Python的网络爬虫基础介绍与实战
- 定义
- 流程
- 包和函数
- 静动态网页
- 爬虫实战
- 红牛分公司?
- 二手房数据(静态网页)
- 豆瓣读书(动态网页)
定义
网络爬虫是按照一定的规则,自动地抓取万维网(www)信息的程序或者脚本。借助于网络爬虫的技术,基本上可以做到所见即所得。比如:新闻、搜索引擎、微博、竞品分析和股票等。
流程

1)发送请求,向对方服务器发送待抓取网站的链接URL;
2)返回请求,在不发生意外的情况下(意外包括网络问题、客户端问题、服务器问题等),对方服务器将会返回请求的内容(即网页源代码)
3)数据存储,利用正则表达式或解析法对源代码作清洗,并将目标数据存储到本地(txt、csv、Excel等)或数据库(MySQL、SQL Server、MongoDB等)
包和函数
import requests
import re
import bs4
requests.get – 基于URL,发送网络请求
re.findall – 基于正则表达式,搜寻目标数据
bs4.BeautifulSoup – 对HTML源代码做解析,便于目标数据的拆解
静动态网页
动态网页就是,页面信息发生变化,但网址没变。
静态网页就是,页面信息发生变化,网址也跟着变化。
爬虫实战
红牛分公司?
首先查看网页源代码。
在网页右击,选择网页源代码,即可查看网页的源代码。

再寻找规律,运用正则表达式进行提取。
import requests # 提取网页源代码包
import re
url = r'http://www.redbull.com.cn/about/branch'
response = requests.get(url) # 发送链接请求,将会反应以2开头的状态码,证明访问正常
# print(response)
# print(response.text) # 将会反应其文本信息
# print(re.findall('<h2>.*?</h2>', response.text)) # 发现所有的公司都在此规律内
company = re.findall('<h2>(.*?)</h2>', response.text) # 只选择规律内部的文字
# print(re.findall("<p class='mapIco'>.*?</p>", response.text)) # 发现所有的公司地点都在此规律内
add = re.findall("<p class='mapIco'>(.*?)</p>", response.text) # 只选择规律内部的文字
print(company)
print(add)
输出:

