基本流控
规则配置
这里和控制台显示的属性一一对应
/**
* 规则id、资源名、针对来源 这三个字段在父类 AbstractRule 里
*/
public class FlowRule extends AbstractRule {
// 阈值类型:1 代表 QPS;0 代表 并发线程数
private int grade = RuleConstant.FLOW_GRADE_QPS;
// 单机阈值:也就是限流数, 根据QPS和线程数有不同的含义
private double count;
// 流控模式:0 代表直接;1 代表关联; 2 代表链路
private int strategy = RuleConstant.STRATEGY_DIRECT;
// 关联资源,当流控模式选择为关联时,此值含义是 关联资源,当流控模式选择为链路时,此值含义是 入口资源
private String refResource;
// 流控效果:0 代表快速失败, 1 代表Warm Up, 2 代表排队等待, 3 代表Warm Up + 排队等待
private int controlBehavior = RuleConstant.CONTROL_BEHAVIOR_DEFAULT;
// 预热时长:只有当流控效果选择 Warm Up 时才会出现
private int warmUpPeriodSec = 10;
// 超时时间:只有当流控效果选择排队等待时才会出现
private int maxQueueingTimeMs = 500;
// 是否集群:默认单机(false)
private boolean clusterMode;
// 集群配置
private ClusterFlowConfig clusterConfig;
// 流控控制器:实现[流控效果]的四种不同算法。
private TrafficShapingController controller;
}
监听器实例化和管理
三个角色
- 监听器
PropertyListener<T> - 监听器管理者
SentinelProperty<T> - 规则管理者
RuleManager
流程和之前差不多, 简单贴一下源码即可
添加监听器
public class FlowRuleManager {
// 维护每个资源的规则列表
private static volatile Map<String, List<FlowRule>> flowRules = new HashMap<>();
// 流控规则监听器
private static final FlowPropertyListener LISTENER = new FlowPropertyListener();
// 监听器管理者
private static SentinelProperty<List<FlowRule>> currentProperty = new DynamicSentinelProperty<List<FlowRule>>();
static {
// 将流控规则监听器注册到监听器管理者中
currentProperty.addListener(LISTENER);
}
// 通知每一个监听器,告诉他们规则发生了变化,需要重新加载规则配置
public static void loadRules(List<FlowRule> rules) {
currentProperty.updateValue(rules);
}
}

初始化规则
private static final class FlowPropertyListener implements PropertyListener<List<FlowRule>> {
@Override
public synchronized void configUpdate(List<FlowRule> value) {
// 规则和资源名绑定
Map<String, List<FlowRule>> rules = FlowRuleUtil.buildFlowRuleMap(value);
// 更新规则
flowRules.updateRules(rules);
RecordLog.info("[FlowRuleManager] Flow rules received: {}", rules);
}
@Override
public synchronized void configLoad(List<FlowRule> conf) {
Map<String, List<FlowRule>> rules = FlowRuleUtil.buildFlowRuleMap(conf);
flowRules.updateRules(rules);
RecordLog.info("[FlowRuleManager] Flow rules loaded: {}", rules);
}
}
/*
根据提供的filter函数将原始的List<FlowRule>构建为Map<K, List<FlowRule>,按提供的Key进行分组
*/
public static <K> Map<K, List<FlowRule>> buildFlowRuleMap(List<FlowRule> list, Function<FlowRule, K> groupFunction, Predicate<FlowRule> filter, boolean shouldSort) {
Map<K, List<FlowRule>> newRuleMap = new ConcurrentHashMap<>();
if (list == null || list.isEmpty()) {
return newRuleMap;
}
Map<K, Set<FlowRule>> tmpMap = new ConcurrentHashMap<>();
for (FlowRule rule : list) {
// 如果规则无效,则忽略该规则并打印警告信息
if (!isValidRule(rule)) {
RecordLog.warn("[FlowRuleManager] Ignoring invalid flow rule when loading new flow rules: " + rule);
continue;
}
// 如果存在filter,并且该规则未通过filter,则跳过该规则
if (filter != null && !filter.test(rule)) {
continue;
}
// 如果规则的限制应用程序为空,则将其设置为默认值
if (StringUtil.isBlank(rule.getLimitApp())) {
rule.setLimitApp(RuleConstant.LIMIT_APP_DEFAULT);
}
// 获取[流控效果]处理器
TrafficShapingController rater = generateRater(rule);
rule.setRater(rater);
// 获获取资源名
K key = groupFunction.apply(rule);
if (key == null) {
continue;
}
Set<FlowRule> flowRules = tmpMap.get(key);
// 将规则放到 Map 里,和当前资源绑定
if (flowRules == null) {
// 这里使用set进行去重
flowRules = new HashSet<>();
tmpMap.put(key, flowRules);
}
flowRules.add(rule);
}
// 规则排序
Comparator<FlowRule> comparator = new FlowRuleComparator();
for (Entry<K, Set<FlowRule>> entries : tmpMap.entrySet()) {
List<FlowRule> rules = new ArrayList<>(entries.getValue());
if (shouldSort) {
// 对规则排序
// 首先集群模式将非集群规则排在集群规则前面
// 接着非默认 limitApp 的规则排在默认 limitApp 的规则前面
Collections.sort(rules, comparator);
}
newRuleMap.put(entries.getKey(), rules);
}
return newRuleMap;
}
public final class FlowRuleUtil {
private static TrafficShapingController generateRater(/*@Valid*/ FlowRule rule) {
// 判断只有当阈值类型为 QPS 的时候的才生效,也就意味着点那个阈值类型选择并发线程数的时候是不生效的。这一点通过Dashboard也可以发现
if (rule.getGrade() == RuleConstant.FLOW_GRADE_QPS) { // QPS
// // 根据选择流控效果返回不同的流控处理器
switch (rule.getControlBehavior()) {
// Warm Up 预热模式,也称冷启动模式
case RuleConstant.CONTROL_BEHAVIOR_WARM_UP:
return new WarmUpController(rule.getCount(), rule.getWarmUpPeriodSec(),
ColdFactorProperty.coldFactor);
// 排队等待模式
case RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER:
return new ThrottlingController(rule.getMaxQueueingTimeMs(), rule.getCount());
// Warm Up + 排队等待 模式
case RuleConstant.CONTROL_BEHAVIOR_WARM_UP_RATE_LIMITER:
return new WarmUpRateLimiterController(rule.getCount(), rule.getWarmUpPeriodSec(), rule.getMaxQueueingTimeMs(), ColdFactorProperty.coldFactor);
// 默认, 直接拒绝
case RuleConstant.CONTROL_BEHAVIOR_DEFAULT:
default:
// Default mode or unknown mode: default traffic shaping controller (fast-reject).
