二维数组的创建
//数组创建
int arr[3][4];
//三行四列,存放整型变量
double arr[2][4];
二维数组的初始化
我们如果这样初始化,效果是什么样的呢
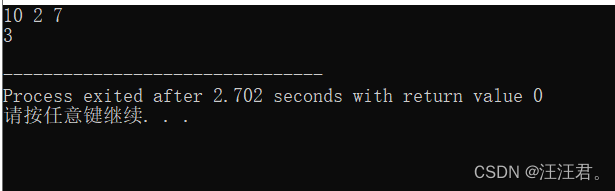
int arr[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };
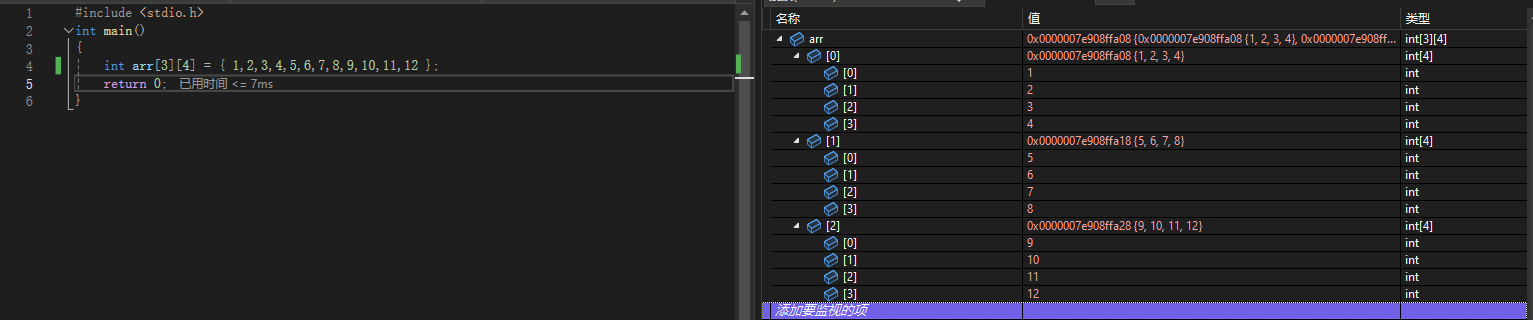
那如果我们不写满十二个呢
int arr[3][4] = { 1,2,3,4,5,6,7};
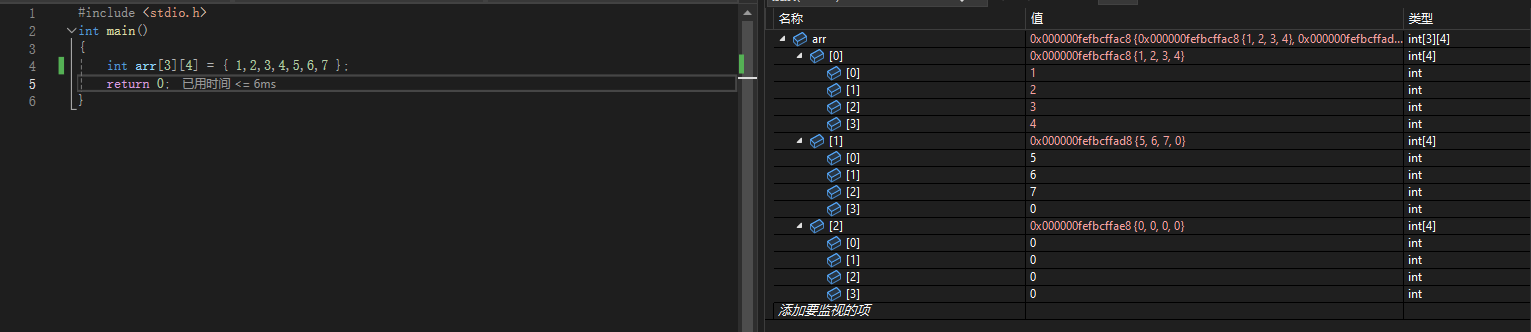
不完全初始化,后面默认补0
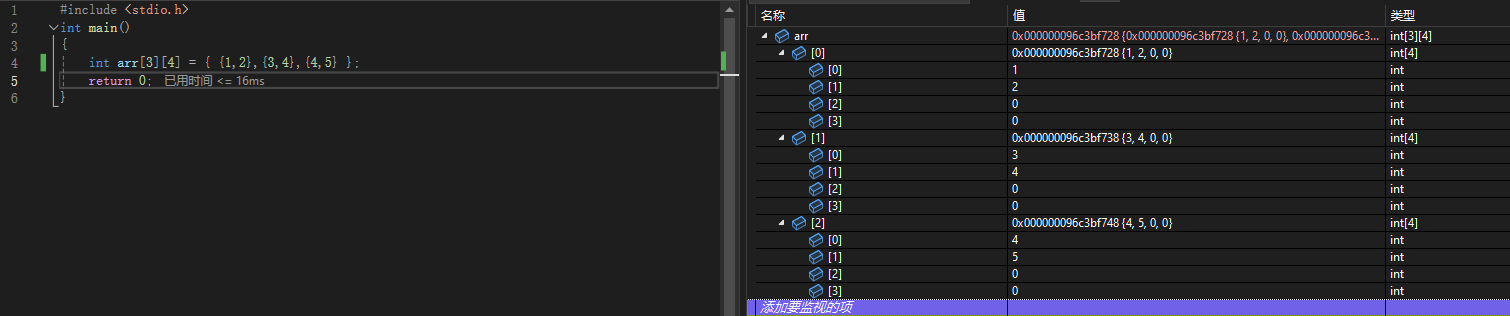
那我们如何按行初始化呢?
