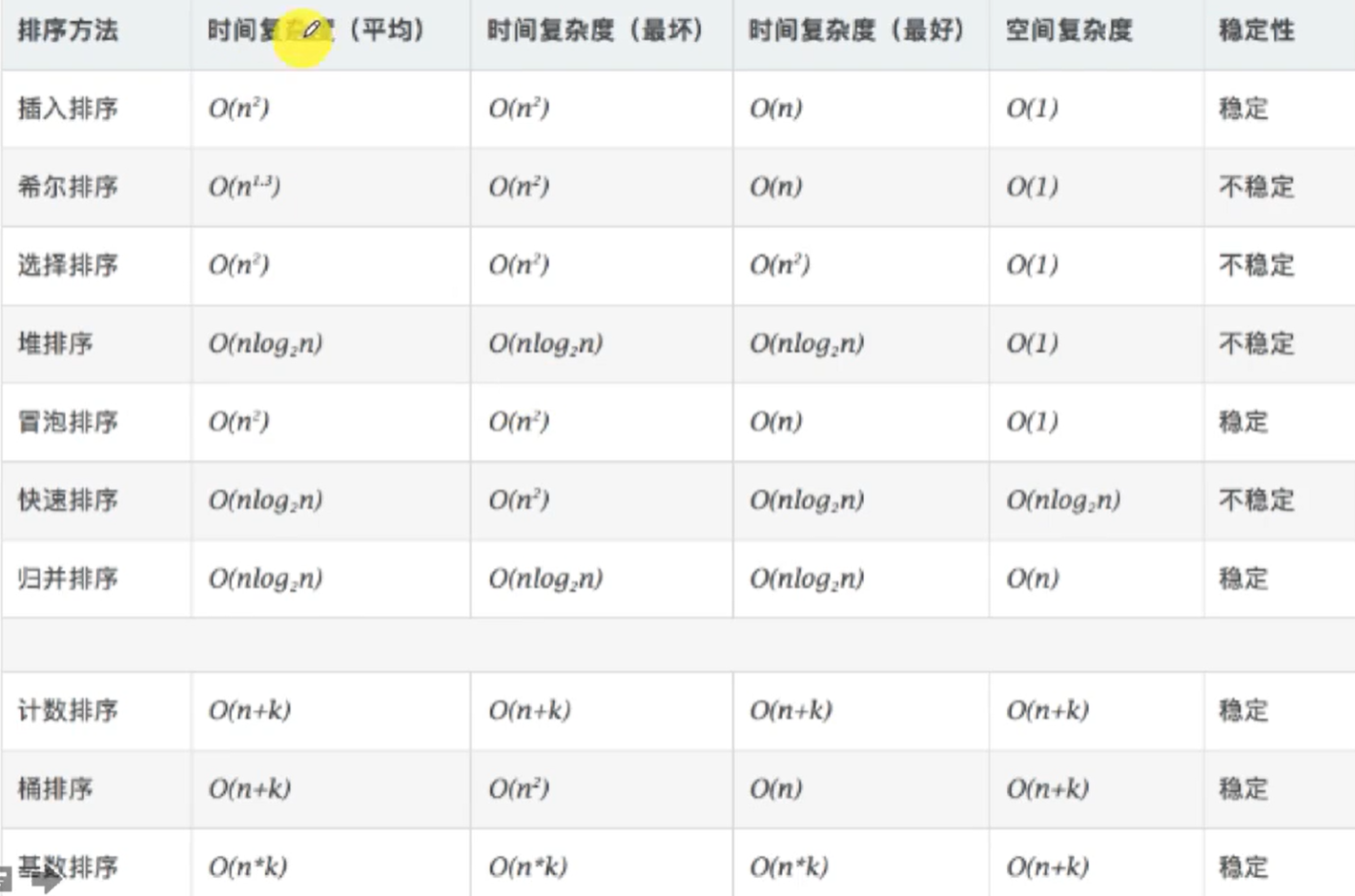
冒泡排序
算法思想:
每次比较相邻元素,若逆序则交换位置,每一趟比较n-1次,确定一个最大值。故需比较n趟,来确定n个数的位置。
- 外循环来表示比较的趟数,每一趟确定一个最大数的位置
- 内循环来表示相邻数字两两比较。

private static void bubble_sort(int[] nums) {
for (int i = 0; i < nums.length; i++){
for (int j = 0; j < nums.length-1; j++){
if (nums[j]>nums[j+1]) {
int temp=nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
}
}
}
}改进:
记录某次遍历时最后发生数据交换的位置pos,这个位置之后的数据显然已经有序了。因此通过记录最后发生数据交换的位置就可以确定下次循环的范围了。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
private static void bubble_sort2(int[] nums) {
for (int i = 0; i < nums.length; i++){
int flag=nums.length-1;
for (int j = 0; j < flag; j++){//扫描的位置
if (nums[j]>nums[j+1]) {
int temp=nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
flag=j;//交换的位置
}
}
}
}- 平均时间复杂度:O(N^2)
- 最佳时间复杂度:O(N)
- 最差时间复杂度:O(N^2)
- 空间复杂度:O(1)
插入排序
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间(去存待插入的元素)的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。

① 从第一个元素开始,该元素可以认为已经被排序
② 取出下一个元素,在已经排序的元素序列中从后向前扫描
③如果该元素(已排序)大于待插入元素,将该元素移到下一位置
④ 重复步骤③,直到找到已排序的元素小于或者等于新元素的位置
⑤将新元素插入到该位置后
⑥ 重复步骤②~⑤
private static void InsertSort(int[] nums) {
for (int i = 1; i <nums.length; i++) {//从第二个元素开始插入
int temp = nums[i];
int j;
for (j=i-1; j >= 0; j--) {//已排好序的是待插入元素之前的,从后往前依次比较
if (temp<nums[j]) nums[j+1]=nums[j];//往后移一位
else break;//找到比待插入元素小的,此时将待插入元素插入此元素的后面
}
nums[j+1]=temp;//将待插入元素插入此元素的后面
}
}改进思路: 在往前找合适的插入位置时采用二分查找的方式,即折半插入。
private static void InsertSort2(int[] nums) {
for (int i = 1; i <nums.length; i++) {//从第二个元素开始插入
int temp = nums[i];
int left = 0;
int right = i-1;
while (left<=right)//找比待插入元素小的元素的位置left
{
int middle = (left+right)/2;
if (nums[middle]>temp)
right = middle-1;
else
left = middle+1;
}
int j;
for (j=i-1; j >= left; j--) {//已排好序的是待插入元素之前的,从后往前依次比较
nums[j+1]=nums[j];//往后移一位
}
nums[j+1]=temp;//将待插入元素插入此元素的后面