}
}
// 默认模式:快速失败用的这个
return new DefaultController(rule.getCount(), rule.getGrade());
}
}
TrafficShapingController类图关系
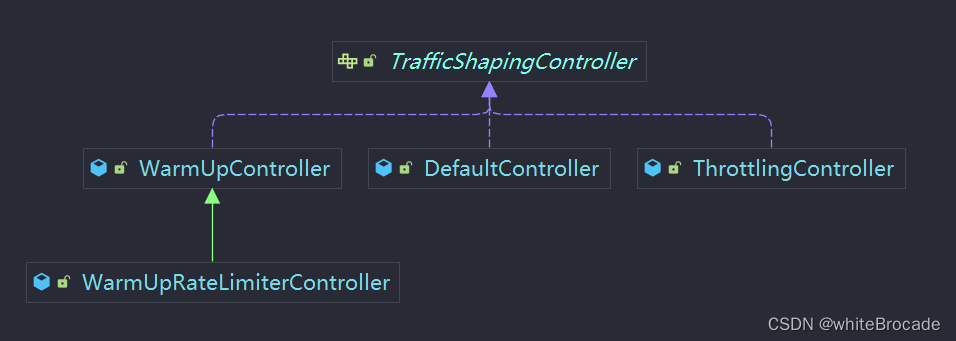
public class FlowRuleComparator implements Comparator<FlowRule> {
@Override
public int compare(FlowRule o1, FlowRule o2) {
// 如果o1是集群模式而o2不是,则o1排在后面,返回1
if (o1.isClusterMode() && !o2.isClusterMode()) {
return 1;
}
// 如果o1不是集群模式而o2是,则o2排在后面,返回-1
if (!o1.isClusterMode() && o2.isClusterMode()) {
return -1;
}
// 如果o1的limitApp属性为空,则认为两个对象相等,返回0
if (o1.getLimitApp() == null) {
return 0;
}
// 如果o1和o2的limitApp属性相等,则认为两个对象相等,返回0
if (o1.getLimitApp().equals(o2.getLimitApp())) {
return 0;
}
// 如果o1的limitApp属性为默认值,则认为o1排在后面,返回1
if (RuleConstant.LIMIT_APP_DEFAULT.equals(o1.getLimitApp())) {
return 1;
} else if (RuleConstant.LIMIT_APP_DEFAULT.equals(o2.getLimitApp())) { // 如果o2的limitApp属性为默认值,则认为o2排在后面,返回-1
return -1;
} else { // 如果以上条件都不满足,则认为两个对象相等,返回0
return 0;
}
}
}
规则验证
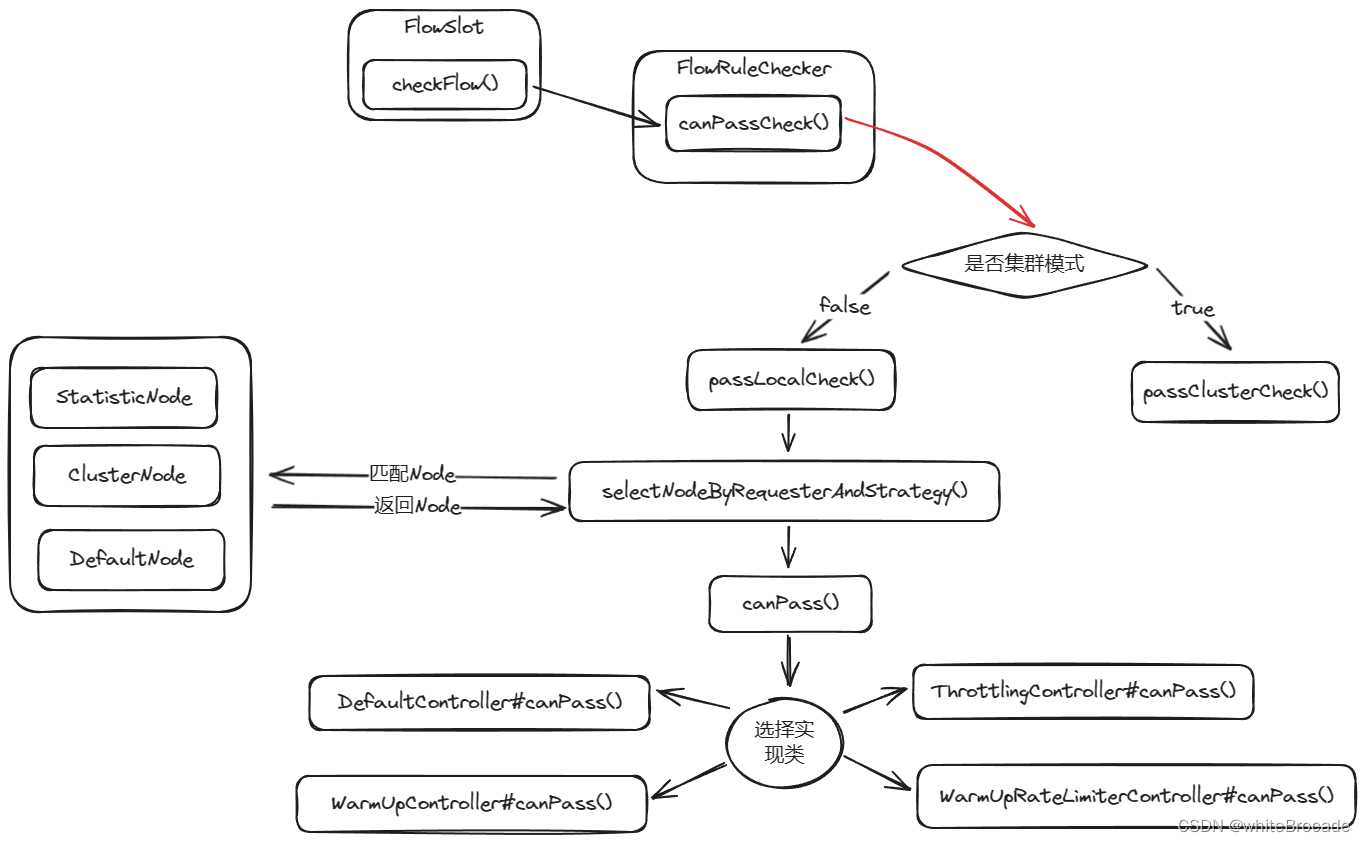
核心流程
FlowSlot是第七个Slot, 下边简单介绍了流程,
public class FlowSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
// 相当于 Util
private final FlowRuleChecker checker = new FlowRuleChecker();
// 入口方法
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args) throws Throwable {
// 核心方法
checkFlow(resourceWrapper, context, node, count, prioritized);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
// 出口方法
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
fireExit(context, resourceWrapper, count, args);
}
// 规则验证
void checkFlow(ResourceWrapper resource, Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
checker.checkFlow(ruleProvider, resource, context, node, count, prioritized);
}
}
checkFlow
public class FlowRuleChecker {
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource, Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
if (ruleProvider == null || resource == null) {
return;
}
// 从 Map 里获取到该资源对应的规则列表
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
// 遍历规则
for (FlowRule rule : rules) {
// 调用 canPassCheck 方法进行规则验证,看此次请求是否命中了该资源配置的规则
if (!canPassCheck(rule, context, node, count, prioritized)) {
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) {
String limitApp = rule.getLimitApp();
if (limitApp == null) {
return true;
}
// 如果是集群模式, 就调用集群passClusterCheck方法, 这部分留到集群模式再分析
if (rule.isClusterMode()) {
return passClusterCheck(rule, context, node, acquireCount, prioritized);
}
// 如果是单机模式,则走单机passLocalCheck方法
return passLocalCheck(rule, context, node, acquireCount, prioritized);
}
/*
单机passLocalCheck方法
*/
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) {
// 根据配置的流控规则选择合适的Node
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
// 调用相应node的canPass方法
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}
}
selectNodeByRequesterAndStrategy
三种情况
-
如果 limitApp 和 origin 相等并且 limitApp 不是默认值 default:这种情况采取的是StatisticNode,目的是确保在针对特定调用方的流量控制规则中,我们使用与调用方相关的统计信息来进行限流判断
- 针对A,B不针对特定的调用方方配置特定流控规则, sentinel找A, B方各自关联的
StatisticNode, 根据其中的统计信息判断是否进行限流
- 针对A,B不针对特定的调用方方配置特定流控规则, sentinel找A, B方各自关联的
-
limitApp 值为 default(默认就是 default) :此种情况采取ClusterNode,这里使用 ClusterNode 的原因是:当限流调用方为默认(default)时,表示我们
不针对特定的调用方进行限流,而是应用通用的限流规则。在这种情况下,我们需要获取与当前资源关联的 ClusterNode ,因为ClusterNode包含了以资源为维度的统计信息,如请求的 QPS、响应时间等- 针对A, B不针对特定的调用方不单独配置流控规则, 都用默认流控规则
-
limitApp 值为other并且
FlowRuleManager.isOtherOrigin(origin, rule.getResource()):此种情况会返回DefaultNode- 针对A, B不针对特定的调用方单独配置特定流控规则, 但是对应A, B之外的调用方配置一套默认的流控规则
/*
根据限流规则的生效来源、限流策略以及实际请求的来源,从上下文、默认节点或集群节点中选择一个适当的节点进行限流计算