int arr[3][4] = {{1,2},{3,4},{4,5}};
二维数组可以省略行吗
int arr[][4] = {{1,2},{3,4},{4,5}};
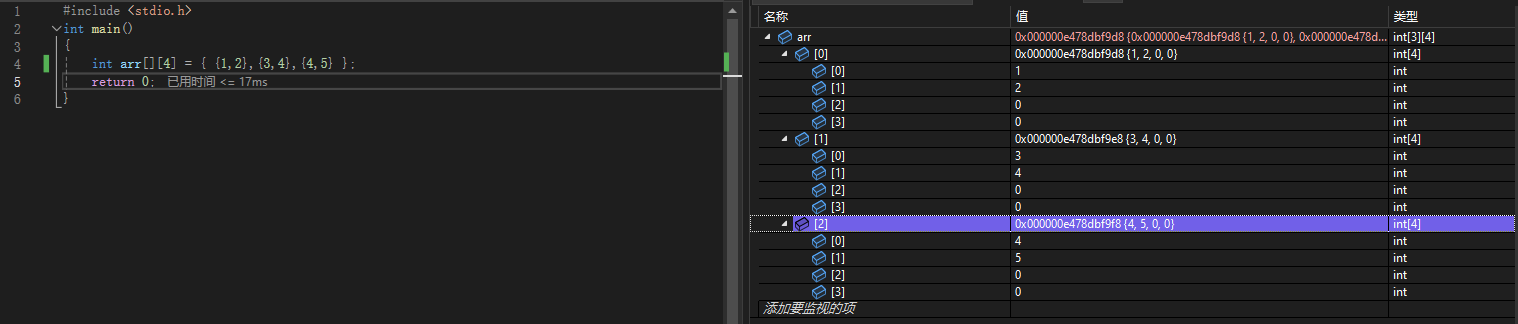
所以有几行可以根据初始化的元素来判断,但是有几列无法判断
不可以省略列数,但是可以省略行数
二维数组的使用
这里有一点需要我们注意一下,二维数组的行和列(下标)和一维数组(下标)一样,都是从0开始
所以我们只要有了行列的坐标,就可以精确找到这个数字
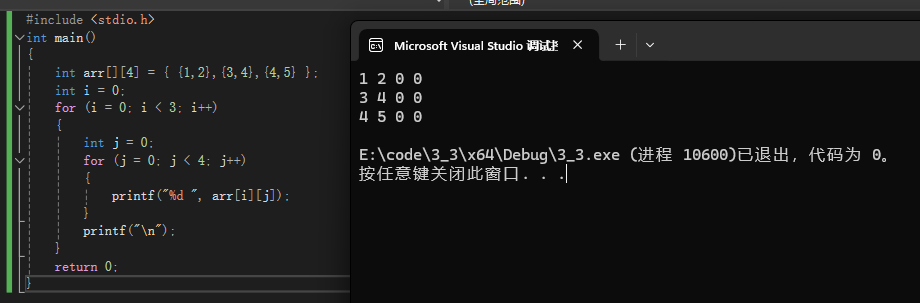
我们通过行和列的双重循环是不是就可以打印出二维数组中所有的元素呢
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
我们来看运行效果
二维数组在内存中的存储
是怎么样存储的呢?
