉','王重阳','梅超风','欧阳锋','一灯大师') 身份 <- c('侠之大者','女中诸葛','全真教掌门','黑风双煞','白驼山庄主','大理高僧') 武功 <- c('降龙十八掌',' 落英神剑掌','全真剑法','九阴白骨爪','蛤蟆功','一阳指') pd <- data.frame(姓名,身份,武功,stringsAsFactors = F) pd |

【2】按照指定列合并
| merge(data,pd,by.x='名称',by.y='姓名') |

(3)逻辑值all为假时
【1】交集合并(默认情况)
| merge(data,pd,by.x='名称',by.y='姓名',all=F) |

(4)逻辑值all为真时
【1】并集合并
| merge(data,pd,by.x = '名称',by.y = '姓名',all=TRUE) |

(5)逻辑值all.x=TRUE且all.y=FALSE时
【1】取x的全集与匹配的y数据
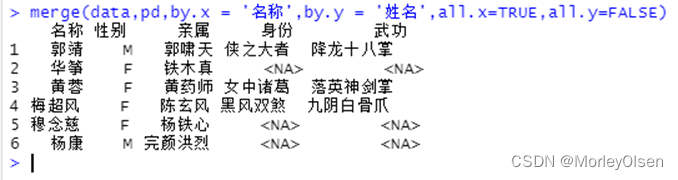
| merge(data,pd,by.x = '名称',by.y = '姓名',all.x=TRUE,all.y=FALSE) |
(6)逻辑值all.y=TRUE且all.x=FALSE时
【1】取y的全集与匹配的x数据
| merge(data,pd,by.x = '名称',by.y = '姓名',all.y=TRUE,all.x=FALSE) |

(7)sort的调用
【1】是否按照公共列排序
| merge(data,pd,by.x = '名称',by.y = '姓名',all=TRUE,sort=TRUE) merge(data,pd,by.x = '名称',by.y = '姓名',all=TRUE,sort=FALSE) |

(8)suffix的调用
【1】构建数据框
| # merge()函数 名称 <- c('郭靖','黄蓉','华筝','梅超风','杨康','穆念慈') 性别 <- c('M','F','F','F','M','F') 亲属 <- c('郭啸天','黄药师','铁木真','陈玄风','完颜洪烈','杨铁心') 武功 <- c('空明拳','兰花拂穴手','无','摧心掌','九阴白骨爪','逍遥游拳法') data <- data.frame(名称,性别,亲属,武功,stringsAsFactors = F) data 姓名 <- c('郭靖','黄蓉','王重阳','梅超风','欧阳锋','一灯大师') 身份 <- c('侠之大者','女中诸葛','全真教掌门','黑风双煞','白驼山庄主','大理高僧') 武功 <- c('降龙十八掌',' 落英神剑掌','全真剑法','九阴白骨爪','蛤蟆功','一阳指') pd <- data.frame(姓名,身份,武功,stringsAsFactors = F) pd |

【2】默认显示变量来源的后缀
| merge(data,pd,by.x = '名称',by.y = '姓名',all=TRUE,sort=TRUE,suffixes = c('.x','.y')) |

【3】个性化显示变量来源的后缀
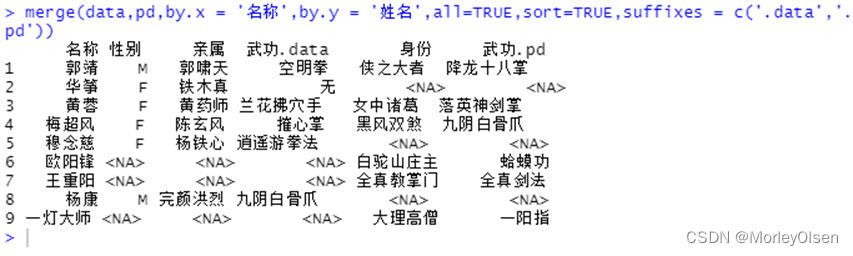
| merge(data,pd,by.x = '名称',by.y = '姓名',all=TRUE,sort=TRUE,suffixes = c('.data','.pd')) |
三:实验参考
[1] merge()函数--R语言_merge函数-CSDN博客
[2] R语言的merge函数_r语言merge函数用法-CSDN博客