目录
一、NoSQL 介绍
二、Memcached
1、Memcached 介绍
1.1 Memcached 概念
1.2 Memcached 特性
1.3 Memcached 和 Redis 区别
1.4 Memcached 工作机制
1.4.1 内存分配机制
1.4.2 懒惰期 Lazy Expiration
1.4.3 LRU(最近最少使用算法)
1.4.4 集群
2、安装 Memcached
2.1 yum安装
2.2 编译安装
3、memcached选项
4、Memcached的基本使用方法
4.1 Memcached开发库和工具
4.1.1 Memping
4.1.2 Memstat
4.2 memcached操作命令
4.2.1 显示服务状态
4.2.2 添加数据
4.2.3 修改数据
4.2.4 调用数据
4.2.5 删除数据
4.2.6 清空数据
三、memcached 集群部署架构
1、基于magent的部署架构
2、Repcached实现原理
3、简化后的部署架构
4、部署repcached
4.1 memcached服务器1配置
4.2 memcached服务器2配置
4.3 客户端测试
4.4 使用HAProxy高可用部署
一、NoSQL 介绍
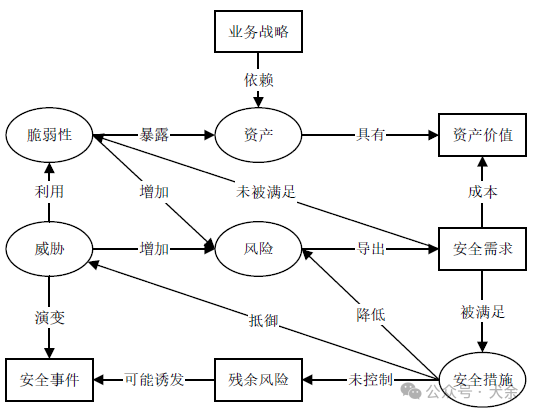
NoSQL是对 Not Only SQL、非传统关系型数据库的统称
NoSQL一词诞生于1998年,2009年这个词汇被再次提出指非关系型、分布式、不提供ACID的数据库设计模式
随着互联网时代的到来,数据爆发式增长,数据库技术发展日新月异,要适应新的业务需求
而随着移动互联网、物联网的到来,大数据的技术中NoSQL也同样重要
NoSQL 分类
-
Key-value Store k/v数据库
-
性能好 O(1) , 如: redis、memcached
-
-
Document Store 文档数据库
-
mongodb、CouchDB
-
-
Column Store 列存数据库,Column-Oriented DB
-
HBase、Cassandra,大数据领域应用广泛
-
-
Graph DB 图数据库
-
Neo4j
-
-
Time Series 时序数据库
-
InfluxDB、Prometheus
-
注:
关系型数据库:数据存放在硬盘,调度数据速率慢
非关系型数据库:数据存放在内存,调度数据速率快
二、Memcached
1、Memcached 介绍
1.1 Memcached 概念
Memcached 只支持能序列化的数据类型,不支持持久化,基于Key-Value的内存缓存系统
memcached 虽然没有像redis所具备的数据持久化功能,比如RDB和AOF都没有,但是可以通过做集群同步的方式,让各memcached服务器的数据进行同步,从而实现数据的一致性,即保证各memcached的数据是一样的,即使有任何一台 memcached 发生故障,只要集群中有一台 memcached 可用就不会出现数据丢失,当其他memcached 重新加入到集群的时候,可以自动从有数据的memcached 当中自动获取数据并提供服务
Memcached 借助了操作系统的 libevent 工具做高效的读写。libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥高性能。memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能
Memcached 支持最大的内存存储对象为1M,超过1M的数据可以使用客户端压缩或拆分报包放到多个key中,比较大的数据在进行读取的时候需要消耗的时间比较长,memcached 最适合保存用户的session实现session共享
Memcached存储数据时, Memcached会去申请1MB的内存, 把该块内存称为一个slab, 也称为一个page
Memcached 支持多种开发语言,包括:JAVA,C,Python,PHP,C#,Ruby,Perl等
Memcached 是一个高性能、分布式的内存对象缓存系统,用于减轻数据库负载,提升动态Web应用的性能。它基于内存键值存储系统设计,通过在内存中存储数据来减少对慢速数据库的访问次数,从而提高网站或应用程序的速度和响应能力
