目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
5.算法完整程序工程
1.算法运行效果图预览


2.算法运行软件版本
matlab2022a
3.部分核心程序
...........................................................................
Year=[2011,2012,2013,2014,2015,2016];
figure;
plot(Year,dn{i},'k-o');
hold on
plot(Year,Predict1{i},'r-s');
grid on
xlabel('year');
ylabel('value');
legend('真实值','训练预测值');
%获得误差
for i = 1:31
error(i) = mean(abs(dn{i}-Predict1{i}));
RMSE(i) = sqrt(sum(abs(dn{i}-Predict1{i}).^2)/6);
end
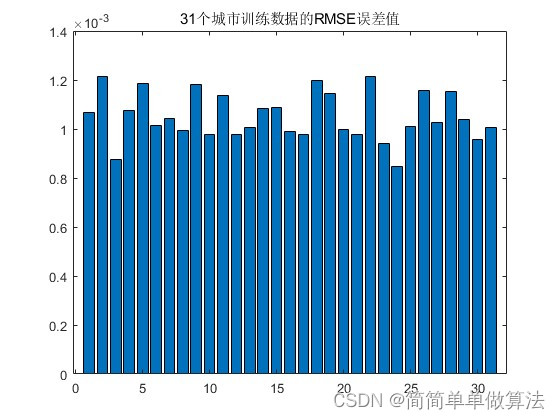
figure;
bar(RMSE);
title('31个城市训练数据的RMSE误差值');
%使用训练模型进行预测
%输入2017年到2020的X变量作为采集数据
%从excel中没提供这个数据集,所以需要这里先用模拟的数据。这里采用拟合法,得到未来几年大概的X值
for i = 1:31%31个城市
tmps1 = Xn{i};
for j = 1:24
tmps2 = tmps1(:,j);
X = [Year'];
%进行拟合
X2 = 2018;
tmps4(:,j) = [tmps2;tmps2(end)+0.001*(X2-2016)*(tmps2(end)-tmps2(end-1))];%调节过大的幅度
end
Xn2{i} = tmps4;
end
%进行预测
for i = 1:31%31个城市
[Predict2{i},error2] = svmpredict([1;1;1;1;1;1;1],Xn2{i},model{i});
end
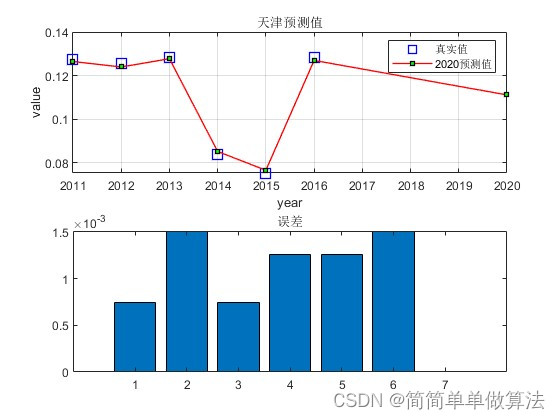
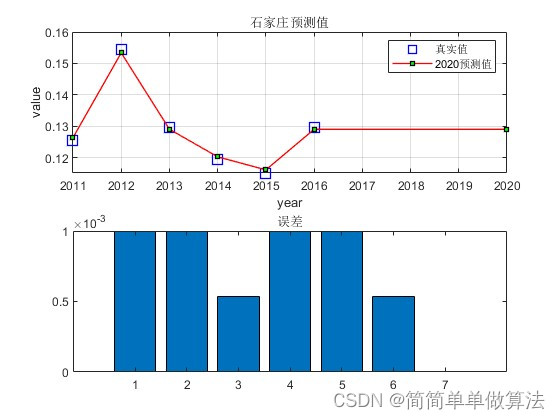
%用北京的数据进行显示预测结果
Year2=[2011,2012,2013,2014,2015,2016,2018];
K=1;%设置不同的K,选择显示不同的城市
.......................................................
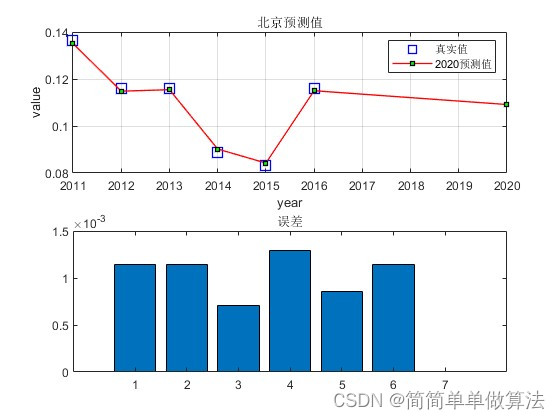
for i = 1:31
figure;
subplot(211);
plot(Year,dn{i},'bs','LineWidth',1,...
'MarkerSize',10);
hold on
plot(Year2,Predict2{i},'r-s','LineWidth',1,...
'MarkerEdgeColor','k',...
'MarkerFaceColor','g',...
'MarkerSize',4)
grid on
xlabel('year');
ylabel('value');
legend('真实值','2018预测值');
title([NAME{i},'预测值']);
subplot(212);
bar([abs(dn{i}-Predict2{i}(1:end-1));0]);
title('误差');
end
%保存数据
XX=[];
for i = 1:31
XX=[XX,Predict2{i}(end)];
end
%注意,XX就是最后的2020年数据Y
XX
05_058m4.算法理论概述
支持向量机是一种监督学习方法,主要用于分类和回归分析。它基于结构风险最小化原则构建最优超平面以实现最大间隔分类,并且在处理非线性问题时通过核函数映射到高维特征空间来实现线性可分。

数学表达式: 超平面可以表示为:
wTx+b=0
其中 w 是法向量,b 是位移项。
最大化间隔的优化问题: 对于给定的数据集,SVM试图找到最优的 w 和b,使其满足以下条件:
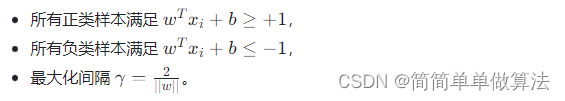

KKT条件与最优解: 最终得到的决策函数为:

其中只有支持向量(满足 0<αi<C 的样本点)影响决策边界。
非线性情况下的SVM原理:为了处理非线性分类问题,引入了核函数 K(xi,xj) 来将低维特征映射到高维特征空间:

常用的核函数包括线性核、多项式核、高斯径向基核(RBF)等。
预测模型: 对于新的输入样本x,其预测类别标签由如下公式给出:
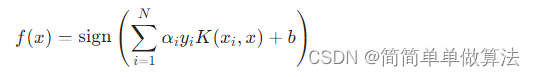
5.算法完整程序工程
OOOOO
OOO
O