在不同条件下,可能会选择上下文中的来源节点StatisticNode、当前请求的集群节点ClusterNode 或默认节点DefaultNode
*/
static Node selectNodeByRequesterAndStrategy(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node) {
String limitApp = rule.getLimitApp();
int strategy = rule.getStrategy();
String origin = context.getOrigin();
// 当限流规则的生效来源(limitApp)与实际请求的来源(origin)相同, 示该限流规则针对特定来源进行限流
if (limitApp.equals(origin) && filterOrigin(origin)) {
// 如果流控模式是 直接
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// 返回上下文中的来源节点,其实就是 StatisticNode
// 因为这种模式要求根据调用方的情况进行限流,而来源节点包含了调用方的统计信息,所以选择来源节点作为限流计算的依据
return context.getOriginNode();
}
// 如果流控模式不是 直接, 调用selectReferenceNode方法获取引用节点
return selectReferenceNode(rule, context, node);
} else if (RuleConstant.LIMIT_APP_DEFAULT.equals(limitApp)) { // 来源为default, 表示该限流规则对所有来源都生效
// 如果流控模式是 直接
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// 取Node对应ClusterNode(Resource)维度指标返回, 因为这种策略要求根据被调用资源的情况进行限流,而集群节点包含了被调用资源的统计信息,所以选择集群节点作为限流计算的依据,limitApp 为 default 的话,是全局默认的,以资源为维度,不区分 Context
return node.getClusterNode();
}
// 如果流控模式不是 直接, 调用selectReferenceNode方法获取引用节点
return selectReferenceNode(rule, context, node);
} else if (RuleConstant.LIMIT_APP_OTHER.equals(limitApp) && FlowRuleManager.isOtherOrigin(origin, rule.getResource())) { // 来源为other, 且实际请求的来源(origin)与限流规则的资源名(rule.getResource())不同, 表示该限流规则针对除默认来源以外的其他来源进行限流
// 如果流控模式是 直接
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// 返回上下文中的来源节点,其实就是 StatisticNode
// 因为这种模式要求根据调用方的情况进行限流,而来源节点包含了调用方的统计信息,所以选择来源节点作为限流计算的依据
return context.getOriginNode();
}
// 如果流控模式不是 直接, 调用selectReferenceNode方法获取引用节点
return selectReferenceNode(rule, context, node);
}
return null;
}
/*
针对关联和链路模式,选择引用节点
*/
static Node selectReferenceNode(FlowRule rule, Context context, DefaultNode node) {
// 获取资源名
String refResource = rule.getRefResource();
int strategy = rule.getStrategy();
if (StringUtil.isEmpty(refResource)) {
return null;
}
// 如果流控模式是 关联
if (strategy == RuleConstant.STRATEGY_RELATE) {
// 使用ClusterBuilderSlot类的静态方法getClusterNode来查找并返回与refResource匹配的集群节点
return ClusterBuilderSlot.getClusterNode(refResource);
}
// 如果流控模式是 链路
if (strategy == RuleConstant.STRATEGY_CHAIN) {
// 检查引用资源是否与当前上下文名称相等
if (!refResource.equals(context.getName())) {
// 如果不相等,则返回null,表示根据当前策略和条件无法找到引用节点
return null;
}
// 若相等,则返回传入的DefaultNode节点作为引用节点
return node;
}
// 执行到这里说明, 流控模式既不是[直接, 关联, 链路]这三个之一, 返回null
return null;
}
核心
- 如果不针对某个来源进行限制( 也就是 limitApp 为 default),那么采取ClusterNode进行数据统计,也就是此资源在所有 app 上共享数据,
共享流控策略 - 如果针对某个来源进行限制,比如 limitApp 为 “shop”,那么只有 origin 为 “shop” 的才会有流控效果,origin 为其他的则直接放行。这里需要采取每个请求链自己的 StatisticNode 来进行数据统计。
- 如果给某资源配置了多个流控规则,比如限制 limitApp 为 “shop” 的 QPS 为 50,然后对其他业务方都走默认共享的限流策略,那么这时候就可以配置两条限流规则: limitApp 为 “shop” 和 limitApp 为 “other” 的。那么 limitApp 为 “shop” 的就会采取自己的 StatisticNode 进行数据统计,而 limitApp 为 “other” 的则会采取 DefaultNode 进行数据统计
流程图大致如下,下边再细致分析具体实现类的canPass()逻辑
快速失败
什么是快速失败?
即当请求数超出设置的阈值后,则直接拒绝请求,也就是直接抛出异常
实现思路
- 对比QPS/线程数, 如果超出阈值, 直接抛出异常
sentinel实现快速失败功能是流控控制器用的是DefaultController, 从名字也看得到, 这是一个默认的处理器
public class DefaultController implements TrafficShapingController {
/**
* acquireCount = 1
*/
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 获取当前请求数
int curCount = avgUsedTokens(node);
// 如果当前请求数 + 1 超出阈值,那么肯定 return false 抛出异常了
if (curCount + acquireCount > count) {
// .. 省略优先级逻辑
return false;
}
//如果当前请求数 + 1 没有超出阈值,则返回成功
return true;
}
}
贴核心代码canPass()
核心就是前边根据阈值类型(limitApp)和限制来源(origin)找到DefaultNode,然后根据Node获取QPS和线程数,最终对比当前请求是否超出设置的阈值,超出则直接抛异常
public class DefaultController implements TrafficShapingController {
