Java实训代码、答案,如果能够帮到您,希望可以点个赞!!!
如果有问题可以csdn私聊或评论!!!感谢您的支持
第1关:为什么要有训练集与测试集
1、下面正确的是?( D )
A、将手头上所有的数据拿来训练模型,预测结果正确率最高的模型就是我们所要选的模型。
B、将所有数据中的前百分之70拿来训练模型,剩下的百分之30作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
C、将所有数据先随机打乱顺序,一半用来训练模型,一半作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
D、将所有数据先随机打乱顺序,百分之80用来训练模型,剩下的百分之20作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
2、训练集与测试集的划分对最终模型的确定有无影响?( A )
A、有
B、无
第2关:欠拟合与过拟合
1、请问,图中A与B分别处于什么状态?( B )
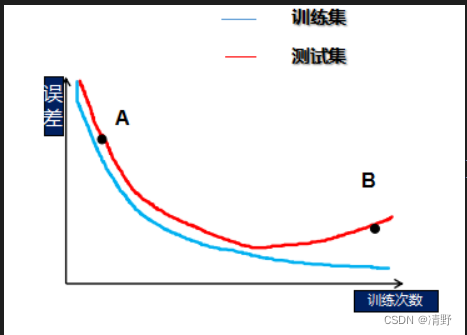
A、欠拟合,欠拟合
B、欠拟合,过拟合
C、过拟合,欠拟合
D、过拟合,过拟合
2、如果一个模型在训练集上正确率为99%,测试集上正确率为60%。我们应该怎么做?( ABD )
A、加入正则化项
B、增加训练样本数量
C、增加模型复杂度
D、减少模型复杂度
第3关:偏差与方差
如果一个模型,它在训练集上正确率为85%,测试集上正确率为80%,则模型是过拟合还是欠拟合?其中,来自于偏差的误差为?来自方差的误差为?( B )
A、欠拟合,5%,5%
B、欠拟合,15%,5%
C、过拟合,15%,15%
D、过拟合,5%,5%
第4关:验证集与交叉验证
1、假设,我们现在利用5折交叉验证的方法来确定模型的超参数,一共有4组超参数,我们可以知道,5折交叉验证,每一组超参数将会得到5个子模型的性能评分,假设评分如下,我们应该选择哪组超参数?( D )
A、子模型1:0.8 子模型2:0.7 子模型3:0.8 子模型4:0.6 子模型5:0.5
B、子模型1:0.9 子模型2:0.7 子模型3:0.8 子模型4:0.6 子模型5:0.5
C、子模型1:0.5 子模型2:0.6 子模型3:0.7 子模型4:0.6 子模型5:0.5
D、子模型1:0.8 子模型2:0.8 子模型3:0.8 子模型4:0.8 子模型5:0.6
2、下列说法正确的是?( BCD )
A、相比自助法,在初始数据量较小时交叉验证更常用。
B、自助法对集成学习方法有很大的好处
C、使用交叉验证能够增加模型泛化能力
D、在数据难以划分训练集测试集时,可以使用自助法
第5关:衡量回归的性能指标
下列说法正确的是?( AB )
A、相比MSE指标,MAE对噪声数据不敏感
B、RMSE指标值越小越好
C、R-Squared指标值越小越好
D、当我们的模型不犯任何错时,R-Squared值为0
第6关:准确度的陷阱与混淆矩阵
import numpy as np
def confusion_matrix(y_true, y_predict):
'''
构建二分类的混淆矩阵,并将其返回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: shape为(2, 2)的ndarray
'''
#********* Begin *********#
def TN(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 0))
def FP(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 1))
def FN(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 0))
def TP(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 1))
return np.array([
[TN(y_true, y_predict), FP(y_true, y_predict)],
[FN(y_true, y_predict), TP(y_true, y_predict)]
])
#********* End *********#第7关:精准率与召回率

import numpy as np
def precision_score(y_true, y_predict):
'''
计算精准率并返回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: 精准率,类型为float
'''
#********* Begin *********#
def TP(y_true, y_predict):
return np.sum((y_true ==1)&(y_predict == 1))
def FP(y_true,y_predict):
return np.sum((y_true ==0)&(y_predict==1))
tp =TP(y_true, y_predict)
fp =FP(y_true, y_predict)
try:
return tp /(tp+fp)
except:
return 0.0
#********* End *********#
def recall_score(y_true, y_predict):
'''
计算召回率并召回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: 召回率,类型为float
'''
#********* Begin *********#
def FN(y_true, y_predict):
return np.sum((y_true ==1)&(y_predict == 0))
def TP(y_true,y_predict):
return np.sum((y_true ==1)&(y_predict==1))
fn =FN(y_true, y_predict)
tp =TP(y_true, y_predict)
try:
return tp /(tp+fn)
except:
return 0.0
#********* End *********#第8关:F1 Score

import numpy as np
def f1_score(precision, recall):
'''
计算f1 score并返回
:param precision: 模型的精准率,类型为float
:param recall: 模型的召回率,类型为float
:return: 模型的f1 score,类型为float
'''
#********* Begin *********#
try:
return 2*precision*recall / (precision+recall)
except:
return 0.0
#********* End ***********#
第9关:ROC曲线与AUC
import numpy as np
def calAUC(prob, labels):
'''
计算AUC并返回
:param prob: 模型预测样本为Positive的概率列表,类型为ndarray
:param labels: 样本的真实类别列表,其中1表示Positive,0表示Negtive,类型为ndarray
:return: AUC,类型为float
'''
#********* Begin *********#
a= list(zip(prob,labels))
rank =[values2 for values1,values2 in sorted(a, key=lambda x:x[0])]
rankList=[i+1 for i in range(len(rank))if rank[i] ==1]
posNum =0
negNum =0
for i in range(len(labels)):
if(labels[i]==1):
posNum+=1
else:
negNum+=1
auc= (sum(rankList)-(posNum*(posNum+1))/2)/(posNum*negNum)
return auc
#********* End *********#
第10关:sklearn中的分类性能指标

from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def classification_performance(y_true, y_pred, y_prob):
'''
返回准确度、精准率、召回率、f1 Score和AUC
:param y_true:样本的真实类别,类型为`ndarray`
:param y_pred:模型预测出的类别,类型为`ndarray`
:param y_prob:模型预测样本为`Positive`的概率,类型为`ndarray`
:return:
'''
#********* Begin *********#
return accuracy_score(y_true, y_pred),precision_score(y_true, y_pred),recall_score(y_true, y_pred),f1_score(y_true, y_pred),roc_auc_score(y_true, y_prob)
#********* End *********#