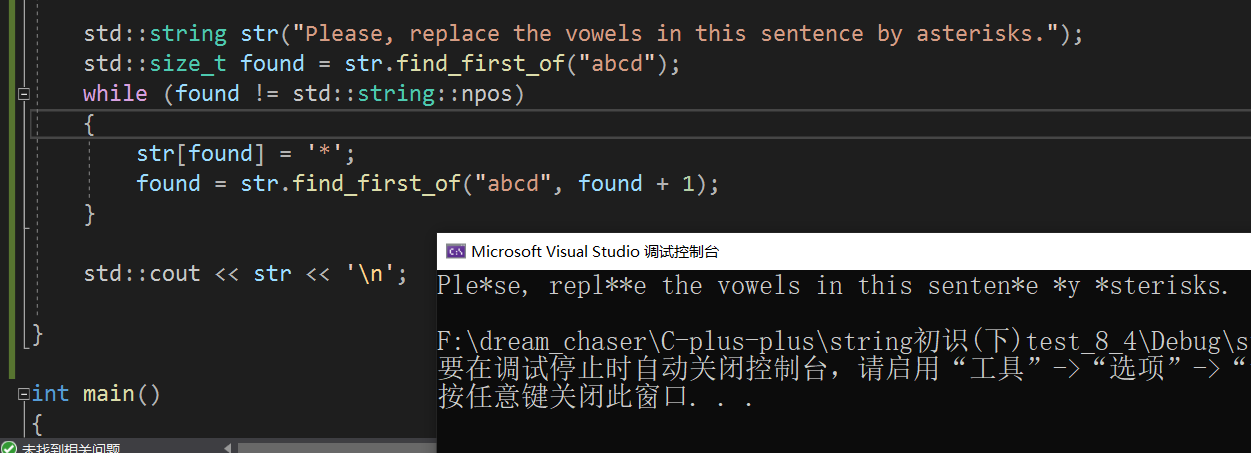
目录
相关传送门
1. NOSQL和关系型数据库比较
2. 主流的NOSQL产品
3. Redis的理解
4. redis数据存储格式
4.1 String
4.2 Hash
4.3 List
4.4 Set
4.5. sorted_set
注:手机端浏览本文章可能会出现 “目录”无法有效展示的情况,请谅解,点击侧栏目录进行跳转
相关传送门
1.【数据结构】布隆过滤器
2.【开发】SpringBoot 整合 Redis
1. NOSQL和关系型数据库比较
优点:低成本、高查询、存储格式丰富、支持多种数据类型
- nosql简单易部署,且多数开源
- nosql将数据存储在缓存之中,sql将数据存储在硬盘中;nosql比sql数据库查询速度快
- nosql的存储格式是键值对形式,文档形式、图片形式等,可以存储基础类型以及对象或者集合等格式,sql支支持基础数据
- 关系型数据库有类似Join的多表查询机制限制扩展很艰难
缺点:维护技术有限、学习使用成本高、不提供关系型数据库对事务的处理
- 新技术,维护工具
- 不遵循SQL标准,学习使用成本高
- 不提供关系型数据库对事务的处理
2. 主流的NOSQL产品
- 键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化
列存储数据库
相关产品:Cassandra, HBase, Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展劣势:功能相对局限
文档型数据库
相关产品:CouchDB、MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的) 数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法
图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络数据模型:图结构
优势:利用图结构相关算法。
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
数据库排名:
3. Redis的理解
概念:C语言开发的一个开源的高性能键值对存储形式的数据库
特征:
1. 数据之间没有必然的关联关系
2. 内部采用单线程机制进行工作
3. 高性能
4. 多数据类型支持
名称 类型 数据结构 字符串类型 String String
列表类型 list LinkedList
散列类型 hash HashMap
集合类型 set HashSet
有序集合类型 sorted_set TreeSet
5. 持久化支持。可以进行数据灾难恢复
4. redis数据存储格式
- redis自身是一个map,所存储的数据都采用键值对的形式存储
- key部分永远都是字符串,value部分指的是存储的数据的类型
- key的语法:
- 在同一个项目中,key部分最好使用统一的命名模式
- key区分大小写
- key尽量不超过1024字节。不仅消耗内存,也会降低查找的效率
- key不易太短,太短会降低可读性
4.1 String
- 存储的数据:单个数据,最简单最常用的数据存储类型
- 存储的数据格式:一个存储空间保存一个数据
- 存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作用数字操作使用
4.2 Hash
- 存储的困惑:对象类数据的存储如果具有频繁的更新需求会显得笨重
- 哈希的特点:
- 存储需求:对一系列存储的数据进行编组,方便管理
- 存储结构:一个存储空间保存多个键值对数据
- hash类型:底层使用哈希表结构实现数据存储
- hash存储结构优化
- 如果filed数量较少,存储结构优化为类数组结构
- 如果filed数量较多,存储结构使用HashMap结构
4.3 List
- 存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
- 存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序
- list类型:保存多个数据,底层使用双向链表存储结构实现
4.4 Set
- 存储需求:存储大量的数据,在查询方面提供更高的效率
- 存储结构:存储大量的数据,高效的内部存储机制,便于查询
- set类型:与hash存储结构完全相同,仅存储键,不存储值,并且值是不允许重复的
4.5. sorted_set
- 存储需求:数据排序 有利于数据的有效展示,需要提供一种可以根据自身特征进行排序的方式
- 存储结构:新的存储模型,可以保存可排序的数据
- sorted_set类型:在set的存储结构基础上添加可排序字段