文章目录
- 显隐特征融合的指静脉识别网络
- 总结
- 摘要
- 介绍
- 显隐式特征融合网络(EIFNet)
- 掩膜生成模块(MGM)
- 掩膜特征提取模块(MFEM)
- 内容特征提取模块(CFEM)
- 特征融合模块(FFM)
- THUFVS
- 实验和结果
- 数据集
- 实现细节
- 评估掩膜生成模型
- 消融实验
- FFM模块
- 门控层
- Batch Size
- 损失函数超参数选择
论文 EIFNet: An Explicit and Implicit Feature Fusion Network for Finger Vein Verification
显隐特征融合的指静脉识别网络
总结
这是一个基于深度学习的指静脉识别方法。从任务类型上说是分类任务。
传统方法分为显式和隐式方法,这里的显式和隐式应该是从人的角度或者说人眼的角度,如血管分割二值掩膜这种人可以清楚识别并且理解其含义的就是显式特征。那么以人为例,首先识别出容易清晰的容易理解的特征,然后根据这种特征完成匹配,是直觉性的做法。因此从直觉上来说给网络提供一个显式特征,或者说给网络的特征提取规定一个良好的标准答案,会增强效果。
因此为了得到二值掩膜这一补充信息,要通过一个U-net做一个分割任务。而两种特征要做融合,因此有了中间平行的融合模块。而作者基于特征层次与卷积层深度相关这个认识,用门控层将特征前后分开,并用其对不同层次特征加权。网络使用非常基础的组件,基本全是卷积层,夹杂一小部分池化层。两个分支间是解耦的,即两种特征不会相互作用在彼此的提取过程中,这样能够更好的互补,而不是重复训练一种单一的特征。如果不解耦,例如通过已有的二值Mask引导下方分支的提取,那么相当于是在重复提取显性特征。
数据增强包括对比度亮度变换,MixUP策略。MixUP用来生成更多的样本,应该只在训练MGM时使用。
这种显式特征可以被叫做人眼感知的特征,对于传统方法来说,输出有一定可解释性方便我们评估方法的准确性,也就是人无法直接判断隐性特征的优劣,所以自然会选择发展显性特征。这种显性特征可以被称作人眼感知的特征,这种和人类对齐的方法是否有效,尤其是在这种特殊图像下,例如调节亮度和对比度可以显著提升人眼的识别效率,但对于网络来说,可能只是一个图像值的简单的线性变换,并没有那么必要对数据做过多处理。以人的先验或者已知的定律对网络做约束,一定条件下应该是有效的,因为除了网络自身的学习能力外,数据多少训练策略等也会影响到网络最后的能力,因此人的先验作为一种预训练很有可能是有效的。
问题
首先得到显性特征的网络是单独训练的,而且使用了额外的数据集,是否相对于其他方法不公平。预训练的ResNet,ViT等如果用作特征提取似乎没有问题,但是使用任务相关的数据集去做预训练是否合理。从图上来看,门控层是串联在干路上,即下一层特征提取要受上一层门控的控制,按照我的理解,门控应该控制往支路即特征融合模块中的信息流动,而不是和干路耦合在一起,导致特征融合和特征提取互相影响,虽然可能实验表明这样更加有效。
摘要
指静脉识别因其高安全性和发展前景在近年受到很多关注。但是从很难从低对比度的原始图片中提取完全的指纹模式,大大限制了指静脉识别算法的表现。收到这一动机的启发,我们提出了一种显式和隐式特征融合网络EIFNet,它可以通过互补融合从二值血管掩膜和原始灰度图像中提取更易理解和区分度的特征。我们设计了一个特征融合模块(FFM)作为掩膜特征提取模块(FFM)和上下文特征提取模块(CFEM)之间的桥梁来实现特征的优化融合。为了获取更加准确的血管掩膜,我们发展了一种新的指血管模式提取方法并且提供了第一个指静脉分割数据集THUFVS。我们还以一种简单有效的方法解决了建立指静脉分割数据集的问题,并发展了一个完整的流程包括数据集建立,数据增强和网络设计,称为掩膜生成模块,对于基于深度学习的指静脉模式提取方法。实验结果表明EIFNet在三个广泛使用的数据集上相比于其他现存的优越表现。
介绍
指静脉识别通常使用近红外相机采集。当血液中的血红蛋白吸收近红外光时,静脉在拍摄的图像中显示为暗线。指静脉识别技术上的优势总结如下(1)自然活体检测:必须对活体手指进行图像采集(2)稳定性高:手指静脉位于手指内部,不易受到外部环境的破坏。(3)高安全性:作为人体内的内部特征,指静脉有效放置了身份信息的丢失和遗忘。
存在很多指静脉识别算法,可以被总结为基于显式特征和隐式特征的方法。基于显式特征的方法主要关注于提取血管模式基于生成的掩膜进行匹配。由于指静脉图片的低对比度,因此并没有手工标注的指静脉分割标签。因此,大多数这些算法是通过检测谷状特征来提取血管模式的传统方法,例如重复线形跟踪(RLT),局部最大曲率点(LMC),主曲率(PC)和现状特征,例如Gabor滤波器,宽线检测器(WLD)。别的方法从原始指静脉图片中直接提取特征进行匹配。大多数的方法基于深度学习,例如卷积自编码器,双流网络,FVRAS-Net,因为深度神经网络相比于传统算法更加鲁棒和强大。
然而,指静脉成像的质量受限于一些因素,如无接触的图片采集,个人皮肤颜色,光照分布和手指粗细导致了低对比度的静脉图像包含了复杂的背景存在如噪声和皮肤纹理在内的冗余信息。
显隐式特征融合网络(EIFNet)
显隐式特征融合网络有两股信息流,一个分支表达隐性特征(从原始输入图片中提取的特征),一个分支表达显性特征(即掩膜生成器产生的掩膜)。这两个分支分别称作内容特征提取模块和掩膜特征提取模块,这两种特征间的特征融合是通过平行的两个特征融合块完成的,以混合完成的特征作为最终提取到的特征。图中所有垂直对齐的卷积块参数设置相同参考下面的表。

