前言
无论是在 lamda 架构还是 kappa 架构中,实时计算通常是使用 flink+mq 来实现的,而在这些场景中涉及到多张表 join 时,一般我们的使用方法是多张流表 join 如:Regular Join、Interval Join,或者流表 + 维表的方式 join 如:Temporal join。但无论是那种方式都会存在一些问题,比如窗口开的过小,数据晚到导致数据丢失。窗口开的过大,内存占用过高,成本高,有被打爆的风险。上篇文章介绍了我们使用 Apache Spark Sql + Apache Hudi 做的近实时数仓架构,在这里主要讲下 Apache Spark Sql + Apache Hudi在近实时数仓建设时遇到多表 join 怎么以宽表部分列更新的方式解决离线数仓高延迟 join。
Apache Hudi 部分列更新特性
目前最新版本的 Apache Hudi (0.12.2)内置了很多 payload,通过 payload 我们可以实现复杂场景下定制化的数据写入方式,大大增加了数据处理的灵活性,比如本片文章我们要介绍的部分列更新功能。
要使用部分列更新的 payload,在建表时我们需要配置以下参数
create table bi_ods_real.ods_hudi_test (
id int,
name string,
price double,
gmt_modified bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'gmt_modified',
hoodie.compaction.payload.class= 'org.apache.hudi.common.model.PartialUpdateAvroPayload',
hoodie.datasource.write.payload.class='org.apache.hudi.common.model.PartialUpdateAvroPayload'
);
primaryKey: 为该表的主键,必须要配置,可以自己根据业务自定义配置preCombineField:预合并字段,在插入前进行数据去重时,根据preCombineField判断多条相同的primaryKey记录哪条数据为最新的数据hoodie.compaction.payload.class: 必须指定部分列更新类org.apache.hudi.common.model.PartialUpdateAvroPayloadhoodie.datasource.write.payload.class: 必须指定部分列更新类org.apache.hudi.common.model.PartialUpdateAvroPayload
增加以上配置后,我们对该表进行如下操作
insert into bi_ods_real.ods_hudi_test values (1,'电视机',1999,0);
>1 电视机 1999.0 0
insert into bi_ods_real.ods_hudi_test values (1,null,2000,1);
>1 电视机 2000.0 1
insert into bi_ods_real.ods_hudi_test values (1,'电视机二代',null,2);
