目录
课堂
SQL执行顺序:
开窗函数
累加order by
开窗格式:
排名
三种排名:
偏移
上偏移
下偏移
同环比
加子查询的几种方式
1 放在 select 后面
2 放在 from 后面 当表
3 放在where 后
4 放在HAVING 后面
作业
1.Order_1显示出每年每个月的订单数,并显示出下一个月比上一个月相差的订单数
2.Order_1查询出每张订单的订单id,客户id,运费,和该客户的订单量
3.Order_1查询出每张订单的订单id,客户id,和这个客户的在各个城市的总运费
4.算连续3天或三天以上登录的人有哪些
用排名解决:
用偏移解决:
5.
(1)计算每个月社保记录,算出每个人在每家公司的 最早工作时间、最近工作时间
(2)计算出每个人的每一段工作履历(二次进宫多段列出)
课堂
SQL执行顺序:
1.from 2.where 3.group by 4.having 5.select 6.order by
开窗函数
其实就是在明细后面加一列聚合
聚合:
sum()
avg()
max()
min()
count()
查询每个的工号,名字,工资,部门 及其所在部门的平均工资
001 zz 3000 10 2500
002 xx 2000 10 2500
select deptno,avg(sal) from emp group by deptno;用到开窗
group by
select emp.*,avg(sal) over(partition by deptno) 部门平均工资 from emp;
1.查询人员的 工号,姓名,工作,工资,及其对应职位的平均工资
select e.empno,e.ename,e.job,e.sal,avg(sal)over(partition by job) from emp e order by e.job;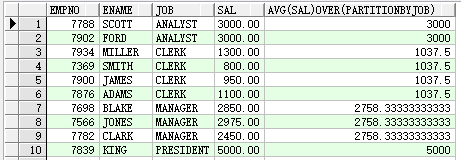
2.查询人员的 工号,部门,姓名,整个公司的平均工资
select e.empno,e.deptno,e.ename,avg(sal)over() 公司平均工资 from emp e; 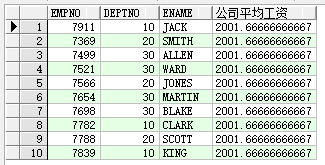
3.查询人员的 工号,姓名,部门,职位,及其所在部门相同职位的工资合计
xx 10 manage 1000 3000
10 manage 2000 3000
select e.empno,e.ename,e.deptno,e.job,
sum(sal)over(partition by deptno ,job) 同部门同职位的合计工资
from emp e order by deptno,job;
就是在明细加了 聚合 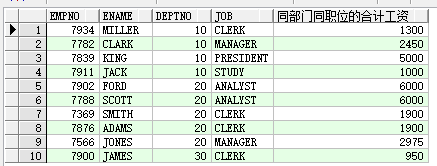
4.查询出 比其所在部门平均工资高的员工的 工号,姓名,部门,工资,所在部门的平均工资
select aa.* from
(select emp.*,avg(sal)over(partition by deptno) 部门平均工资 from emp ) aa
where sal >部门平均工资;
累加order by
1.开窗函数 分析函数
按入职时间排序,每个人员入职后,总共要发多少工资
001 1000 1000
002 1500 2500
003 1000 3500
select e.*,sum(sal)over(order by hiredate) from emp e;
2.人员入职后,各个部门的平均工资的变化情况
10 1000 1000
10 2000 1500
20 2000 2000
20 1200 1600按部门分组、按时间累加,求平均工资
select e.*,avg(sal)over(partition by deptno order by hiredate) from emp e;