掩膜生成模块(MGM)
掩膜生成模块是一个U-net,同时使用了卷积注意力(CBAM)模块。因为没有公开的指静脉分割数据集,因此使用作者提出的THUFVS进行训练。每个下采样单元后接一个CBAM。
损失函数:
L
m
a
s
k
=
L
C
E
+
L
D
i
c
e
+
λ
L
p
\mathcal{L}_{mask} = \mathcal{L}_{CE}+\mathcal{L}_{Dice}+\lambda\mathcal{L}_p
Lmask=LCE+LDice+λLp
L
p
\mathcal{L}_p
Lp是惩罚项,定义为
L
p
=
l
o
g
∑
i
=
1
N
s
i
^
∑
i
=
1
N
y
i
\mathcal{L}_p = log\frac{\sum_{i = 1}^{N}\hat{s_i}}{\sum_{i = 1}^{N}{y_i}}
Lp=log∑i=1Nyi∑i=1Nsi^
N
N
N是所有训练batch的总像素数,
s
^
i
\hat{s}_i
s^i是一个batch预测的掩膜图像第
i
i
i个像素值。这一项用来限制生成额外错误的血管,当生成mask中的点多余GT图像中的点数时提高损失函数的值。
λ
\lambda
λ设置为0.05。

掩膜特征提取模块(MFEM)
似乎只是简单的卷积层堆叠,还有一个门控层,从图上来看这个门控层并不是分支,而是直接串在后面,可能是图没有画完整。

内容特征提取模块(CFEM)
似乎只是简单的卷积层堆叠,具体的卷积参数设置见下图

特征融合模块(FFM)
特征融合模块也是简单的卷积层堆叠。
由于指静脉图像的低对比度,隐式特征的区分性被冗余的背景信息限制。在同时,掩膜很难包含所有的血管模式,导致了特征缺乏有效性。因此,为了实现特征互补和增强指静脉图像的特征表达,我们在FFM融合这两种特征。
为了保持多层次的信息,我们设计了信息融合结点,对应生成 F 1 F_1 F1, F 2 F_2 F2, F 3 F_3 F3。
我们使用对比损失
L
c
o
n
L_{con}
Lcon训练EIFNet。区别于传统方法基于样本的和,对比损失使用样本对进行计算。令
x
i
x_i
xi和
x
j
x_j
xj为训练数据集中的一对输入。当
x
i
x_i
xi和
x
j
x_j
xj 属于同一类时,属于正例对
y
=
1
y=1
y=1,不同类属于负例对
y
=
0
y = 0
y=0。
x
i
x_i
xi和
x
j
x_j
xj之间的距离通过输出特征的欧几里得距离定义
d
(
x
i
,
x
j
)
=
∥
f
(
x
i
)
−
f
(
x
j
)
∥
2
d(x_i,x_j)=\|f(x_i) - f(x_j)\|_2
d(xi,xj)=∥f(xi)−f(xj)∥2
对比损失定义为:
L
c
o
n
=
1
2
B
∑
b
=
1
B
y
d
b
2
+
(
1
−
y
)
m
a
x
(
α
−
d
b
,
0
)
2
\mathcal{L}_{con} = \frac{1}{2B}\sum_{b=1}^{B}yd_b^2+(1-y)max(\alpha-d_b,0)^2
Lcon=2B1b=1∑Bydb2+(1−y)max(α−db,0)2
d
b
d_b
db时第b对样本对,
B
B
B是一个训练batch中总的样本对的总数目,
α
\alpha
α大于0,表示样本
x
x
x的特征距离半径,只有距离小于
α
\alpha
α的负例对会计算损失。当大于
α
\alpha
α损失等于0,并关注于更难得样本对,在这篇文章中
α
\alpha
α设置为2。
THUFVS
我们建立了第一个基于切块得指静脉切割数据集称为THUFVS,并且提供了一个简单有效得方法供研究者建立一个这样的数据集。流程图如下。