尽管 Memcached 在功能上有时被当作一种辅助数据库使用,但其主要角色是作为一个高性能、分布式的缓存层,适用于实时性要求高且数据可以容忍一定程度丢失的应用场景
1.2 Memcached 特性
-
分布式缓存: 可以在多台服务器上分布数据,允许构建大规模的缓存系统
-
内存中存储: 数据存储在内存中,因此读写速度非常快
-
简单的键值存储: 它使用简单的键值对存储方式,适合于存储对象、文本和其他数据类型
-
缓存数据过期: 可以为缓存的数据设置过期时间,确保缓存中的数据不会永远存在
-
支持多种语言: 提供了多种编程语言的客户端库,便于在不同的应用程序中使用
-
减轻数据库负载: 通过缓存频繁访问的数据,可以显著减轻数据库的负载,提高网站或应用程序的性能
-
LRU(最近最少使用)淘汰策略:当内存达到预设上限时,Memcached 将根据 LRU 算法自动删除最近最少使用的数据,为新数据腾出空间
-
非持久化:Memcached 不支持持久化存储,主要用于临时缓存
-
高性能: 由于数据存储在内存中,因此具有非常高的读取和写入性能
-
开源:
Memcached是一个开源项目,可以自由使用和修改
1.3 Memcached 和 Redis 区别
| 区别 | Redis | memcached |
|---|---|---|
| 支持的数据结构 | 哈希、列表、集合、有序集合 | 纯kev-value |
| 持久化支持 | 有 | 无 |
| 高可用支持 | redis支持集群功能,可以实现主动复制,读写分离官方也提供了sentinel集群管理工具,能够实现主从服务监控,故障自动转移,这一切,对于客户端都是透明的,无需程序改动,也无需人工介入 | 需要二次开发 |
| 存储value容量 | 最大512M | 最大1M |
| 内存分配 | 临时申请空间,可能导致碎片 | 预分配内存池的方式管理内存,能够省去内存分配时间 |
| 虚拟内存使用 | 有自己的VM机制,理论上能够存储比物理内存更多的数据,当数据超量时,会引发swap,把冷数据刷到磁盘上 | 所有的数据存储在物理内存里 |
| 网络类型 | 非阻塞IO复用模型,提供一些非KV存储之外的排序聚合功能,在执行这些功能时,复杂的CPU计算,会阻塞整个IO调度 | 非阻塞IO复用模型 |
| 水平扩展支持 | redis cluster 可以横向扩展 | 暂无 |
| 多线程 | Redis6.0之前是只支持单线程 | Memcached支持多线程,CPU利用方面Memcache优于redis |
| 单机QPS | 约10W | 约60W |
| 源代码可读性 | 代码清爽简洁 | 可能是考虑了太多的扩展性,多系统的兼容性,代码不清爽 |
| 适用场景 | 复杂数据结构、有持久化、高可用需求、value存储内容较大 | 纯KV,数据量非常大,并发量非常大的业务 |
1.4 Memcached 工作机制
1.4.1 内存分配机制
应用程序运行需要使用内存存储数据,但对于一个缓存系统来说,申请内存、释放内存将十分频繁,非常容易导致大量内存碎片,最后导致无连续可用内存可用。
Memcached 采用了 Slab Allocator 机制来分配、管理内存。
- Page:分配给 Slab 的内存空间,默认为1MB,分配后就得到一个Slab。Slab分配之后内存按照固定字节大小等分成 chunk
- Chunk:用于缓存记录 k/v 值的内存空间。Memcached 会根据数据大小选择存到哪一个chunk中,假设chunk有128bytes、64bytes等多种,数据只有100bytes存储在128bytes中,存在少许浪费
- Chunk 最大就是 Page的大小,即一个Page中就一个Chunk
- Slab Class:Slab 按照 Chunk 的大小分组,就组成不同的 Slab Class, 第一个Chunk大小为 96B的Slab为Class1,Chunk 120B为Class 2,如果有100bytes要存,那么 Memcached 会选择下图中Slab Class 2 存储,因为它是120bytes的Chunk。Slab之间的差异可以使用Growth Factor 控制,默认1.25