3.按部门分组、按时间累加,求最高工资
select e.*,max(sal) over(partition by deptno order by hiredate) from emp e;
4.按部门分组,求平工资
select e.*,max(sal)over(partition by deptno ) from emp e; 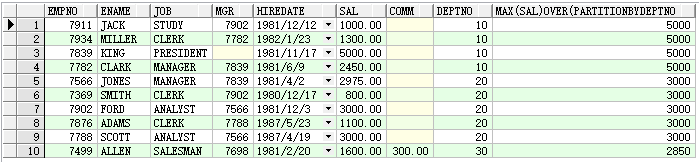
开窗格式:
聚合()over(partition by 分组 order by 排序)
排名
select aa.*,rownum from
(select emp.*,rownum from emp where deptno = 10 order by sal desc ) aa
where rownum <=3;
三种排名:
连续排名(row_number)、
跳跃排名 (rank)、
连续不跳跃排名(dense_rank)
| row_number | rank | dense_rank | |
| 90 | 1 | 1 | 1 |
| 80 | 2 | 2 | 2 |
| 70 | 3 | 3 | 3 |
| 70 | 4 | 3 | 3 |
| 60 | 5 | 5 | 4 |
1.查询公司内的人员工资排名
select e.*,
row_number()over(order by sal desc) 连续排名,
rank()over(order by sal desc) 跳跃排名,
dense_rank()over(order by sal desc) 连续不跳跃排名
from emp e;
2.找出每个部门中工资排名第二的人员
select * from
(select e.*,
row_number()over(partition by deptno order by sal desc) 连续,
rank()over(partition by deptno order by sal desc) 跳跃 ,
dense_rank()over(partition by deptno order by sal desc) 不跳
from emp e )
where 连续 = 2;
3.查询每个岗位最早入职的三人员
select * from
(select e.*,row_number()over(partition by job order by hiredate ) 入职排名 from emp e )
where 入职排名 <=3
偏移
需求
算出公司下一个入职的人员比上个入职 多多少钱?
| 上偏 | 向上偏移 | lead(字段,偏移的行数,默认值) |
| 下偏 | 向下偏移 | lag(字段,偏移的行数,默认值) |
参数
lead(字段,偏移几行,默认值)
lag(字段,偏移几行,默认值) 上偏移
select e.empno,e.ename,e.job,e.hiredate,e.deptno,e.sal,lead(sal,1,sal)over(order by hiredate ) 上偏,
lead(sal ,1,sal) over(order by hiredate )-sal 下比上入职多
from emp e where sal is not null;
下偏移
select e.*,
lag(sal ,1)over(order by hiredate) 下偏移,
sal- lag(sal ,1)over(order by hiredate)连续性
from emp e;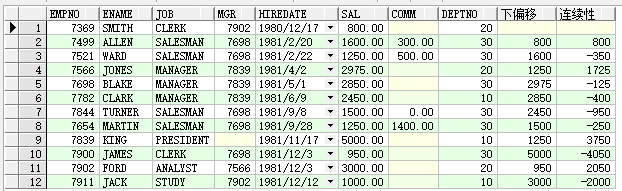
当连续性相同时,可证明三天活跃7天连续
1.查询公司职位的平均工资从多到少相差多少钱?