}
}- 平均时间复杂度:O(N^2)
- 最差时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 排序方式:In-place
- 稳定性:稳定
希尔排序
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
对相隔某个增量所构成的数组进行插入排序。
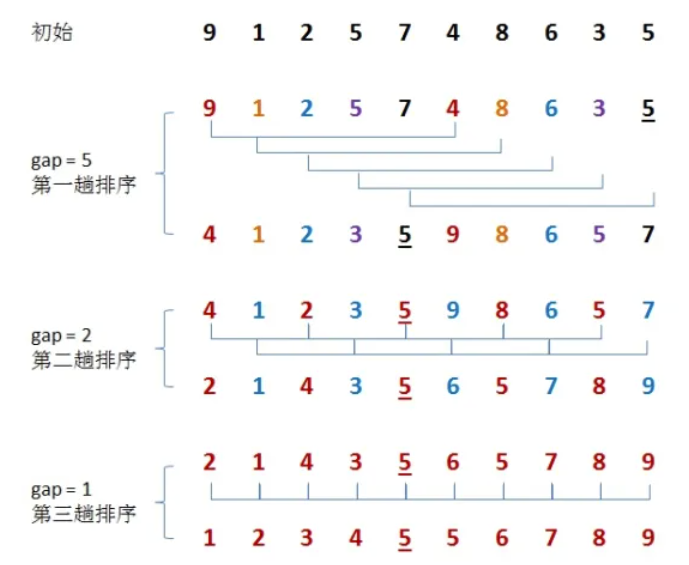
第一趟排序: 设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。接下来,按照直接插入排序的方法对每个组进行排序。
第二趟排序:
将上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为2组。按照直接插入排序的方法对每个组进行排序。
第三趟排序:
再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为1的元素组成一组,即只有一组。按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
private static void Shellsort(int[] nums) {
for (int gap=nums.length/2; gap>0; gap/=2) {//定义间隔
//插入排序
for (int i=gap;i<nums.length;i++) {
int temp=nums[i];
int j;
for (j=i-gap;j>=0;j-=gap) {
if (temp<nums[j]) nums[j+gap]=nums[j];
else break;
}
nums[j+gap]=temp;
}
}
}- 平均时间复杂度:O(Nlog2N)
- 最佳时间复杂度:
- 最差时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
- 复杂性:较复杂
选择排序
首先在序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
特别注意:这里需要将已找到的最小值与已排好序的最后一个进行比较,因此再求最小值时,求最小值的坐标
int min=j;//min用来记录最小值的坐标 for (; j < nums.length; j++) { if (nums[j] < nums[min]) min=j; }
private static void selectSort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int j=i;
int min=j;//min用来记录最小值的坐标
for (; j < nums.length; j++) {
if (nums[j] < nums[min]) min=j;
}
if(nums[min]<nums[i-1]){
int temp=nums[i-1];
nums[i-1]=nums[min];
nums[min]=temp;
}
}
}- 平均时间复杂度:O(N^2)
- 最佳时间复杂度:O(N^2)
- 最差时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 排序方式:In-place
- 稳定性:不稳定
改进方法:上述方法每次只确定一个最小值,可采取每一次比较找出最大值与最小值,同时确定两个值。
快速排序
通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
快速排序使用分治法策略来把一个序列分为两个子序列。
① 从数列中挑出一个元素,称为 “基准值”(以第一个为例)
② 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区操作。在数组的头部和尾部分别设置一个
哨兵,同时向对方走去。尾部的哨兵如发现有比基准数小的数,停下。头部的哨兵如发现有比基准数大的数,停下。交换两个数。再重新走重复前面的交换过程。直到两个哨兵相遇,交换基准数和尾哨兵