#查看Slab Class
[root@localhost ~]#memcached -u memcached -f 2 -vv
1.4.2 懒惰期 Lazy Expiration
memcached 不会监视数据是否过期,而是在取数据时才看是否过期,如果过期,把数据有效期限标识为0,并不清除该数据。以后可以覆盖该位置存储其它数据。
1.4.3 LRU(最近最少使用算法)
当内存不足时,memcached 会使用 LRU(Least Recently Used)机制来查找可用空间,分配给新记录使用
1.4.4 集群
Memcached 集群,称为基于客户端的分布式集群,即由客户端实现集群功能,即 Memcached本身不支持集群
Memcached集群内部并不互相通信,一切都需要客户端连接到Memcached服务器后自行组织这些节点,并决定数据存储的节点
2、安装 Memcached
官方安装说明:https://github.com/memcached/memcached/wiki/Install2.1 yum安装
[root@localhost ~]#yum info memcached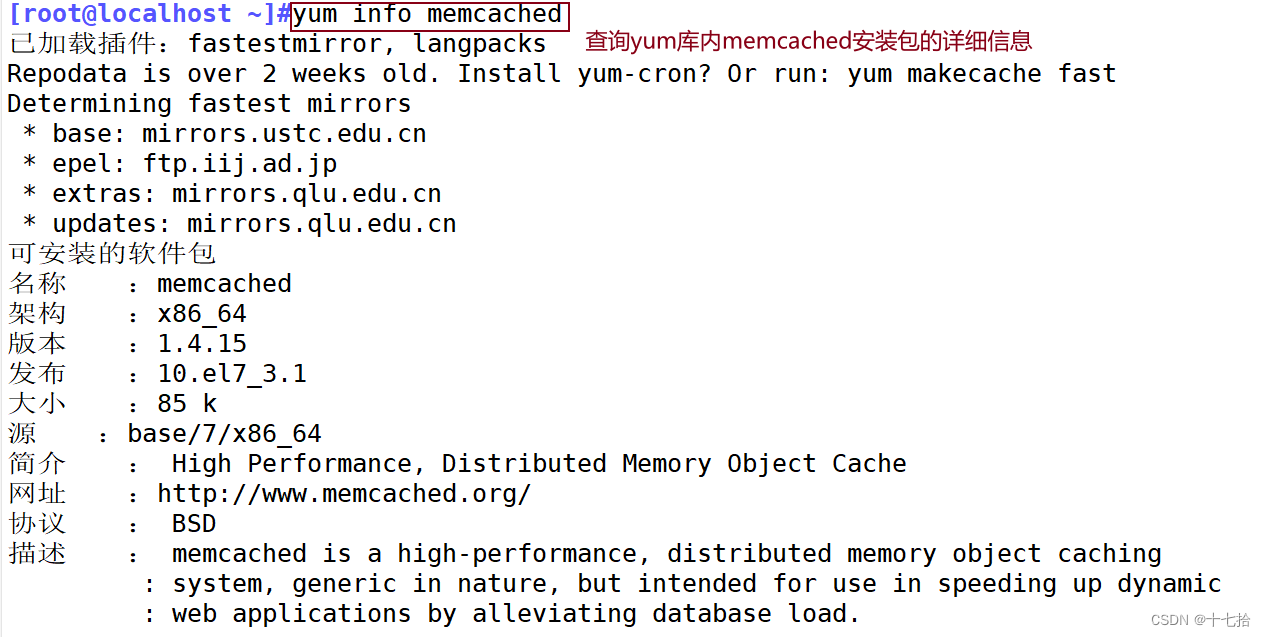
[root@localhost ~]#yum install memcached -y #yum安装memcached软件
[root@localhost ~]#rpm -ql memcached #查看memcached的相关文件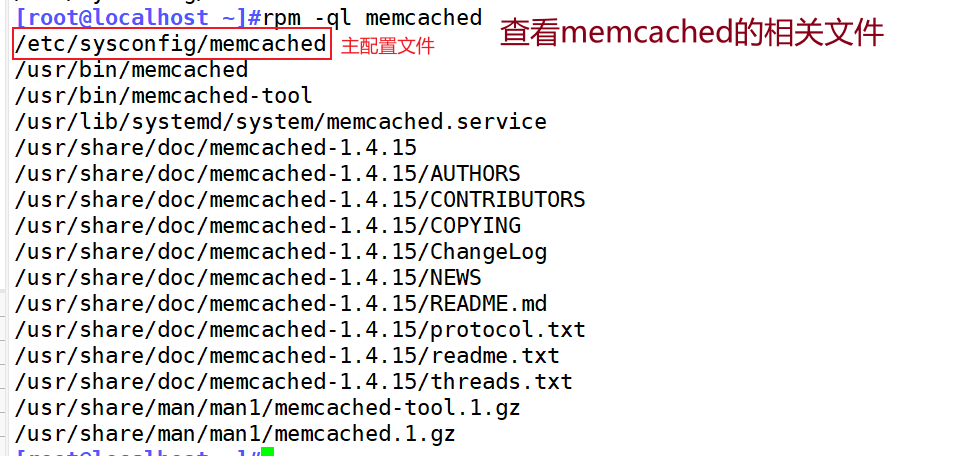
[root@localhost ~]#cat /etc/sysconfig/memcached #查看memcached主配置文件内容

[root@localhost ~]#systemctl start memcached.service
[root@localhost ~]#systemctl status memcached.service
[root@localhost ~]#ss -natp | grep memcached
2.2 编译安装
[root@localhost ~]#yum install gcc libevent-devel -y #安装依赖环境
[root@localhost ~]#cd /opt
[root@localhost opt]#wget http://memcached.org/files/memcached-1.6.6.tar.gz
[root@localhost opt]#tar xf memcached-1.6.6.tar.gz
[root@localhost opt]#cd memcached-1.6.6/
[root@localhost memcached-1.6.6]#./configure --prefix=/apps/memcached
[root@localhost memcached-1.6.6]#make -j 2 && make install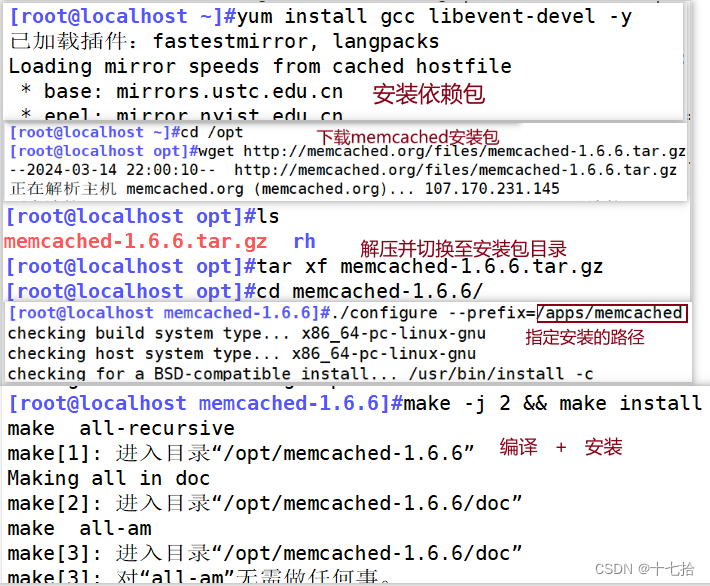
[root@localhost memcached-1.6.6]#ln -s /apps/memcached/bin/ /usr/bin/
#创建软链接,方便补全
[root@localhost memcached-1.6.6]#useradd -r -s /sbin/nologin memcached
#创建memcached系统用户
#写memcached配置文件
[root@localhost memcached-1.6.6]#cat > /etc/sysconfig/memcached << eof
PORT="11211"
USER="memcached"
MAXCONN="1024"
CACHESIZE="64"
OPTIONS=""
eof
#写systemd管理文件
[root@localhost memcached-1.6.6]#cat > /lib/systemd/system/memcached.service << eof
