1、Java当中的基本数据类型
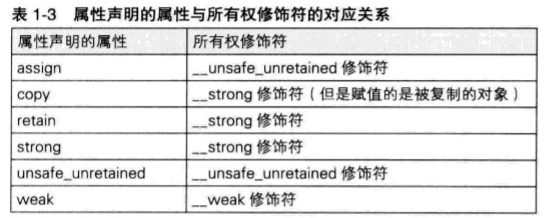
Java中常见的数据类型及其对应的字节长度和取值范围如下:
- byte:1字节,取值范围为-128到127。
- short:2字节,取值范围为-32,768到32,767。
- int:4字节,取值范围为-2,147,483,648到2,147,483,647。
- long:8字节,取值范围为-9,223,372,036,854,775,808到9,223,372,036,854,775,807。
- float:4字节,取值范围约为±3.4E-45到±3.4E+38。
- double:8字节,取值范围约为±4.9E-324到±1.8E+308。
- char:2字节(Unicode编码),取值范围为0到65,535。
- boolean:1字节,只有两个取值true和false。
注意:这里的取值范围是指整数类型的正负数范围,浮点数的精度和表示范围与具体实现有关。
2、JVM vs JDK vs JRE
JVM
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
【什么是字节码:Java字节码是一种特定的二进制格式,Java字节码由一系列的操作码(opcode)和操作数构成,每个操作码通常占用一个字节,指示JVM执行特定的操作,如加载、存储、计算、方法调用等】
JDK 和 JRE
JDK(Java Development Kit)和JRE(Java Runtime Environment)是Java平台的两个关键组件,它们之间有明显的区别:
-
JDK(Java Development Kit):
- JDK是Java开发工具包,它是为Java开发者提供的一个完整的软件开发环境。
- 包含了编译器(javac)、调试器(jdb)、文档生成器(javadoc)和其他工具,这些工具用于创建、编译、测试和打包Java应用程序。
- JDK中还包含了JRE,因为开发过程中需要运行和测试Java程序。
-
JRE(Java Runtime Environment):
- JRE是Java运行时环境,它是用于执行已编译好的Java应用程序(即字节码文件.class)所需要的全部软件系统。
- 它包括Java虚拟机(JVM)以及Java核心类库等支持Java程序运行的基本组件。
- 对于普通用户而言,如果只需要运行Java应用程序而不需要进行开发工作,则只需安装JRE即可。
总结来说,JDK是给Java开发者使用的,它不仅提供了运行Java程序所需的环境(JRE),还包括了一系列开发工具。而JRE则是运行Java程序的基础,是所有Java应用程序运行的必备条件,但不包含任何开发工具。
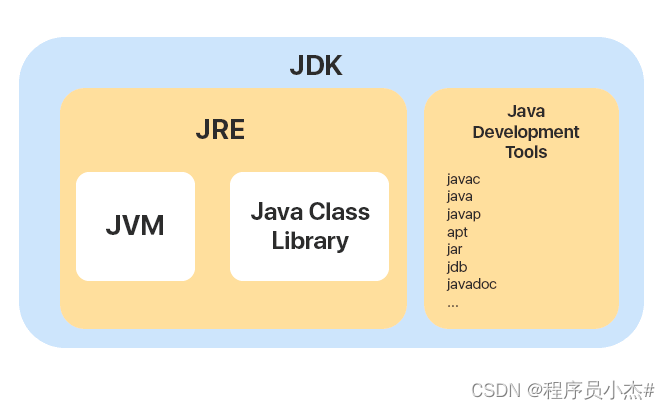
不过,从 JDK 9 开始,就不需要区分 JDK 和 JRE 的关系了,取而代之的是模块系统(JDK 被重新组织成 94 个模块)+ jlinkopen in new window 工具 (随 Java 9 一起发布的新命令行工具,用于生成自定义 Java 运行时映像,该映像仅包含给定应用程序所需的模块) 。并且,从 JDK 11 开始,Oracle 不再提供单独的 JRE 下载。
3、什么是字节码?采用字节码的好处是什么
字节码是一种中间代码表示形式,它通常是指Java源代码经过编译后生成的一种机器无关的二进制格式。在Java中,当开发人员编写好.java文件(Java源代码)并使用Java编译器(javac)进行编译时,编译器并不会直接生成针对特定平台的机器码,而是生成一种被Java虚拟机(JVM)理解的指令集,这种指令集即被称为字节码,存储在.class文件中。
采用字节码的好处主要包括以下几点:
-
跨平台性:由于字节码不依赖于任何特定的处理器架构,可以在任何安装了Java虚拟机的平台上运行,实现了“一次编译,到处运行”(Write Once, Run Anywhere, WORA),极大地提高了程序的可移植性。
-
安全性增强:JVM能够对字节码进行校验,确保其符合Java语言规范和安全策略,这在一定程度上增强了系统的安全性和健壮性。
-
性能优化:尽管字节码是解释执行的,但现代JVM通常包含即时编译器(Just-In-Time, JIT),可以将热点字节码转换为高效的目标机器码,从而兼顾了解释型语言的灵活性和编译型语言的良好性能。
-
抽象层级更高:字节码提供了比底层机器码更高的抽象级别,简化了实现复杂特性的过程,比如垃圾回收、动态加载类等,这些特性对于程序员来说更加透明且易于管理。
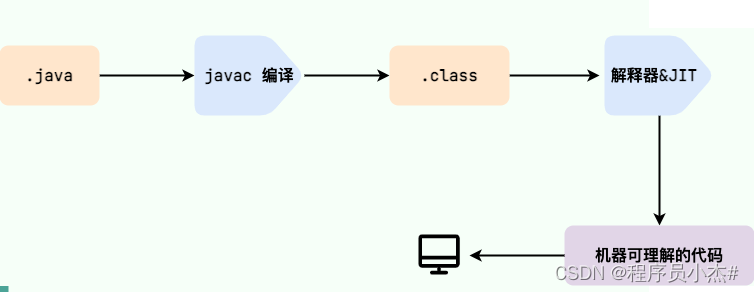
在Java中,字节码到机器码的转化主要通过Java虚拟机(JVM)实现,特别是通过JVM中的即时编译器(Just-In-Time, JIT)技术来完成。以下是这个过程的基本原理: -
源代码编译:
- 开发者编写Java源代码并使用
javac编译器将其编译成.class文件,这些文件包含的是符合JVM规范的字节码。
- 开发者编写Java源代码并使用
-
加载与验证:
- 当程序运行时,类加载器将这些
.class文件加载进JVM。 - JVM会对字节码进行合法性校验,确保其遵循语法规则和安全约束。
- 当程序运行时,类加载器将这些
-
解释执行:
- 初始阶段,JVM内置的解释器逐条读取字节码指令并解释执行,即将每一条字节码转换为对应平台的机器指令。
-
即时编译(JIT):
- 为了提高性能,JVM采用了即时编译技术,它观察程序的运行情况,识别出热点代码(即频繁执行的代码段)。
- 对于热点代码,JIT编译器会选择性地将它们从字节码转换成本地机器码,并进行优化,如方法内联、消除冗余操作等,生成的机器码会被直接缓存起来供后续调用。
- HotSpot JVM是目前广泛使用的JVM实现,其中包含了C1(Client Compiler)和C2(Server Compiler)两种不同的即时编译器策略,分别针对不同场景下的性能优化。
通过这种方式,Java能够兼顾跨平台性和运行效率,既实现了“一次编写,到处运行”的特性,又能通过JIT编译器提供接近于原生编译语言的性能。
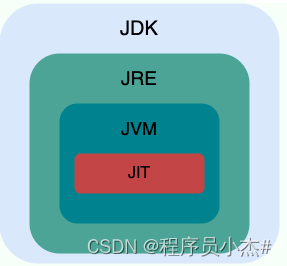
JDK、JRE、JVM、JIT 这四者的关系如下图所示。
4、为什么说 Java 语言“编译与解释并存”?
Java语言被描述为“编译与解释并存”,这是因为Java程序的执行过程结合了编译型语言和解释型语言的特点。
-
编译阶段:
- Java源代码首先通过Java编译器(javac)进行编译。编译器将.java源文件转换为一种中间表示形式,即字节码(Bytecode),这些字节码存储在.class文件中。字节码是一种平台无关的指令集,它不是直接针对特定CPU架构的机器码。
-
解释与即时编译阶段:
- 当运行Java程序时,类加载器会加载这些编译好的字节码到Java虚拟机(JVM)中。
- JVM并不直接执行字节码,而是对字节码进行解释或即时编译(Just-In-Time, JIT)后执行。
- 解释执行:JVM内置的解释器逐条读取字节码并解释执行,即将每一条字节码转换成对应的机器指令来执行。
- 即时编译:为了提高性能,JVM还可以选择性地将热点代码(经常被执行的代码)进行即时编译成本地机器码,这样就可以绕过解释步骤,直接以更高效的方式执行。即时编译可以带来接近于静态编译语言的执行速度。
因此,Java兼具编译型语言的预编译特性(生成跨平台的字节码)和解释型语言的动态执行特性(通过JVM解释或即时编译执行字节码),从而实现了“编译与解释并存”的特点。
5、AOT 有什么优点?为什么不全部使用 AOT 呢?
JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation) 。和 JIT 不同的是,这种编译模式会在程序被执行前就将其编译成机器码,属于静态编译(C、 C++,Rust,Go 等语言就是静态编译)。AOT 避免了 JIT 预热等各方面的开销,可以提高 Java 程序的启动速度,避免预热时间长。并且,AOT 还能减少内存占用和增强 Java 程序的安全性(AOT 编译后的代码不容易被反编译和修改),特别适合云原生场景。JIT 与 AOT 两者的关键指标对比:
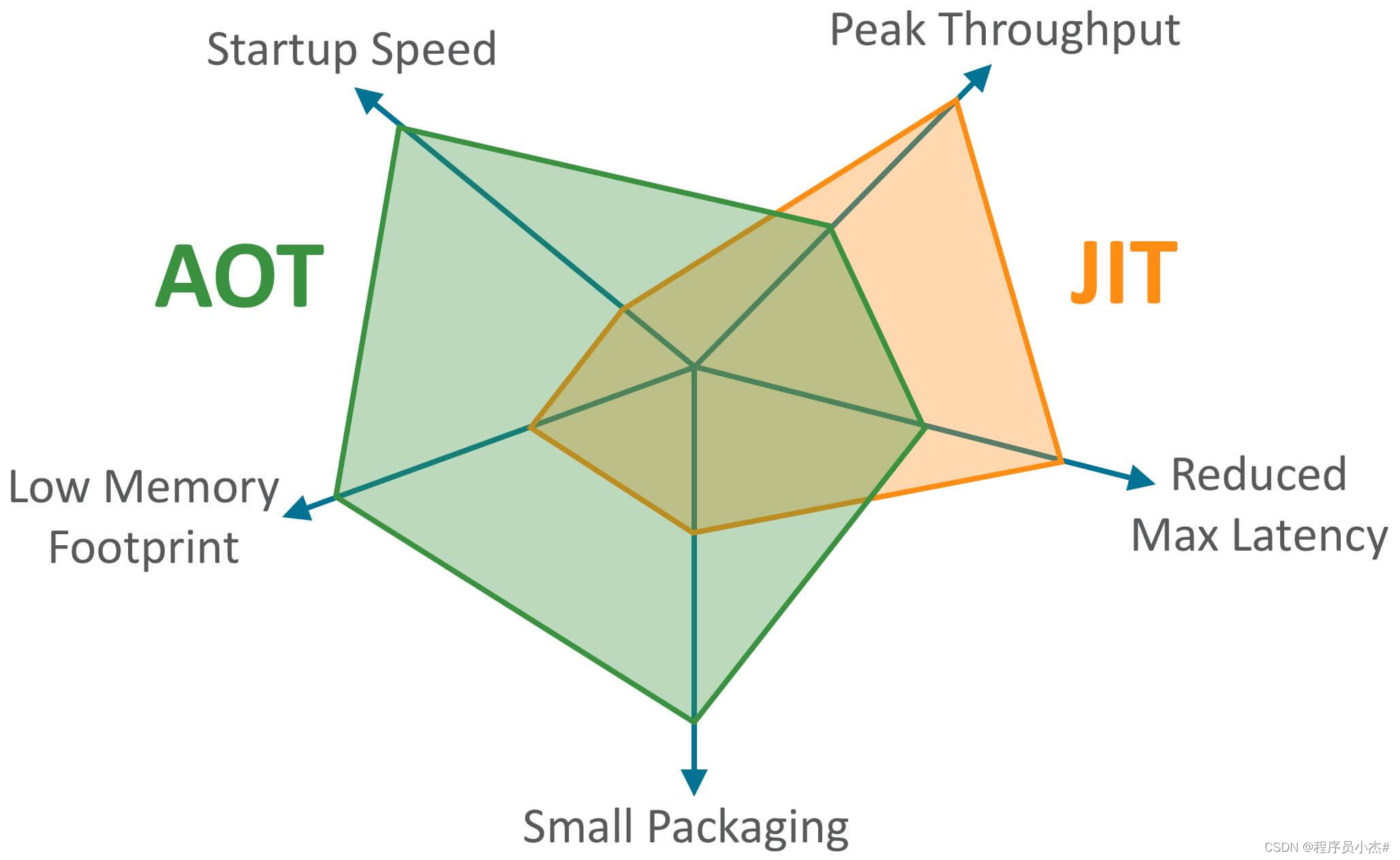
可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。提到 AOT 就不得不提 GraalVMopen in new window 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档:https://www.graalvm.org/latest/docs
6、面向对象和面向过程的区别
面向对象编程(Object-Oriented Programming, OOP)和面向过程编程(Procedural Programming)是两种不同的编程范式,它们在程序设计的思维方式、组织结构以及解决问题的方法上有显著区别:
面向过程编程:
- 核心思想:面向过程以过程(或称为函数)为中心,强调一系列操作步骤的执行流程,通过将复杂的任务分解成一系列可重用的函数来实现功能。
- 结构特点:关注的是步骤和顺序,把解决问题的过程抽象为一个接一个的函数调用,每个函数通常完成一项特定的任务。
- 数据与逻辑的关系:数据和处理这些数据的过程通常是分离的,数据结构独立,而函数作为外部实体对数据进行操作。
面向对象编程:
- 核心思想:面向对象以对象为核心,强调封装性、继承性和多态性。它模拟现实世界中的实体(即对象),每个对象包含数据(属性)和操作数据的方法(行为)。
- 封装:将数据和处理数据的代码封装在一起,形成一个保护屏障,防止外部直接访问内部细节。
- 继承:子类可以继承父类的属性和方法,并可以扩展新的属性和方法,实现代码复用。
- 多态:允许不同类型的对象对同一消息做出不同的响应,增强系统的灵活性和扩展性。
- 结构特点:面向对象的程序由多个相互协作的对象组成,每个对象都负责其自身的状态管理和行为实现,通过发送消息(方法调用)进行通信。
- 数据与逻辑的关系:在面向对象中,数据和操作数据的逻辑紧密绑定,数据和方法组合成一个整体——对象,体现了“万物皆对象”的概念。
简单总结一下,面向过程更注重如何一步一步地解决一个问题,而面向对象更侧重于通过对象之间的交互来描述系统,更加模块化且易于维护和扩展。在实际应用中,现代编程语言往往结合了这两种思想,但在架构层面会根据问题特性和需求选择更适合的编程方式。
7、创建一个对象用什么运算符?对象实体与对象引用有何不同?