③ 递归地把小于基准值元素的子数列和大于基准值元素的子数列排序。
特别注意:若以第一个元素为基准数,在哨兵互走过程需右边的哨兵先走。 原因很好理解,哨兵互走交换的过程就是不断排序的过程。若右边的哨兵先走,不管走多少次,最后相遇时的那个数是小于基准数的。这时与基准数交换,正好分为两个序列。可若是左边的先走,相遇在大于基准数上就不好办了。
private static void quickSort(int[] nums,int start,int end) {
if (start>=end) return;
int pivot = nums[start];
int i=start;
int j=end;
while(i < j){
while (nums[j]>pivot&&i<j) j--;//右哨兵先走
while (nums[i]<=pivot&&i<j) i++;
//以上两个循环找到左侧比pivot大的与右侧比pivot小的
swap(nums,i,j);
}//此循环将比pivot大的分一组,小的分一组
//最终位置,最后一个小于pivot的位置是j指向的
swap(nums,start,j);//将基准值插入中间,即此时j指向pivot的位置
quickSort(nums,start,j-1);
quickSort(nums,j+1,end);
}- 平均时间复杂度:O(NlogN)
- 最佳时间复杂度:O(NlogN)
- 最差时间复杂度:O(N^2)
- 空间复杂度:根据实现方式的不同而不同
快速排序的三指针思想
scan指针:从头到尾扫描元素
equal指针:存与基准值相等的区间的起始位置
big指针:存比基准值大的区间的起始位置
private static void quick_sort3(int []nums,int start,int end){ int scan = start+1; int equal = scan; int big = end; //设置退出条件 if(scan >= big) return ; //选择主元,一般为首元 int num = nums[start]; /* * 当smaller扫描到的数字小于主元,则下标为smaller和equal的需要交换数据,这样就又将小于主元的放在一起了,然后smaller和equal都要自增 * 当smaller扫描到的数字等于主元,直接将smaller自增 * 当smaller扫描到的数字大于主元,就将小标为smaller和bigger上的数据交换,bigger再自减(和单向扫描分区法处理一样) */ while(scan < big) { //注意以下三种情况(互斥)每扫一次,只执行一个if语句(不能三个都执行),故不能少写else if(nums[scan] < num) { swap(nums, equal, scan); equal++; scan++; } else if(nums[scan] == num) { scan++; } else if(nums[scan] > num) { swap(nums, scan, big); big--; } } //交换首元与right上的数 swap(nums,start,equal-1); //继续将right两边的数组进行快速排 quick_sort3(nums,start,equal-2); quick_sort3(nums,big+1,end); }


归并排序
首先把一个未排序的序列从中间分割成2部分,再把2部分分成4部分,依次分割下去,直到分割成一个一个的有序的数据,再把这些有序的数据两两归并到一起,使之有序,不停的归并,最后成为一个排好序的序列。

private static int[] Mergesort(int[] nums) {
if (nums.length<=1) return nums;
int mid= (nums.length-1)/2;
//int []left=Arrays.copyOfRange(nums,0,mid+1);
//int []right=Arrays.copyOfRange(nums,mid+1,nums.length);