[Unit]
Description=memcached daemon
Before=httpd.service
After=network.target
[Service]
EnvironmentFile=/etc/sysconfig/memcached
ExecStart=/apps/memcached/bin/memcached -p \${PORT} -u \${USER} -m \${CACHESIZE} -c \${MAXCONN} \$OPTIONS
#-p \${PORT} -u \${USER} -m \${CACHESIZE} -c \${MAXCONN} \$OPTIONS必须要加\转义,不然输入的内容为空
[Install]
WantedBy=multi-user.target
eof
[root@localhost memcached-1.6.6]#systemctl daemon-reload
[root@localhost memcached-1.6.6]#systemctl enable --now memcached.service
[root@localhost memcached-1.6.6]#systemctl status memcached.service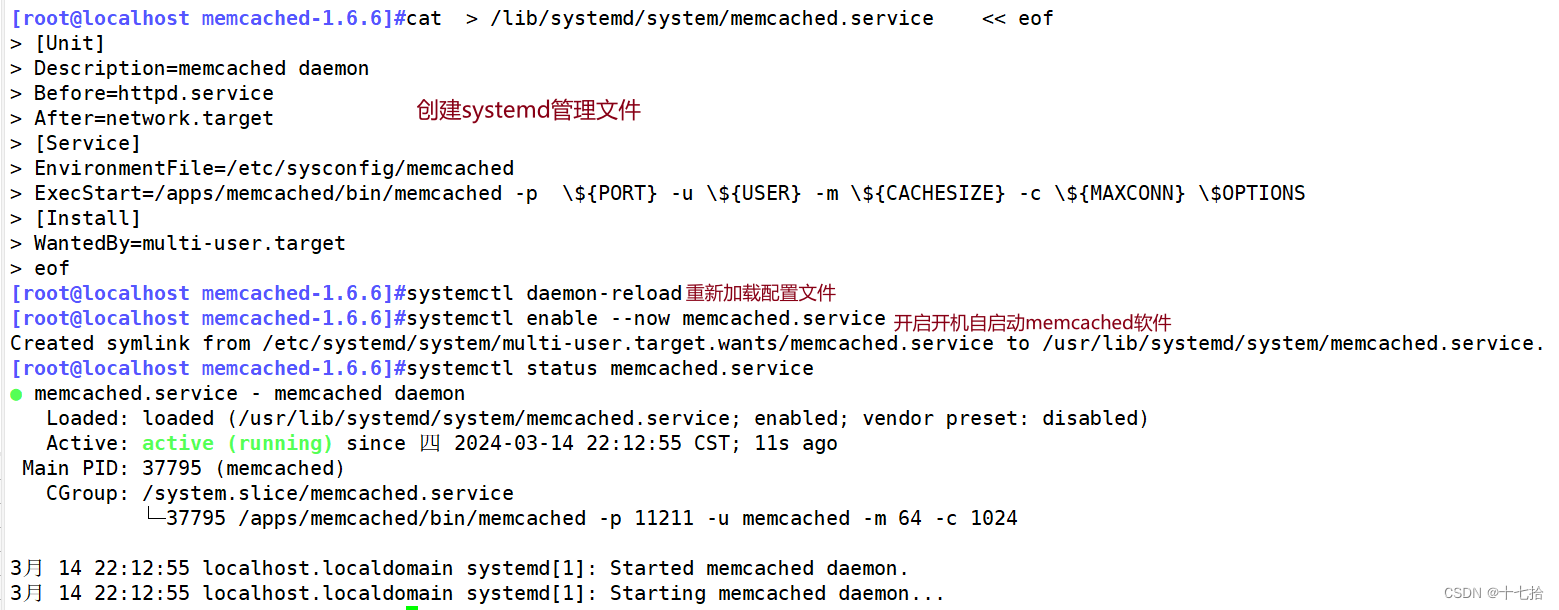
3、memcached选项
[root@localhost ~]#memcached -h #查询memcached选项及其用法
memcached 1.4.15
-p <num> TCP port number to listen on (default: 11211)
-U <num> UDP port number to listen on (default: 11211, 0 is off)
-s <file> UNIX socket path to listen on (disables network support)
-a <mask> access mask for UNIX socket, in octal (default: 0700)
-l <addr> interface to listen on (default: INADDR_ANY, all addresses)
<addr> may be specified as host:port. If you don't specify
a port number, the value you specified with -p or -U is
used. You may specify multiple addresses separated by comma
or by using -l multiple times
-d run as a daemon
-r maximize core file limit
-u <username> assume identity of <username> (only when run as root)
-m <num> max memory to use for items in megabytes (default: 64 MB)
-M return error on memory exhausted (rather than removing items)
-c <num> max simultaneous connections (default: 1024)
-k lock down all paged memory. Note that there is a
limit on how much memory you may lock. Trying to
allocate more than that would fail, so be sure you
set the limit correctly for the user you started
the daemon with (not for -u <username> user;
under sh this is done with 'ulimit -S -l NUM_KB').