我们还是和一维数组一样,把二维数组的地址都打印下来
#include <stdio.h>
int main()
{
int arr[3][4];
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}
看结果
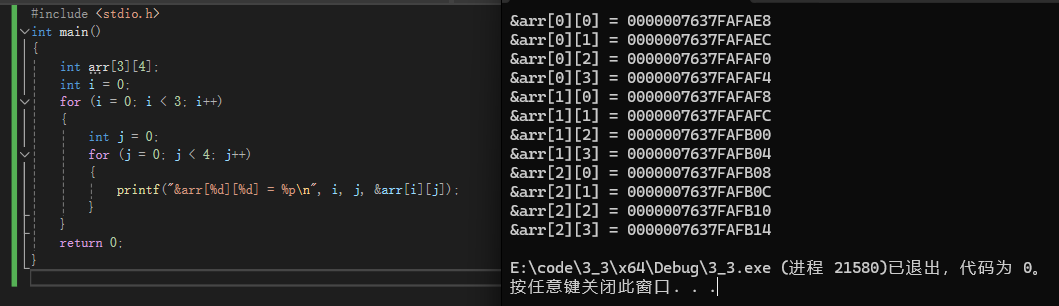
我们注意一下就能发现,每两个数组元素之间的地址都差了4
正好是我们所储存的一个整型变量的空间
所以就说明:
二维数组在内存中也是连续存放的,换行也是连续的
那么我们在回到刚刚的问题,为什么行数可以省略,而列数不能省略呢?
因为地址存放是连续的,有几行直接往后加就行,但是我们如果不知道有几列,就不知道下一行开始时候的地址,所以就无法进行存储
那如果二维数组在内存中是连续的,我们是不是可以通过地址来打印呢?
#include <stdio.h>
int main()
{
int arr[][4] = {{1,2},{3,4},{4,5}};
int i = 0;
int* p = &arr[0][0];
for (i = 0; i < 12; i++)
{
printf("%d", *p);
p++;
}
return 0;
}
看结果
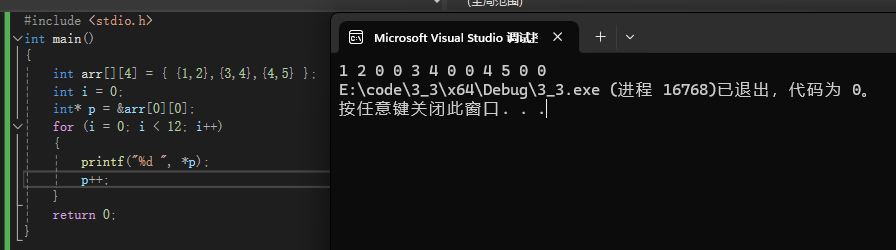
其实我们可以这么理解
我现在有一个二维数组
arr[3][4]
那么每一个数组名就是
| arr[0] [0] | arr[0] [1] | arr[0] [2] | arr[0] [3] |
|---|---|---|---|
| arr[1] [0] | arr[1] [1] | arr[1] [2] | arr[1] [3] |
| arr[2] [0] | arr[2] [1] | arr[2] [2] | arr[2] [3] |
我们其实也可以把第一行的元素看成数组名为arr[0]的一维数组,下标为[0],[1],[2],[3]
下面几行也是
所以二维数组也可以这么理解
数组越界
数组的下标是有范围限制的。
数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就 是正确的,
所以程序员写代码时,最好自己做越界的检查。
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i=0; i<=10; i++)
{
printf("%d\n", arr[i]);//当i等于10的时候,越界访问了
}
return 0;
}
二维数组的行和列也可能存在越界。
数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传个函数,比如:我要实现一个冒泡排序(这里要讲算法 思想)函数将一个整形数组排序。
int main()
{
int arr[] = {9,8,7,6,5,4,3,2,1,0};
//排序为升序
return 0;
}
好的,那么我们开始写一下冒泡排序
bubble_sort(int arr[])
{
}
int main()
{
int arr[] = {9,8,7,6,5,4,3,2,1,0};
bubble_sort(arr);
return 0;
}
什么是冒泡排序呢?