int []sortleft =Mergesort(Arrays.copyOfRange(nums,0,mid+1));
int []sortright=Mergesort(Arrays.copyOfRange(nums,mid+1,nums.length));
return merge(sortleft,sortright,nums);
}
private static int[] merge(int[] sortleft, int[] sortright, int[] nums) {
int l=0;
int r=0;
int index=0;
while (l<sortleft.length && r<sortright.length){
if (sortleft[l]<sortright[r]){
nums[index]=sortleft[l];
l++;
index++;
}else {
nums[index]=sortright[r];
r++;
index++;
}
}
while (l<sortleft.length) nums[index++]=sortleft[l++];
while (r<sortright.length) nums[index++]=sortright[r++];
return nums;
} private static int[] mergerSort(int[] nums) {//形成有序数列
if (nums.length <= 1) return nums;
int mid= (nums.length-1)/2;
//划分为两部分
int []left = Arrays.copyOfRange(nums,0,mid+1);
int []right = Arrays.copyOfRange(nums,mid+1,nums.length);
//将左右变为有序数列
int []sortleft = mergerSort(left);
int []sortright = mergerSort(right);
//归并
int m = 0, i = 0, j = 0;
while (i < sortleft.length && j < sortright.length) {
nums[m++] = sortleft[i] < sortright[j] ? sortleft[i++] : sortright[j++];
}
while (i < sortleft.length)
nums[m++] = sortleft[i++];
while (j < sortright.length)
nums[m++] = sortright[j++];
return nums;
}- 平均时间复杂度:O(nlogn)
- 最佳时间复杂度:O(n)
- 最差时间复杂度:O(nlogn)
- 空间复杂度:O(n)
- 排序方式:In-place
- 稳定性:稳定
计数排序
计数排序使用一个额外的数组C,其中第i个元素是待排序数组A中值等于i的元素的个数。
① 找出待排序的数组中最大和最小的元素
② 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
③ 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
④ 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1

private static int[] countSort(int[] nums) {
int min = nums[0];
int max = nums[0];
for (int i = 1; i< nums.length;i++){
if (nums[i] < min) min = nums[i];
if (nums[i] > max) max = nums[i];
}
int [] count = new int[max-min+1];
for (int i=0;i<nums.length;i++){
count[nums[i]-min]++;//count[i]表示nums中i出现的次数。