创建一个Java对象通常使用 new 运算符。通过 new 关键字,可以实例化一个类,具体操作包括在内存的堆(heap)中分配空间,并调用相应的构造方法初始化该对象。
例如,在Java中创建一个名为 MyClass 的对象实例:
MyClass obj = new MyClass();
在这段代码中:
MyClass()是类的构造函数,用于初始化新创建的对象。new关键字负责在内存中为MyClass对象分配存储空间。obj是一个引用变量,它存放在栈(stack)内存中,指向堆内存中刚刚创建的对象实体。
对象实体与对象引用的区别:
-
对象实体:
- 对象实体是实际存在的、包含数据和行为的一个具体实例,它占据了一块内存空间。
- 它包含了类定义中的所有属性值以及可能的方法实现(状态和行为)。
-
对象引用:
- 对象引用是一个变量,其类型对应于所引用的对象类型。
- 引用并不直接存储对象的内容,而是存储了对象在内存中的地址或指针。
- 通过对象引用,我们可以访问和操作堆内存中对象实体的属性和方法。
形象地说,对象实体就像是一块特定内容的土地,而对象引用则像是这块土地的地图坐标,通过这个坐标我们能找到并操作那块土地上的资源。
8、对象的相等和引用相等的区别
在Java中,对象的相等和引用相等是两种不同的概念:
-
对象的相等性:
- 当我们谈论两个对象是否相等时,通常是指它们的内容或状态相同。在Java中,通过重写
equals()方法来定义对象之间逻辑上的相等性。 - 例如,如果你有两个
Person对象,它们的名字、年龄以及其他属性都相同,那么这两个Person对象在逻辑上就是相等的(前提是Person类已经正确地重写了equals()方法)。 - 默认情况下,所有Java类继承自
Object类,其中提供的equals()方法仅检查对象引用是否指向同一内存位置,这与引用相等是一致的。但为了实现基于对象内容的比较,通常需要在子类中覆盖这个方法。
- 当我们谈论两个对象是否相等时,通常是指它们的内容或状态相同。在Java中,通过重写
-
引用相等:
- 引用相等比较简单,它关注的是两个对象引用变量是否指向内存中的同一个对象实例。
- 在Java中,使用
==运算符可以测试两个对象引用是否指向同一个内存地址。 - 如果
a == b返回true,那么说明a和b都指向内存中的同一个对象实体;如果返回false,则说明它们各自指向不同的对象实体,即使这些实体的内容可能完全相同。
总结来说,对象相等性是一种逻辑上的概念,由程序员根据业务需求决定如何判断两个对象是否相等;而引用相等性则是纯粹的技术层面的概念,只关心两个引用是否指向相同的内存位置。
9、构造方法有哪些特点?是否可被 override?
构造方法在Java等面向对象编程语言中具有以下特点:
- 与类同名:构造方法的名称必须与它所在的类的名称完全相同。
- 无返回类型:构造方法没有返回类型,既不写void,也不写任何其他数据类型。
- 作用:主要用于初始化新创建的对象实例,设置其初始状态。当使用
new关键字创建一个对象时,会自动调用相应的构造方法。 - 默认构造器:如果类中没有定义任何构造方法,编译器会提供一个默认(无参)构造器。一旦定义了至少一个构造方法,编译器将不再自动生成默认构造器。
- 重载:构造方法可以有多个,即可以根据参数的不同进行重载。
关于是否可被override(覆盖):
- 构造方法不能被子类继承和覆盖(override)。这是因为构造方法的作用是初始化当前类的新实例,并不是从父类继承而来的成员方法。子类需要通过
super(...)关键字调用父类的构造方法来完成对父类部分的初始化,但这并不是覆盖操作,而是构造方法链的一部分。
因此,构造方法的特点决定了它们不能被子类覆盖,但可以在同一个类中通过不同的参数列表实现重载。
10、接口和抽象类有什么共同点和区别?
接口和抽象类在Java等面向对象编程语言中都用于实现抽象化,它们有以下共同点和区别:
共同点:
- 都不能被实例化:接口(Interface)和抽象类(Abstract Class)自身都不能直接创建对象。
- 包含抽象方法:接口中的所有方法默认都是抽象的(public abstract),而抽象类可以包含抽象方法(abstract method),这些抽象方法都没有具体的实现。
- 实现多态性:通过继承或实现,子类需要提供抽象方法的具体实现,从而支持多态性的实现。
区别:
-
定义方式与关键字:
- 抽象类使用
abstract关键字声明,可以包含抽象方法以及非抽象(具体实现)的方法、常量成员变量和静态方法。 - 接口使用
interface关键字声明,只能包含抽象方法(Java 8之后还可以包含默认方法和静态方法)和常量成员变量(Java 9引入了私有接口方法和私有静态方法)。
- 抽象类使用
-
方法修饰符与实现:
- 在抽象类中,方法可以有各种访问修饰符(public、protected、private),且可以包含非抽象的公共方法、受保护方法和私有方法。
- 接口中所有方法默认为
public abstract,从Java 8开始,接口可以有default方法(提供了默认实现)和static方法,但不能有非公开的或非抽象的实例方法。
-
继承与实现限制:
- 一个类只能单继承自一个抽象类(不考虑Java 17的sealed类特性),但可以同时实现多个接口。
- 类在继承抽象类时,可以选择覆盖部分或全部抽象方法;而在实现接口时,必须实现接口中所有的未实现方法。
-
目的与用途:
- 抽象类主要用于代码复用和设计多层次的继承体系结构,它允许定义部分实现,并强制子类实现剩余部分。
- 接口更多地作为契约或者规范来使用,用来规定类应该遵循的行为规范,强调的是设计上的耦合关系而不是继承层次。通常用于实现组件之间的松耦合。
11、深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
在Java中,深拷贝和浅拷贝是两种不同的对象复制方式,它们的区别主要在于是否真正复制了对象内部所引用的对象。
-
浅拷贝(Shallow Copy):
当执行浅拷贝时,系统会创建一个新的对象,新对象的属性与原对象相同,但如果原对象的字段引用了其他对象,则这些引用仍然指向原来的对象。换句话说,对于基本类型字段,浅拷贝会直接复制其值;而对于引用类型字段(如数组、集合或自定义对象),浅拷贝仅复制引用地址,而不是复制引用对象的内容。例如:
public class Sheep { private String name; private int age; private List<String> favoriteFoods; // 构造函数,getter和setter省略 public Sheep clone() { try { // Java中的默认clone方法实现的就是浅拷贝 return (Sheep) super.clone(); } catch (CloneNotSupportedException e) { throw new AssertionError(); // 实际上Java的所有类都支持clone() } } } // 使用 Sheep original = new Sheep("Dolly", 2, new ArrayList<>()); original.getFavoriteFoods().add("grass"); Sheep shallowCopy = original.clone(); // 此时shallowCopy和original共享同一个favoriteFoods列表 shallowCopy.getFavoriteFoods().add("carrots"); // 改变shallowCopy的favoriteFoods会影响到original -
深拷贝(Deep Copy):
深拷贝不仅复制对象本身,还递归地复制其引用的对象,直到所有的引用都是基本类型的值为止。因此,通过深拷贝得到的新对象完全独立于原对象,即使改变新对象内部引用对象的状态,也不会影响到原对象。对于上述示例,如果要实现深拷贝,我们需要手动复制
favoriteFoods列表:public class Sheep implements Cloneable { // ... @Override public Sheep clone() throws CloneNotSupportedException { Sheep cloned = (Sheep) super.clone(); // 创建favoriteFoods的新副本,实现深拷贝 cloned.favoriteFoods = new ArrayList<>(this.favoriteFoods); return cloned; } } // 使用 Sheep original = new Sheep("Dolly", 2, new ArrayList<>()); original.getFavoriteFoods().add("grass"); Sheep deepCopy = original.clone(); deepCopy.getFavoriteFoods().add("carrots"); // 此时original和deepCopy各有独立的favoriteFoods列表,互不影响 -
引用拷贝(Reference Copy):
引用拷贝(Reference Copy)在Java中指的是当一个对象的引用被赋值给另一个变量时,实际上并不是复制了对象本身,而是将原对象的引用地址复制了一份给新的变量。因此,新旧两个变量实际上指向的是堆内存中的同一个对象。
例如:
public class Sheep {
private String name;
// 构造函数、getter和setter省略
}
// 创建一个Sheep对象
Sheep original = new Sheep("Dolly");
// 引用拷贝
Sheep referenceCopy = original;
// 此时original和referenceCopy指向的是同一个对象
referenceCopy.setName("Eve");
// 输出original的名字,会发现已经被修改为"Eve"
System.out.println(original.getName()); // 输出:Eve
在这个例子中,referenceCopy并没有创建一个新的Sheep对象,它只是持有original所指向的那个对象的引用。所以对referenceCopy进行操作时,实际上是直接修改了原始对象original的状态。
12、Java当中浅拷贝和引用拷贝的区别?
在Java中,浅拷贝和引用拷贝实际上描述的是同一现象的不同方面:
引用拷贝:
当一个对象被赋值给另一个变量时,或者通过简单的赋值操作创建所谓的“副本”时,实际上并没有复制对象本身,而是将原对象的引用(内存地址)复制给了新的变量。这样新旧两个变量就指向了堆内存中的同一个对象实例。
MyObject original = new MyObject();
MyObject referenceCopy = original;
在这段代码中,referenceCopy是original的一个引用拷贝,它们指向相同的内存空间。
浅拷贝:
在Java中,如果一个类实现了Cloneable接口并重写了Object类的clone()方法,但未对包含的对象引用进行特殊处理,这时调用clone()方法得到的新对象就是进行了浅拷贝。浅拷贝同样不会复制对象内部所引用的对象,而只复制对象本身(非引用类型)的属性值。对于引用类型的字段,它只是复制了该引用的值(即内存地址),因此原始对象和克隆对象对此类字段引用的对象仍然共享。
class MyObject implements Cloneable {
private String primitiveField;
private AnotherObject refField;
// 简化的clone()实现,默认为浅拷贝
@Override
public MyObject clone() {
try {
return (MyObject) super.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError(); // 不会发生,因为已经实现了Cloneable
}
}
}
MyObject shallowCopy = original.clone();
在这个例子中,shallowCopy.primitiveField会有一个与original.primitiveField不同的独立副本,但shallowCopy.refField和original.refField将引用同一个AnotherObject实例。
总结起来,在Java中浅拷贝和引用拷贝没有本质区别,都是指仅复制对象的引用而非复制引用所指向的对象实例。具体表现为,对于包含引用类型成员变量的对象进行浅拷贝时,不会创建这些成员变量所引用的对象的新副本,而是新旧对象共用同一份引用指向的数据。
13、String 为什么是不可变的?
String 类中使用 final 关键字修饰字符数组来保存字符串,所以String 对象是不可变的。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
//...
}
我们知道被 final 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,final 关键字修饰的数组保存字符串并不是 String 不可变的根本原因,因为这个数组保存的字符串是可变的(final 修饰引用类型变量的情况)。
String 真正不可变有下面几点原因:保存字符串的数组被 final 修饰且为私有的,并且String 类没有提供/暴露修改这个字符串的方法。
String 类被 final 修饰导致其不能被继承,进而避免了子类破坏 String 不可变
public final class String implements java.io.Serializable,Comparable<String>, CharSequence {
// @Stable 注解表示变量最多被修改一次,称为“稳定的”。
@Stable
private final byte[] value;
}
abstract class AbstractStringBuilder implements Appendable, CharSequence {
byte[] value;
}
14、Java 9 为何要将 String 的底层实现由 char[] 改成了 byte[] ?
Java 9 将 String 类的底层实现从 char[] 改为 byte[] 主要基于以下原因:
内存优化:在 Java 9 之前,String 对象使用 char[] 数组存储字符数据,每个 char 在 JVM 中占用 2 个字节(采用 UTF-16 编码)。然而,在许多情况下,尤其是对于只包含 ASCII 或 Latin-1 字符集的字符串,实际上只需要一个字节就可以表示。因此,将底层存储结构改为 byte[] 可以显著节省内存空间。
适应 Unicode 编码的发展:随着 Unicode 标准的普及和多语言环境的需求增加,UTF-8 编码因其可变长度编码特性而广受欢迎,它能更有效地存储非拉丁语系字符。通过使用 byte[],可以灵活地支持不同编码格式,特别是对于那些主要包含ASCII字符且不需要两个字节来表示的字符串。
GC 性能提升:由于 String 对象通常在 Java 应用程序中占据大量堆内存,减少其内存占用有助于降低垃圾收集器的压力,从而可能提高整体性能。
与 String 压缩相关:Java 9 引入了对字符串内容的压缩存储机制(称为Compact Strings),当字符串的内容完全由ISO-8859-1(Latin-1)字符组成时,可以直接存储为单字节,进一步节约内存。
综上所述,这一改动是为了更好地利用内存资源、提高内存效率以及适应现代编程环境中的多语言需求。
15、字符串拼接用“+” 还是 StringBuilder?
在Java中,当需要频繁拼接字符串时,建议使用 StringBuilder 而不是使用 “+” 运算符。这是因为:
-
性能差异:
- 使用 “+” 进行字符串拼接(尤其是在循环或者多次嵌套拼接中)会创建多个中间临时字符串对象。每次字符串拼接操作都会生成一个新的
String对象,因为String在Java中是不可变的,这意味着每进行一次拼接都需要复制原字符串内容并附加新内容到新的内存空间。 - 相比之下,
StringBuilder或StringBuffer(线程安全版本)允许在原有对象上直接修改内容,不会产生额外的对象,因此在大量字符串拼接场景下具有更高的性能。
- 使用 “+” 进行字符串拼接(尤其是在循环或者多次嵌套拼接中)会创建多个中间临时字符串对象。每次字符串拼接操作都会生成一个新的
-
内存效率:
- 使用 “+” 会产生许多短期生命周期的临时字符串,这些临时对象将被垃圾回收器处理,增加内存分配和回收的压力。
- 使用
StringBuilder可以减少内存分配次数,尤其对于长字符串或在循环中的拼接操作更为明显。
-
实际应用指导:
- 当仅进行少量字符串拼接时,“+” 的简洁性可能更具优势,并且编译器有时会对简单的 "+” 操作做优化(例如,在方法内部的字符串连接可能会被合并成一个
StringBuilder操作)。 - 对于多处或频繁的字符串拼接,尤其是性能敏感的代码段,应优先选择
StringBuilder。
- 当仅进行少量字符串拼接时,“+” 的简洁性可能更具优势,并且编译器有时会对简单的 "+” 操作做优化(例如,在方法内部的字符串连接可能会被合并成一个
使用 “+” 连接字符串:
public class StringConcatExample {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = ", ";
String str3 = "World!";
String resultUsingPlus;
// 使用 "+" 连接多个字符串
for (int i = 0; i < 10000; i++) { // 假设循环次数代表频繁度
resultUsingPlus = str1 + str2 + i + str3;
}
System.out.println(resultUsingPlus); // 输出最后的结果
}
}
使用 StringBuilder 连接字符串:
import java.lang.StringBuilder;
public class StringBuilderExample {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = ", ";
String str3 = "World!";
StringBuilder sb = new StringBuilder();
// 使用 StringBuilder 连接多个字符串
for (int i = 0; i < 10000; i++) {
sb.append(str1).append(str2).append(i).append(str3);
}
String resultUsingStringBuilder = sb.toString();
System.out.println(resultUsingStringBuilder); // 输出最后的结果
}
}
在上述例子中,当循环次数很大时,使用 StringBuilder 的版本会比使用 “+” 运算符的版本更高效,因为它避免了创建大量临时字符串对象。尤其是在实际应用中,如果循环体内部包含复杂的字符串构造逻辑,这种性能差异将更为显著。
总结来说,如果你关注程序性能,特别是在循环、大字符串构建或高并发场景下,应该使用 StringBuilder 来代替 “+” 进行字符串拼接。而在简单的一次性拼接或调试代码中,“+” 运算符的可读性和便捷性则更优。
16、String.equals() 和 Object.equals() 有何区别?