思想:
两两相邻的元素进行比较,并且可能的话需要交换
9 8 7 6 5 4 3 2 1 0
8 9 7 6 5 4 3 2 1 0
8 7 9 6 5 4 3 2 1 0
…
8 7 6 5 4 3 2 1 0 9
一趟冒泡排序后,有一个数字一定来到他最终应该在的位置上
一趟解决一个数组
8 7 6 5 4 3 2 1 0 9
7 8 6 5 4 3 2 1 0 9
7 6 8 5 4 3 2 1 0 9
…
7 6 5 4 3 2 1 0 8 9
十个数字就需要就趟排序,n个数字就需要n-1趟排序
所以我们来写函数
bubble_sort(int arr[])
{
//计算数组元素个数
int sz = sizeof(arr)/sizeof(arr[0]);
//确定趟数
int i = 0;
for(i = 0, i< sz - 1, i++)
//这里的sz - 1就是循环的趟数
{
//一趟冒泡排序的过程
int j = 0;
for(j=0; j<sz-i-1; j++)
//这里的sz-i-1就是每一次比较的个数,每次循环都会把一个数字放在正确的位置,那么我们只需要比较前面的数字就行
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}//这就是冒泡排序
我们来看运行
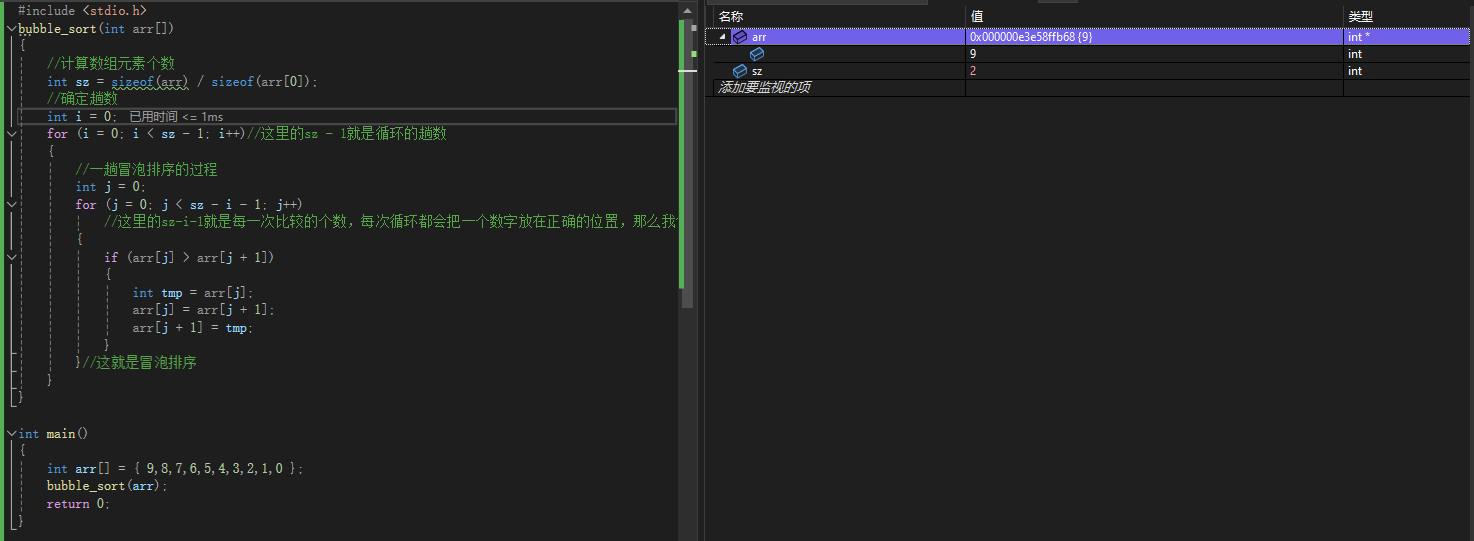
好的我们看到,在这里已经出现问题了,我们在传参的时候并没有传递完整数组
问题出在哪呢?