-v verbose (print errors/warnings while in event loop)
-vv very verbose (also print client commands/reponses)
-vvv extremely verbose (also print internal state transitions)
-h print this help and exit
-i print memcached and libevent license
-P <file> save PID in <file>, only used with -d option
-f <factor> chunk size growth factor (default: 1.25)
-n <bytes> minimum space allocated for key+value+flags (default: 48)
-L Try to use large memory pages (if available). Increasing
the memory page size could reduce the number of TLB misses
and improve the performance. In order to get large pages
from the OS, memcached will allocate the total item-cache
in one large chunk.
-D <char> Use <char> as the delimiter between key prefixes and IDs.
This is used for per-prefix stats reporting. The default is
":" (colon). If this option is specified, stats collection
is turned on automatically; if not, then it may be turned on
by sending the "stats detail on" command to the server.
-t <num> number of threads to use (default: 4)
-R Maximum number of requests per event, limits the number of
requests process for a given connection to prevent
starvation (default: 20)
-C Disable use of CAS
-b <num> Set the backlog queue limit (default: 1024)
-B Binding protocol - one of ascii, binary, or auto (default)
-I Override the size of each slab page. Adjusts max item size
(default: 1mb, min: 1k, max: 128m)
-S Turn on Sasl authentication
-o Comma separated list of extended or experimental options
- (EXPERIMENTAL) maxconns_fast: immediately close new
connections if over maxconns limit
- hashpower: An integer multiplier for how large the hash
table should be. Can be grown at runtime if not big enough.
Set this based on "STAT hash_power_level" before a
restart.修改memcached 运行参数,可以使用下面的选项修改/etc/sysconfig/memcached文件
| 选项 | 说明 |
|---|---|
| -u | username memcached运行的用户身份,必须普通用户 |
| -p | 绑定的端口,默认11211 |
| -m | num 最大内存,单位MB,默认64MB |
| -c | num 最大连接数,缺省1024 |
| -d | daemon 守护进程方式运行 |
| -f | 增长因子Growth Factor,默认1.25 |
| -v | 详细信息,-vv能看到详细信息 |
| -M | 使用内存直到耗尽,不许LRU |
| -U | 设置UDP监听端口,0表示禁用UDP |
[root@localhost ~]#memcached -u memcached -m 1024 -c 65536 -f 2 -vv
#设置默认前台执行,
-u memcached:设置 Memcached 以 memcached 用户身份运行
-m 1024:为 Memcached 分配最大内存为 1024 MB(即1GB),用于缓存数据
-c 65536:设置最大并发连接数为 65536,这意味着同时可以有这么多的客户端连接到 Memcached 实例
-f 2:设置核心文件大小限制,这里的“2”表示如果 Memcached 进程崩溃,将创建一个大小为当前内存两倍的核心转储文件,以便于调试。但在一些系统中,这个参数可能已经被弃用或不支持
-vv:开启详细模式(verbose mode),让 Memcached 在运行时输出更多的信息和日志
[root@localhost ~]#memcached -u memcached -m 1024 -c 65536 -d
#设置默认后台执行,
-d:该选项会让 Memcached 在后台作为守护进程运行(daemonize),这样在终端窗口关闭后,Memcached 服务依然会继续运行,提供缓存服务
4、Memcached的基本使用方法
4.1 Memcached开发库和工具
与memcached通信的不同语言的连接器。libmemcached提供了C库和命令行工具
[root@localhost ~]#yum install libmemcached -y
#安装工具包4.1.1 Memping
检测memcached服务器是否正常工作
[root@localhost ~]#memping --help
memping v1.0
Ping a server to see if it is alive
Current options. A '=' means the option takes a value.
--version
Display the version of the application and then exit.
--help
Display this message and then exit.
--quiet
stderr and stdin will be closed at application startup.
--verbose
Give more details on the progression of the application.
--debug
Provide output only useful for debugging.
--servers=
List which servers you wish to connect to.
--expire=
Set the expire option for the object.
--binary
Switch to binary protocol.
--username=
Username to use for SASL authentication
--password=
Password to use for SASL authentication[root@localhost ~]#memping --servers 172.16.12.10 #检测172.16.12.10设备的memcached服务是否能通
[root@localhost ~]#echo $?