>1 电视机二代 2000.0 2
通过上面的命令和其对应表数据可以看出,将不需要更新的列的值设置为 null,我们即可实现了表的部分列更新。
Tip: 需要注意的是这里的 insert into 命令并不是执行插入操作,在不配置任何参数时会自动转换为 upsert 操作
Apache Hudi 使用 Spark sql 读取表的数据
使用 spark 读取 hudi 表数据有多种方式,但是使用 spark sql 读取增量数据时一直没有支持。所以我新增了几种读取方式,其它方式有一些局限性,在这里只介绍我当前一直使用的 call copy_to_temp_view
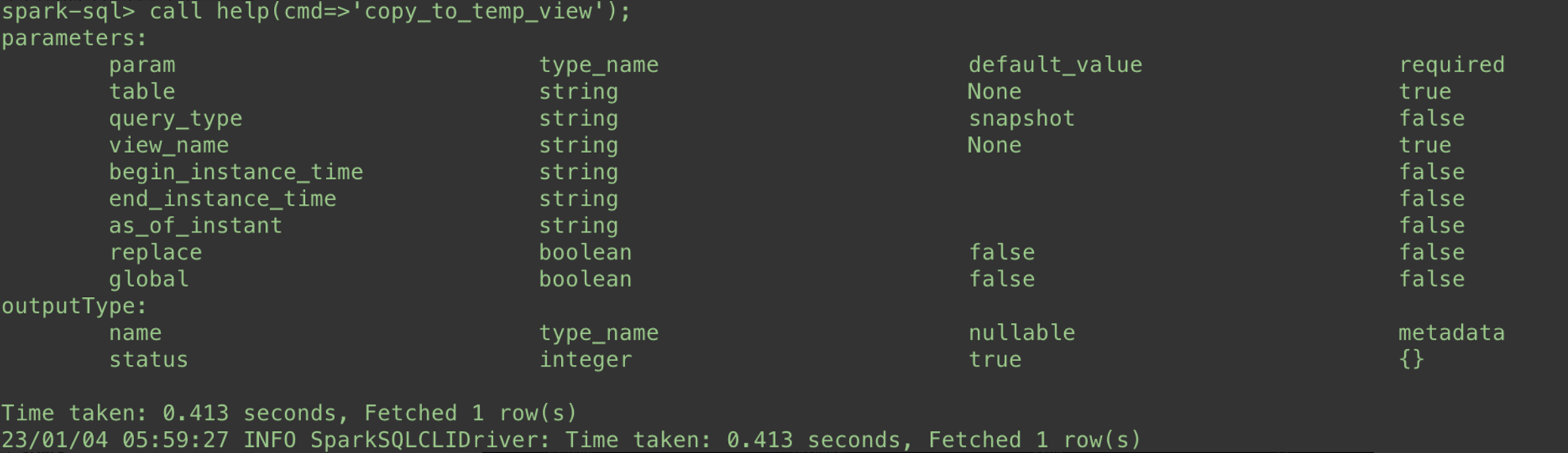
参数介绍
table: 要读取的hudi表query_type: 读取方式,支持快照读(snapshot),增量读(incremental)和读优化(read_optimized)`view_name: 将hudi表数据注册的临时视图名称,自定义即可begin_instance_time: 当query_type='incremental'时,配置的起始时间end_instance_time: 当query_type='incremental'时,配置的结束时间as_of_instant: 当query_type='snapshot'时,配置的时间旅行的时间replace: 当spark session中存在相同的view_name时,是否要替换旧的global: 是否配置注册为跨spark session的临时视图表
该命令可以将 hudi 表的注册到 spark session 临时视图表
具体使用方式如下:
# read snapshot data from hudi table
call copy_to_temp_view(table=>'$tableName',view_name=>'$viewName',query_type=>'snapshot',as_of_instant=>'20221018055647688')
select * from $viewName
# read incremental data from hudi table
call copy_to_temp_view(table=>'$tableName',view_name=>'$viewName',query_type=>'incremental',begin_instance_time=>'20221018055647688')
select * from $viewName
# read read_optimized data from hudi table
call copy_to_temp_view(table=>'$tableName',view_name=>'$viewName',query_type=>'read_optimized')
select * from $viewName
近实时宽表建设之主键一致
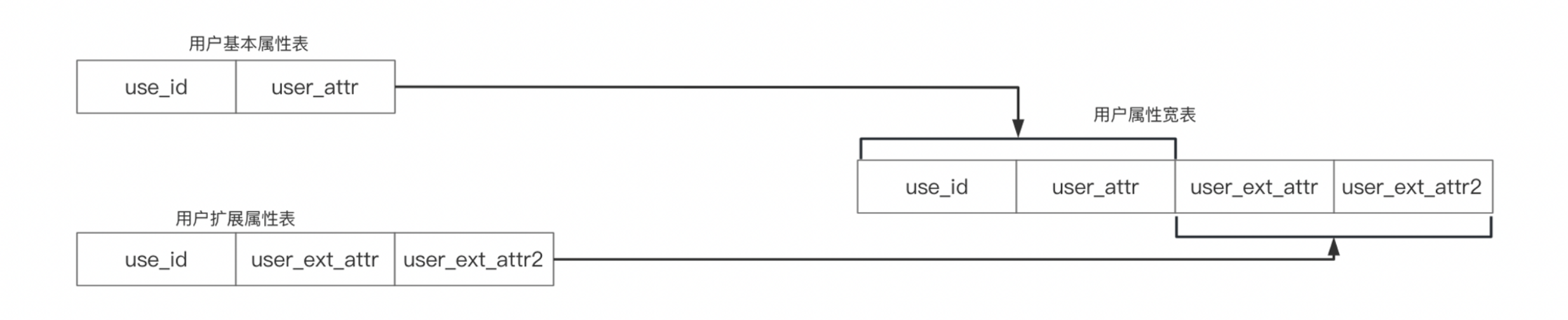
在上图中,我们有两个维表,用户基本属性表和用户扩展属性表,并且它们的主键相同。在近实时场景中,我们需要将其合并成一个用户属性宽表,此时我们应该如何来做呢?