select aa.*,lag(职位平均,1)over(order by 职位平均 desc),
lag(职位平均,1)over(order by 职位平均 desc)-职位平均 多比少多出
from
(select job,avg(sal) 职位平均 from emp group by job) aa;
2.求相同职位的平均工资
select job,职位平均工资 from
(select job,avg(sal) over(partition by job) 职位平均工资 from emp e )
group by job,职位平均工资
select e.*,avg(sal)over(partition by deptno) from emp e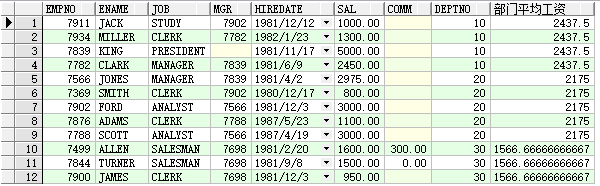
select e.*,avg(sal) over(partition by job) 职位平均工资 from emp e; 
同环比
| 同比 | 这一期比去年同期 |
| 环比 | 这一期比上一期 |
南宁市的24年2月份的房价 8000
23年2月 9000
24年1月 7000
1.南宁市24年2月房价同比增长:select trunc((8000-9000)/9000*100,4)||'%' from dual;
(新-旧)/旧 ![]()
2.南宁市24年2月房价环比增长:select trunc((8000-7000)/7000*100,4)||'%' from dual;
(新-旧)/旧 ![]()
加子查询的几种方式
1 放在 select 后面
select * from (子查询)
查询出emp人员信息及其对应的部门名称
select e.*,(select dname from dept d where d.deptno =e.deptno) 部门名称 from emp e;
2 放在 from 后面 当表
还有一种当表来查的写法
with as
比如说
查询出比其所在部门平均工资高的人员
with aa as(
select e.*,avg(sal)over(partition by job ) 平均工资 from emp e)
select * from aa where sal>平均工资
3 放在where 后
查询比 7369 工资高的人员信息
select * from emp where sal > (select sal from emp where empno=7369);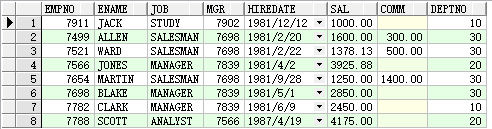
还有一种 单行多列
查询和7788同部门同职位的人员
select * from emp where (deptno,job)=( select deptno,job from emp e where e.empno = 7788);
4 放在HAVING 后面
查询出比20号部门的人多的部门
select deptno,count(1) from emp group by deptno having count(1)>( select count(1) from emp where deptno = 20);![]()
作业
1.Order_1显示出每年每个月的订单数,并显示出下一个月比上一个月相差的订单数
select aa.* ,
lag(月订量,1)over(order by 日期)下偏移,
月订量-lag(月订量,1)over(order by 日期) 下个月比上个月多
from
(select TO_CHAR(订购日期, 'yyyy-MM') 日期,count(订购日期)月订量
from Order_1 group by TO_CHAR(订购日期, 'yyyy-MM'))aa2.Order_1查询出每张订单的订单id,客户id,运费,和该客户的订单量
select 订单id,运货费,客户id,count(1)over(partition by 客户id)客户的订单量 from Order_1select 客户id,count(1) from Order_1 group by 客户id3.Order_1查询出每张订单的订单id,客户id,和这个客户的在各个城市的总运费
select 订单id,客户id,货主城市,
sum(运货费)over(partition by 客户id,货主城市) 客户的在各个城市的总运费
from Order_14.算连续3天或三天以上登录的人有哪些
建表
create table login_a
(
login_date date,
id varchar2(2)
);
insert into login_a (LOGIN_DATE, ID)
values (to_date('03-01-2022', 'dd-mm-yyyy'), 'a');
insert into login_a (LOGIN_DATE, ID)
values (to_date('02-01-2022', 'dd-mm-yyyy'), 'a');
insert into login_a (LOGIN_DATE, ID)
values (to_date('01-01-2022', 'dd-mm-yyyy'), 'a');
insert into login_a (LOGIN_DATE, ID)
values (to_date('04-01-2022', 'dd-mm-yyyy'), 'b');
insert into login_a (LOGIN_DATE, ID)
values (to_date('05-01-2022', 'dd-mm-yyyy'), 'c');
insert into login_a (LOGIN_DATE, ID)
values (to_date('06-01-2022', 'dd-mm-yyyy'), 'a');
insert into login_a (LOGIN_DATE, ID)
values (to_date('07-01-2022', 'dd-mm-yyyy'), 'b');
insert into login_a (LOGIN_DATE, ID)
values (to_date('08-01-2022', 'dd-mm-yyyy'), 'b');
insert into login_a (LOGIN_DATE, ID)
values (to_date('09-01-2022', 'dd-mm-yyyy'), 'b');
insert into login_a (LOGIN_DATE, ID)
values (to_date('10-01-2022', 'dd-mm-yyyy'), 'c');
insert into login_a (LOGIN_DATE, ID)
values (to_date('11-01-2022', 'dd-mm-yyyy'), 'c');
Commit;select * from login_a

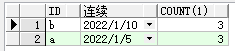
用排名解决:
select aa.id, aa.连续, count(1)
from (select a.*,
row_number() over(partition by id order by a.login_date desc) 排名,
a.login_date + row_number() over(partition by id order by a.login_date desc) 连续
from login_a a) aa
group by aa.id, aa.连续
having count(1) >= 3
用偏移解决:
select b.用户id
from (select a.id 用户id,
a.login_date 登陆日期,
lag(login_date, 1, login_date) over(partition by id order by login_date) 偏移量
from login_a a) b
where b.登陆日期 - b.偏移量 <= 1
group by 用户id
having count(*) >= 3![]()
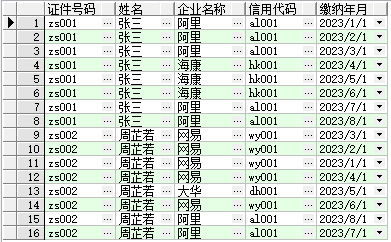
5.