String.equals() 和 Object.equals() 方法在 Java 中的主要区别在于它们的行为和用途。
equals() 方法在 Object 类中提供了一个默认的实现,该实现仅仅是检查两个对象引用是否指向内存中的同一个对象。
而在 String 类中,equals() 方法被重写以提供基于字符串内容相等性的比较。
Object.equals() 的行为:
public boolean equals(Object obj) {
return (this == obj);
}
这意味着如果你使用 Object 类的默认 equals() 方法比较两个 String 对象,它只会检查这两个对象是否是同一个对象实例,而不是比较它们所包含的字符序列是否相同。
String.equals() 的行为:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
在这个重写的方法中,String 类首先检查传入的对象是否与当前对象引用相同(即,是否是同一个实例)。
如果不是,它会进一步检查传入的对象是否为 String 类型,如果是,则逐个比较两个字符串中的字符,直到发现不匹配或者所有字符都匹配,从而判断两个字符串的内容是否相等。
案例代码:
// 使用 Object.equals()
String s1 = new String("Hello");
String s2 = new String("Hello");
System.out.println(s1.equals(s2)); // 输出:true,因为调用的是 String 类重写的 equals 方法
System.out.println(s1.getClass().getSuperclass().getMethod("equals", Object.class).invoke(s1, s2));
// 输出:false,如果强制调用 Object 类的 equals 方法,仅比较引用,所以返回 false
// 正常情况下我们不会直接使用 Object.equals() 来比较字符串内容
总结来说,在实际开发中,当你需要比较两个字符串的内容时,应始终使用 String.equals() 方法,因为它提供了基于内容的比较,这通常是期望的行为。而直接使用 Object.equals() 在处理字符串时可能无法得到预期的结果。
17、为什么要有 hashCode?
在Java中,hashCode()方法是Object类的一个基本方法,它的默认实现返回对象的内存地址的某种哈希码。这个哈希码主要用于与equals()方法协同工作,在基于散列的数据结构(如HashMap、HashSet或Hashtable)中高效地定位对象。
概念:
-
哈希码(Hash Code):它是对象的某种表示形式,通常是一个整数值。哈希码的设计目标是使得不同对象(根据业务逻辑认为不相等的对象)具有尽可能不同的哈希码,以减少冲突(即“哈希碰撞”)。
-
重写hashCode()的目的:
- 一致性:如果两个对象通过equals()判断为相等(业务逻辑上的相等),那么它们必须有相同的hashCode。
- 高效性:哈希数据结构依赖于hashCode来快速定位元素,若hashCode设计得当,可以大大加快查找速度。
-
equals()与hashCode()的关系:
- 如果两个对象equals相等,那么它们的hashCode也必须相等。
- 但是,hashCode相等并不意味着两个对象一定equals相等,因为hashCode函数可能会产生哈希冲突。
使用场景及案例讲解:
假设我们有一个Person类,包含姓名和年龄作为业务上判断两个实例是否相等的标准:
public class Person {
private String name;
private int age;
// 构造器、getter、setter...
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null || getClass() != obj.getClass())
return false;
Person person = (Person) obj;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
在这个例子中,我们重写了equals()方法,使其基于姓名和年龄来确定两个Person对象是否相等。
相应的,我们也重写了hashCode()方法,确保了当两个Person实例在业务逻辑上相等时(即他们的姓名和年龄都相同),它们生成的哈希码也是相同的。
如果我们没有重写hashCode(),当我们将一个Person实例存入到HashMap后,用另一个业务上相等但不是同一个实例的Person去查找,由于它们默认的hashCode值不同(基于不同的内存地址),即使equals方法返回true,也无法在HashMap中找到已存在的对象,这显然违背了我们的预期行为。
而正确重写hashCode之后,则能确保在这样的场景下能够正确查找到已经存储的对象。
18、Overload(重载)和Override(重写)的区别案例代码
Overload(重载)和Override(重写)是Java中两个重要的概念,它们的区别如下:
-
Overload(重载):在同一个类中,方法名相同但参数列表不同,即方法签名不同。这样可以实现多个方法共用一个方法名,但根据传递的参数类型和个数来调用不同的方法。
-
Override(重写):子类继承父类的方法,并重新实现该方法。这样可以使子类具有自己独特的行为,同时还可以保留父类原有的功能。
下面是一个简单的案例代码:
// 父类:Animal
public class Animal {
public void makeSound() {
System.out.println("动物发出声音");
}
}
// 子类:Dog,重写父类的makeSound方法
public class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("汪汪汪");
}
}
// 子类:Cat,重写父类的makeSound方法
public class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("喵喵喵");
}
}
// 测试类
public class Test {
public static void main(String[] args) {
Animal myAnimal = new Animal(); // 创建Animal对象
Animal myDog = new Dog(); // 创建Dog对象
Animal myCat = new Cat(); // 创建Cat对象
myAnimal.makeSound(); // 输出:动物发出声音
myDog.makeSound(); // 输出:汪汪汪
myCat.makeSound(); // 输出:喵喵喵
}
}
19、Java当中long和Long的区别
Java中long和Long的区别如下:
- long是基本数据类型,而Long是包装类(Wrapper Class)。
- long的默认值为0L,而Long的默认值为null。
- long占用8个字节的内存空间,而Long占用16个字节的内存空间(因为Long是一个对象,需要额外的内存来存储对象信息)。
- long的取值范围为-9223372036854775808到9223372036854775807,而Long的取值范围为-1.8E+19到1.8E+308。
- long可以使用字面量赋值,而Long必须通过new关键字创建对象来赋值。
总结:如果需要操作基本数据类型的long,建议使用long;如果需要将long作为对象进行操作,建议使用Long。
20、String、StringBuilder、StringBuffer的区别及使用场景
Java中,String、StringBuilder和StringBuffer都是用来封装字符串的类,但它们在使用时存在一些主要的区别。
-
String:
- String类的内容是不可改变的,能改变的只是其内存指向。
- 由于其不可变性,每次对String进行操作都会生成一个新的String对象,这会导致额外的内存开销和性能损失。
- 使用场景:适用于不需要修改字符串的场景,例如字符串常量、少量的变量运算等。
-
StringBuilder:
- StringBuilder是可变的,因此对其进行操作时不会生成新的对象。
- 由于其可变性,它比String更加高效,特别是在单线程环境中进行频繁的字符串操作时。
- 使用场景:适用于单线程环境中进行频繁的字符串操作。
-
StringBuffer:
- StringBuffer与StringBuilder类似,也是可变的。
- 与StringBuilder不同的是,StringBuffer是线程安全的,也就是说它是同步的。
- 使用场景:适用于多线程环境中进行字符串操作。
具体案例:
// String的使用示例
String str = "Hello World!"; // 创建一个不可变字符串对象
str += " Java"; // 这里会创建一个新的字符串对象,因为原字符串对象不可变
System.out.println(str); // 输出结果为"Hello World! Java"
// StringBuilder的使用示例
StringBuilder sb = new StringBuilder("Hello World!"); // 创建一个可变字符串对象
sb.append(" Java"); // 这里不会创建新的字符串对象,而是直接在原对象上进行修改
System.out.println(sb.toString()); // 输出结果为"Hello World! Java"
// StringBuffer的使用示例
StringBuffer sbf = new StringBuffer("Hello World!"); // 创建一个可变字符串对象(线程安全)
sbf.append(" Java"); // 这里不会创建新的字符串对象,而是直接在原对象上进行修改
System.out.println(sbf.toString()); // 输出结果为"Hello World! Java"
21、Java面向对象有哪些特征?
面向对象编程是利用类和对象编程的一种思想。万物可归类,类是对于世界事物的高度抽象,不同的事物之间有不同的关系,一个类自身与外界的封装关系,一个父类和子类的继承关系,一个类和多个类的多态关系。
万物皆对象,对象是具体的世界事物,面向对象的三大特征封装,继承,多态。封装,封装说明一-个类行为和属性与其他类的关系,低耦合,高内聚;继承是父类和子类的关系,多态说的是类与类的关系。
封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据。对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法。
属性的封装:使用者只能通过事先定制好的方法来访问数据,可以方便地加入逻辑控制,限制对属性的不合理操作;方法的封装:使用者按照既定的方式调用方法,不必关心方法的内部实现,便于使用;便于修改, 增强代码的可维护性; 继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力。
在本质上是特殊一般的关系, 即常说的is-a关系。
子类继承父类,表明子类是一-种特殊的父类,并且具有父类所不具有的一些属性或方法。
从多种实现类中抽象出一一个基类,使其具备多种实现类的共同特性,当实现类用extends关键字继承了基类(父类)后,实现类就具备了这些相同的属性。继承的类叫做子类(派生类或者超类),被继承的类叫做父类(或者基类)。
比如从猫类、狗类、虎类中可以抽象出一个动物类,具有和猫、狗、虎类的共同特性(吃、跑、叫等)。Java通过extends关键字来实现继承,父类中通过private定 义的变量和方法不会被继承,不能在子类中直接操作父类通过private定义的变量以及方法。
继承避免了对一般类和特殊类之间共同特征进行的重复描述,通过继承可以清晰地表达每一项共同特征所适应的概念范围,在一般类中定义的属性和操作适应于这个类本身以及它以下的每一层特殊类的全部对象。运用继承原则使得系统模型比较简练也比较清晰。
相比于封装和继承,Java多态是三大特性中比较难的一个,封装和继承最后归结于多态,多态指的是类和类的关系,两个类由继承关系,存在有方法的重写,故而可以在调用时有父类引用指向子类对象。
多态必备三个要素:继承,重写,父类引用指向子类对象。
22、字符串常量池的作用了解吗?
Java中的字符串常量池,也被称为字符串字面量池或者字符串缓冲区,是Java堆内存中一个特殊的区域,主要用于存储和管理字符串常量。
它的主要作用在于:
-
减少内存开销:当创建字符串时,如果字符串常量池中已经存在了相同内容的字符串,则不会创建新的字符串对象,而是直接返回池中已有对象的引用,这样可以避免大量重复字符串实例的创建,从而节省内存。
-
提高性能:由于字符串在程序运行过程中频繁使用,通过字符串常量池能够快速地查找和复用已存在的字符串,这大大提高了程序运行效率。
案例代码如下:
public class StringPoolExample {
public static void main(String[] args) {
// 创建两个相同的字符串字面量
String s1 = "Hello, World!";
String s2 = "Hello, World!";
// 检查它们是否指向同一内存地址(即常量池中的同一个对象)
System.out.println(s1 == s2); // 输出 true,因为它们引用的是字符串常量池中的同一个对象
// 使用 new 关键字创建新的字符串对象
String s3 = new String("Hello, World!");
// 尽管内容相同,但这是不同的对象,因此比较结果为 false
System.out.println(s1 == s3); // 输出 false,因为 s3 是新创建的对象,不在常量池中
// 但是,通过调用 intern() 方法,s3 可以尝试将其内容添加到字符串常量池,并返回该常量池中的引用
String s4 = s3.intern();
// 现在 s4 和 s1 都指向常量池中的同一个对象
System.out.println(s1 == s4); // 输出 true,因为 s4 是通过 intern() 方法加入到常量池后获得的引用
}
}
在这个示例中,s1 和 s2 都是通过字符串字面量方式创建的,它们引用的是字符串常量池中的同一个对象。
而 s3 是通过 new String() 显式构造方法创建的新对象,即使内容与 s1 相同,它也不在常量池中。
最后,通过调用 s3.intern() 方法,将 s3 的内容放入字符串常量池,s4 获取到了常量池中相应字符串的引用,所以 s1 和 s4 的比较结果为 true。
23、String s1 = new String(“abc”);这句话创建了几个字符串对象?
在Java中,String s1 = new String("abc"); 这句话实际上创建了两个字符串对象。
-
第一个对象:当编译器遇到字面量 “abc” 时,它会在字符串常量池中创建一个字符串对象。这意味着,无论程序在哪里使用到这个字面值 “abc”,都将引用同一个常量池中的字符串对象。
-
第二个对象:
new String("abc")创建了一个新的字符串对象,并且该对象的内容与字符串常量池中的 “abc” 相同。这里,new关键字明确指示JVM在堆内存中创建一个新的字符串实例,即使其内容与常量池中的字符串相同,也会生成一个新的对象。
所以,总共创建了两个字符串对象:一个是字符串常量池中的 “abc”,另一个是在堆内存中通过 new 操作符创建的新对象。
24、String.intern 方法有什么作用?
Java 中的 String.intern() 方法主要用于将字符串对象添加到 Java 虚拟机(JVM)的字符串常量池中,并返回该常量池中这个字符串的一个引用。其作用和行为可以总结如下:
-
查询与合并:当调用
String s = new String("xyz").intern();时,首先会在字符串常量池中查找是否存在内容相同的字符串。如果存在,则返回常量池中已有字符串的引用;如果不存在,则把当前堆上的字符串对象复制一份到字符串常量池,并返回该常量池中的新字符串引用。 -
内存优化:通过使用
intern()方法,可以避免在运行时创建大量重复内容的字符串对象,从而减少内存开销。 -
相等性测试:由于
==操作符在比较字符串时不仅检查对象引用是否相同,还检查常量池中的字符串引用是否相同,因此,对于通过intern()方法得到的引用,使用==可以正确判断两个内容相同的字符串是否指向同一个实例。 -
性能提升:对于需要频繁使用和比较的固定或重复字符串,通过 intern 方法将其放入常量池可以提高查找和比较的速度。
-
跨类加载器共享:在多类加载器环境中,intern 方法可以确保即使字符串是由不同类加载器加载的,只要它们的内容相同,就能够共享同一份字符串常量。
总之,String.intern() 主要是用来管理和优化字符串实例的存储和复用,它有助于减少内存消耗并增强某些场景下的程序性能。
25、String 类型的变量和常量做“+”运算时发生了什么?