假设我们已经使用 spark + hudi 完成了 ods 层的近实时数据抽取, 宽表如果使用离线全量计算的思想时,我们可能会使用如下方式
//创建宽表
create external table if not exists bi_dw.dim_user (
user_id string comment '用户id',
user_attr string comment '用户基本属性',
user_ext_attr string comment '用户扩展属性1',
user_ext_attr2 string comment '用户扩展属性2',
)
comment '用户宽表'
partitioned by (dt string comment '按天分区')
stored as parquet
location '/tmp/bi/bi_dw/dim_user';
// 获取用户基本属性表当天最新数据
with user as (
select user_id ,user_attr from bi_ods.ods_user where dt='${yyyymmdd}'
),
// 获取用户扩展属性表当天最新数据
user_ext as (
select user_id ,user_ext_attr,user_ext_attr2 from bi_ods.ods_user_ext where dt='${yyyymmdd}'
)
//更新用户宽表最新数据
insert overwrite table bi_dw.dim_user PARTITION(dt = '${yyyymmdd}')
select
user.user_id,user.user_attr,user_ext.user_ext_attr,user_ext.user_ext_attr2
from
user
left join
user_ext
on
user.user_id=user_ext.user_id
通过上面的 ETL SQL,我们就使用离线全量计算的思想完成了用户宽表的更新。但是该种方式有很多弊端,比如 (1):近实时计算在调度上一般为 5-30 分钟一次,上面 SQL 每次走的都是全量insert overwrite ,当主表数据量过大时,可能在一个调度周期内任务未执行完成,导致数据计算延迟 (2):无论维表数据是否变更,全量 insert overwrite 都存在,造成资源浪费
那么在使用 spark + hudi 的近实时计算时怎么处理该场景呢?
//新建用户近实时宽表
CREATE TABLE IF NOT EXISTS bi_dw_real.dim_user_rt (
user_id string comment '用户id',
user_attr string comment '用户基本属性',
user_ext_attr string comment '用户扩展属性1',
user_ext_attr2 string comment '用户扩展属性2',
gmt_create bigint COMMENT '创建时间戳',
gmt_modified bigint COMMENT '修改时间戳',
dt STRING COMMENT '分区字段'
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'user_id',
preCombineField = 'gmt_modified',
hoodie.compaction.payload.class= 'org.apache.hudi.common.model.PartialUpdateAvroPayload',
hoodie.datasource.write.payload.class='org.apache.hudi.common.model.PartialUpdateAvroPayload'
)
PARTITIONED BY (dt)
COMMENT '用户属性宽表';
-- 获取用户基本属性表最近的增量数据
call copy_to_temp_view(table=>'bi_ods_real.ods_user_rt',view_name=>'user_view',query_type=>'incremental',begin_instance_time=>'${taskBeginTime}',end_instance_time=>'${next10minuteTime}');
-- 获取用户扩展属性表最近的增量数据
call copy_to_temp_view(table=>'bi_ods_real.ods_user_ext_rt',view_name=>'user_ext_view',query_type=>'incremental',begin_instance_time=>'${taskBeginTime}',end_instance_time=>'${next10minuteTime}');
-- 将两张表的增量数据插入宽表
insert into bi_dw_real.dim_user_rt
select
user_id,user_attr,null as user_ext_attr,null as user_ext_attr2,gmt_create,gmt_modified,case when length(gmt_create)=10 then date_format(from_unixtime(gmt_create),'yyyyMM') when length(gmt_create)=13 then date_format(from_unixtime(gmt_create/1000),'yyyyMM') else '197001' end as dt
from
user_view
union all
select
user_id,null as user_attr,user_ext_attr,user_ext_attr2,gmt_create,gmt_modified,case when length(gmt_create)=10 then date_format(from_unixtime(gmt_create),'yyyyMM') when length(gmt_create)=13 then date_format(from_unixtime(gmt_create/1000),'yyyyMM') else '197001' end as dt
from
user_ext_view
如上的 SQL,我们新建一张根据 dt 字段进行分区的近实时的 hudi 宽表 bi_dw_real.dim_user_rt, 并在 tblproperties 中增加部分列更新的配置项。
然后使用 copy_to_temp_view 的 call procedure 命令将 bi_ods_real.ods_user_rt 、bi_ods_real.ods_user_ext_rt 表的增量数据分别注册到临时视图表 user_view 和 user_ext_view 。
最后将两张表的增量数据进行 union all, 插入到宽表中。其中 user_view、user_ext_view 表的数据在读取时分别设置另外一张表的字段为 null 即可,hudi 在预合并阶段(preCombine)会对相同 user_id 的数据根据 preCombineField 配置的字段选择较新的记录,并根据这两条比较的记录生成一条新的填充 null 字段后的新记录。
通过如上方式,我们通过 hudi+部分列更新 的方式完成了宽表的建设。其中有一点需要注意,在第一次执行时,需要把 bi_ods_real.ods_user_rt 和 bi_ods_real.ods_user_ext_rt 的全量数据初始化进来,初始化方式也很简单,将上面的 call copy_to_temp_view 修改为注册两张表的 snapshot 数据视图即可。初始化之后,即可修改为增量计算。
call copy_to_temp_view(table=>'bi_ods_real.ods_user_rt',view_name=>'user_view',query_type=>'snapshot');
call copy_to_temp_view(table=>'bi_ods_real.ods_user_ext_rt',view_name=>'user_ext_view',query_type=>'snapshot');
近实时宽表建设之主键不一致
上面讲了宽表中维表主键一致的情况,那么对于维表主键和主表不一致的情况我们要如何做呢?