[root@localhost ~]#systemctl stop memcached.service
[root@localhost ~]#memping --servers 172.16.12.10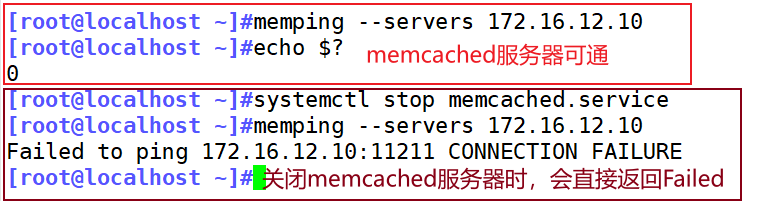
4.1.2 Memstat
用于获取 Memcached 服务的统计信息
[root@localhost ~]#memstat --servers=172.16.12.10
4.2 memcached操作命令
/usr/share/doc/memcached-1.4.15//protocol.txt
#操作命令帮助文档Memcached服务只支持Telnet连接
[root@localhost ~]#yum install -y telnet #安装telnet服务五种基本 memcached 命令执行最简单的操作。这些命令和操作包括:
- set
- add
- flush
- get
- delete
#前三个命令是用于操作存储在 memcached 中的键值对的标准修改命令,都使用如下所示的语法:
command <key> <flags> <expiration time> <bytes>
<value>
#参数说明:
command:一般为set/add/replace
key:key 用于查找缓存值
flags:可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息
expiration time:在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)
bytes:在缓存中存储的字节数
value:存储的值(始终位于第二行)
#如
#增加key,过期时间为秒,bytes为存储数据的字节数
add key flags exptime bytes 4.2.1 显示服务状态
[root@localhost ~]#telnet 172.16.12.10 11211
stats #显示服务状态
stats items #显示各个 slab 中 item 的数目和存储时长(最后一次访问距离现在的秒数)。
stats slabs #用于显示各个slab的信息,包括chunk的大小、数目、使用情况等

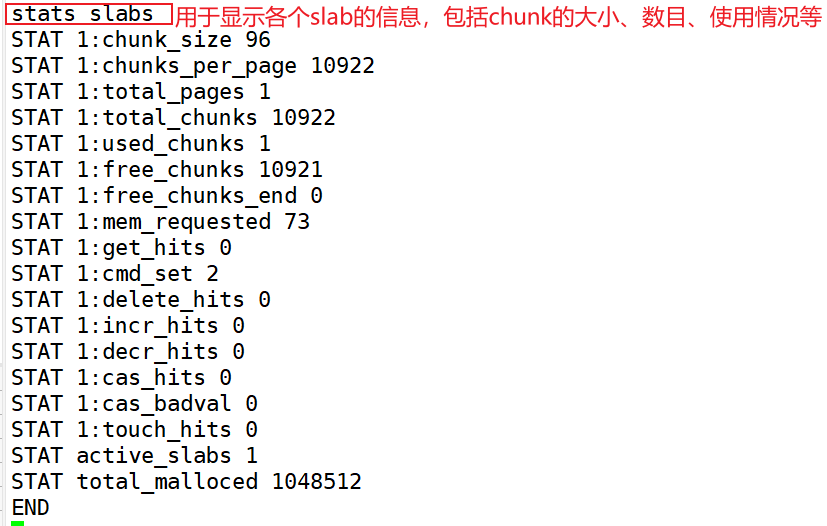
4.2.2 添加数据
[root@localhost ~]#telnet 172.16.12.10 11211
add name 1 10 5
hello
#说明
add 添加
name 键的名字
1 flages标志,描述信息
10 超时时间,默认0秒代表永久有效
4 字节数,数据的大小
hello 具体的值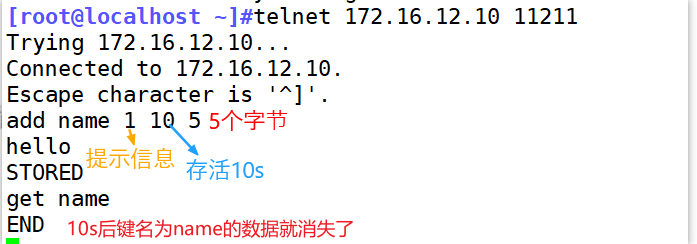
4.2.3 修改数据
set name 1 0 5
#修改键名为name的键,flages标志位1,永不超时,且长度为5字节
world
#修改的内容为world
4.2.4 调用数据
get name
#调用键名为name的数据
4.2.5 删除数据
delete name
#删除键名为name的数据
4.2.6 清空数据
flush_all
#清空所有的数据
三、memcached 集群部署架构
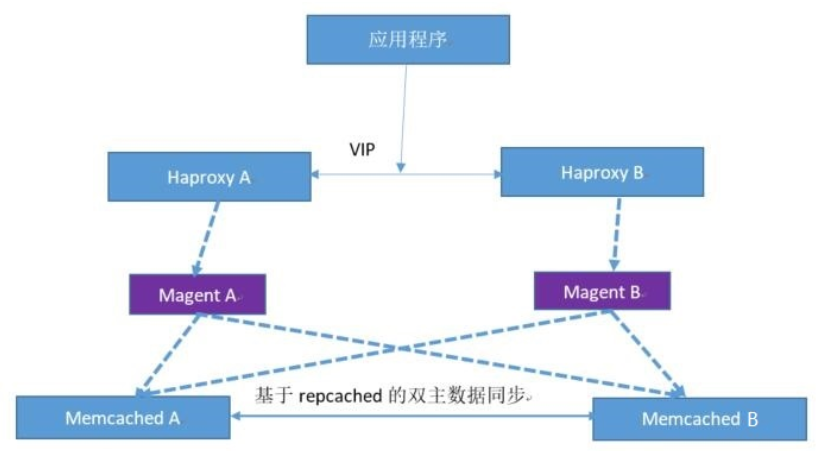
1、基于magent的部署架构
Magent 是google开发的项目,应用端通过负载均衡服务器连接到 magent,然后再由 magent 代理用户应用请求到 memcached 处理,底层的 memcached 为双主结构会自动同步数据,本部署方式存在 magent 单点问题,因此需要两个 magent 做高可用