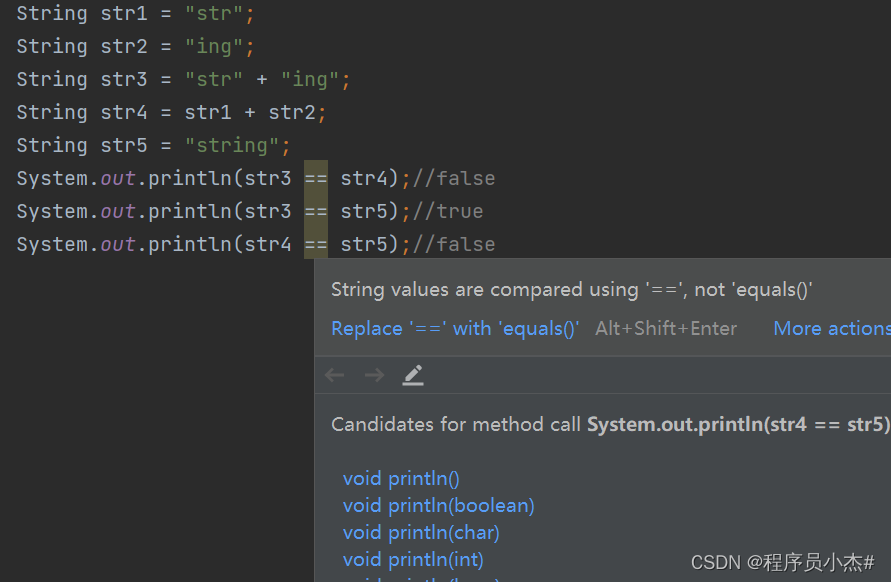
先来看字符串不加 final 关键字拼接的情况(JDK1.8):
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";
String str4 = str1 + str2;
String str5 = "string";
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
注意:比较 String 字符串的值是否相等,可以使用 equals() 方法。
String 中的 equals 方法是被重写过的。
Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是字符串的值是否相等。
如果你使用 == 比较两个字符串是否相等的话,IDEA 还是提示你使用 equals() 方法替换。
在Java中,当对String类型的变量或常量进行“+”运算时(例如 String a = "Hello" + "World";),会发生以下几种情况:
-
编译期优化:
- 如果所有参与连接的都是字符串字面量(编译期常量),那么JVM在编译期间会执行这个字符串拼接操作,并将结果作为一个新的字符串字面量存储。这意味着在运行时并不会生成额外的对象。
-
运行时操作:
- 当一个或多个操作数不是编译期可知的字符串字面量时,比如是变量或者表达式的结果,那么在运行时执行“+”运算将会触发实际的字符串连接操作。
- Java会在运行时创建一个新的
StringBuilder或者StringBuffer对象(取决于上下文是否需要线程安全)。 - 然后逐个将各个字符串添加到
StringBuilder/StringBuffer中。 - 最后调用其
toString()方法得到最终连接后的字符串对象。
- Java会在运行时创建一个新的
String s1 = "Hello"; String s2 = "World"; String result = s1 + " " + s2; // 这将在运行时创建一个新的String对象 - 当一个或多个操作数不是编译期可知的字符串字面量时,比如是变量或者表达式的结果,那么在运行时执行“+”运算将会触发实际的字符串连接操作。
-
内存影响:
- 每次通过“+”运算符连接字符串都会创建至少一个额外的中间对象(除非优化为编译期常量)。如果频繁使用这种方式连接字符串,可能会导致内存中的临时对象过多,从而影响性能。
为了避免运行时不必要的对象创建和提高效率,推荐在知道要连接多个字符串的情况下,直接使用 StringBuilder 或 StringBuffer 来构建字符串,尤其是在循环体内部或者处理大量字符串拼接的情况。例如:
StringBuilder sb = new StringBuilder();
sb.append("Hello").append(" ").append("World");
String result = sb.toString();
对于编译期可以确定的字符串常量拼接,现代Java编译器(如JDK 7及以上版本)通常会对这样的代码进行优化,称为“字符串串联的常量折叠”。
26、Java常见包有哪些,分别用法是什么?
在Java编程中,存在许多常用的包,每个包都有其特定的用途和功能。下面是一些最常见以及它们的主要用途:
-
java.lang包:这个包是Java语言的核心包,系统会自动导入这个包中的所有类,如String、Math、Sytem和Thread类等。这些类包括了Java的基本数据类型和函数,是我们进行程序设计时最常用的部分。
-
java.util包:这个包下包含了大量工具类/接口和集合框架类/接口,如Arrays和List、Set等。这些工具类和集合框架为我们在处理数据和执行算法时提供了极大的便利。
-
java.net包:这个包下包含了一些与网络编程相关的类/接口,如URL、URLConnection、Socket等。在进行网络编程时,这些类和接口会起到很大的作用。
-
java.io包:这个包下包含了一些与输入/输出编程相关的类/接口,如File、InputStream、OutputStream等。在进行文件操作或者设备交互时,这些类和接口是必不可少的。
-
java.text包:这个包下包含一些与文本处理相关的类,如DateFormat、SimpleDateFormat、Collator等。在进行文本格式化或者国际化处理时,这些类可以提供帮助。
-
java.sql包:该包下包含了进行JDBC数据库编程的相关类/接口,如Connection、Statement、ResultSet等。在进行数据库操作时,我们会使用到这些类和接口。
-
java.awt包:该包下包含了用于创建图形用户界面(GUI)的类和接口,如Component、Container、Window等。在进行图形界面开发时,我们会用到这些类和接口。
27、JAVA中的equals用法,在字符串对比、变量对比,int和Long对比
在Java中,equals()方法用于比较两个对象是否相等。对于不同类型的对象,equals()方法的实现方式可能不同。以下是一些常见的用法:
- 字符串对比:
String str1 = "hello";
String str2 = "world";
boolean isEqual = str1.equals(str2); // true
- 变量对比:
int num1 = 10;
int num2 = 10;
boolean isEqual = (num1 == num2); // true, 使用==比较的是值,使用equals比较的是对象的引用
- int和Long对比:
int num1 = 10;
Long num2 = 10L;
boolean isEqual = (num1 == num2); // false, int和Long是不同的类型,不能直接比较
boolean isEqual = (num1 == num2.intValue()); // true, 先将Long类型的值转换为int类型再进行比较
boolean isEqual = num1.equals(num2.intValue()); // false, int和Long是不同的类型,equals方法不能直接比较
boolean isEqual = num2.equals(new Integer(num1)); // true, 先将int类型的值转换为Integer类型再进行比较
28、JAVA中的引用类型有哪几种?
1)强引用
只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null【没有任何引用指向这个对象】,这样一来,JVM就可以适时的回收对象了。
public class M {
@Override
protected void finalize() throws Throwable {
System.out.println("finalize");
}
}
public class Test {
public static void main(String[] args) throws IOException {
M m = new M();
m = null;
System.gc();
System.out.println(m);
System.in.read();
}
}
上述代码的作用是创建一个名为M的类,并重写了finalize()方法。在Test类的main方法中,创建了一个M类的对象m,将其赋值为null,然后调用System.gc()来请求JVM进行垃圾回收。接着输出m的值,最后等待用户输入。
2)软引用
内存不够时会被垃圾回收器回收。
public class T02_SoftReference {
public static void main(String[] args) {
SoftReference<byte[]> sr = new SoftReference<>(new byte[1024 * 1024 * 10]);
// m = null
System.out.println(sr.get());
System.gc();
try {
Thread.sleep(500);
}catch (Exception e){
e.printStackTrace();
}
System.out.println(sr.get());
//再分配,一个数组,heap将安装不下,这个时候系统会垃圾回收,先回收一次,如果不够,会把软引用干掉
byte[] b = new byte[1024 * 1024 * 12];
System.out.println(sr.get());
}
}
首先,它创建了一个大小为10MB的字节数组,并将其包装在一个软引用对象中。然后,通过调用sr.get()方法,输出该软引用所引用的对象的值。接着,调用System.gc()来请求JVM进行垃圾回收。
在垃圾回收之前,再次调用sr.get()方法,输出软引用所引用的对象的值。此时,由于内存不足,JVM可能会回收这个字节数组,导致软引用所引用的对象变为null。
最后,分配一个新的字节数组,其大小超过了可用内存。这时,JVM会尝试回收一些内存以容纳新的字节数组,但由于软引用的存在,JVM不会立即回收这个字节数组,而是将其置为null。
总之,这段代码展示了软引用在内存不足时的行为:当内存不足以容纳新的对象时,软引用所引用的对象会被回收,而软引用本身则变为null。【正常是会内存溢出,但是这里是软引用,会回收对应的内存对象】
运行上述代码的时候,需要设置jvm启动的时候设置JVM的空间。
软引用(SoftReference)适用于以下情况:
缓存数据:当需要缓存一些较大的数据对象,但又不希望它们长期占用内存时,可以使用软引用。软引用会在内存不足时被垃圾回收器回收,释放内存空间。
内存敏感的应用程序:对于内存敏感的应用程序,可以使用软引用来避免内存溢出问题。通过将一些大的对象包装在软引用中,可以在内存紧张时及时释放这些对象,从而减少内存占用。
临时使用的对象:如果有一些对象只在特定时间段内需要使用,可以使用软引用来管理这些对象。当不再需要这些对象时,垃圾回收器可以回收它们所占用的内存。
需要注意的是,软引用并不是一个可靠的内存管理机制。因为垃圾回收器的运行时间和策略是不确定的,所以不能保证软引用所引用的对象一定会被回收。因此,在使用软引用时,应该谨慎评估其适用性,并确保有适当的备选方案来处理可能的内存泄漏问题。
3)弱引用
垃圾回收器会回收弱引用的对象。【对象被弱引用指向,垃圾回收器只要发现就会回收】
public class T03_WeakReference {
public static void main(String[] args) {
WeakReference<M> wr = new WeakReference<M>(new M());
System.out.println(wr.get());
System.gc();
try {
Thread.sleep(1000);
}catch (Exception e){
e.printStackTrace();
}
System.out.println(wr.get());
}
}
这段代码的作用是创建一个弱引用(WeakReference)对象,并尝试获取其引用的对象。
然后调用垃圾回收器(System.gc())进行垃圾回收,最后再次尝试获取其引用的对象。
具体来说,代码执行的步骤如下:
创建一个名为wr的弱引用对象,该对象引用一个新创建的M类实例。
通过wr.get()方法获取弱引用所引用的对象,并将其打印到控制台。
调用System.gc()方法请求垃圾回收器运行。
等待一段时间(1秒),以便垃圾回收器有足够的时间回收对象。
再次通过wr.get()方法获取弱引用所引用的对象,并将其打印到控制台。
需要注意的是,由于垃圾回收器的运行时机是不确定的,因此第二次打印的结果可能为null,表示对象已经被回收了。
ThreadLocal<M> tl = new ThreadLocal<M>();
tl.set(new M());
tl.remove();
创建一个名为tl的线程局部变量对象,该对象引用一个新创建的M类实例。通过调用tl.set(new M())方法将新对象设置到线程局部变量中。然后调用tl.remove()方法移除线程局部变量中的引用,使其成为垃圾回收的目标。
什么是ThreadLocal
Java中的ThreadLocal是一个用于存储线程局部变量的类。它为每个线程提供了一个独立的变量副本,这样每个线程都可以独立地改变自己的副本,而不会影响其它线程。
这种机制可以用于实现线程安全的数据共享,避免多线程环境下的数据竞争问题。
案例代码:
public class ThreadLocalExample {
// 创建一个ThreadLocal对象
private static ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
// 启动两个线程
new Thread(() -> {
// 为当前线程设置一个值
threadLocal.set((int) (Math.random() * 100));
System.out.println("线程1设置的值:" + threadLocal.get());
}).start();
new Thread(() -> {
// 获取当前线程的值
System.out.println("线程2获取的值:" + threadLocal.get());
}).start();
}
}
在这个例子中,我们创建了一个ThreadLocal对象,并在两个线程中分别设置了和获取了它的值。由于ThreadLocal为每个线程提供了独立的变量副本,所以输出结果可能是:
线程1设置的值:42
线程2获取的值:null
或者:
线程1设置的值:73
线程2获取的值:73
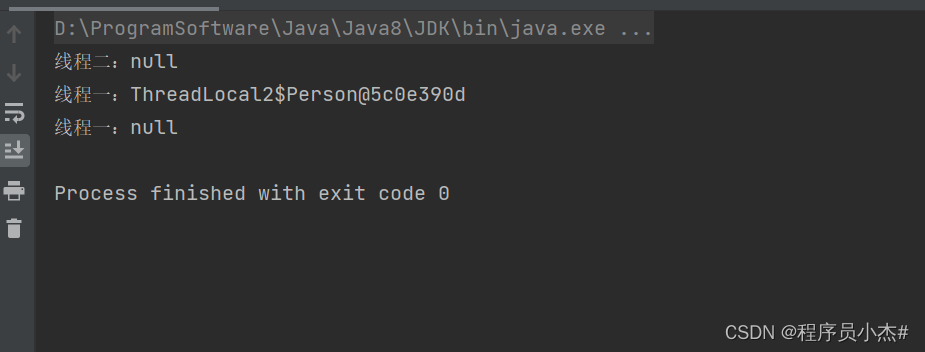
public class ThreadLocal2 {
private static ThreadLocal<Person> tl = new ThreadLocal<Person>();
public static void main(String[] args) {
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
tl.set(new Person("zhangsan"));
System.out.println("线程一:"+tl.get());
tl.remove();
System.out.println("线程一:"+tl.get());
}).start();
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程二:"+tl.get());
}).start();
}
static class Person{
private String name;
public Person(String name){
this.name = name;
}
}
}
4)虚引用
虚引用是一种最弱的引用关系,它并不会决定对象的生命周期,如果一个对象仅持有虚引用,那么它就可能会被垃圾回收器回收。
Java中的虚引用(PhantomReference)是一种特殊的引用类型,它的特点是在垃圾回收器进行垃圾回收时,如果发现某个对象只被虚引用所引用,那么这个对象就会被回收。虚引用主要用于跟踪对象被垃圾回收的情况,例如在内存泄漏检测和资源释放等场景中。
具体案例:
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class PhantomReferenceDemo {
public static void main(String[] args) throws InterruptedException {
// 创建一个强引用对象
Object strongReference = new Object();
// 创建一个引用队列,用于存储被垃圾回收器回收的对象
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
// 创建一个虚引用,关联到强引用对象,并指定引用队列
PhantomReference<Object> phantomReference = new PhantomReference<>(strongReference, referenceQueue);
// 将虚引用添加到一个集合中,方便后续操作
Set<PhantomReference<Object>> phantomReferences = new HashSet<>();
phantomReferences.add(phantomReference);
// 取消强引用,使得对象只被虚引用所引用
strongReference = null;
// 强制进行垃圾回收
System.gc();
// 等待一段时间,让垃圾回收器有足够的时间回收对象
Thread.sleep(1000);
// 检查引用队列中是否有被回收的对象
if (!referenceQueue.isEmpty()) {
PhantomReference<Object> collectedPhantomReference = (PhantomReference<Object>) referenceQueue.poll();
System.out.println("PhantomReference has been collected: " + collectedPhantomReference);
} else {
System.out.println("No PhantomReference has been collected");
}
}
}
在这个案例中,我们创建了一个强引用对象strongReference,然后创建了一个引用队列referenceQueue和一个虚引用phantomReference。
我们将虚引用添加到一个集合中,然后取消强引用,使得对象只被虚引用所引用。接下来,我们强制进行垃圾回收,并等待一段时间,让垃圾回收器有足够的时间回收对象。
最后,我们检查引用队列中是否有被回收的对象,如果有,则输出相应的信息。
29、每种引用类型的特点是什么?