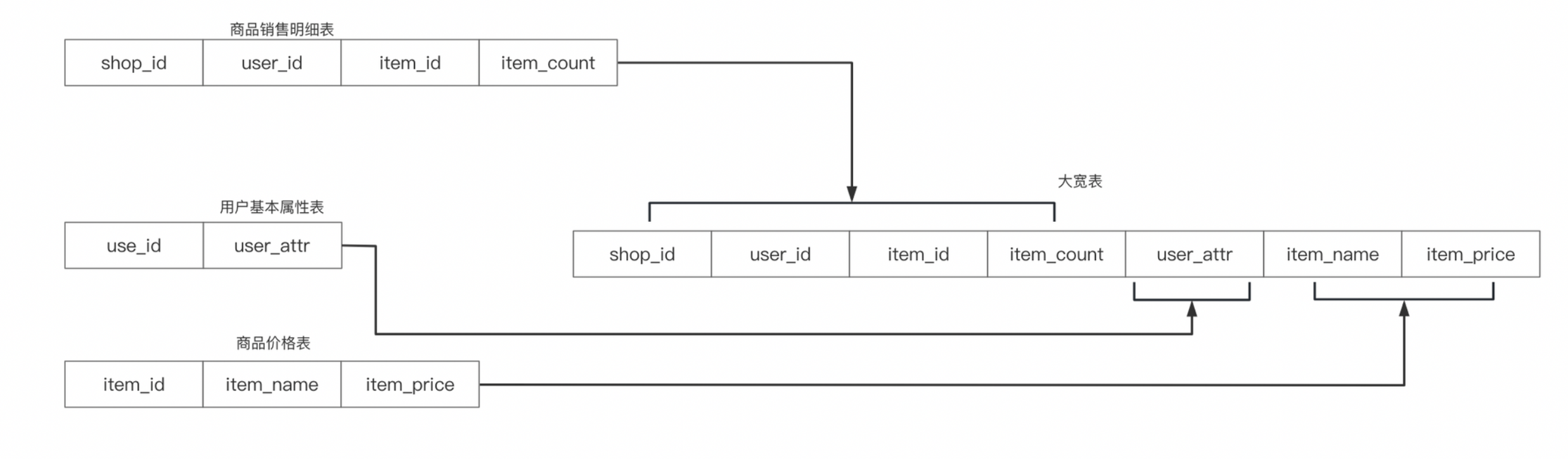
如上图所示,我们有商品销售明细表、用户基本属性表和商品价格表,数仓需要根据这三张表创建一张商品销售的大宽表供下游业务使用,其中用户基本属性维表和商品价格维表的主键和商品销售明细表的主键不一致,这种情况下,我们使用 hudi+部分列更新 更新时需要做一些改变
CREATE TABLE IF NOT EXISTS bi_dw_real.dwd_sale_rt (
shop_id bigint NOT NULL COMMENT 'shop_id',
user_id bigint NOT NULL COMMENT 'user_id',
item_id bigint NOT NULL COMMENT 'item_id',
item_count bigint NOT NULL COMMENT 'item_count',
user_attr string NOT NULL COMMENT '用户基本属性',
user_gmt_modified bigint COMMENT '用户基本属性更新时间戳',
item_name string NOT NULL COMMENT '商品名称',
item_price bigint NOT NULL COMMENT '商品价格',
item_gmt_modified bigint COMMENT '商品更新时间戳',
gmt_modified bigint COMMENT '主表更新时间戳',
dt STRING COMMENT '分区字段'
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'shop_id',
preCombineField = 'gmt_modified',
hoodie.compaction.payload.class= 'org.apache.hudi.common.model.PartialUpdateAvroPayload',
hoodie.datasource.write.payload.class='org.apache.hudi.common.model.PartialUpdateAvroPayload'
)
PARTITIONED BY (dt)
COMMENT '商品销售大宽表';
-- 获取商品销售明细表最近10分钟的增量数据
call copy_to_temp_view(table=>'bi_ods_real.ods_sale_detail_rt',view_name=>'sale_view',query_type=>'incremental',begin_instance_time=>'${taskBeginTime}',end_instance_time=>'${next10minuteTime}'));
-- 新增主表商品数据到宽表
insert into bi_dw_real.dwd_sale_rt
select
shop_id,user_id,item_id,item_count
null as user_attr,null as user_gmt_modified,
null as item_name,null as item_price,null as item_gmt_modified,
gmt_modified ,date_format(from_unixtime(gmt_create),'yyyyMM') as dt
from
sale_view;
// 获取用户维表的全量数据
call copy_to_temp_view(table=>'bi_ods_real.ods_user_rt',view_name=>'user_view',query_type=>'snapshot');
// 获取价格维表的全量数据