2、Repcached实现原理
项目站点:http://repcached.sourceforge.net/
在 master上可以通过 -X 选项指定 replication port(默认为11212/tcp),在 slave上通过 -x 指定复制的master并连接,事实上,如果同时指定了 -x/-X, repcached先会尝试连接对端的master,但如果连接失败,它就会用 -X参数来自己 listen(成为master);如果 master坏掉, slave侦测到连接断了,它会自动 listen而成为 master;而如果 slave坏掉,master也会侦测到连接断开,它就会重新 listen等待新的 slave加入。
从这方案的技术实现来看,其实它是一个单 master单 slave的方案,但它的 master/slave都是可读写的,而且可以相互同步,所以从功能上看,也可以认为它是双机 master-master方案
3、简化后的部署架构
magent 已经有很长时间没有更新,因此可以不再使用 magent,直接通过负载均衡连接到memcached,仍然有两台 memcached 做高可用,repcached 版本的 memcached 之间会自动同步数据,以保持数据一致性,即使其中的一台 memcached 故障也不影响业务正常运行,故障的memcached 修复上线后再自动从另外一台同步数据即可保持数据一致性。

4、部署repcached
4.1 memcached服务器1配置
[root@localhost ~]#yum -y install gcc libevent libevent-devel
#安装依赖环境
[root@localhost ~]#cd /opt
[root@localhost opt]#wget https://jaist.dl.sourceforge.net/project/repcached/repcached/2.2.1-1.2.8/memcached-1.2.8-repcached-2.2.1.tar.gz
#可能该网站资源有点问题,需要自己找安装包
[root@localhost opt]#tar xf memcached-1.2.8-repcached-2.2.1.tar.gz
[root@localhost opt]#cd memcached-1.2.8-repcached-2.2.1/
[root@localhost memcached-1.2.8-repcached-2.2.1]#./configure --prefix=/apps/repcached --enable-replication#如果直接执行make会出现如下报错
[root@localhost memcached-1.2.8-repcached-2.2.1]#make

#解决办法是修改源码配置信息
[root@localhost memcached-1.2.8-repcached-2.2.1]#vim memcached.c
#ifndef IOV_MAX
#if defined(__FreeBSD__) || defined(__APPLE__) 删除
# define IOV_MAX 1024
#endif 删除
#endif
#再次编译安装
[root@localhost memcached-1.2.8-repcached-2.2.1]#make -j 2 && make install