在Java中,引用类型主要包括强引用、软引用、弱引用和虚引用。
这些类型的主要区别在于其生命周期和强度。
强引用:是Java程序中最常见的引用类型。
只要强引用还存在,垃圾收集器就不会回收被引用的对象。
软引用:用于描述一些有用但并非必需的对象。
只有在内存空间不足时,才会被垃圾收集器回收。
弱引用:具有更短的生命周期。只要垃圾收集器运行,无论内存空间是否充足,都会被回收。
虚引用:是最弱的一种引用关系。主要用于跟踪对象被垃圾收集器回收的活动。
除了以上四种引用类型外,Java还有另一种重要的类别,即基本数据类型,如int, double等。基本数据类型不是引用类型,它们是由Java虚拟机直接分配和操作的。
总的来说,理解这些不同类型的引用对于有效管理Java应用程序的内存使用非常重要。
30、JSP当中的作用域有哪些,分别如何获取其值,JSP当中如何获取值
JSP中的作用域主要有以下几种:
-
request:表示客户端请求,用于获取客户端传递的参数、属性等信息。
在JSP页面中,可以通过request.getParameter()、request.getAttribute()等方法获取值。 -
session:表示服务器端会话,用于存储用户登录状态、购物车信息等。
在JSP页面中,可以通过session.getAttribute()、session.setAttribute()等方法获取和设置值。 -
application:表示整个Web应用程序,用于存储全局变量、配置信息等。
在JSP页面中,可以通过application.getAttribute()、application.setAttribute()等方法获取和设置值。 -
page:表示当前JSP页面,用于存储页面级别的变量、函数等。
在JSP页面中,可以通过page.getAttribute()、page.setAttribute()等方法获取和设置值。
以下是一些示例代码:
<!-- 获取request作用域的值 -->
<% String paramValue = request.getParameter("paramName"); %>
<!-- 获取session作用域的值 -->
<% Object sessionValue = session.getAttribute("sessionName"); %>
<!-- 获取application作用域的值 -->
<% Object applicationValue = application.getAttribute("applicationName"); %>
<!-- 获取page作用域的值 -->
<% Object pageValue = page.getAttribute("pageName"); %>
在Java后端代码中,可以通过HttpServletRequest对象来获取这些作用域的值。以下是一些示例代码:
// 获取request作用域的值
String paramValue = request.getParameter("paramName");
// 获取session作用域的值
Object sessionValue = request.getSession().getAttribute("sessionName");
// 获取application作用域的值
Object applicationValue = getServletContext().getAttribute("applicationName");
// 获取page作用域的值
Object pageValue = ((PageContext) request).getAttribute("pageName", PageContext.REQUEST_SCOPE);
31、什么是ServletContext,如何获取ServletContext设置的参数值
ServletContext是Java Web应用程序中的一种全局对象,它代表了整个Web应用程序的上下文环境。每个Web应用程序只有一个ServletContext实例,它负责管理Web应用程序的配置信息、资源文件等。
获取ServletContext设置的参数值可以通过以下方法:
-
通过HttpServletRequest对象的getServletContext()方法获取当前请求所在的ServletContext对象。
-
使用ServletContext对象的getInitParameter()方法获取指定参数名的值。例如:
String paramValue = request.getServletContext().getInitParameter("paramName");
其中,"paramName"是要获取的参数名。如果该参数不存在,则返回null。
具体案例代码如下:
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class GetServletContextParam extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 获取ServletContext对象
ServletContext context = request.getServletContext();
// 获取指定参数名的值
String paramValue = context.getInitParameter("paramName");
// 输出参数值
response.setContentType("text/html;charset=UTF-8");
PrintWriter out = response.getWriter();
out.println("<html><body>");
out.println("<h1>ServletContext参数值: " + paramValue + "</h1>");
out.println("</body></html>");
}
}
在这个示例中,我们创建了一个名为GetServletContextParam的Servlet类,它继承了HttpServlet类。在doGet方法中,我们首先通过HttpServletRequest对象的getServletContext()方法获取ServletContext对象,然后使用getInitParameter()方法获取指定参数名的值,并将其输出到响应中。
32、每种引用类型的应用场景是什么?
在Java编程中,不同的引用类型因其独特的生命周期和强度,被应用在不同的场景下。
强引用:
强引用是Java中最常见的引用类型,只要强引用还存在,垃圾收集器就不会回收被引用的对象。
因此,强引用适用于那些需要长时间存在,且不允许被回收的对象。
软引用:
软引用通常用于描述一些有用但并非必需的对象。
只有在内存空间不足时,才会被垃圾收集器回收。
因此,软引用适用于实现缓存机制,即在内存充足时保留这些对象,当内存不足时,则删除这些对象。
弱引用:
弱引用的生命周期更短。
只要垃圾收集器运行,无论内存空间是否充足,都会被回收。
弱引用适用于实现一种类似"幽灵"对象的概念,即当一个对象不再需要时,可以被及时回收以便释放内存。
虚引用:
虚引用是最弱的一种引用关系,主要用于跟踪对象被垃圾收集器回收的活动。
其具体应用场景并不广泛,通常用于一些特殊的需求,如跟踪对象的垃圾回收状态等。
总的来说,理解不同引用类型的特性和适用场景对于有效管理Java应用程序的内存使用非常重要。
33、ThreadLocal你了解吗?
ThreadLocal是Java中的一个类,它主要用于实现线程本地存储。ThreadLocal提供线程本地变量,如果创建一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个副本。在实际多线程操作的时候,操作的是自己本地内存中的变量,从而规避了线程安全问题。
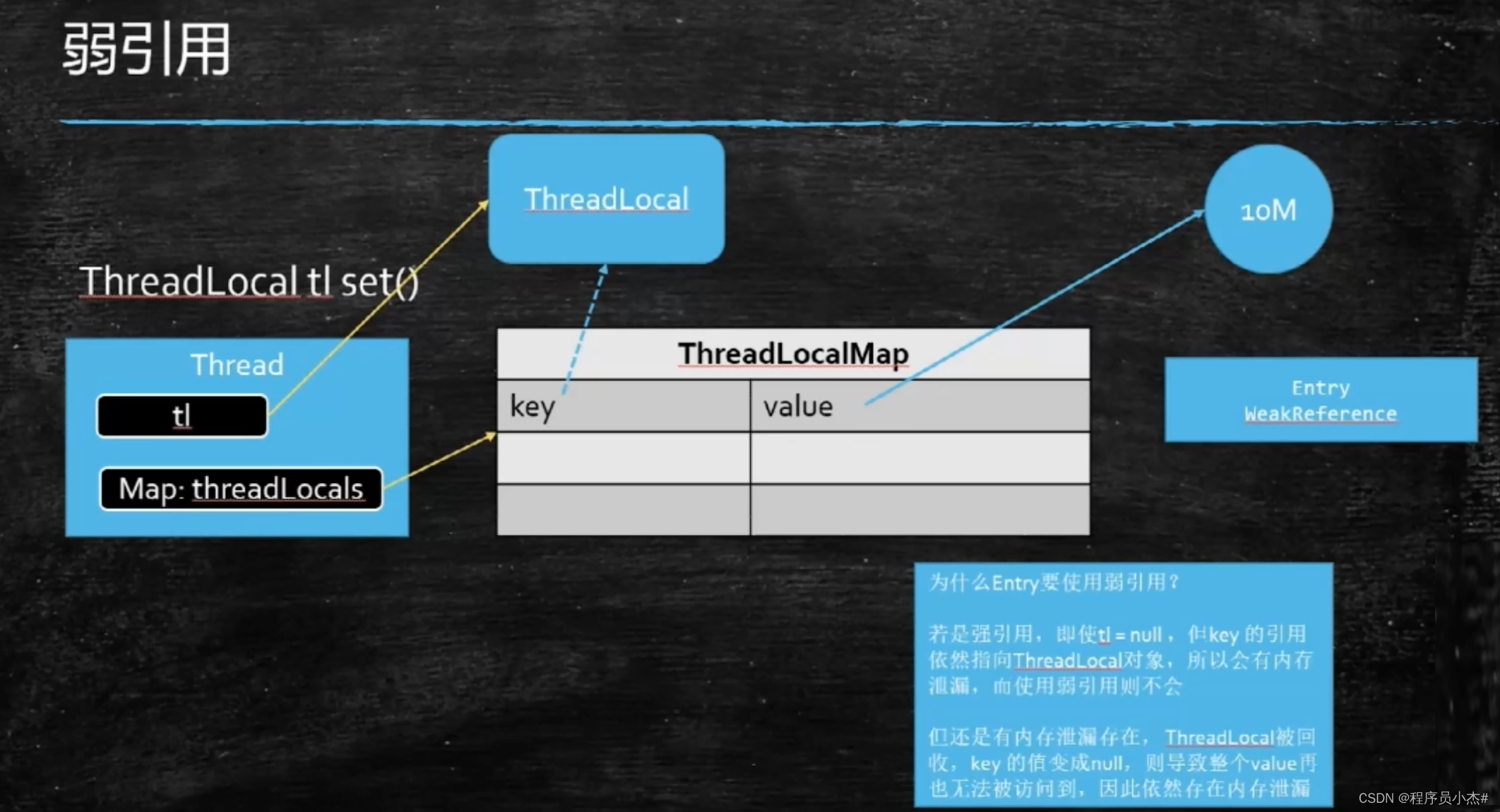
ThreadLocal的名字告诉我们它是属于当前线程的局部变量,该变量对其他线程而言是封闭且隔离的。也就是说,每个线程都可以访问到自己内部的这个变量,但无法访问到其他线程的这个变量。
为了达到这样的目标,ThreadLocal在内部创建了一个静态的内部类叫:ThreadLocalMap。ThreadLocalMap并不是在ThreadLocal类中定义的,实际上被Thread持有。Entry的key是(虚引用的)ThreadLocal对象,而不是当前线程ID或者线程名称。ThreadLocalMap中持有的是Entry数组,而不是Entry对象。
34、ThreadLocal应用在什么地方?
ThreadLocal是Java中的一个类,它主要用于实现线程本地存储。ThreadLocal提供线程本地变量,如果创建一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个副本。在实际多线程操作的时候,操作的是自己本地内存中的变量,从而规避了线程安全问题。
ThreadLocal适用于每一个线程需要自己独立实例的场景,而且这个实例需要在多个方法里被使用到,也就是变量在线程之间是隔离的但是在方法或者是类里面是共享的场景。以下是一些具体的应用场景:
数据库连接【线程池】:在一个Web应用中,每个线程可能需要执行数据库操作。通过使用ThreadLocal,可以在每个线程中创建独立的数据库连接,避免了多线程环境下的资源竞争和同步问题。
Session管理:在Web应用中,为了保证用户的状态信息在整个会话过程中都能被跟踪,可以使用ThreadLocal来存储用户会话信息。
这样即使多个请求并发访问,也能保证每个请求都能获取到正确的会话信息。
线程安全的对象池:在一些对象池实现中,为了解决多线程环境下的对象争用问题,可以使用ThreadLocal来存储每个线程独有的对象。这样每个线程都可以从自己的对象池中取对象,而不会影响其他线程的对象池。
总的来说,ThreadLocal是一种强大的工具,它能够帮助我们更好地管理和控制多线程环境下的变量共享问题。
35、ThreadLocal会产生内存泄漏你了解吗?
ThreadLocal在使用时确实可能会引发内存泄漏的问题。具体来说,ThreadLocal内部维护了一个ThreadLocalMap,这个map的生命周期跟Thread一样长。
因此,如果没有手动删除对应key,就可能导致内存泄漏。特别是当使用static的ThreadLocal时,因为这样延长了ThreadLocal的生命周期,如果分配了ThreadLocal对象又不再调用get(), set(), remove()方法,那么就更容易导致内存泄漏。
然而,这并不是说ThreadLocal一定会导致内存泄漏。实际上,ThreadLocal的设计者已经考虑到了这个问题,并采取了一些措施来避免内存泄漏。例如,当Key是弱引用时,由于外部没有强引用了,所以GC可以将其回收。此时,如果ThreadLocal通过key.get()==null判断出Key已经被回收了,那么当前Entry就是一个废弃的过期节点。ThreadLocal可以自发地清理这些过期节点,从而避免内存泄漏。
总的来说,虽然ThreadLocal有可能导致内存泄漏,但只要我们正确使用(比如每次使用完ThreadLocal都调用它的remove()方法清除数据),或者避免静态使用ThreadLocal,就可以有效地避免这个问题。
36、HashMap和HashTable的区别是什么
HashMap和Hashtable都是Java中的哈希表实现,它们都实现了Map接口。然而,它们之间存在一些主要的区别:
继承的父类不同:Hashtable继承自Dictionary类,而HashMap则继承自AbstractMap类。
值得注意的是,Dictionary类在Java中已经被废弃,因此Hashtable也不常被使用。
线程安全性:Hashtable是线程安全的,其所有方法都被Synchronize修饰,这保证了同一时间只有一个线程可以访问一个Hashtable对象。
相比之下,HashMap是非线程安全的,它的性能通常会高于Hashtable,因为在多线程环境下,不需要进行同步控制。
null值的处理:HashMap允许使用一个null键和多个null值。相反,Hashtable不允许使用null键和null值。
迭代器的不同:由于HashMap不是线程安全的,因此不能在迭代过程中对HashMap进行结构性修改,否则会抛出ConcurrentModificationException异常。而Hashtable由于是线程安全的,可以在迭代过程中对其进行结构性修改。
37、HashMap有哪几种线程安全的方式
以下是Java中保证HashMap线程安全的方式及其具体案例:
- 使用ConcurrentHashMap:ConcurrentHashMap是线程安全的HashMap实现,采用了分段锁的机制,可以提高并发性能。一个具体的例子如下:
Map<String, String> map = new ConcurrentHashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
在这个例子中,我们创建了一个ConcurrentHashMap实例,并向其中添加了两个键值对。
- 使用Collections.synchronizedMap:这个方法可以将HashMap转换为线程安全的Map,但需要注意的是在迭代时需要手动进行同步。示例代码如下:
Map<String, String> map = new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
Map<String, String> syncMap = Collections.synchronizedMap(map);
syncMap.put("key3", "value3");
在这个例子中,首先我们创建了一个非线程安全的HashMap,然后通过Collections.synchronizedMap方法将其转换为线程安全的Map,并向其中添加了一个键值对。
- 使用读写锁(ReentrantReadWriteLock):读写锁允许多个线程同时读取数据,但只允许一个线程写入数据,可以实现线程安全的HashMap。以下是一个示例:
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
import java.util.HashMap;
import java.util.Map;
public class Test {
private final Map<String, String> map = new HashMap<>();
private final ReadWriteLock lock = new ReentrantReadWriteLock();
public void put(String key, String value) {
lock.writeLock().lock();
try {
map.put(key, value);
} finally {
lock.writeLock().unlock();
}
}
public String get(String key) {
lock.readLock().lock();
try {
return map.get(key);
} finally {
lock.readLock().unlock();
}
}
}
在这个例子中,我们创建了一个非线程安全的HashMap,并使用读写锁来保证其线程安全性。当我们向map中添加或获取数据时,都会先获取相应的锁。
38、Java循环遍历HashMap的几种方式
Java中遍历HashMap的几种方式如下:
1、使用entrySet()方法遍历键值对:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}
2、使用keySet()方法遍历键:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
for (String key : map.keySet()) {
System.out.println("Key: " + key + ", Value: " + map.get(key));
}
}
}
3、使用values()方法遍历值:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
for (Integer value : map.values()) {
System.out.println("Value: " + value);
}
}
}
4、使用Java 8的forEach()方法遍历键值对:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
map.forEach((key, value) -> System.out.println("Key: " + key + ", Value: " + value));
}
}
5、要通过迭代器遍历HashMap,首先需要创建一个HashMap对象,然后使用迭代器进行遍历。以下是一个简单的示例:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Main {
public static void main(String[] args) {
// 创建一个HashMap对象
HashMap<String, Integer> hashMap = new HashMap<>();
// 向HashMap中添加元素
hashMap.put("one", 1);
hashMap.put("two", 2);
hashMap.put("three", 3);
// 获取HashMap的迭代器
Iterator<Map.Entry<String, Integer>> iterator = hashMap.entrySet().iterator();
// 使用迭代器遍历HashMap
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}
39、 HashMap底层实现原理和扩容机制
HashMap是Java中常用的一个数据结构,它是基于哈希表实现的。底层实现原理和扩容机制如下:
-
底层实现原理:HashMap内部使用数组+链表/红黑树的数据结构来存储键值对。当插入新的键值对时,首先根据key的hashCode()方法计算出其hash值,然后通过hash值找到对应的数组下标位置,如果该位置没有元素或该元素与要插入的元素不相等,则直接在该位置插入;否则,将该位置的元素作为链表的头节点或红黑树的根节点,将新元素插入到链表或红黑树中。
-
扩容机制:当HashMap中的元素数量达到一定阈值(默认为负载因子0.75 * 容量)时,就需要进行扩容操作。扩容时,会创建一个新的数组,大小为原数组的两倍,并将原来的元素重新计算hash值后放入新数组中。因为扩容操作涉及到元素的重新计算和复制,所以性能开销较大,因此尽量避免频繁扩容。
下面是一些使用HashMap的案例代码:
// 创建一个HashMap对象
HashMap<String, Integer> hashMap = new HashMap<>();
// 向HashMap中添加元素
hashMap.put("apple", 1);
hashMap.put("banana", 2);
hashMap.put("orange", 3);
System.out.println(hashMap); // {apple=1, banana=2, orange=3}
// 获取HashMap的大小
int size = hashMap.size();
System.out.println(size); // 3
// 判断HashMap是否包含指定key的元素
boolean containsKey = hashMap.containsKey("apple");
System.out.println(containsKey); // true
// 删除指定key的元素
hashMap.remove("apple");
System.out.println(hashMap); // {banana=2, orange=3}
40、 HashMap什么样的类适合作为键
HashMap的键(Key)可以是任何实现了Object类的类,包括基本数据类型和引用数据类型。但是,由于HashMap是基于哈希表实现的,因此对于作为键的对象,最好重写其hashCode()方法和equals()方法,以保证键的唯一性和比较性。
以下是一些适合作为HashMap键的类的示例:
- 自定义类:如果需要存储具有唯一标识符的数据,可以定义一个自定义类,并重写hashCode()方法和equals()方法。例如:
public class Student {
private String name;
private int age;
private String id;
// 构造函数、getter和setter省略