bubble_sort(int arr[])//arr的本质是指针
int sz = sizeof(arr)/sizeof(arr[0]);//那sizeof(arr)应该是4个字节
bubble_sort(arr);//数组在传参的时候,传递的其实是数组首元素的地址
所以,我们应该在函数外面计算数组的长度,作为参数传递进函数
#include <stdio.h>
bubble_sort(int arr[],int sz)
{
//确定趟数
int i = 0;
for (i = 0; i < sz - 1; i++)//这里的sz - 1就是循环的趟数
{
//一趟冒泡排序的过程
int j = 0;
for (j = 0; j < sz - i - 1; j++)
//这里的sz-i-1就是每一次比较的个数,每次循环都会把一个数字放在正确的位置,那么我们只需要比较前面的数字就行
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}//这就是冒泡排序
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
//计算数组元素个数
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
return 0;
}
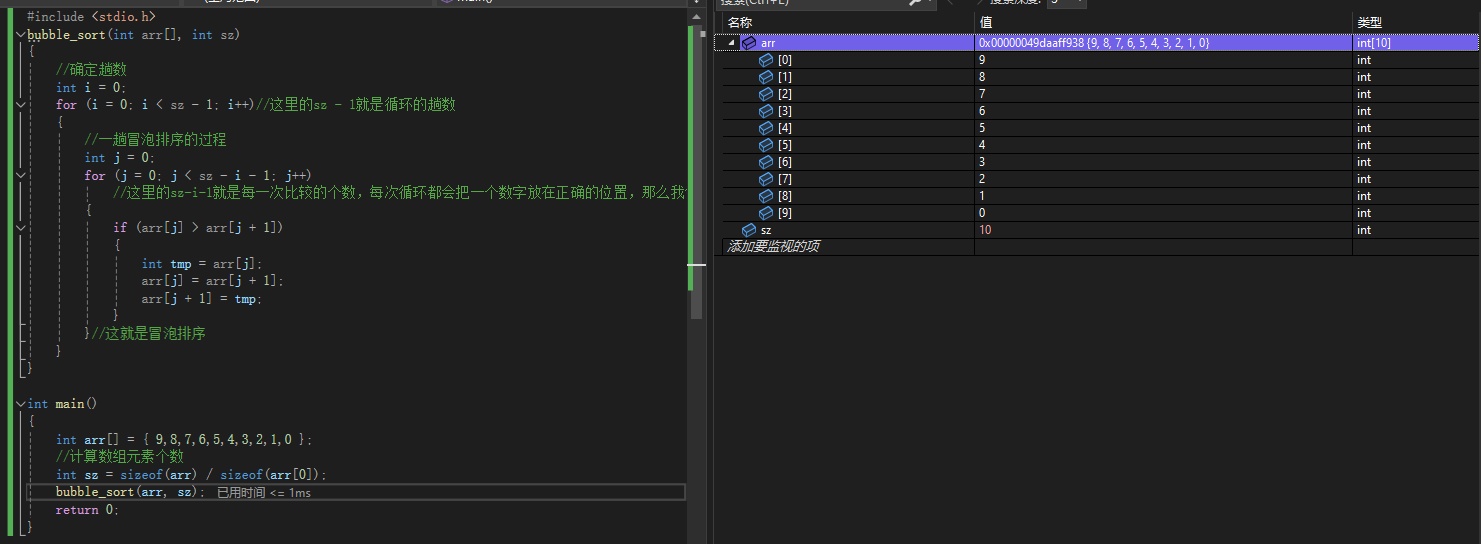
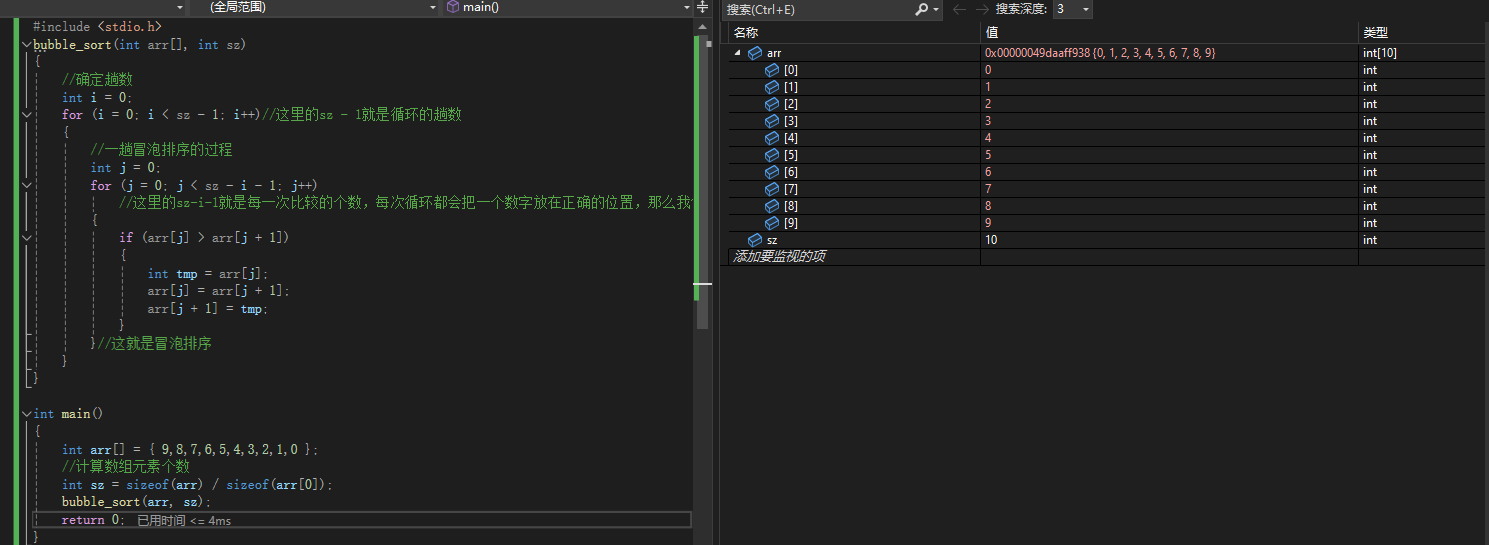
成功!
还有几个问题值得探讨一下
数组名是什么?
数组名是数组首元素的地址