}
int []newnum =new int[nums.length];
int j=0;
for (int i=0;i<count.length;i++){
while (count[i]>0){
newnum[j++] = i+min;
count[i]--;
}
}
return newnum;
}
桶排序
桶排序假设待排序的一组数均匀独立的分布在一个范围中,并将这一范围划分成几个子范围(每个桶的范围成顺序)。然后基于某种映射函数f ,将待排序列的元素映射到第i个桶中。
映射函数一般是 f = array[i] / k; k^2 = n; n是所有元素个数

private static void bucketSort(int[] nums) {
int n = nums.length;
if (n <= 0)
return;
ArrayList<Integer>[] bucket = new ArrayList[n];
// 创建空桶
for (int i = 0; i < n; i++)
bucket[i] = new ArrayList<Integer>();
// 根据规则将序列中元素分散到桶中,每个桶之间的大小区间有顺序
for (int i = 0; i < n; i++) {
int bucketIndex = (int) (nums[i] / Math.sqrt(n));//映射函数
bucket[bucketIndex].add(nums[i]);
}
// 对各个桶内的元素进行排序
for (int i = 0; i < n; i++) {
Collections.sort((bucket[i]));
}
// 合并所有桶内的元素
int index = 0;
for (int i = 0; i < n; i++) {
for (int j = 0, size = bucket[i].size(); j < size; j++) {
nums[index++] = bucket[i].get(j);
}
}
}- 平均时间复杂度:O(n + k)
- 最佳时间复杂度:O(n + k)
- 最差时间复杂度:O(n ^ 2)
- 空间复杂度:O(n * k)
- 稳定性:稳定
基数排序
原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
① 将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。
② 从最低位开始,依次进行一次排序。
③ 这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。

private static void RadixSort(int[] nums) {
int maxlen=maxIndex(nums);
int radix=1;
for (int i=0; i<maxlen; i++){//位数等于排序次数
//桶排序
ArrayList<Integer> []lists= new ArrayList[10];
for (int j=0; j< 10; j++) lists[j]=new ArrayList<>();
for (int j=0;j< nums.length;j++){
lists[(nums[j]/radix)%10].add(nums[j]);
}
for (int j=0;j<10;j++) Collections.sort(lists[j]);
int index = 0;
for (int k = 0; k < nums.length; k++) {
for (int j = 0, size = lists[k].size(); j < size; j++) {
nums[index++] = lists[k].get(j);
}
}
//依次取个位、十位、、、、
radix*=10;
}
}- 时间复杂度:O(k*N)
- 空间复杂度:O(k + N)
- 稳定性:稳定
堆排序
堆是一种特殊的树。只要满足以下两点,它就是一个堆:
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