private static final int DEFAULT_AVG_USED_TOKENS = 0;
/*
- node: Node类型节点
- acquireCount: 该次请求需要消耗的令牌数
- prioritized: 是否为优先级高请求
*/
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 获取当前当前令牌数
int curCount = avgUsedTokens(node);
// 如果当前令牌数 + 所需要的令牌数 > 配置阈值,那么肯定 return false 抛出异常了
// 通常来说acquireCount都为1, 即表示该次请求需要一个令牌
if (curCount + acquireCount > count) {
// 如果prioritized为true且grade等于RuleConstant.FLOW_GRADE_QPS(表示优先级高且规则为QPS)
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
// 获取当前时间currentTime和需要等待的时间waitInMs
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
// 如果waitInMs小于OccupyTimeoutProperty类的getOccupyTimeout方法返回的占用超时时间
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
// 将currentTime加上waitInMs传入node对象的addWaitingRequest方法,将acquireCount作为参数传入,将当前请求加入等待队列
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
// 调用node对象的addOccupiedPass方法,将acquireCount作为参数传入,增加已占用的通行数量
node.addOccupiedPass(acquireCount);
// 调用sleep方法,休眠等待时间waitInMs
sleep(waitInMs);
// 抛出PriorityWaitException异常,表示请求将通过,但需要等待waitInMs毫秒
throw new PriorityWaitException(waitInMs);
}
}
// 如果不满足上述条件,只要超过阈值则不通过
return false;
}
// 没超过阈值,正常返回
return true;
}
/*
计算当前节点的平均使用令牌数量, 其实也就说count值
*/
private int avgUsedTokens(Node node) {
if (node == null) {
return DEFAULT_AVG_USED_TOKENS;
}
// 如果是 QPS 则从 Node 里获取 QPS 数,反之从 Node 里获取线程数
return grade == RuleConstant.FLOW_GRADE_THREAD ? node.curThreadNum() : (int)(node.passQps());
}
}
对于
prioritized参数需要补充说明一下
prioritized参数表示是否对该请求设置优先级。在 Sentinel 中,一般用于区分高优先级请求和普通请求当
prioritized为true时,表示该请求具有较高优先级,高优先级应尽量保证其可以通过限流检查一般情况下,prioritized 参数的值为false,除非手动指定为 true,根据场景自行设置,大多数场景是无需此参数的,因为我们限流的目的就是不想让超出的流量通过,设置为 true 的话会尽量保证其可以通过限流检查
排队等待
排队等待底层基于漏桶算法来实现的,通过控制请求在恒定速率下流出,以应对流量突增并保持系统稳定, 适用于希望平滑处理流量的场景,以避免短时间内的流量波动对系统造成压力
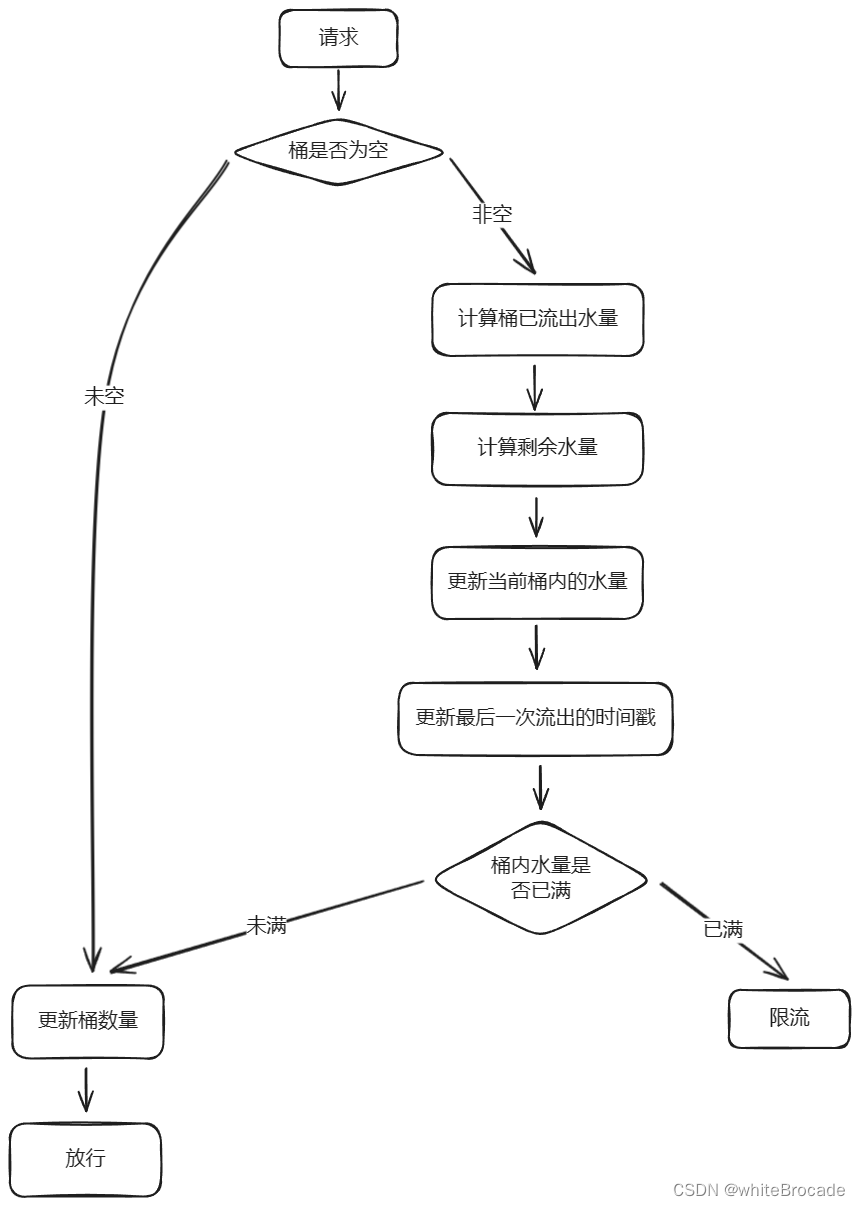
漏桶算法原理
特点:
- 固定速率:请求以固定速率流出, 但请求写入速度不固定
- 有限容量:桶的容量有限,当桶满时,新到达的请求会被拒绝,即拒绝超过容量的流量。
- 先进先出(FIFO) :请求按照先进先出的顺序从桶中流出,类似于流量请求的处理顺序
核心:
- 当请求到达时,将请求放入缓冲区(请求队列)中
- 系统以固定速率处理缓冲区中的请求
- 如果缓冲区未满,请求将被正常处理;否则,请求将被拒绝或丢弃
Java实现源码
/**
* @author whitebrocade
* @version 1.0
* @description: 漏桶算法
*/
public class RateLimiter {
// 最后一次流出的时间戳
private static long lastOutTime = System.currentTimeMillis();
// 流出速率(每秒 10 次)
private static int outRate = 10;
// 桶的最大容量 10 个
private static int maxCapacity = 10;
// 当前桶内的水量
private static AtomicInteger currentWater = new AtomicInteger(0);
// 返回值说明:
// false:未受到限制
// true:受到限制
public static synchronized boolean isLimited(long taskId, int turn) {
// 桶为空, 则当前时间作为最后一次流出时间, 水量+1
if (currentWater.get() == 0) {
lastOutTime = System.currentTimeMillis();
currentWater.incrementAndGet();
return false;
}
// 计算桶已流出水量, 当前时间 - 上次流出时间 * 流出速率 = 该时间段流出的水量
int leakedWater = (int) ((System.currentTimeMillis() - lastOutTime) / 1000) * outRate;
// 计算剩余水量, 当前数量 - 这段时间流出水量 = 剩余水量
int remainingWater = currentWater.get() - leakedWater;
// 更新当前桶内的水量
currentWater.set(Math.max(0, remainingWater));
// 更新最后一次流出的时间戳
lastOutTime = System.currentTimeMillis();
// 如果桶内水量未满, 加水然后则放行
if (currentWater.get() < maxCapacity) {
currentWater.incrementAndGet();
return false;
}
// 执行到这里说明, 桶内水量已满,就不放水了, 进行限流
return true;
}
}
流程图如下
源码实现
排队等待相关的代码实现在ThrottlingController, 旧版本的sentinel则是RateLimiterController , 新版本的sentinel中ThrottlingController有这么一行注释Refactored from legacy RateLimitController of Sentinel 1.x.翻译过来就是从Sentinel 1.x的旧版RateLimitController重构
核心源码还是围绕canPass()展开的
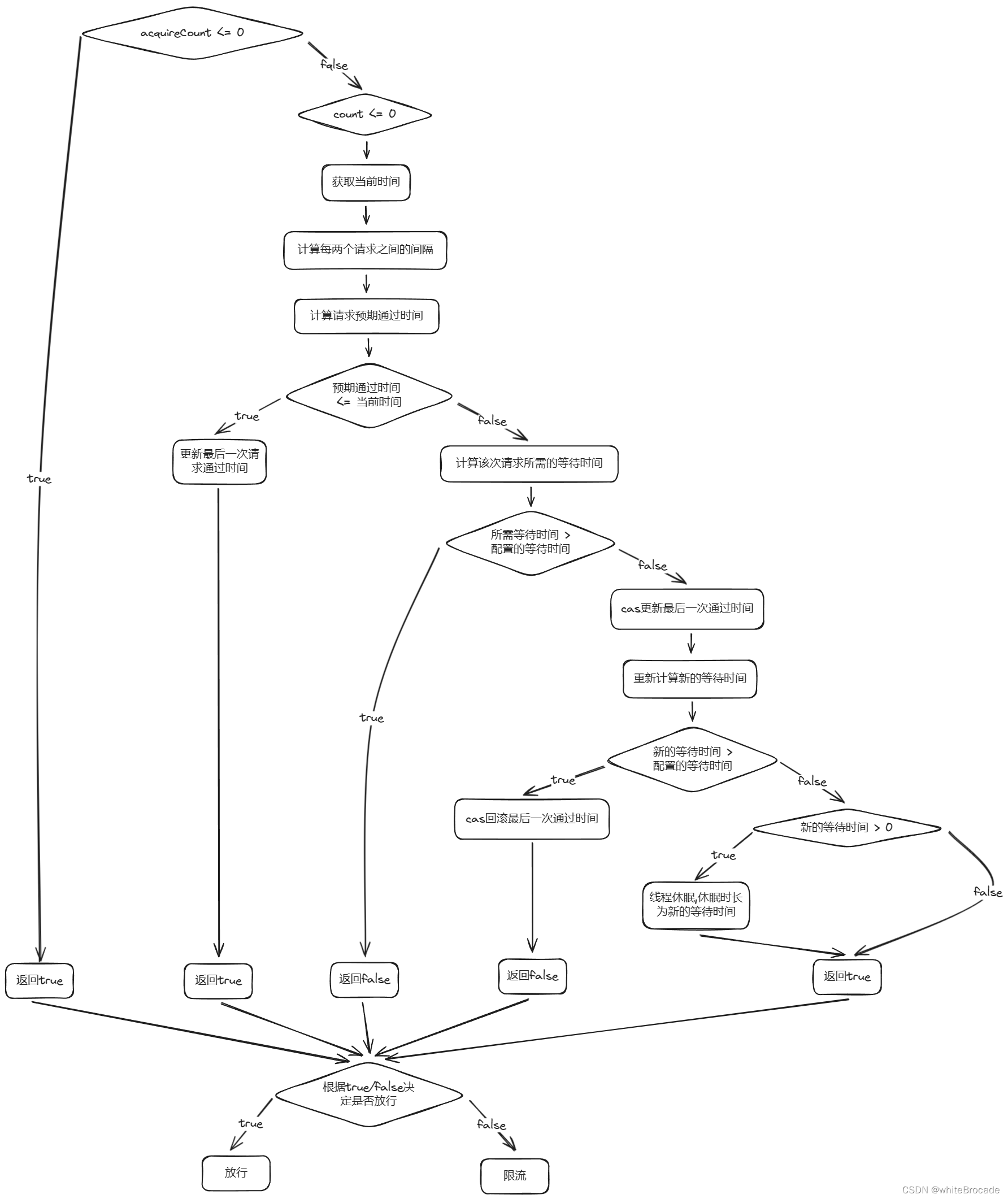
public class ThrottlingController implements TrafficShapingController {
// 排队等待时间, 单位毫秒值