但是有两个例外
- sizeof(数组名) 数组名表示数组 计算的是整个数组的大小
- &数组名 数组名表示的是整个数组 取出的是整个数组的地址
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr);
printf("%p\n", &arr);
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%d\n", sz);
return 0;
}
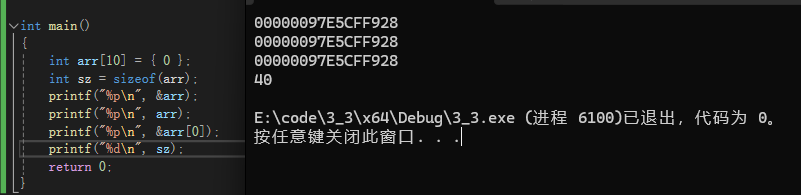
最后一个很好理解,为什么前三个地址都相同呢?
首先,数组名就是首元素地址,所以第二行和第三行相同是没错的
但是第一行,&arr取出的实际上是数组的地址
只是数组的地址和数组首元素的地址是相同的
怎么去理解呢?
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr);
printf("%p\n", &arr);
printf("%p\n", &arr + 1);
printf("%p\n", arr);
printf("%p\n", arr + 1);
return 0;
}
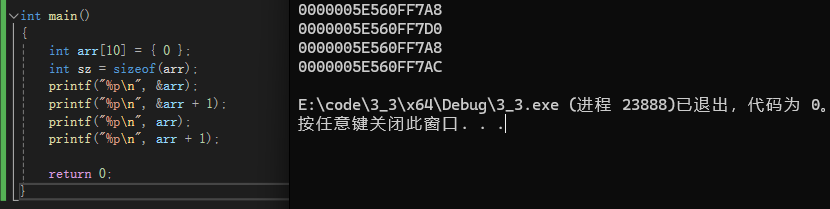
我们很明显能看出来,数组地址的下一个地址和上一个差了A8-D0,转换成10进制就是40个字节
而数组首元素的下一个地址和本身只是差了4个字节
所以说虽然他们看起来一样,但是实际上表达的含义是不一样的
所以当数组以形参传到函数内部时,是无法计算元素个数的