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null || getClass() != obj.getClass()) {
return false;
}
Student student = (Student) obj;
return id.equals(student.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
- 不可变类:不可变类是指一旦创建就不能修改其状态的类。由于不可变对象的状态不会改变,因此它们非常适合作为键。例如:
public final class ImmutablePerson {
private final String name;
private final int age;
private final String id;
// 构造函数、getter和静态工厂方法省略
}
- 基本数据类型和String类型:基本数据类型和String类型可以直接作为HashMap的键。例如:
Map<Integer, String> map = new HashMap<>(); // 使用基本数据类型int作为键
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
System.out.println(map); // {1=one, 2=two, 3=three}
- 如果不重写其hashCode()方法和equals()方法会怎么样
如果不重写hashCode()方法和equals()方法,那么HashMap将使用默认的Object类的hashCode()方法和equals()方法。
这意味着:
当两个对象具有相同的哈希码时,它们被认为是相等的。但是,这并不意味着它们的内容是相等的。例如,两个具有相同哈希码的字符串可能包含不同的字符序列。
如果两个对象具有相同的内容,它们的哈希码也可能不同。这是因为哈希码是根据对象的内存地址计算的,而不是根据对象的内容。因此,即使两个对象的内容相同,它们的哈希码也可能不同。
在多线程环境下,如果不重写hashCode()方法和equals()方法,可能会导致数据不一致的问题。因为HashMap不是线程安全的,多个线程同时修改HashMap可能导致数据不一致。
为了避免这些问题,建议重写hashCode()方法和equals()方法,以确保HashMap的正确性和线程安全性。
重写hashCode()方法可以确保在HashMap中,具有相同内容的对象具有相同的哈希码。如果不重写hashCode()方法,则默认的Object类的hashCode()方法将根据对象的内存地址计算哈希码,而不是根据对象的内容。因此,即使两个对象具有相同的内容,它们的哈希码也可能不同。
当多个对象具有相同的哈希码时,它们会被存储在同一个桶(bucket)中。如果这些对象的内容也相等,那么它们将被存储在同一个链表或红黑树中。但是,如果这些对象的内容不相等,那么它们将被视为不同的键值对,并被存储在不同的位置。这可能导致数据不一致的问题。
因此,重写hashCode()方法可以确保具有相同内容的对象具有相同的哈希码,从而避免数据不一致的问题。
41、Java集合有哪几种,分别的用法和区别有哪些
Java集合框架主要包括List,Set,Map三种类型的容器。其中,List和Set都是继承自Collection接口,而Map不是。
List是有序的,允许元素重复,主要用于存储有序的数据。每次插入数据,不是把对象本身存储到集合中,而是在集合中用一个索引变量指向这个对象。因为List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。常用的实现类有ArrayList、LinkedList等。
ArrayList和LinkedList都可以实现列表功能,但ArrayList是基于动态数组实现的,支持随机访问,而LinkedList是基于双向链表实现的,适用于频繁插入和删除操作。例如,可以使用ArrayList存储学生信息,使用LinkedList存储电话簿。
ArrayList和LinkedList都是Java中的List接口的实现类,它们都可以用于存储有序或无序的元素集合。下面是它们的使用案例:
- ArrayList的使用案例:
假设我们需要存储一组学生的成绩信息,可以使用ArrayList来存储这些成绩信息。首先,我们需要创建一个ArrayList对象,然后使用add()方法向其中添加元素。最后,我们可以使用get()方法获取指定位置上的元素值。
import java.util.ArrayList;
public class StudentScores {
public static void main(String[] args) {
// 创建一个ArrayList对象
ArrayList<Integer> scores = new ArrayList<>();
// 向ArrayList中添加元素
scores.add(90);
scores.add(85);
scores.add(92);
scores.add(78);
scores.add(88);
// 获取指定位置上的元素值
int scoreAtIndex3 = scores.get(3); // 结果为78
System.out.println("第4个学生的成绩是:" + scoreAtIndex3);
}
}
- LinkedList的使用案例:
假设我们需要在一个链表中存储一组电话号码,可以使用LinkedList来存储这些电话号码。首先,我们需要创建一个LinkedList对象,然后使用add()方法向其中添加元素。最后,我们可以使用get()方法获取指定位置上的元素值。
LinkedList中的元素是可以重复的。这是由于LinkedList是基于双向链表实现的,它的存储结构中维护了一个双向链表,底层维护了两个属性first和last,分别指向了首节点和尾节点。每个节点为一个Note对象,其中有维护了prev(上一个),item(可以理解为记下,记下存储的元素),next(下一个),通过prev和next把多个节点串联就形成了链表。
此外,因为链表的删除和新增不是通过数组而是通过修改指向,所以效率高。这也使得LinkedList在增删操作上的效率要高于查询操作。例如,你可以通过元素的equals()方法判断是否重复,并且如果需要从LinkedList中删除重复元素,也可以使用Iterator迭代器或者增强for循环来实现。
import java.util.LinkedList;
public class PhoneNumbers {
public static void main(String[] args) {
// 创建一个LinkedList对象
LinkedList<String> phoneNumbers = new LinkedList<>();
// 向LinkedList中添加元素
phoneNumbers.add("13812345678");
phoneNumbers.add("13912345678");
phoneNumbers.add("13712345678");
phoneNumbers.add("13612345678");
phoneNumbers.add("13512345678");
// 获取指定位置上的元素值
String phoneNumberAtIndex2 = phoneNumbers.get(2); // 结果为"13712345678"
System.out.println("第3个电话号码是:" + phoneNumberAtIndex2);
}
}
Set是无序的,不允许元素重复,主要用于存储无序且不重复的数据。Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。常用的实现类有HashSet、TreeSet等。
Java中的Set是一个接口,它继承了Collection接口。Set集合不允许有重复的元素,如果添加重复元素则会抛出异常。
常用的实现类有HashSet、LinkedHashSet和TreeSet。其中,HashSet是基于哈希表实现的,它的元素是无序的;LinkedHashSet是基于链表和哈希表实现的,它的元素是有序的;TreeSet是基于红黑树实现的,它的元素也是有序的。
下面是使用Set的一些示例:
- 创建一个HashSet对象并添加元素:
import java.util.HashSet;
public class SetExample {
public static void main(String[] args) {
// 创建一个HashSet对象
HashSet<String> set = new HashSet<>();
// 向set中添加元素
set.add("apple");
set.add("banana");
set.add("orange");
set.add("apple"); // 重复元素,不会被添加到set中
// 输出set中的元素个数
System.out.println("set中的元素个数:" + set.size()); // 输出3
}
}
- 创建一个LinkedHashSet对象并添加元素:
import java.util.LinkedHashSet;
public class SetExample {
public static void main(String[] args) {
// 创建一个LinkedHashSet对象
LinkedHashSet<String> set = new LinkedHashSet<>();
// 向set中添加元素
set.add("apple");
set.add("banana");
set.add("orange");
set.add("apple"); // 重复元素,不会被添加到set中
// 输出set中的元素个数和顺序
System.out.println("set中的元素个数:" + set.size()); // 输出3
System.out.println("set中的元素顺序:" + set); // 输出[apple, banana, orange]
}
}
- 创建一个TreeSet对象并添加元素:
import java.util.TreeSet;
public class SetExample {
public static void main(String[] args) {
// 创建一个TreeSet对象,指定排序规则为自然排序(升序)
TreeSet<Integer> set = new TreeSet<>(Comparator.naturalOrder());
// 向set中添加元素
set.add(5);
set.add(3);
set.add(8);
set.add(1); // 重复元素,不会被添加到set中,且会按照排序规则重新插入到正确的位置上
// 输出set中的元素个数和顺序
System.out.println("set中的元素个数:" + set.size()); // 输出4,因为1被插入到了正确的位置上,所以实际上只有3个不同的元素被添加到了set中
System.out.println("set中的元素顺序:" + set); // 输出[1, 3, 5, 8],因为1被插入到了正确的位置上,所以实际上只有3个不同的元素被添加到了set中,并且按照排序规则进行了排序输出
}
}
Map是一种键值对映射的集合,主要用于存储键值对。
常用的实现类有HashMap、LinkedHashMap等。
42、 ArrayList、Vector和LinkedList的区别及使用场景
ArrayList、Vector和LinkedList都是Java中的集合类,用于存储有序的数据。它们之间的区别主要体现在内部实现和使用场景上:
-
ArrayList:基于动态数组实现,支持随机访问,即通过索引可以快速查找元素。因此,如果需要频繁随机访问元素的场景,例如随机读取数据,可以使用ArrayList。但是,由于其内部实现是数组,插入和删除元素时可能需要移动大量数据,所以性能相对较低。另外,当内存不足时,ArrayList默认扩展50% + 1个元素。
-
LinkedList:基于双向链表实现,不支持随机访问,但插入和删除元素的效率较高。因为链表的结构允许在不移动数据的情况下进行插入和删除操作。所以,如果需要频繁插入和删除元素的场景,例如在列表中间插入或删除元素,建议使用LinkedList。
-
Vector:与ArrayList类似,也是基于动态数组实现,但它是线程安全的。每个方法都添加了同步锁,确保在多线程环境下的安全性。然而,由于同步锁的存在,Vector的执行效率相对较低。如果需要在多线程环境下使用,并且考虑线程安全的重要性高于执行效率,可以选择Vector。但需要注意,Vector的默认扩展策略是1倍,而不是ArrayList的50% + 1。
下面是一些使用案例代码:
// ArrayList的使用示例
List<String> arrayList = new ArrayList<>();
arrayList.add("apple");
arrayList.add("banana");
arrayList.add("orange");
System.out.println(arrayList); // [apple, banana, orange]
arrayList.remove(1); // 删除索引为1的元素
System.out.println(arrayList); // [apple, orange]
int index = arrayList.indexOf("orange"); // 查找元素"orange"的索引
System.out.println(index); // 1
String element = arrayList.get(1); // 获取索引为1的元素
System.out.println(element); // orange
// LinkedList的使用示例
List<String> linkedList = new LinkedList<>();
linkedList.add("apple");
linkedList.add("banana");
linkedList.add("orange");
System.out.println(linkedList); // [apple, banana, orange]
linkedList.removeFirst(); // 删除第一个元素
System.out.println(linkedList); // [banana, orange]
linkedList.addLast("grape"); // 在末尾添加元素"grape"
System.out.println(linkedList); // [banana, orange, grape]
boolean contains = linkedList.contains("orange"); // 判断是否包含元素"orange"
System.out.println(contains); // true
linkedList.set(1, "peach"); // 将索引为1的元素替换为"peach"
System.out.println(linkedList); // [banana, peach, grape]
Vector是Java中的一个集合类,它与ArrayList类似,也是基于动态数组实现的。但是,Vector是线程安全的,每个方法都添加了同步锁,确保在多线程环境下的安全性。因此,如果需要在多线程环境下使用,并且考虑线程安全的重要性高于执行效率,可以选择Vector。
下面是一些Vector的使用案例代码:
// 创建一个Vector对象
Vector<String> vector = new Vector<>();
// 向Vector中添加元素
vector.add("apple");
vector.add("banana");
vector.add("orange");
System.out.println(vector); // [apple, banana, orange]
// 获取Vector的大小
int size = vector.size();
System.out.println(size); // 3
// 判断Vector是否为空
boolean isEmpty = vector.isEmpty();
System.out.println(isEmpty); // false
// 删除指定索引的元素
vector.remove(1); // 删除索引为1的元素
System.out.println(vector); // [apple, orange]
// 获取指定索引的元素
String element = vector.get(0); // 获取索引为0的元素
System.out.println(element); // apple
// 修改指定索引的元素
vector.set(0, "pear"); // 将索引为0的元素替换为"pear"
System.out.println(vector); // [pear, orange]
43、 ArrayList扩容机制案例代码
ArrayList的扩容机制主要是在添加元素时,当数组容量不足以容纳新元素时,会创建一个新的数组,将原数组的元素复制到新数组中,然后将新元素添加到新数组中。这个过程可以通过以下代码实现:
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
arrayList.add(i);
System.out.println("添加元素 " + i + ",当前数组容量:" + arrayList.size());
}
}
}
在这个例子中,我们创建了一个初始容量为10的ArrayList,然后循环添加10个元素。每次添加元素后,都会输出当前数组的容量。当添加第10个元素时,由于数组容量不足,会自动扩容为原来的两倍(即20),并将原数组的元素复制到新数组中。
44、 Collection和Collections的区别
Collection和Collections都是Java中的集合类,但它们之间有一些区别:
-
Collection是一个接口,它定义了一组通用的集合操作方法,例如add、remove、size等。而Collections是一个工具类,它提供了一些静态方法,用于对集合进行排序、查找等操作。
-
Collection是集合类的根接口,它包括了List、Set、Queue等子接口。而Collections只包含了一些与集合相关的工具方法,不涉及具体的集合类型。
下面是一些使用Collection和Collections的案例代码:
// 使用Collection接口创建ArrayList对象并添加元素
Collection<String> collection = new ArrayList<>();
collection.add("apple");
collection.add("banana");
collection.add("orange");
System.out.println(collection); // [apple, banana, orange]
// 使用Collection接口遍历集合元素
for (String element : collection) {
System.out.println(element);
}
// apple
// banana
// orange
// 使用Collection接口获取集合的大小
int size = collection.size();
System.out.println(size); // 3
// 使用Collection接口删除指定索引的元素
collection.remove(1); // 删除索引为1的元素
System.out.println(collection); // [apple, orange]
// 使用Collections工具类对ArrayList进行排序
List<Integer> list = new ArrayList<>();
list.add(5);
list.add(3);
list.add(1);
list.add(4);
list.add(2);
Collections.sort(list); // 对list进行升序排序
System.out.println(list); // [1, 2, 3, 4, 5]
45、final、finally、finalize的区别
final、finally和finalize是Java中的三个关键字,它们的区别如下:
- final:用于修饰类、方法和变量,表示不可变。当一个类被声明为final时,它不能被继承;当一个方法被声明为final时,该方法不能被子类覆盖;当一个变量被声明为final时,该变量的值只能被赋值一次,即常量。
案例代码:
// 使用final修饰类
public final class MyClass {
// ...
}
// 使用final修饰方法
public void myMethod() {
// ...