1)数据增强:MGM即分割网络在THUFVS上训练,其任务是从不同数据中提取出二值血管模式。THUFVS有以下特性1)血管结构简单稀疏2)切块是有高对比度的血管区域3)图片强度范围大,如过暗或者过曝。为了提升网络的泛化性,数据增强是至关重要的。基于比较,我们将在血管结构和对比度亮度上做了数据增强。
2)Mixup 因为目前没有关于血管结构的数据增强方法,我们提出了一个简单有效的方法。受MIXup想法的启发,使用了成对的图片和标签的凸组合并常用于图像分类。不同于Mixup,我们使用两个标签的结合作为新产生的标签来提升网络在低对比度下分割复杂血管结构的能力。
I
m
=
θ
I
i
+
(
1
−
θ
)
I
j
S
m
=
S
i
∪
S
j
I_m = \theta I_i+(1-\theta)I_j \\ S_m = S_i \cup S_j
Im=θIi+(1−θ)IjSm=Si∪Sj
I
i
I_i
Ii和
I
j
I_j
Ij是两个静脉图像切块,
s
i
,
s
j
s_i,s_j
si,sj是他们的分割标签。
I
m
I_m
Im和
S
m
S_m
Sm是生成的图像切块和标签。
θ
\theta
θ是超参数这里设置为0.5。生成的新样本如下。

实验和结果
数据集
1)USM数据集:数据集包括123个对象,包括每个被采集者双手的中指和食指,因此共有123 x 2 x 2 = 492类别。并且分为两期,每期间隔两个星期。每期每根手指拍摄6张图片,因此总的图片数为492 x 2 x 6 = 5904张。
分辨率为640 x 480 ROI图像尺寸300 x 100。

