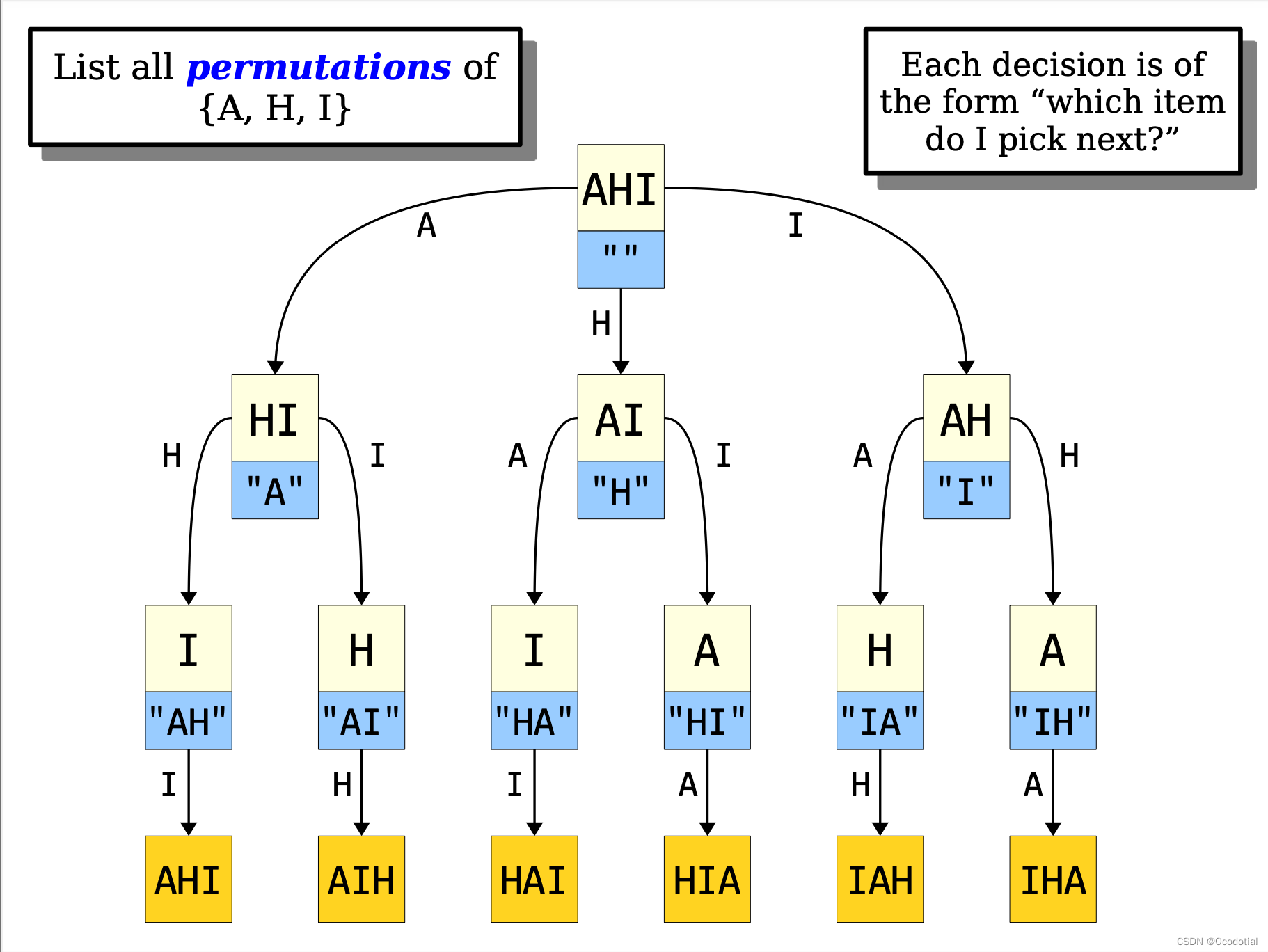
目录
写在前面
一、获取代理IP
二、验证代理IP
三、使用代理IP
四、定期更新代理IP
总结

写在前面
自己搭建代理IP池有很多好处。首先,使用代理IP可以绕过目标网站的访问限制,隐藏真实的IP地址,提高爬虫的稳定性和可靠性。其次,代理IP池可以提高爬虫的速度和效率,通过动态切换代理IP进行爬取,可以减少被封禁的风险,同时也可以绕过目标网站对IP访问频率的限制。此外,自己搭建代理IP池还可以减少成本,不需要购买商业化的代理服务,提高爬虫的可持续性。
下面将详细介绍如何自己搭建代理IP池。
一、获取代理IP
获取代理IP有多种方法,可以购买商业化的代理服务,也可以通过免费的代理IP网站获取。以下是使用免费的代理IP网站进行获取的示例代码:
import requests
from bs4 import BeautifulSoup
def get_proxy_ips(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', {'id': 'ip_list'})
rows = table.tbody.find_all('tr')
proxy_ips = []
for row in rows:
columns = row.find_all('td')
ip = columns[1].text
port = columns[2].text
proxy_ips.append(ip + ':' + port)
return proxy_ips
url = 'https://www.xicidaili.com/nn'
proxy_ips = get_proxy_ips(url)
print(proxy_ips)以上代码使用requests库和BeautifulSoup库来获取免费代理IP网站https://www.xicidaili.com/nn上的代理IP地址和端口号。函数get_proxy_ips(url)用于解析网页内容,获取代理IP地址和端口号,并返回一个代理IP列表。
二、验证代理IP
获取到代理IP后,我们需要对其进行验证,确保可用性。以下是验证代理IP的示例代码:
import requests
def check_proxy_ip(proxy_ips):
valid_proxy_ips = []
for proxy_ip in proxy_ips:
proxies = {'http': 'http://' + proxy_ip, 'https': 'https://' + proxy_ip}
try:
response = requests.get('http://www.baidu.com', proxies=proxies, timeout=3)
if response.status_code == 200:
valid_proxy_ips.append(proxy_ip)
except:
continue
return valid_proxy_ips