}
// 使用final修饰变量
public final int myVar = 10;
- finally:用于异常处理,表示无论是否发生异常,都会执行的代码块。通常与try-catch语句一起使用。
案例代码:
try {
// ...可能抛出异常的代码
} catch (Exception e) {
// ...处理异常的代码
} finally {
// ...无论是否发生异常,都会执行的代码
}
- finalize:用于在对象被回收前执行一些清理操作。可以重写Object类的finalize方法来实现自定义的清理逻辑。需要注意的是,finalize方法的执行不是保证的,因为垃圾回收器可能会忽略它。因此,不建议依赖finalize方法进行资源清理。
案例代码:
public class MyClass {
@Override
protected void finalize() throws Throwable {
try {
// ...清理资源的代码
} finally {
super.finalize();
}
}
}
46、sleep()和wait()的区别
sleep()和wait()都是可以让线程进入休眠的方法,他们都可以响应Interrupt(中断)请求。然而,它们之间存在一些显著的区别:
- sleep是Thread的静态方法,wait是Object的方法,任何对象实例都能调用。
- sleep不会释放锁,它也不需要占用锁。相反,wait会释放锁,但调用它的前提是当前线程占有锁(即代码要在synchronized中)。
- sleep必须传递一个数值类型的参数,表明线程需要休眠的时间长度。无参的wait方法让线程进入了WAITING状态。而wait可以接受notify / notifyAll之后就绪执行。
- sleep方法可以使线程进入WAITING状态,而且不会占用CPU资源。在休眠期间如果被中断,会抛出异常,并会清空中断状态标记。
- 一般情况下,sleep只能等待超时时间之后再回复执行;而wait可以接受notify / notifyAll之后就绪执行。
下面是使用sleep()和wait()的示例代码:
// 使用sleep()的例子
public class SleepExample {
public static void main(String[] args) {
try {
// 让当前线程休眠3秒
Thread.sleep(3000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 使用wait()的例子
public class WaitExample {
public static void main(String[] args) {
Object lock = new Object();
synchronized (lock) {
try {
// 让当前线程等待,直到其他线程调用lock对象的notify()或notifyAll()方法
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
47、forward(转发)和redirect(重定向)的区别
在Java中,forward()和redirect()都是用于将请求从一个Servlet转发到另一个Servlet的方法。它们之间的主要区别在于:
-
forward()方法会将请求和响应对象传递给目标Servlet,然后由目标Servlet处理请求并生成响应。这意味着目标Servlet可以访问原始请求的上下文信息,如请求参数、请求属性等。而redirect()方法则会创建一个新的请求URI,并将请求发送到该URI,然后由目标Servlet处理请求并生成响应。这意味着目标Servlet无法访问原始请求的上下文信息。 -
使用
forward()方法时,目标Servlet可以继续处理请求,直到完成处理或调用RequestDispatcher对象的include()方法。而使用redirect()方法时,目标Servlet只能处理新的请求URI,而不能处理原始请求的上下文信息。
具体案例代码如下:
// 导入相关类
import java.io.IOException;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/ForwardAndRedirectExample")
public class ForwardAndRedirectExample extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 设置请求属性
request.setAttribute("message", "Hello, this is a forward example!");
// 转发请求到目标Servlet
RequestDispatcher dispatcher = request.getRequestDispatcher("/TargetServlet");
dispatcher.forward(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 设置请求属性
request.setAttribute("message", "Hello, this is a redirect example!");
// 重定向到目标Servlet
response.sendRedirect("/TargetServlet");
}
}
在这个例子中,我们创建了一个名为ForwardAndRedirectExample的Servlet,它有两个方法:doGet()和doPost()。当用户通过GET或POST方法访问这个Servlet时,它会设置一个名为message的请求属性,然后使用RequestDispatcher对象的forward()或redirect()方法将请求转发或重定向到名为/TargetServlet的目标Servlet。
48、什么是序列化,在SpringBoot数据库对应的实体类为什么要进行序列化,序列化和不去序列化有什么区别
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String username;
private String password;
// 其他属性,getter和setter方法
}
和
public class User{
private String username;
private String password;
// 其他属性,getter和setter方法
}
在Java中,序列化是一种将对象的状态信息转换为可以存储或传输的形式的过程。在第一个代码示例中,User类实现了Serializable接口,这意味着它可以被序列化。在第二个代码示例中,User类没有实现Serializable接口,因此不能被序列化。
以下是序列化的一些主要用途:
对象持久化:当你想将一个对象保存到文件或数据库中,或者通过网络发送到另一个运行相同应用的机器上时,你需要使用序列化。
远程方法调用(RMI):如果你想在一个JVM(Java虚拟机)上调用另一个JVM上的对象的方法,那么你需要使用序列化来传递对象的状态。
在内存中保存对象状态:例如,如果你想在服务器重启后,能够重新创建对象的状态,那么你需要序列化。
如果一个类没有被设计为可序列化的,那么当你试图将其序列化时,会抛出NotSerializableException。
对于Spring Boot应用中的User类,如果你想将其状态保存下来(例如,保存到数据库),或者在不同的JVM之间传输,那么你需要使其可序列化。如果User类只是作为一个普通的Java对象,不涉及上述操作,那么是否实现Serializable接口就无关紧要了。
以下是一个使用序列化的具体案例代码:
import java.io.*;
public class SerializeDemo {
public static void main(String[] args) {
User user = new User("Alice", "password123");
try {
FileOutputStream fileOut = new FileOutputStream("user.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(user);
out.close();
fileOut.close();
System.out.println("Serialized data is saved in user.ser");
} catch (IOException i) {
i.printStackTrace();
}
}
}
class User implements Serializable {
private static final long serialVersionUID = 1L;
private String username;
private String password;
// 其他属性,getter和setter方法
public User(String username, String password) {
this.username = username;
this.password = password;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
在这个例子中,我们创建了一个User类,并实现了Serializable接口,使其可以被序列化。然后,我们创建一个User对象并将其序列化到文件user.ser中。
当我们在另一个JVM中反序列化该对象时,我们可以重新创建User对象并访问其属性。
在Spring Boot中,创建数据对应的实体类并不一定需要进行序列化。序列化是将对象转换为字节流的过程,以便可以将其存储到文件或通过网络传输。
在许多情况下,实体类不需要进行序列化,例如在内存中处理对象或将其存储到数据库中。
如果不将实体类序列化,不会有任何问题。实体类仍然可以作为普通Java对象使用,并且可以通过Spring Data JPA或MyBatis等持久层框架进行存储和检索。
然而,如果需要将实体类对象存储到文件或通过网络传输,或者需要在不同的JVM之间共享对象状态,那么就需要进行序列化。
序列化是将对象转换为字节流的过程,以便可以将其存储到文件或通过网络传输。反序列化是将字节流转换回对象的过程,以便可以在另一个JVM中重新创建对象。
总之,实体类是否需要序列化取决于具体的应用场景和需求。
如果需要将对象存储到文件或通过网络传输,或者需要在不同的JVM之间共享对象状态,那么就需要进行序列化。否则,实体类可以作为普通Java对象使用,不需要进行序列化。
49、java通过JDBC操作数据库、实现增删改查
要使用Java通过JDBC操作数据库,首先需要导入相关的包,然后创建一个数据库连接,接着创建一个Statement对象,最后通过Statement对象执行SQL语句。以下是一个简单的示例:
- 导入相关包:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
- 创建数据库连接:
public class JdbcExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/test_db";
String user = "root";
String password = "your_password";
try {
Connection connection = DriverManager.getConnection(url, user, password);
System.out.println("数据库连接成功");
} catch (SQLException e) {
System.out.println("数据库连接失败");
e.printStackTrace();
}
}
}
- 创建Statement对象并执行SQL语句:
public class JdbcExample {
public static void main(String[] args) {
// ...省略数据库连接部分...
try {
Statement statement = connection.createStatement();
// 插入数据
String insertSql = "INSERT INTO users (name, age) VALUES ('张三', 25)";
int insertResult = statement.executeUpdate(insertSql);
System.out.println("插入数据成功,影响行数:" + insertResult);
// 查询数据
String querySql = "SELECT * FROM users";
ResultSet resultSet = statement.executeQuery(querySql);
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
System.out.println("ID: " + id + ", Name: " + name + ", Age: " + age);
}
// 更新数据
String updateSql = "UPDATE users SET age = 26 WHERE name = '张三'";
int updateResult = statement.executeUpdate(updateSql);
System.out.println("更新数据成功,影响行数:" + updateResult);
// 删除数据
String deleteSql = "DELETE FROM users WHERE name = '张三'";
int deleteResult = statement.executeUpdate(deleteSql);
System.out.println("删除数据成功,影响行数:" + deleteResult);
statement.close();
connection.close();
} catch (SQLException e) {
System.out.println("操作数据库失败");
e.printStackTrace();
}
}
}
注意:在实际项目中,建议使用PreparedStatement代替Statement,以防止SQL注入攻击。同时,为了提高性能和资源利用率,建议使用连接池管理数据库连接。
50、java中JDBC如何防止SQL注入
在Java中,使用JDBC时可以通过以下几种方式防止SQL注入:
- 使用预编译语句(PreparedStatement):预编译语句可以有效地防止SQL注入,因为它们将参数与SQL查询分开处理。这样,即使用户输入包含恶意代码的参数,也不会被解释为SQL代码。
示例代码:
String userInput = "some_user_input";
String sql = "SELECT * FROM users WHERE username = ?";
try (Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "username", "password");
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
preparedStatement.setString(1, userInput);
ResultSet resultSet = preparedStatement.executeQuery();
} catch (SQLException e) {
e.printStackTrace();
}
- 使用存储过程:在某些情况下,可以使用存储过程来执行数据库操作,从而避免直接拼接SQL语句。存储过程可以将参数作为输入传递,而不是直接嵌入到SQL语句中。
示例代码:
String userInput = "some_user_input";
String sql = "{call get_users(?)}";
try (Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "username", "password");
CallableStatement callableStatement = connection.prepareCall(sql)) {
callableStatement.setString(1, userInput);
ResultSet resultSet = callableStatement.executeQuery();
} catch (SQLException e) {
e.printStackTrace();
}
- 对用户输入进行验证和过滤:在将用户输入传递给数据库之前,对其进行验证和过滤,以确保它不包含可能导致SQL注入的字符或模式。这可以通过正则表达式、白名单等方法实现。
总之,为了防止SQL注入,最好的做法是使用预编译语句或存储过程,并对用户输入进行适当的验证和过滤。
51、Exception 和 Error 有什么区别?
在Java中,Exception和Error都是继承自java.lang.Throwable的类,它们都代表了程序运行时可能遇到的问题。
然而,它们之间的主要区别在于问题的严重程度以及程序员处理这些问题的方式:
-
Exception(异常):
Exception是程序运行过程中预期可能会发生的一些非正常情况,通常可以预见并进行处理。它分为两种类型:- Checked Exception(检查型异常):这是编译器强制要求处理的异常,例如
IOException、SQLException等。在方法签名上需要声明这些异常或者在方法内部捕获并处理。 - Unchecked Exception(未检查型异常):也称为运行时异常,如
NullPointerException、ArrayIndexOutOfBoundsException、IllegalArgumentException等,它们是RuntimeException及其子类的实例。虽然编译器不会强制处理,但它们仍然可能导致程序崩溃,因此推荐在编码阶段尽量避免或妥善处理。
- Checked Exception(检查型异常):这是编译器强制要求处理的异常,例如
-
Error(错误):
Error表示严重的系统错误或者资源耗尽的情况,这些通常是JVM自身无法处理或者恢复的错误条件,比如OutOfMemoryError、VirtualMachineError、ThreadDeath等。这类错误往往与编程逻辑无关,更多地与系统的底层资源限制、严重故障或不可恢复的状态有关。- 对于大多数
Error,应用程序代码一般不需要也无法合理地去捕获并处理,因为它们通常标志着系统环境出现了根本性的问题,超出了应用能够自我修复的范围。
总结来说,Exception更偏向于可控制和可恢复的异常情况,而Error则代表着较为严重且通常难以通过常规手段来恢复的错误状况。
52、Checked Exception 和 Unchecked Exception 有什么区别?
Java 中的 Checked Exception 和 Unchecked Exception 的区别主要在于编译器对它们的要求和处理方式不同。下面通过具体案例代码来说明:
Checked Exception(检查型异常)
检查型异常在编译时就需要被处理,如果不处理,编译器会报错。通常,这类异常是可以通过修改程序逻辑或者外部资源的状态来避免的。
import java.io.File;
import java.io.IOException;
public class CheckedExample {
public static void main(String[] args) {
// 操作文件可能会抛出 IOException,这是个 Checked Exception
try {
readFile(new File("non_existent_file.txt"));
} catch (IOException e) {
System.out.println("File not found or could not be read: " + e.getMessage());
}
}
// 方法声明抛出了一个 Checked Exception
public static void readFile(File file) throws IOException {
if (!file.exists()) {
throw new FileNotFoundException("File not found: " + file.getName());
}
// 实际的读取文件操作...
}
}
在上述代码中,readFile 方法声明了它可能抛出 IOException,这是一种检查型异常。因此,在调用该方法的地方必须捕获或声明抛出此异常。
Unchecked Exception(运行时异常)
运行时异常在编译时不强制处理,但如果在运行时发生,则可能导致程序中断执行。这些异常通常表示编程错误,如空指针引用、数组越界等。
public class UncheckedExample {
public static void main(String[] args) {
String str = null;
// 调用对象的方法但对象为 null,这将抛出 NullPointerException,是 Unchecked Exception
try {
printLength(str);
} catch (NullPointerException e) {
System.out.println("Null pointer exception occurred: " + e.getMessage());
}
}
// 该方法没有声明抛出任何异常,但内部操作可能会抛出 Unchecked Exception
public static void printLength(String s) {
System.out.println("Length of string is: " + s.length()); // 如果 s 为 null,这里会抛出 NullPointerException
}
}
在上述代码中,printLength 方法并未声明抛出任何异常,但在调用 s.length() 时如果 s 为 null,则会抛出 NullPointerException 这种运行时异常。虽然编译器不会要求我们显式处理这个异常,但是建议在编码阶段尽量避免此类异常的发生,例如在调用之前检查参数是否为 null。
53、Throwable 类常用方法有哪些?
Java中的java.lang.Throwable类是所有错误(Error)和异常(Exception)的基类,它是Java异常处理机制的核心。Throwable类包含了一些常用的方法:
-
getMessage()
- 返回描述该异常或错误情况的消息字符串,通常用于获取异常发生时的具体信息。
-
getLocalizedMessage()
- 返回用当前locale创建的详细消息字符串,可能与getMessage()返回的有所不同,具体取决于实现。
-
printStackTrace()
- 打印此
Throwable及其堆栈跟踪到标准错误输出流System.err中。堆栈跟踪信息包含了异常发生的位置以及导致异常的一系列方法调用序列。
- 打印此
-
toString()
- 返回该对象的简短描述,通常包含类名和详细的异常信息。
-
getCause()
- 返回引发当前异常的原因,即嵌套的“原因”异常,如果有的话,返回的是另一个
Throwable对象。
- 返回引发当前异常的原因,即嵌套的“原因”异常,如果有的话,返回的是另一个
-
initCause(Throwable cause)
- 初始化这个
Throwable对象的原因,只能在第一次抛出异常后且没有设置过cause时使用。
- 初始化这个
-
fillInStackTrace()
- 生成并初始化此
Throwable对象的堆栈跟踪数据。默认情况下,当一个异常被创建时会自动调用此方法。
- 生成并初始化此
-
getStackTrace()
- 返回一个表示堆栈跟踪元素的数组,这些元素表示从方法调用堆栈到异常被抛出位置的路径。
-
setStackTrace(StackTraceElement[] stackTrace)
- 设置此
Throwable对象的堆栈跟踪元素数组。
- 设置此
-
addSuppressed(Throwable exception)
- 添加一个被抑制的异常,这个方法主要用于处理多异常捕获场景下,某个catch块内部抛出了新的异常,但希望记录之前被捕获但未处理的异常。
-
getSuppressed()
- 返回一个包含所有被抑制的异常的数组,这些异常是在同一时刻尝试抛出但因为另一个异常而被抑制的。
以上就是Throwable类的一些常见方法,它们对于调试、日志记录和程序健壮性等方面都非常重要。
54、try-catch-finally 如何使用?