private final int maxQueueingTimeMs;
// 限制的QPS阈值
private final double count;
// 最近一个请求的通过时间,每次请求通过后就会更新此时间
private final AtomicLong latestPassedTime = new AtomicLong(-1);
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 如果当前的acquireCount小于或等于0时, 相当于没有流量通过
if (acquireCount <= 0) {
return true;
}
// 当count小于或等于0时拒绝, 即不放行任何一个请求
if (count <= 0) {
return false;
}
// 使用纳秒精度还是毫秒精度计算
if (useNanoSeconds) {
// 纳米精度
return checkPassUsingNanoSeconds(acquireCount, this.count);
} else {
// 毫米精度
return checkPassUsingCachedMs(acquireCount, this.count);
}
}
}
一些值含义解析
-
acquireCount: 代表每次从桶底流出多少个请求,如果acquireCount小于等于 0,则直接通过,无需限流,默认是 1 -
count: 限流规则的count(即允许的 QPS)小于等于 0,则直接拒绝,相当于一个请求也不能放行 -
latestPassedTime:最近一个请求通过的时间, 用于辅助计算出下一个请求的预期通过时间, 详细计算方式后边会分析 -
maxQueueingTimeMs: 排队等待的意思是超出阈值后等待一段时间,那么这个字段就是队列中的最大等待时间 -
useNanoSeconds: 设置为true,表明需要使用纳秒级精度来计算时间;否则,将其设置为false,意味着可以使用毫秒作为计时单位
我们以毫秒checkPassUsingCachedMs()进行分析, 即useNanoSeconds=false走的逻辑分支
private boolean checkPassUsingCachedMs(int acquireCount, double maxCountPerStat) {
// 获取当前时间
long currentTime = TimeUtil.currentTimeMillis();
// 计算每两个请求之间的间隔, 1s内请求通过的平均间隔(statDurationMs为统计周期, 通常为1/s)
long costTime = Math.round(1.0d * statDurationMs * acquireCount / maxCountPerStat);
// 计算当前这次请求的预期通过时间, 即这次请求预计在几点几分几秒内通过
long expectedTime = costTime + latestPassedTime.get();
// 如果此请求预期通过时间比当前时间小,也就是在预期之内,则直接放行
if (expectedTime <= currentTime) {
// 没超出阈值,则更新最后一次通过时间为当前时间,且返回true代表放行此次请求, 也可以理解成距离上一次请求这个资源,已经过去了很长时间
latestPassedTime.set(currentTime);
return true;
} else { // 如果请求的预期通过时间 大于 当前时间, 可能需要等待
// 计算当前这次请求需要等待时间
long waitTime = costTime + latestPassedTime.get() - TimeUtil.currentTimeMillis();
// 如果需要等待的时间 大于 规则中配置最大等待时间, 直接拒绝这次请求
// 相当于漏桶内的水溢出了,处理不完,抛出异常
if (waitTime > maxQueueingTimeMs) {
return false;
}
// 执行到这里说明需要等待的时间 小于等于 规则中配置等待的时间, 等待执行即可
// 尝试累加上次通过时间, 通过addAndGet方法将上一次请求通过时间加上每次请求需要多少时间得到下一个请求预计通过时间, (考虑并发竞争条件)
long oldTime = latestPassedTime.addAndGet(costTime);
// 下一个请求需要等待多久 = 下一个请求预计通过时间 - 当前系统时间
waitTime = oldTime - TimeUtil.currentTimeMillis();
// 如果二次确认等待时间大于排队时间,则需要回滚刚才更新的最近一次请求通过的时间(通过减去 costTime),然后返回 false 表示请求无法通过
if (waitTime > maxQueueingTimeMs) {
// 回滚latestPassedTime的修改
latestPassedTime.addAndGet(-costTime);
// 拒绝这次请求
return false;
}
// if (waitTime > 0) 的判断是为了确保线程仅在确实需要等待时才进行休眠。当计算得到的 waitTime 大于0时,表示当前请求未达到预期通过时间,需要等待一段时间才能满足速率限制策略。
// 若 waitTime <= 0,则可能是因为在并发环境下其他线程已经更新了latestPassedTime导致等待时间减少为0或者变为负数(即已经超过预期通过时间)。在这种情况下,没有必要再让当前线程进行休眠,可以直接返回 true 并允许请求通过
if (waitTime > 0) {
// 等待
sleepMs(waitTime);
}
// 最后, 无论等待与否,由于之前已成功更新latestPassedTime,此时返回true表示请求最终能够通过(可能已经经过了等待)
return true;
}
}
流程图如下
对上述流程举例说明
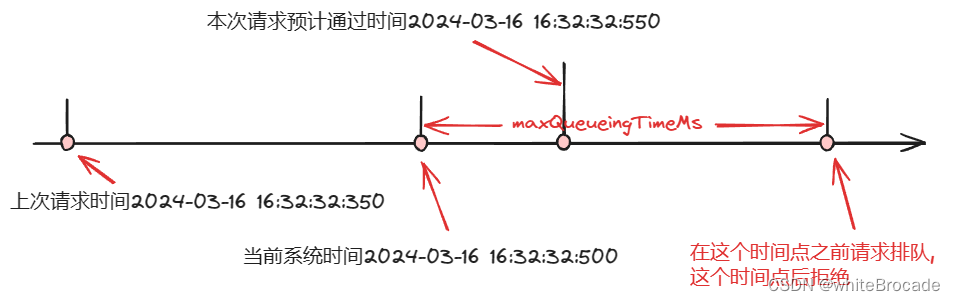
假设以下条件
- 当前系统时间currentTime=2024-03-16 16:32:32:500
- 限流规则QPS为10, 即count=10
- 最近一次请求时间latestPassedTime=currentTime=2024-03-16 16:32:32:350
- 每次请求所需要的count, acquireCount=1
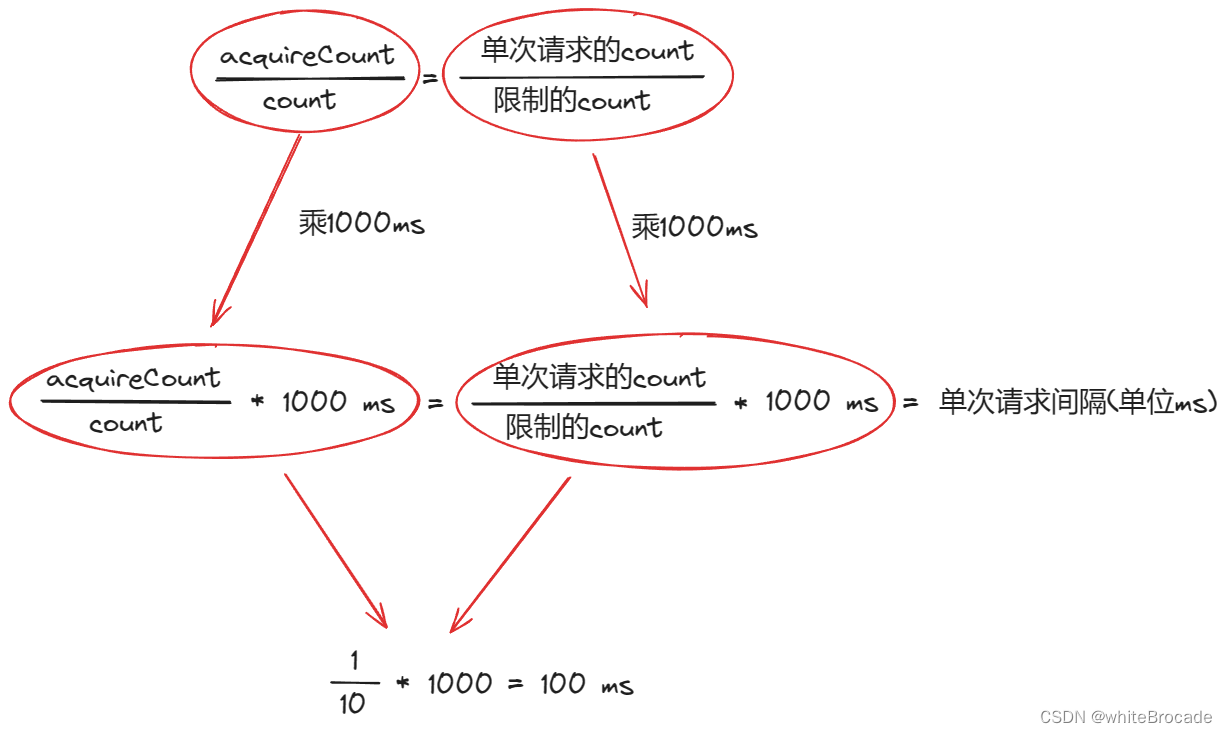
计算两次请求之间的间隔costTime
long costTime = Math.round(1.0 * (acquireCount) / count * 1000);
⬇️
long costTime = Math.round(1.0 * (1) / 10 * 1000) = 100ms;
计算该次请求预期通过时间
long expectedTime = costTime + latestPassedTime.get();
⬇️
long expectedTime = 100ms + 2024-03-16 16:32:32:350ms = 2024-03-16 16:32:32:450ms;
判断下一个请求预期通过时间是不是小于等于当前系统时间, 如果小于等于,则代表此次请求在阈值时间范围内,直接放行,反之则需要等待
if (2024-03-16 16:32:32:450 <= 2024-03-16 16:32:32:500) {
// 没超出阈值,则更新最后一次通过时间为当前时间,且返回true代表放行此次请求
latestPassedTime.set(2024-03-16 16:32:32:500);
return true;
} else {
// 超出阈值,则等待
}
如下图, 发现预计通过时间比当前时间还小, 说明可以通过

如果预计通过时间大于当前系统时间, 即下图这种情况, 那么就需要排队等待了
为什么需要计算和判断两次waitTime?