建表
create table 社保缴纳记录
(
证件号码 VARCHAR2(30),
姓名 VARCHAR2(20),
企业名称 VARCHAR2(100),
信用代码 VARCHAR2(30),
缴纳年月 DATE
)
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '阿里', 'al001', to_date('01-01-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '阿里', 'al001', to_date('01-02-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '阿里', 'al001', to_date('01-03-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '海康', 'hk001', to_date('01-04-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '海康', 'hk001', to_date('01-05-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '海康', 'hk001', to_date('01-06-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '阿里', 'al001', to_date('01-07-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs001', '张三', '阿里', 'al001', to_date('01-08-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '网易', 'wy001', to_date('01-03-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '网易', 'wy001', to_date('01-02-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '网易', 'wy001', to_date('01-01-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '网易', 'wy001', to_date('01-04-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '大华', 'dh001', to_date('01-05-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '网易', 'wy001', to_date('01-06-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '阿里', 'al001', to_date('01-08-2023', 'dd-mm-yyyy'));
insert into 社保缴纳记录 (证件号码, 姓名, 企业名称, 信用代码, 缴纳年月)
values ('zs002', '周芷若', '阿里', 'al001', to_date('01-07-2023', 'dd-mm-yyyy'));
Commit;select * from 社保缴纳记录
(1)计算每个月社保记录,算出每个人在每家公司的 最早工作时间、最近工作时间
select distinct 证件号码,
企业名称,
min(缴纳年月) over(partition by 证件号码, 企业名称 ) 最早工作时间,
max(缴纳年月) over(partition by 证件号码, 企业名称 ) 最近工作时间
from 社保缴纳记录
(2)计算出每个人的每一段工作履历(二次进宫多段列出)
select distinct 连续,a.证件号码,a.姓名,a.信用代码,a.企业名称,
min(缴纳年月)over(partition by 姓名,企业名称,连续)kssj,
max(缴纳年月)over(partition by 姓名,企业名称,连续)jssj
from(select s.*,
row_number()over(partition by 姓名,企业名称 order by 缴纳年月 desc)排名,
to_char(缴纳年月,'MM')+row_number()over(partition by 姓名,企业名称 order by 缴纳年月 desc) 连续
from 社保缴纳记录 s)a
order by 姓名,kssj子表
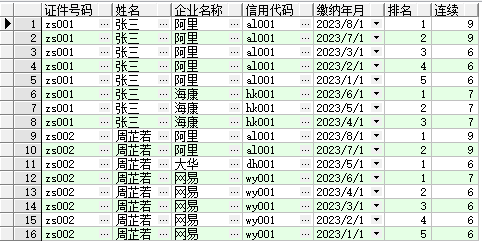
最终结果





![[大模型]ollama本地部署自然语言大模型](https://img-blog.csdnimg.cn/img_convert/33137f9e58f1daebe0f9e93126122b18.png)