堆的构造
一般用数组(层序排列)来表示堆,用数组的1号下标存储根节点。那么对于一般的节点 i,其左孩子为 i*2,右孩子为 i*2+1,其父亲节点则为 i/2。(当然所有派生出来的节点x都要先判断 0<x<=n,表示存在
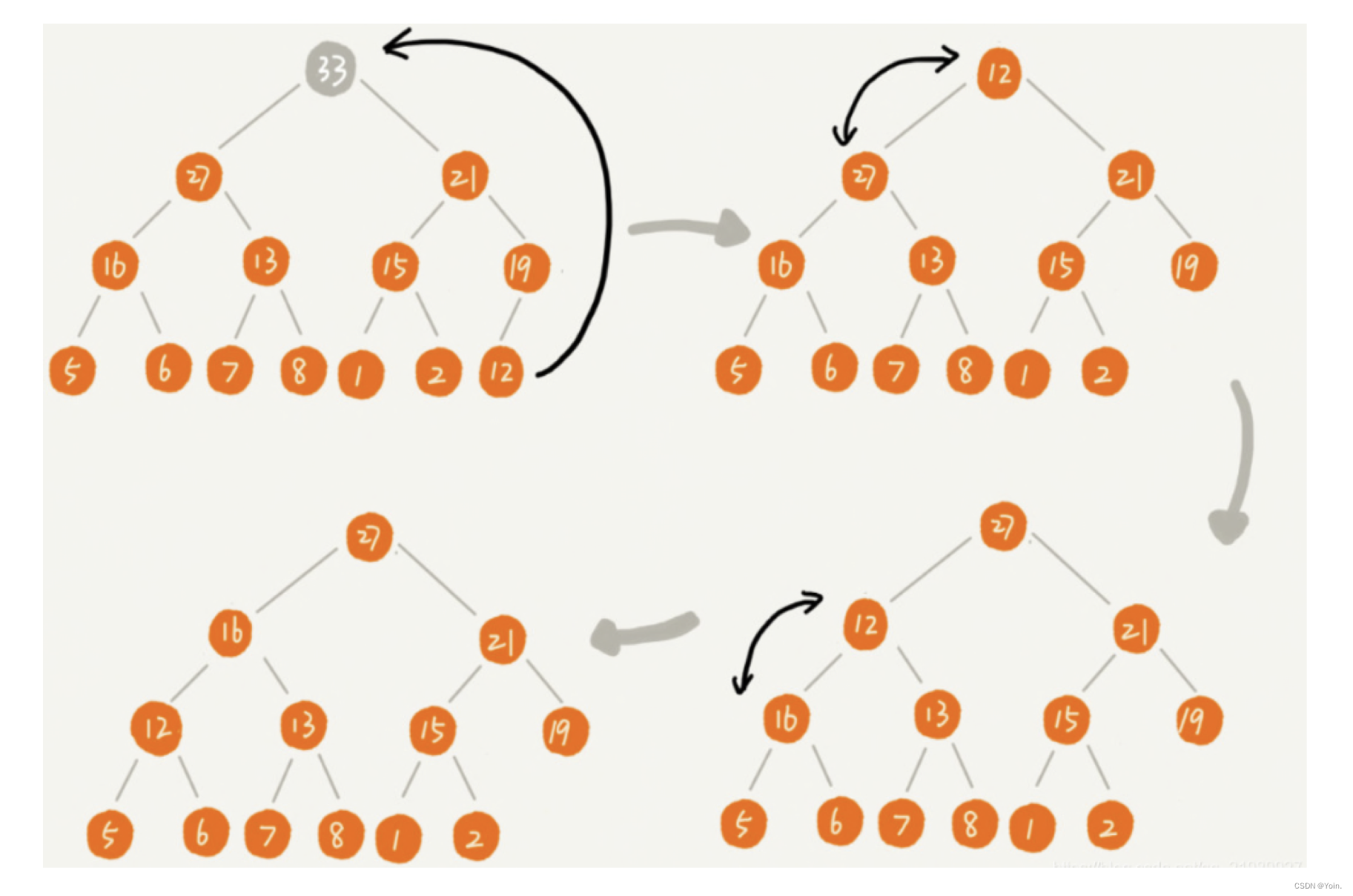
①首先我们将数组我们将数组从上至下按顺序排列,转换成二叉树:一个无序堆。每一个三角关系都是一个堆,上面是父节点,下面两个分叉是子节点,两个子节点俗称左孩子、右孩子;
②转换成无序堆之后,我们要努力让这个无序堆变成最大堆(或是最小堆),即每个堆里都实现父节点的值都大于任何一个子节点的值。
③从最后一个堆开始,即左下角那个没有右孩子的那个堆开始;首先对比左右孩子,由于这个堆没有右孩子,所以只能用左孩子,左孩子的值比父节点的值小所以不需要交换。如果发生交换,要检测子节点是否为其他堆的父节点,如果是,递归进行同样的操作。
④第二次对比红色三角形内的堆,取较大的子节点,右孩子8胜出,和父节点比较,右孩子8大于父节点3,升级做父节点,与3交换位置,3的位置没有子节点,这个堆建成最大堆。
⑤对黄色三角形内堆进行排序,过程和上面一样,最终是右孩子33升为父节点,被交换的右孩子下面也没有子节点,所以直接结束对比。
⑥最顶部绿色的堆,堆顶100比左右孩子都大,所以不用交换,至此最大堆创建完成。





堆的插入(以大根堆为例)
插入元素的位置,一定是n的下一个位置。
再将形成的堆进行堆化调整(自底向上),是每个节点均符合大根堆的性质。

删除堆顶元素
用最后一个结点覆盖堆顶节点,然后堆调整。
堆排序
基本思想:不断取出堆顶元素,进行堆调整
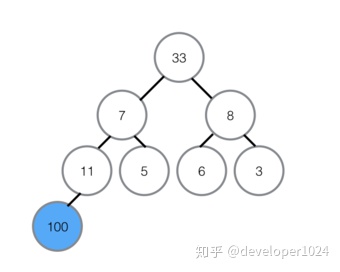
①首先将堆顶元素100交换至最底部7的位置,7升至堆顶,100所在的底部位置即为有序区,有序区不参与之后的任何对比。
②在7升至顶部之后,对顶部重新做最大堆调整,左孩子33代替7的位置。
③在7被交换下来后,下面还有子节点,所以需要继续与子节点对比,左孩子11比7大,所以11与7交换位置,交换位置后7下面为有序区,不参与对比,所以本轮结束,无序区再次形成一个最大堆。
④将最大堆堆顶33交换至堆末尾,扩大有序区;
⑤不断建立最大堆,并且扩大有序区,最终全部有序。





public void sort(){
/*
* 第一步:将数组堆化
* beginIndex = 第一个非叶子节点。
* 从第一个非叶子节点开始即可。无需从最后一个叶子节点开始。
* 叶子节点可以看作已符合堆要求的节点,根节点就是它自己且自己以下值为最大。
*/
int len = arr.length - 1;
int beginIndex = (len - 1) >> 1;
for(int i = beginIndex; i >= 0; i--){
maxHeapify(i, len);
}
/*
* 第二步:对堆化数据排序
* 每次都是移出最顶层的根节点A[0],与最尾部节点位置调换,同时遍历长度 - 1。
* 然后从新整理被换到根节点的末尾元素,使其符合堆的特性。
* 直至未排序的堆长度为 0。
*/
for(int i = len; i > 0; i--){
swap(0, i);
maxHeapify(0, i - 1);
}
}
private void maxHeapify(int index,int len){
int li = (index << 1) + 1; // 左子节点索引
int ri = li + 1; // 右子节点索引
int cMax = li; // 子节点值最大索引,默认左子节点。
if(li > len) return; // 左子节点索引超出计算范围,直接返回。
if(ri <= len && arr[ri] > arr[li]) // 先判断左右子节点,哪个较大。
cMax = ri;
if(arr[cMax] > arr[index]){
swap(cMax, index); // 如果父节点被子节点调换,
maxHeapify(cMax, len); // 则需要继续判断换下后的父节点是否符合堆的特性。
}
}