call copy_to_temp_view(table=>'bi_ods_real.ods_item_price_rt',view_name=>'price_view',query_type=>'snapshot');
-- 通过 join 过滤出需要更新的数据插入宽表
insert into bi_dw_real.dwd_sale_rt
select
shop_id,user_id,item_id,item_count
user_view.user_attr,user_view.gmt_modified as user_gmt_modified,
price_view.item_name,price_view.item_price,price_view.gmt_modified as item_gmt_modified,
dwd_sale_rt.gmt_modified , date_format(from_unixtime(dwd_sale_rt.gmt_create),'yyyymmddhh') as dt
from
dwd_sale_rt
left join
user_view
on
ods_user_rt.user_id = dwd_sale_rt.user_id and (dwd_sale_rt.user_gmt_modified is null or dwd_sale_rt.user_gmt_modified < ods_user_rt.gmt_modified)
left join
price_view
on
price_view.item_id = dwd_sale_rt.item_id and (dwd_sale_rt.item_gmt_modified is null or dwd_sale_rt.item_gmt_modified < price_view.gmt_modified)
where
dwd_sale_rt.dt='${yyyymmddhh}' and user_view.user_id is not null or price_view.item_id is not null;
通过宽表的建表语句,我们可以发现新增了 user_gmt_modified 和 item_gmt_modified 两个字段,这两个字段分别表示两张表维表列的更新时间。
首先需要获取商品销售明细表的增量数据,然后把这些增量数据插入到宽表中。
下一步需要读取宽表的所有数据做为主表,使用 left join 获取维表列的值,最后通过 where 过滤掉没有 join 上的数据。
通过上面的一系列操作,我们就完成了宽表中维表列的增量更新。
这里有两个要解释的地方:
- 维表
join条件需要根据维表的gmt_modified时间和宽表中的维表更新时间进行比较,只有大于或者宽表的字段为null时才更新 where条件需要过滤掉维表没有join上的记录
上面的这些操作是为了只更新受影响的行,避免所有行的覆盖写。
后记
本文介绍了 spark + hudi 实现近实时计算时,对于相同主键和不同主键情况下的宽表建设。由于是在 spark 3.2 + hudi 0.12.2的版本下进行操作,后续版本可能会增加更加灵活方便的方式,希望各位读者留意一下。比如获取 hudi 表的增量数据,社区目前已经有很多种实现的 PR,但是截止到 0.12.2 还是使用上面的 copy_to_temp_view 较方便,该命令是 hudi 内置的命令,理论上无 spark 版本的限制,其它方式多多少少有些局限性,这里就不再介绍。另外,对于不同主键的宽表建设每次要读取原表的全量数据,也是比较影响性能的一点,后续 hudi 增加了 query index 之后应该会有新的解法,大家一起期待。











![[JavaEE初阶] 线程安全问题之内存可见性问题----volatile](https://img-blog.csdnimg.cn/1a9c6c9cb3164e4aa9929bc0b45715e6.png)