2)SDUMLA-HMT数据集:包括106个对象的食指,中指和无名指,同样两期,因此共有 106 x 3 x 2 = 636类,
每个手指重复6次,636 x 6 = 3816图片,分辨率320 x 240。
3)MMCBNU_6000数据集:MMCBNU包含100个对象的食指中指无名指,重复10次,因此共有600类别,6000图像,分辨率480 x 640
实现细节
首先我们独立训练MGM,进行灰度变换,对比度变换和mixup等数据增强,不包含模型其他部分。第二阶段,我们在保持MGM参数冻结情况下,训练EIFNet。我们直接使用USM提供的ROI图像和从SDU和MMCBNU中提取出的300x100ROI图像。所有的ROI图像处理成224 x 224。因为我们使用对比损失,因此训练数据是成对送入网络。我们使用随机采样策略,样本属于同类或不同类有相同的概率。每次采样作为一个循环。对于网络测试,每一类三分之一的图像用于测试。两张图片的匹配分数通过欧几里得距离定义。
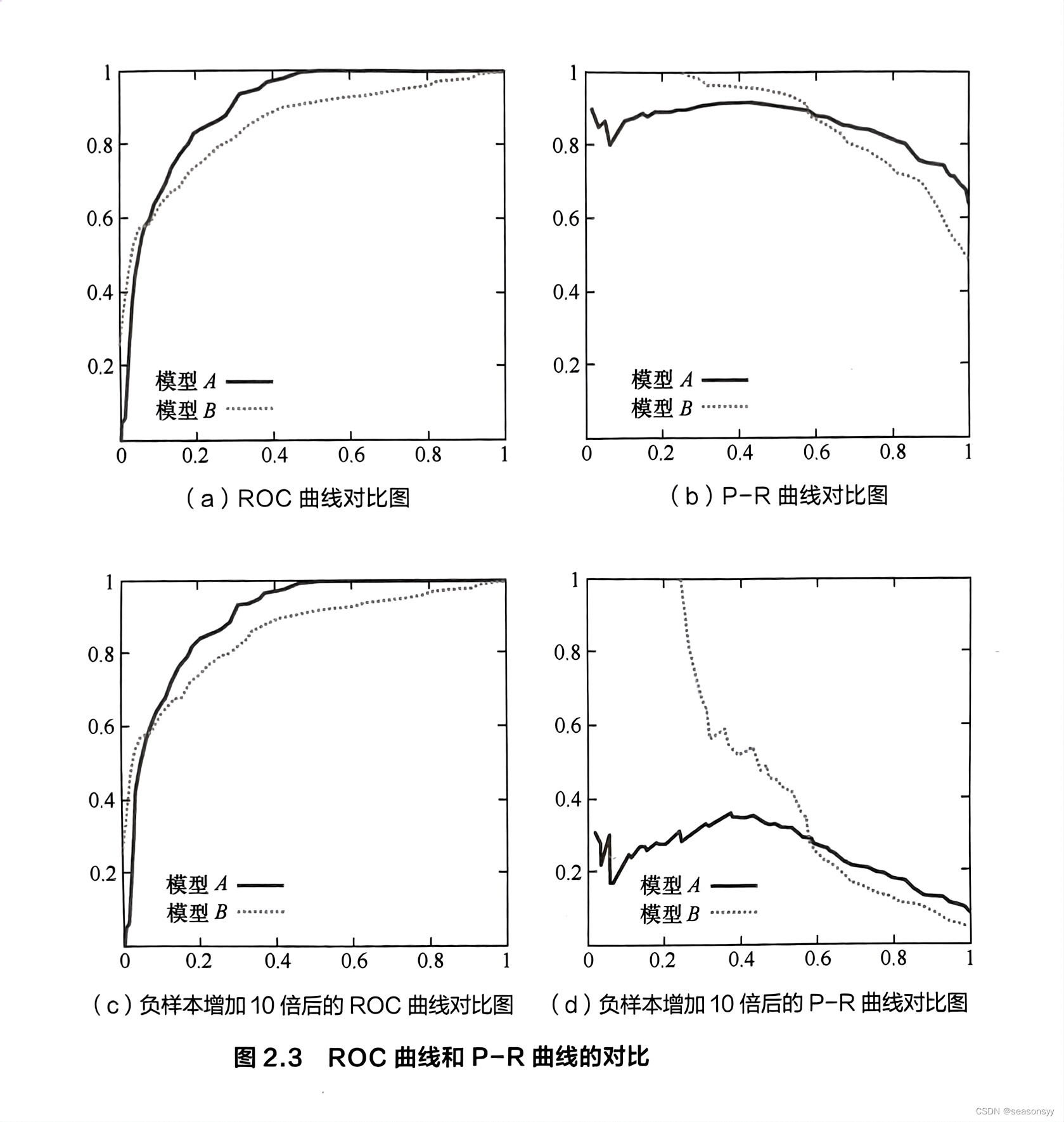
为了更好评估提出方法的表现公平比较其他算法。等错误率(ERR)被用于度量,EER是一个广泛用于生物识别的度量,表示在ROC曲线上错误接受率(FAR)等于错误拒绝率(FRR)的位置。通常来说,更小的EER,更好的系统表现
F
A
R
=
f
a
l
s
e
a
c
c
e
p
t
e
d
i
m
p
o
s
t
e
r
m
a
t
c
h
i
n
g
F
R
R
=
f
a
l
s
e
r
e
j
e
c
t
e
d
g
e
n
u
i
n
e
m
a
t
c
h
i
n
g
FAR = \frac{false\ accepted}{imposter\ matching} \\ FRR = \frac{false\ rejected}{genuine\ matching}
FAR=imposter matchingfalse acceptedFRR=genuine matchingfalse rejected
F A R = F P F P + T P F R R = F N F N + T N FAR = \frac{FP}{FP +TP} \\ FRR = \frac{FN}{FN +TN} FAR=FP+TPFPFRR=FN+TNFN
评估掩膜生成模型
从解剖知识上总结指静脉的结构如下 1)方向性:核心分支和手指几乎平行,其他分支倾斜不同角度2)连续性:从头到尾不断3)粗细变化,核心分支更厚4)光滑和稳定性,每个分支光滑无噪点或者洞。
消融实验

样本间特征距离的分布如图10所示。距离通过欧几里得距离计算,通过图10,我们发现EIFNet使特征更具可分性。
FFM模块
FFFM分为F1,F2,F3。提取不同层次的信息,并且通过F2在中间的桥接,使得底层和高层信息更容易融合,消融实验表明,如果拼接将三者的输出都拼接在一起,会导致相对于只有F3性能都会下降。而F2和F3融合效果最好。作者解释是F1和F2之间的差距比较大,不适合直接拼接在一起。
门控层
作者解释没有门控层的较差结果因为网络深度变浅导致学习能力下降
Batch Size
随着batch_size增加表现变好,但是受限于显存,因此设置为32
损失函数超参数选择
对比损失中的 α \alpha α如果较小,会导致难以区分不同类别。而较大会导致难以训练。 λ \lambda λ是限制MGM生成错误血管的惩罚项,如果太小不能起到限制作用,当达到 λ = 0.5 \lambda = 0.5 λ=0.5时会导致不完整的模式生成。