[root@localhost memcached-1.2.8-repcached-2.2.1]#ln -s /apps/repcached/bin/memcached /usr/bin/ #作软连接
[root@localhost memcached-1.2.8-repcached-2.2.1]#useradd -r -s /sbin/nologin memcached #创建memcached程序用户![]()
[root@localhost memcached-1.2.8-repcached-2.2.1]#memcached -d -m 1024 -p 11211 -u memcached -c 2048 -x 172.16.12.11![]()
4.2 memcached服务器2配置
#首先需编译安装recached软件,也可以直接远程拷贝编译安装好的recached软件
[root@localhost ~]#rsync -a /apps 172.16.12.11:/
[root@localhost ~]#yum -y install gcc libevent libevent-devel #安装依赖包
[root@localhost ~]#useradd -r -s /sbin/nologin memcached #创建memcached程序用户
[root@localhost ~]#ln -s /apps/repcached/bin/memcached /usr/bin/ #作软链接
4.3 客户端测试
[root@localhost ~]#yum install -y telnet[root@localhost ~]#telnet 172.16.12.11 11211
add name 1 0 4
good
get name
[root@localhost ~]#telnet 172.16.12.10 11211
get name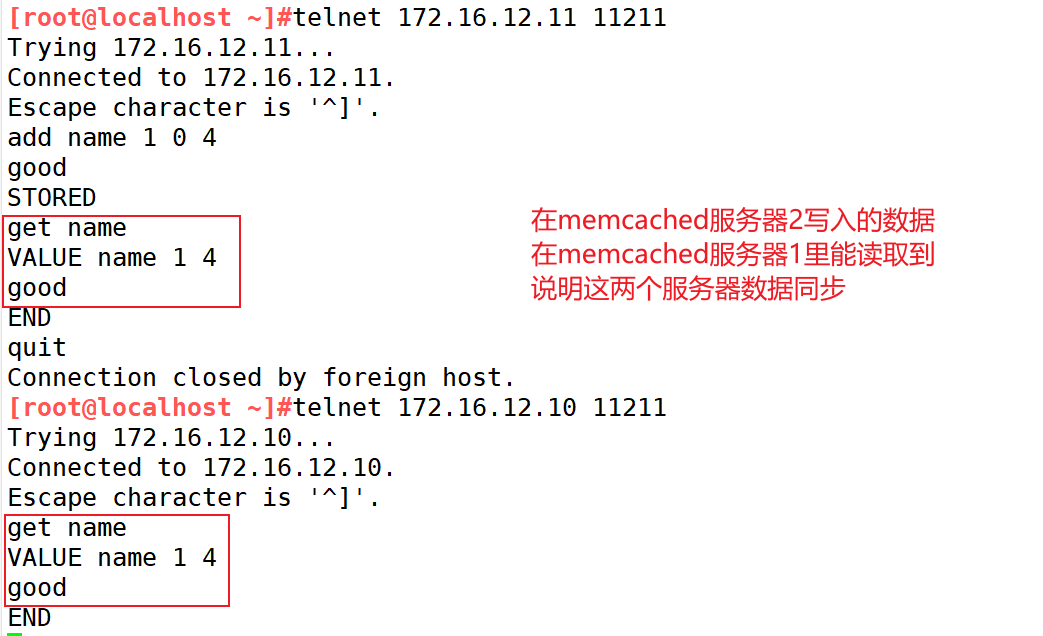
4.4 使用HAProxy高可用部署
HAProxy服务器操作:
[root@localhost ~]#yum install -y haproxy
[root@localhost ~]#systemctl start haproxy.service
[root@localhost ~]#systemctl status haproxy.service#编写haproxy主配置文件
[root@localhost ~]#vim /etc/haproxy/haproxy.cfg
listen memcached
bind 172.16.12.12:11211
mode tcp
server m1 172.16.12.10:11211 check
server m2 172.16.12.11:11211 check
[root@localhost ~]#systemctl restart haproxy.service
[root@localhost ~]#ss -natp | grep 11211
![]()
测试:
[root@localhost ~]#telnet 172.16.12.12 11211
get name
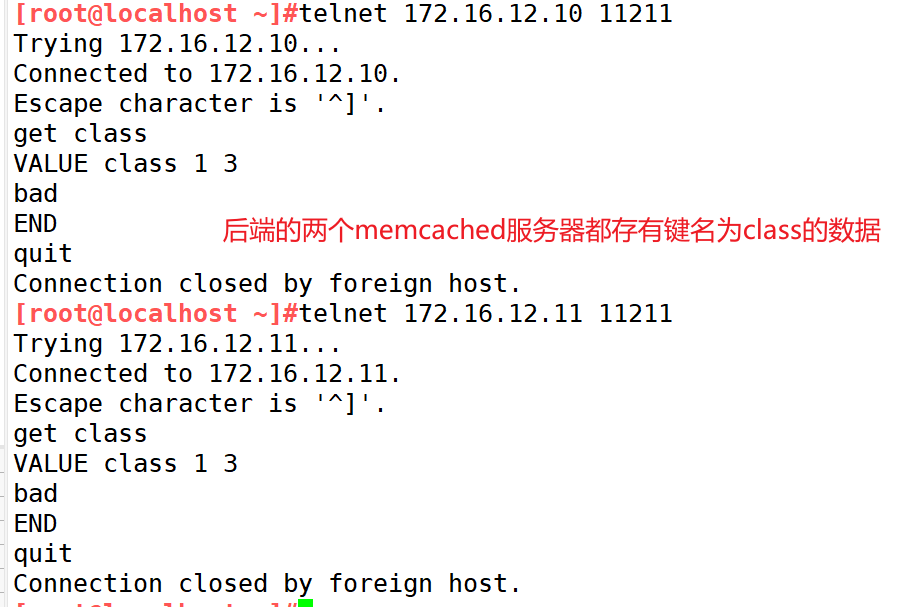
add class 1 0 3
bad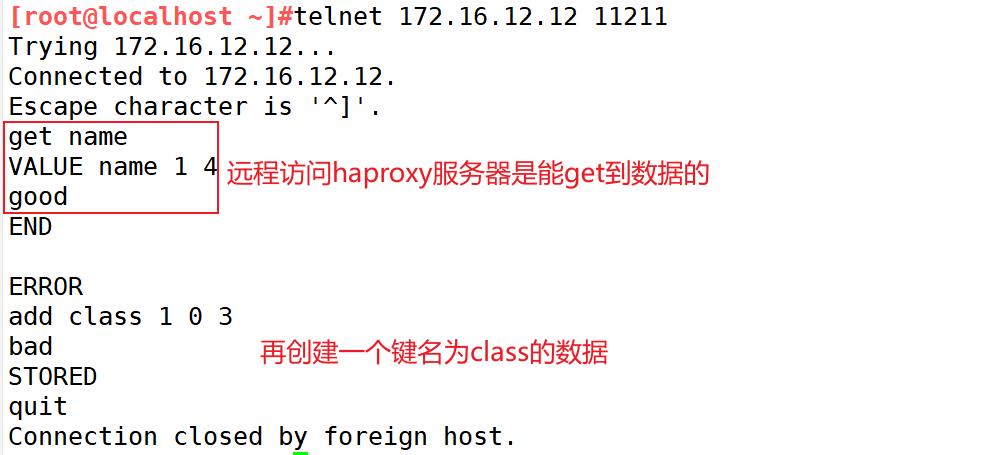
[root@localhost ~]#telnet 172.16.12.10 11211
get class
[root@localhost ~]#telnet 172.16.12.11 11211
get class