Java中的try-catch-finally语句用于异常处理,它允许你捕获并处理可能出现的异常情况。以下是一个具体的使用案例代码:
public class TryCatchFinallyExample {
public static void main(String[] args) {
try {
// 可能抛出异常的代码块
int arrayIndex = 5;
int[] numbers = {1, 2, 3, 4};
System.out.println("Value at index " + arrayIndex + ": " + numbers[arrayIndex]);
} catch (ArrayIndexOutOfBoundsException e) {
// 捕获并处理ArrayIndexOutOfBoundsException异常
System.out.println("Caught an ArrayIndexOutOfBoundsException: " + e.getMessage());
e.printStackTrace();
} finally {
// 不论try或catch中是否有异常发生,finally块中的代码都会被执行
System.out.println("This block is always executed, even if an exception occurs.");
// 这里可以关闭资源、清理操作等,确保无论是否出现异常都能得到执行
}
// 继续执行其他代码...
}
}
在这个例子中,
try块包含可能抛出异常的代码(这里尝试访问数组的一个不存在的索引)。- 当在
try块内抛出ArrayIndexOutOfBoundsException时,程序会立即跳转到对应的catch块来处理这个异常。 finally块内的代码无论try块内是否抛出了异常,或者catch块是否捕获到了异常,都将被执行。通常在这里放置那些必须执行的清理操作,比如关闭文件流、数据库连接等。
注意:
- 如果
try块中有一个return语句,那么finally块仍然会在方法返回之前执行。 - 如果
finally块也包含一个return语句,则该return语句将覆盖try和catch块中的任何return语句。但是,方法的实际返回值是在finally块执行前确定的。如果finally块改变了变量的值,这不会影响到已经确定的方法返回值。
55、finally 中的代码一定会执行吗?
finally块中的代码在大多数情况下确实会执行,无论是否发生异常或是否使用了return语句。但是,也有一些特殊场景下,finally块可能不会被执行:
- 程序正常终止(如调用System.exit(int)):如果在
try或catch块中调用了System.exit(int)方法来终止Java虚拟机(JVM),那么finally块将不会被执行。
public class FinallyExample {
public static void main(String[] args) {
try {
System.out.println("Before calling System.exit()");
System.exit(0);
// 这里的代码不会被执行
} catch (Exception e) {
//...
} finally {
System.out.println("This won't be printed if System.exit() is called.");
}
}
}
- 线程被中断:如果包含
try-finally结构的线程在执行到finally块之前被中断且没有处理中断请求,那么finally块可能不会被执行。
public class ThreadFinallyExample {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
try {
while (true) {
// 模拟长时间运行的任务
}
} finally {
System.out.println("This might not be printed if the thread is interrupted.");
}
});
thread.start();
Thread.sleep(100); // 等待线程开始运行
thread.interrupt(); // 中断线程
}
}
除此之外,正常情况下,即使try块中有return语句,finally块也将在方法返回前执行。以下是一个示例:
public class FinallyAlwaysExecutes {
public static int methodWithReturn() {
try {
System.out.println("Inside try block");
return 42; // return语句
} catch (Exception e) {
System.out.println("Inside catch block");
} finally {
System.out.println("Inside finally block, always executed!");
}
return -1; // 不会执行到这里
}
public static void main(String[] args) {
System.out.println(methodWithReturn());
}
}
在这个例子中,尽管methodWithReturn方法的try块中有return语句,但finally块仍然会被执行,并且先于return语句执行完毕。
56、如何使用 try-with-resources 代替try-catch-finally?
Java 7 引入了try-with-resources语句,它简化了对实现了 java.lang.AutoCloseable 接口的资源(如:文件、数据库连接等)的管理和关闭。
当资源实例在try块中初始化后,无论是否抛出异常,都会自动调用资源的 close() 方法。
以下是一个使用 try-with-resources 替换传统 try-catch-finally 结构来读取文件并确保文件流被正确关闭的案例代码:
传统 try-catch-finally 方式:
import java.io.*;
public class TraditionalTryCatchFinallyExample {
public static void main(String[] args) {
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader("example.txt"));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
使用 try-with-resources 方式:
import java.io.*;
public class TryWithResourcesExample {
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("example.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上述第二个例子中,BufferedReader 实例被声明在 try 关键字后面的括号内,这意味着 Java 编译器会自动生成相应的 finally 块来确保在 try 或 catch 执行完毕后,不论是否发生异常,都会调用 BufferedReader 的 close() 方法关闭文件流。
57、异常使用有哪些需要注意的地方?
在Java中使用异常时,需要注意以下几点,并通过具体案例代码进行说明:
-
合理抛出和捕获异常
- 只有在发生异常条件时才应该抛出异常。不应滥用异常作为控制流程的手段。
public void divide(int a, int b) throws ArithmeticException { if (b == 0) { throw new ArithmeticException("Division by zero is not allowed."); } int result = a / b; // ... } -
正确处理资源管理
- 使用
try-with-resources语句自动关闭需要关闭的资源,如流、连接等。
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) { String line; while ((line = reader.readLine()) != null) { System.out.println(line); } } catch (IOException e) { e.printStackTrace(); } - 使用
-
避免空指针异常
- 在访问对象或数组之前检查其是否为null,以防止NullPointerException。
String str = getNullableString(); if (str != null) { System.out.println(str.length()); } else { System.out.println("String is null."); } -
明确异常类型
- 抛出具体的异常子类,而不是过于通用的异常基类,这有助于调用者准确判断如何处理异常。
public void readFile(String filePath) throws FileNotFoundException { File file = new File(filePath); if (!file.exists()) { throw new FileNotFoundException("File " + filePath + " not found."); } //... } -
恰当处理checked异常
- 如果一个方法可能会抛出checked异常,要么在方法签名中声明它,要么在方法内部捕获并处理。
public void processFile() throws IOException { FileInputStream fis = new FileInputStream("input.txt"); // 处理文件内容... // 关闭输入流(此处假设没有使用try-with-resources) fis.close(); } -
不要忽略捕获到的异常
- 不要简单地捕获异常而不做任何处理或者只是打印堆栈跟踪信息。至少应该记录异常详情,然后根据实际情况决定是继续执行还是停止程序。
try { // 可能抛出异常的操作 } catch (SomeException e) { logger.error("An error occurred: ", e); // 或者在此处进行适当的恢复操作 } -
避免过多的嵌套catch块
- 当有多个可能抛出的异常需要处理时,可以考虑合并具有相同处理逻辑的异常类型,或者将它们包装成一个更一般的异常。
-
清理工作放在finally块中
- 当需要确保无论是否发生异常都能执行某些清理工作时,使用finally块。
Connection conn = null; try { conn = dataSource.getConnection(); // 执行数据库操作... } catch (SQLException e) { // 处理SQL异常 } finally { if (conn != null) { try { conn.close(); } catch (SQLException e) { // 记录但不中断清理过程中的异常 logger.error("Error closing connection", e); } } }
58、什么是泛型?有什么作用?
Java中的泛型(Generics)是一种用于参数化类型的方法,允许在编译时为类、接口或方法指定类型参数。这些类型参数可以在代码中用作占位符,代表某种未知的类型,在使用类或方法时可以传入具体的类型来替代这些占位符。
作用:
-
类型安全:通过强制编译器进行类型检查,能够在编译阶段发现潜在的类型错误,而不是等到运行时才抛出异常。例如,容器类如List、Map等在添加元素或获取元素时,编译器能确保元素类型与容器声明的类型一致。
-
代码重用:无需为每种数据类型编写重复的类和方法,一个泛型类或方法就可以处理多种类型的对象,提高了代码的可复用性和灵活性。
-
消除类型转换:在使用非泛型集合时,需要经常做类型转换,而使用泛型后,可以从集合中直接取出期望类型的对象,无需显式转换。
案例代码:
// 泛型类示例
public class GenericClass<T> {
private T value;
public void setValue(T value) {
this.value = value;
}
public T getValue() {
return value;
}
public static void main(String[] args) {
// 创建一个Integer类型的GenericClass实例
GenericClass<Integer> integerBox = new GenericClass<>();
integerBox.setValue(42);
System.out.println(integerBox.getValue()); // 输出:42
// 创建一个String类型的GenericClass实例
GenericClass<String> stringBox = new GenericClass<>();
stringBox.setValue("Hello, World!");
System.out.println(stringBox.getValue()); // 输出:"Hello, World!"
}
}
// 泛型方法示例
public class Util {
public static <T extends Comparable<T>> int compare(T a, T b) {
return a.compareTo(b);
}
public static void main(String[] args) {
System.out.println(compare(5, 10)); // 输出:-1 (因为5小于10)
System.out.println(compare("apple", "banana")); // 输出:-1 (因为"apple"字典序在"banana"之前)
}
}
在这两个例子中,GenericClass 是一个泛型类,它可以存储任何类型的对象,并且通过类型参数 T 确保了存取操作的类型一致性。Util 类中的 compare 方法是一个泛型方法,它接受任意实现了 Comparable 接口的对象并比较它们,这使得该方法可以用于不同类型但具有自然排序规则的对象。
59、泛型的使用方式有哪几种?
Java中的泛型使用方式主要有以下几种:
-
泛型类(Generic Class)
- 泛型类允许定义一个可以接受任何类型的类模板,具体的类型在实例化时指定。
public class GenericClass<T> { private T value; public void setValue(T value) { this.value = value; } public T getValue() { return value; } } // 使用示例: GenericClass<String> stringBox = new GenericClass<>(); stringBox.setValue("Hello"); String str = stringBox.getValue(); -
泛型接口(Generic Interface)
- 类似于泛型类,也可以为接口定义类型参数。
public interface GenericInterface<T> { void process(T item); } // 实现与使用示例: class Processor implements GenericInterface<String> { @Override public void process(String item) { System.out.println("Processing: " + item); } } GenericInterface<String> processor = new Processor(); processor.process("Some text"); -
泛型方法(Generic Method)
- 即在方法签名中包含类型参数的方法,这样方法能够处理多种类型的数据。
public class Util { public static <T> void printList(List<T> list) { for (T item : list) { System.out.println(item); } } public static void main(String[] args) { List<String> strings = Arrays.asList("A", "B", "C"); Util.printList(strings); // 泛型方法处理String列表 List<Integer> numbers = Arrays.asList(1, 2, 3); Util.printList(numbers); // 同样的泛型方法处理Integer列表 } } -
泛型的上下界限制
- 在声明泛型时,可以通过
extends或super关键字来指定类型参数的上限或下限。这有助于限制传入的类型必须是某个类或接口的子类或超类。
public class BoundedGeneric<T extends Number> { private T value; public void setValue(T value) { this.value = value; } // ... } // 上述代码中,类型参数T被限制为Number及其子类 - 在声明泛型时,可以通过
-
通配符类型(Wildcards)
- 使用通配符
?可以代表未知的具体类型,例如List<?>表示可以接受任意类型的List。
- 使用通配符
通过这些不同的泛型使用方式,可以在编写更加灵活、可复用和类型安全的Java代码时大大增强程序设计能力。
60、Java当中什么是反射,具体案例代码
Java反射(Reflection)是Java运行时提供的一种强大的工具,它允许在运行时检查类、接口、字段和方法的信息,并动态地创建对象、调用方法或访问字段。
通过反射API,程序可以获取到关于类的结构信息,并能进行诸如获取构造函数、执行私有方法、修改私有属性等操作。
以下是一个简单的Java反射案例代码:
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class ReflectionExample {
public static void main(String[] args) {
try {
// 获取String类的Class对象
Class<?> stringClass = Class.forName("java.lang.String");
// 输出类名
System.out.println("Class name: " + stringClass.getName());
// 获取并输出所有公共字段
Field[] fields = stringClass.getFields();
for (Field field : fields) {
System.out.println("Public field: " + field.getName());
}
// 获取并输出指定名称的方法
Method method = stringClass.getMethod("length");
System.out.println("Method: " + method.getName());
// 使用默认构造函数创建一个String对象实例
Constructor<String> constructor = stringClass.getConstructor();
String str = constructor.newInstance();
System.out.println("Created instance: " + str);
// 动态调用方法
int length = (int) method.invoke(str);
System.out.println("Length of the string: " + length);
// 访问私有字段(假设有一个私有字段)
Field privateField = stringClass.getDeclaredField("value");
privateField.setAccessible(true); // 允许访问私有字段
char[] valueChars = (char[]) privateField.get(str);
System.out.println("Value of private field 'value': " + new String(valueChars));
} catch (ClassNotFoundException | NoSuchMethodException | IllegalAccessException |
InstantiationException | InvocationTargetException | NoSuchFieldException e) {
e.printStackTrace();
}
}
}
在这个例子中,我们首先获取了java.lang.String类的Class对象,然后使用反射API获取类的公共字段、方法以及默认构造函数,并创建了一个新的字符串实例。
接着,我们动态调用了字符串的length()方法,并访问了其内部的私有字段(注意:实际的String类并没有名为value的私有字段,这里仅用于演示目的)。
另外,像 Java 中的一大利器 注解 的实现也用到了反射。为什么你使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
61、Java当中什么是注解?
Java中的注解(Annotation)是一种元数据,它提供了一种安全的、类似于注释的机制,可以在源代码级别对类、方法、字段等程序元素添加描述信息。这些信息可以被编译器、开发工具或其他运行时环境所解析和处理,用于生成文档、执行编译检查、动态修改程序行为或实现框架功能增强。
注解不会直接影响程序的正常执行流程,但可以通过反射API在运行时读取注解信息并据此调整应用程序的行为。
例如:
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
// 定义一个注解
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {
String value() default "";
}
// 使用注解
public class MyClass {
@MyAnnotation(value = "This is a custom annotation")
public void myMethod() {
// ...
}
}
在这个例子中,MyAnnotation 是自定义的一个注解,使用了 @Retention(RetentionPolicy.RUNTIME) 指定了这个注解在编译后仍保留在字节码文件中,因此可以在运行时通过反射获取到该注解的信息。而 MyClass 类中的 myMethod 方法应用了 @MyAnnotation 注解,并提供了值 "This is a custom annotation"。
Java也内置了一些标准注解,如 @Override 用于检查是否正确重写了超类的方法;@Deprecated 用于标记已过时的元素;@ SuppressWarnings 用于抑制编译器警告等。
62、Java当中何谓 SPI?
Java SPI(Service Provider Interface)是一种标准的服务发现机制,允许在运行时动态加载实现特定接口的类。SPI通过在META-INF/services/目录下创建一个配置文件来指定服务提供者。
以下是一个简单的Java SPI使用案例:
- 首先定义一个接口作为服务接口:
package com.example.spi;
public interface ServiceInterface {
void doSomething();
}
- 创建两个实现了上述接口的类,它们将作为服务提供者:
package com.example.spi.impl;
import com.example.spi.ServiceInterface;
public class ServiceProviderOne implements ServiceInterface {
@Override
public void doSomething() {
System.out.println("ServiceProviderOne is doing something.");
}
}
// 另一个服务提供者
package com.example.spi.impl;
import com.example.spi.ServiceInterface;
public class ServiceProviderTwo implements ServiceInterface {
@Override
public void doSomething() {
System.out.println("ServiceProviderTwo is doing something.");
}
}
- 在
META-INF/services/目录下为服务接口创建一个配置文件,并列出所有可用的服务提供者类名:
# 文件路径:src/main/resources/META-INF/services/com.example.spi.ServiceInterface
com.example.spi.impl.ServiceProviderOne
com.example.spi.impl.ServiceProviderTwo
- 使用Java SPI API加载并实例化服务提供者:
import java.util.ServiceLoader;
public class SpiDemo {
public static void main(String[] args) {
ServiceLoader<ServiceInterface> serviceLoader = ServiceLoader.load(ServiceInterface.class);
for (ServiceInterface provider : serviceLoader) {
provider.doSomething();
}
}
}
当运行SpiDemo时,它会自动加载和实例化在配置文件中声明的所有ServiceInterface的实现类,并调用它们的doSomething()方法。
这就是Java SPI的基本工作原理和应用方式。