valid_proxy_ips = check_proxy_ip(proxy_ips)
print(valid_proxy_ips)以上代码使用requests库来发送请求,验证代理IP的可用性。函数check_proxy_ip(proxy_ips)用于对每个代理IP进行验证,如果能够成功连接到百度网站(我们也可以替换为其他目标网站),则将该代理IP添加到有效的代理IP列表中。
三、使用代理IP
获取到有效的代理IP后,我们可以使用它们来发送请求。以下是使用代理IP发送请求的示例代码:
import requests
def send_request(url, proxy_ips):
proxies = []
for proxy_ip in proxy_ips:
proxy = {'http': 'http://' + proxy_ip, 'https': 'https://' + proxy_ip}
proxies.append(proxy)
for i in range(10):
try:
proxy = proxies[i % len(proxies)]
response = requests.get(url, proxies=proxy, timeout=3)
print(response.text)
except:
continue
url = 'http://www.example.com'
send_request(url, valid_proxy_ips)以上代码使用requests库来发送请求,并设置代理IP。函数send_request(url, proxy_ips)用于循环发送请求,每次发送请求使用一个代理IP,循环使用有效的代理IP列表中的代理IP。
四、定期更新代理IP
代理IP的可用性是会发生变化的,因此我们需要定期更新代理IP。以下是定期更新代理IP的示例代码:
import schedule
import time
def update_proxy_ips():
# 获取新的代理IP
new_proxy_ips = get_proxy_ips(url)
# 验证新的代理IP
valid_proxy_ips = check_proxy_ip(new_proxy_ips)
# 更新全局的代理IP列表
global proxy_ips
proxy_ips = valid_proxy_ips
# 设置定时任务每小时更新代理IP
schedule.every(1).hours.do(update_proxy_ips)
while True:
schedule.run_pending()
time.sleep(1)以上代码使用schedule库来设置定时任务,每隔一小时更新代理IP列表。函数update_proxy_ips()用于获取新的代理IP,并验证它们的可用性,最后更新全局的代理IP列表。循环中使用schedule.run_pending()来运行定时任务。
总结
自己搭建代理IP池可以有效提高爬虫的稳定性和可靠性,减少被封禁的风险,提高爬虫的速度和效率。通过上述的代码示例,你可以在自己的爬虫项目中实现代理IP池的搭建。