避免不必要的等待:首先进行非原子性的预计通过时间计算和判断,如果当前时间已经满足或超过预计通过时间(即waitTime <= currentTime),那么可以直接更新最新通过时间为当前时间并返回true,这样就无需任何额外的等待,提高了执行效率减少同步开销:如果不进行预判而直接使用原子操作更新最新通过时间,那么对于每个调用该方法的线程来说都会增加同步操作的负担,这可能对性能造成影响,尤其是在高并发场景下。先进行预判可以过滤掉部分无需同步处理的情况(这种思想很棒)
再提过一嘴, 这里的分段判断为了维护可读性和提前返回, 先初步判断是否超时, 如果超时再进一步同步判断
如果我们只用第一次的long waitTime = costTime + latestPassedTime.get() - currentTime, 不用第二次的行不行?
答案是不行的, 代码如下
if(预计通过时间<=当前时间) {
放行
} else { // 预计通过时间>当前时间
long waitTime = costTime + latestPassedTime.get() - currentTime;
if (waitTime > timeoutInMs) {
return false;
}
return true;
}
但是这里的代码会有以下问题
竞争条件:当多个线程同时调用该函数并满足第一个判断条件时,所有线程都可能认为自己可以立即通过(更新最新通过时间为当前时间),这会导致多个线程在同一统计周期内通过,从而违反了每秒最大次数的限制计数不准确:由于没有同步控制,多个线程会并发修改latestPassedTime变量,导致其值可能不是预期中的下一个允许通过的时间点,使得流量控制失效不公平性:在极端情况下,可能出现一个线程刚更新完latestPassedTime,另一个线程紧接着又更新的情况,这样可能导致某些线程总是无法成功通过,造成不公平的资源分配
因此,在多线程环境下,仅依赖第一次判断是不够的,必须配合适当的同步机制(如这里的原子操作)来确保数据的一致性和正确地实施流量控制策略
如果我们只用latestPassedTime.addAndGet(costTime), 不用第一次的计算判断行不行?
答案是行的, 代码如下
if(预计通过时间<=当前时间) {
放行
} else { // 预计通过时间>当前时间
long oldTime = latestPassedTime.addAndGet(costTime);
try {
long waitTime = oldTime - TimeUtil.currentTimeMillis();
if (waitTime > timeoutInMs) {
latestPassedTime.addAndGet(-costTime);
return false;
}
if (waitTime > 0) {
Thread.sleep(waitTime);
}
return true;
} catch (InterruptedException e) {
}
}
但是这里的代码会有以下问题
效率降低: 每次走这里的逻辑时, 都会执行原子同步操作, 特别是在不需要更新latestPassedTime的情况下(即当前时间已满足条件可以直接通过),这将导致不必要的性能损失- 在这里的体现就是: 本来应该先判断再决定是否执行对
latestPassedTime执行add, 但是这里直接就行了addAndGet
- 在这里的体现就是: 本来应该先判断再决定是否执行对
复杂度提高: 若直接在原子操作后判断等待时间是否超过限制,那么在满足条件的情况下需要进行更复杂的逻辑处理以避免不必要的时间更新, 例如,在发现等待时间过长后可能还需要进行原子性的回滚操作,这会使代码逻辑变得更为复杂和难以维护- 在这里的体现就是: 执行
addAndGet()后, 发现wailtTime超时, 所以得再执行addAndGet回滚操作
- 在这里的体现就是: 执行
资源浪费:对于无需等待的线程,如果直接使用原子操作,可能会造成其他线程无谓地等待锁资源,从而影响整体并发性能- 比如A,B线程同时到达这里, 实际A,B理论上都是可以通过, 但是
addAndGet是同步操作, 线程A线获取锁更新latestPassedTime, 然后释放锁, 然后B线程也是同理, 虽然大家这种场景都能通过,但是B线程却要等待A线程释放锁才能执行addAndGet操作
- 比如A,B线程同时到达这里, 实际A,B理论上都是可以通过, 但是
综上所述, 引入了第一次计算和判断waitTime的逻辑, 进行一次过滤, 第一次粗略判断能通过的, 那么就直接过, 如果第一次过滤过了, 那么同步执行再计算判断waitTime, 保证准确性
为什么需要回滚latestPassedTime的修改?
- 当多个线程并发尝试获取锁时,它们之间可能存在竞争。如果当前线程在计算等待时间后发现超过了最大排队等待时间(maxQueueingTimeMs),这意味着当前线程不应该通过。在这种情况下,我们需要将最近一次请求通过的时间回滚,以免对后续请求产生负面影响。具体来说,如果不进行回滚操作,后续请求在计算等待时间时可能会受到当前线程的影响,导致计算出错误的等待时间
- 回滚操作确保了即使当前线程无法通过限流检查,后续线程仍然可以基于正确的最近一次请求通过的时间来计算等待时间,并尝试获取许可。这样可以在高并发场景下实现更公平和准确的限流行为。
如果不考虑上述问题, 那么直接使用Thread.sleep(waitTime)可能也能达到限流的目的,但在并发环境下,这种简单的方法可能会导致不公平的限流行为,这也是Sentinel 代码严谨性的一种体现
为什么需要判断waitTime > 0?
避免不必要的休眠:如果waitTime计算结果为零或负数,表示当前线程无需等待,直接返回true即可。通过判断waitTime > 0,可以避免线程进入不必要的休眠状态。
Sentinel 实现的漏桶算法和之前Java写的漏桶算法本质上有何不同?
| sentinel | java | |
|---|---|---|
| 是否有字段记录请求令牌数 | 没有单独字段记录当前桶内的请求量,而是通过上一次通过请求的时间和每个请求通过预计需要多久时间这两个字段来实现 | 有个字段单独记录当前桶内的水量)请求量),每通过一个请求,则此字段值 - 1,反之,每新进一个请求,此字段的值 + 1 |
| 拒绝策略 | 排队等待 | 直接拒绝 |
为什么 Sentinel 的排队等待功能要采取漏桶算法而不是令牌桶算法呢?
todo
小Bug补充
latestPassedTime.set(currentTime)造成的线程竞争
if (expectedTime <= currentTime) {
// Contention may exist here, but it's okay.
latestPassedTime.set(currentTime);
return true;
} else {
// 超出阈值,则等待
}
这句注释意味着在这个代码段中可能存在竞争(即多个线程同时访问和修改 latestPassedTime),但这种竞争是可以接受的。当多个请求同时到达此判断,可能会出现多个请求都判断为可以通过的情况。然而,由于排队等待这个场景是用于平滑处理流量,短暂的竞争不会对系统稳定性产生严重影响,所以可以容忍这种竞争。对我们实际业务的影响就是可能会超出一丢丢的限流阈值,但不会很离谱,在可接受范围内
排队等待设置count>1000时造成的流控失效
计算每个请求通过时间间隔的公式为:long costTime = Math.round(1.0 * (acquireCount) / count * 1000)
// 假设我们设置 QPS 的阈值为 1100 时
// 计算两次请求通过间隔时间
long costTime = Math.round(1.0 * (acquireCount) / count * 1000);
⬇️
long costTime = Math.round(1.0 * (1) / 1100 * 1000) 约等于 0.9ms
结果约等于 0.9ms,是小于 1ms 的,源码中使用 Math.round(0.9) 取整后值为 1
假设我设置 QPS 阈值大于 2000,那么会出现计算出来的结果小于 0.5,也就是Math.round(小于0.5) 取整后值为 0
结论:Sentinel 排队等待流控效果支持的QPS阈值不能超过1000,如果超过 1000,且 costTime 计算结果大于等于 0.5 的话,都认为是间隔时间 1 毫秒;如果 costTime 计算结果小于 0.5 的话,则认为配置失效,相当于没有配置此条流控规则
反馈的Issue
Warm Up
Warm Up 又称冷启动,是一种限流策略,适用于系统启动时或长时间无流量后突然接收到大量请求的场景。在这种情况下,为了保护系统,限流策略会逐步增加系统的处理能力,直到达到设定的阈值。这种策略有助于避免在高并发情况下系统过载或宕机
令牌桶原理
核心思想: 通过控制令牌生成和消耗的速率来实现平滑地限制请求速率, 同时允许一定程度的突发流量
特点:
-
支持突发流量:令牌桶算法允许在限流之内应对突发流量,有助于提高系统的响应能力
-
平滑处理速率:和漏桶算法一样,令牌桶算法也可以平滑地处理流量,避免处理速率的突变
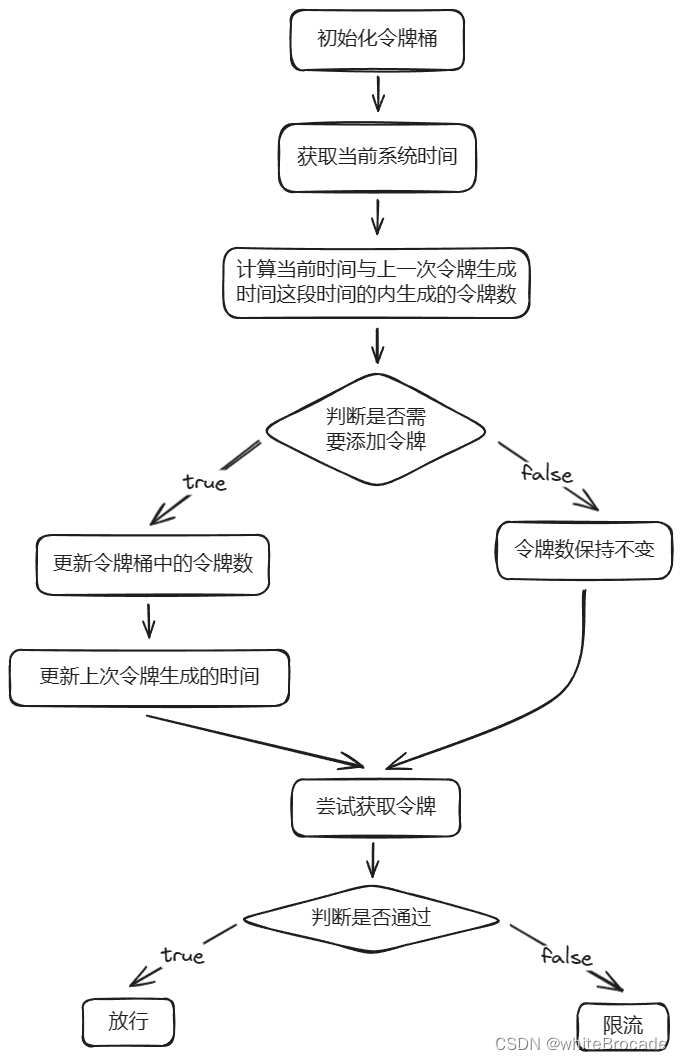
实现步骤
- 初始化令牌桶,设置令牌桶容量和生成速率。
- 当有新请求到来时,检查令牌桶中是否有足够的令牌。
- 如果有足够的令牌,允许请求通过,并从令牌桶中扣除相应数量的令牌。
- 如果没有足够的令牌,拒绝请求。
- 以固定速率向令牌桶中添加令牌,直到达到令牌桶容量
Java实现
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
public class TokenBucket {
// 令牌桶的容量
private final int capacity;
// 令牌生成速度,也就是每秒钟产生多少个令牌
private final int tokensPerSecond;
// 当前桶内的令牌数量
private final AtomicInteger currentTokens;
// 上一次令牌生成时间, 用于辅助计算本次请求需要新增多少令牌
private final AtomicLong lastRefillTime;
// 初始化
public TokenBucket(int capacity, int tokensPerSecond) {
this.capacity = capacity;
this.tokensPerSecond = tokensPerSecond;
this.currentTokens = new AtomicInteger(capacity);
this.lastRefillTime = new AtomicLong(System.currentTimeMillis());
}
/**
* true:放行
* false:限流
*/
public synchronized boolean tryAcquire(int tokens) {
// 填充令牌
refill();
// 规则判断
// refill() 已经将桶内剩余令牌数(currentTokens)更新为最新值,那么我们直接判断当前桶内剩余令牌数是不是大于申请的令牌数,如果大于,则返回 false,代表没有足够令牌,反之,返回 true,代表此次请求放行
return currentTokens.addAndGet(-tokens) >= 0;
}
// 填充令牌
private void refill() {
// 获取当前系统时间
long currentTime = System.currentTimeMillis();
// 用当前系统时间 - 上一次令牌生成时间 得出两次生成令牌需要间隔多久ms
long timeSinceLastRefill = currentTime - lastRefillTime.get();
// 得出上一次令牌生成时间到现在这段时间内,应该生成多少令牌
int tokensToAdd = (int) (timeSinceLastRefill * tokensPerSecond / 1000);
// 添加if判断是为了每次都执行更新操作
if (tokensToAdd > 0) {
// 更新当前令牌数, Math.min()保证令牌桶不会超出容量阈值
int newTokenCount = Math.min(capacity, currentTokens.get() + tokensToAdd);
currentTokens.set(newTokenCount);
// 更新上一次令牌生成时间为当前系统时间, 方便后续补充令牌的时计算时间间隔
lastRefillTime.set(currentTime);
}
}
}
原理流程图如下
源码实现
相关成员变量
public class WarmUpController implements TrafficShapingController {
// FlowRule.count QPS阈值
protected double count;
// 默认3,冷却因子
private int coldFactor;
// 警戒令牌数量,区分系统冷热状态
// 小于warningToken为热状态,走正常逻辑,允许QPS最大为阈值count
// 大于warningToken为状态,允许QPS不超过阈值count
protected int warningToken = 0;
// 令牌最大数量
private int maxToken;
// 斜率 固定等于 (coldFactor - 1.0) / count / (maxToken - warningToken),冷状态时的爬升QPS速度
protected double slope;
// 令牌桶
protected AtomicLong storedTokens = new AtomicLong(0);
// 上次投放令牌的时间,用于计算本次需要新增多少令牌
protected AtomicLong lastFilledTime = new AtomicLong(0);
}
核心参数
- QPS 阈值(
count):这个参数表示系统在正常运行状态下允许的最大QPS。在冷启动期间,系统允许的 QPS 不会直接到达count值,而是会逐渐增加,直到达到这个count阈值为止,这样就能让我们系统接收到的流量是一个平滑上升的状态,而不是瞬间打满。 - 冷启动时长(
warmUpPeriodInSec):这个参数表示系统需要多长时间从冷启动状态到正常运行状态。- 比如我们限制 QPS 为 100,再比如我们设置冷启动时长为 10s,那么可能第 1s 只允许 10 个请求进来,第 2s 可能允许15 个请求进来,就这样逐步递增,直至递增到 100 为止。因此,冷启动时长越长,系统在冷启动期间允许的 QPS 将越低,直到冷启动完成。
- 冷启动因子(
coldFactor):它是一个大于 1 的数字, 这个参数表示系统在最冷的时候(冷启动刚开始时)允许的 QPS 与正常运行状态下允许的 QPS 之比。此参数直接影响冷启动期间允许的 QPS 数,冷启动因子越大,冷启动期间允许的 QPS 将越低, 预热速度越慢
三个核心属性
- 告警值
- 系统最冷时候的剩余令牌数
- 斜率
public class WarmUpController implements TrafficShapingController {
private void construct(double count, int warmUpPeriodInSec, int coldFactor) {
if (coldFactor <= 1) {
throw new IllegalArgumentException("Cold factor should be larger than 1");
}
this.count = count;
this.coldFactor = coldFactor;
// 1. 告警值,小于告警值系统就进入正常运行期
warningToken = (int)(warmUpPeriodInSec * count) / (coldFactor - 1);
// 2. 系统最冷时候的剩余Token数
maxToken = warningToken + (int)(2 * warmUpPeriodInSec * count / (1.0 + coldFactor));
// 3. 斜率
slope = (coldFactor - 1.0) / count / (maxToken - warningToken);
}
}
warningToken: 系统从冷启动状态转为正常运行状态的阈值,即当剩余令牌数低于这个值时,系统认为已完成冷启动。而maxToken表示系统最冷时刻(冷启动刚开始时)的剩余令牌数maxToken: 冷启动过程中,剩余令牌数能够从maxToken逐渐减少至warningToken。在这个过程中,系统允许的 QPS 会逐渐增加,直到达到正常运行状态下的 QPS 阈值(2 * warmUpPeriodInSec * count)这部分用于计算从预热阶段到稳定阶段之间的令牌数量差。在这部分公式中,2 是一个缓冲因子,用于在预热阶段和稳定阶段之间留出一定的缓冲空间,使流量限制系统能够更平滑地过渡/(1.0 + coldFactor)将缓冲令牌数量除以(1.0 + coldFactor)的目的是在保持平滑过渡的同时,根据冷启动因子调整缓冲区的大小。当coldFactor增加时,过渡期间需要的缓冲令牌数量会减少,这是因为限流提升速度更慢,系统有更多的时间逐步调整到稳定阶段的最大吞吐量warningToken + (int) (2 * warmUpPeriodInSec * count / (1.0 + coldFactor))保证了剩余令牌数能够从maxToken逐渐减少至warningToken,并且在这个过程中,系统允许的 QPS 会逐渐增加,直到达到正常运行状态下的 QPS 阈值
slope: 表示当剩余令牌数从maxToken逐渐减少至warningToken时,允许的 QPS 如何逐渐增加(coldFactor - 1.0) / count:这部分表示冷启动过程中,允许的 QPS 与正常运行状态下的 QPS 之间的比例。coldFactor是一个大于 1 的数,表示冷启动时系统允许的最小 QPS 与正常运行状态下的 QPS 之间的比例。通过使用(coldFactor - 1.0),我们将这个比例调整为冷启动期间允许的最大 QPS 与正常运行状态下的 QPS 之间的比例/(maxToken - warningToken):这部分表示过程中剩余令牌数的范围。通过将前面得到的比例除以剩余令牌数的范围,我们可以得到一个斜率值,用于表示冷启动过程中剩余令牌数如何影响允许的 QPS
Warm Up中包含两个时期
- 冷启动期间: 桶内剩余令牌数大于等于
warningToken告警值时期 - 冷启动结束: 桶内剩余令牌数小于
warningToken告警值
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
long passQps = (long) node.passQps();
long previousQps = (long) node.previousPassQps();
// 根据上一个时间窗口的QPS,调整令牌数量
syncToken(previousQps);
long restToken = storedTokens.get();
// 当桶内剩余令牌 >= 告警值时,代表正处于冷启动期间,即系统处于业务低峰期, 需要逐步加量控制QPS增长,不能一下子就达到正常的限流水平
if (restToken >= warningToken) {
// 如果剩余token相对比较充足,大于警戒线,代表系统处于业务低峰期,需要warm up,动态计算QPS阈值
long aboveToken = restToken - warningToken;
// 计算得到QPS警戒阈值warningQps
double warningQps = Math.nextUp(1.0 / (aboveToken * slope + 1.0 / count));
// 如果 获取令牌数量 + 当前时间窗口qps 小于 QPS警戒阈值
if (passQps + acquireCount <= warningQps) {
// 放行
return true;
}
} else {
// 如果剩余token不是很充足,小于警戒线,代表系统处于非业务低峰期,要严格控制QPS
// 逻辑同DefaultController
if (passQps + acquireCount <= count) {
return true;
}
}
return false;
}
/**
* 获取令牌桶内剩余令牌数以及更新令牌桶
* 方法参数传递进来的是 前一个时间窗口的 QPS,也就是上一秒通过的 QPS数。
*/
protected void syncToken(long prePassQps) {
// 获取当前时间 ms
long currentTime = TimeUtil.currentTimeMillis();
// 将当前时间ms转换为 s
currentTime = currentTime - currentTime % 1000;
// 获取上一次更新令牌桶的时间
long oldLastFillTime = lastFilledTime.get();
// 如果上一次更新令牌桶的时间和当前时间一样,或者发生了时钟回拨等情况导致比当前时间还小,那么就无需更新,直接 return 即可
if (currentTime <= oldLastFillTime) {
return;
}
// 先获取令牌数量
long oldValue = storedTokens.get();
// 调用 coolDownTokens 方法得到最新令牌数
long newValue = coolDownTokens(currentTime, prePassQps);
// cas 更新令牌桶
if (storedTokens.compareAndSet(oldValue, newValue)) {
// 当前令牌数 - 前一秒的令牌数 = 最新令牌数。
long currentValue = storedTokens.addAndGet(0 - prePassQps);
if (currentValue < 0) {
storedTokens.set(0L);
}
// 更新上一次填充令牌桶的时间为当前时间
lastFilledTime.set(currentTime);
}
}
时钟回拨: 指服务器的硬件时钟或者网络时钟发生了不准确或者校准的情况,导致服务器的
时间倒退或者跳跃
private long coolDownTokens(long currentTime, long prePassQps) {
// 获取当前令牌桶令牌数
long oldValue = storedTokens.get();
long newValue = oldValue;
// 添加令牌的判断前提条件:
// 当令牌的消耗程度远远低于告警线的时候
if (oldValue < warningToken) {
// 如果小于告警值,则说明系统已经处于冷启动结束的阶段了,也就是桶内令牌数没达到冷启动预阈值,此时需要较快地向令牌桶中添加令牌
// 添加令牌公式: 在当前令牌数量的基础上,加上从上次填充令牌到现在经过的时间(以秒为单位)乘以令牌生成速率(count)
newValue = (long)(oldValue + (currentTime - lastFilledTime.get()) * count / 1000);
} else if (oldValue > warningToken) { // 如果大于告警值,说明系统正处于冷启动阶段,此时继续如下判断
// 当前的通过量(QPS)是否小于平均令牌生成速率(count)除以冷却因子(coldFactor)。如果满足这个条件,说明系统当前的负载较低,可以继续向令牌桶中添加令牌
if (prePassQps < (int)count / coldFactor) {
// 表示在当前令牌数量的基础上,加上从上次填充令牌到现在经过的时间(以秒为单位)乘以令牌生成速率(count)
// 和刚刚一样
newValue = (long)(oldValue + (currentTime - lastFilledTime.get()) * count / 1000);
}
}
// 确保更新后的令牌数量不超过最大令牌数量(maxToken)
return Math.min(newValue, maxToken);
}
为什么获取当前剩余令牌数的公式要用 coolDownTokens 方法得到的令牌数减去前一秒通过的令牌数?
因为我们在填充令牌时首先根据当前时间和上一次填充时间计算需要添加的令牌数量,然后将这些令牌添加到令牌桶中。因此,在计算新的令牌总数时,需要考虑到在上一个时间窗口内已经消耗掉的令牌。所以,这里用
long currentValue = storedTokens.addAndGet(0 - prePassQps);这行代码来扣除上一个时间窗口内已经通过的请求所消耗的令牌数
冷启动期间
需要解决的事
- 超出的告警值怎么计算?
- 超出的令牌个数=桶内剩余令牌数-冷启动阈值=
restToken - warningToken
- 超出的令牌个数=桶内剩余令牌数-冷启动阈值=
- 冷启动的所允许的QPS是动态递增的, 如何计算允许的QSP?
warningQps = 1.0 / (aboveToken * slope + 1.0 / count)- 当剩余令牌数超过告警值时,请求通过的速度会逐渐接近正常速度,而不是继续保持冷启动阶段的慢速度。因此,我们需要根据剩余令牌数
restToken、斜率slope和令牌生成速度count来计算此时系统允许的最大 QPS
- 判断当前已通过的QPS(
passQps)加上本次请求需要的令牌数(acquireCount)是否小于等于warningQps,如果满足这个条件,说明系统在当前剩余令牌数下,有足够的令牌处理这次请求,那么请求就可以通过
if (restToken >= warningToken) {
// 获取内剩余令牌数超过告警值的令牌个数
long aboveToken = restToken - warningToken;
// 根据公式得出系统允许的 QPS,其实就是根据斜率等字段计算出来的
double warningQps = Math.nextUp(1.0 / (aboveToken * slope + 1.0 / count));
// 如果当前时间窗口通过的 QPS + 客户端申请的令牌数 小于等于 冷启动告警值,那就代表允许通过。
if (passQps + acquireCount <= warningQps) {
return true;
}
}
return false;
冷启动结束
利用当前时间窗口通过的 QPS 数 + 客户端申请的令牌数,看此值是否超出阈值,超出则返回 false, 反之返回 true,放行
else {
if (passQps + acquireCount <= count) {
return true;
}
return false;
}
预热可视化例子
我们限制 QPS 阈值为 100,也就是 count = 100,那么我们分别列举冷启动时长为 1s、3s、5s、7s、9s、10s 时的情况。我们将其制作成表格,展示在不同冷启动时长下,每秒允许的请求数量。如下:
| 冷启动时长 (秒) | 第 1 秒 | 第 2 秒 | 第 3 秒 | 第 4 秒 | 第 5 秒 | 第 6 秒 | 第 7 秒 | 第 8 秒 | 第 9 秒 | 第 10 秒 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 33 | 100 | ||||||||
| 3 | 33 | 66 | 100 | |||||||
| 5 | 33 | 50 | 66 | 83 | 100 | |||||
| 7 | 33 | 43 | 53 | 63 | 74 | 84 | 100 | |||
| 9 | 33 | 40 | 47 | 54 | 61 | 68 | 75 | 82 | 100 | |
| 10 | 33 | 39 | 45 | 51 | 57 | 63 | 69 | 75 | 81 | 100 |
表格中的数值表示在每个冷启动时长下,每秒允许的请求数量。例如,在冷启动时长为 3 秒时,第 1 秒允许 33 个请求,第 2 秒允许 66 个请求,第 3 秒允许 100 个请求。这些数值是近似的,实际应用中可能会有细微差异
参考资料
通关 Sentinel 流量治理框架 - 编程界的小學生
Sentinel源码(四)ProcessorSlot(中)