方法二:
因绝大多数语言都是由html语言写出来的,我们就还能发现一些规律,比如:
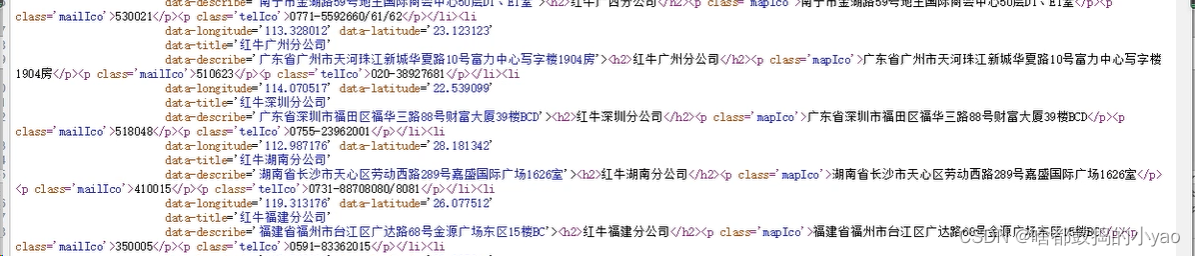
公司名称,在h2标签里;地址在p的class=‘mapIco’,邮编在class='telIco’标签里
那么我们不借助于正则表达式,先将字符转变类型对象
然后找对应找的关键字,首先在爬虫的网页中按电脑的f12,出现网页监控,用小箭头回到原网页选择抓取的内容,他就会自动出现
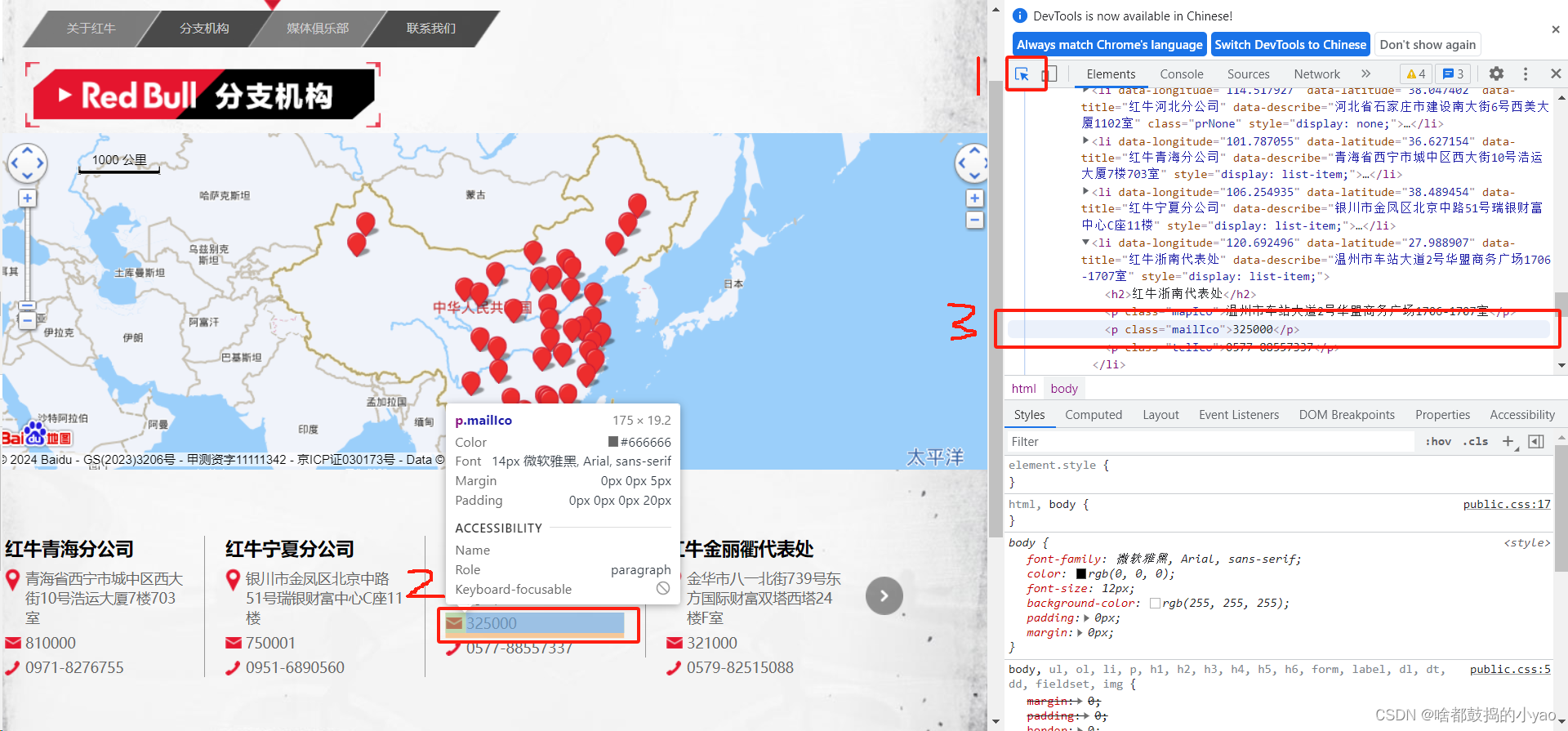
import requests # 提取网页源代码包
import re
import bs4
url = r'http://www.redbull.com.cn/about/branch'
response = requests.get(url) # 发送链接请求,将会反应以2开头的状态码,证明访问正常
soup = bs4.BeautifulSoup(response.text) # 转换字符类型
# print(soup)
a = soup.findAll(name = 'p', attrs={'class':'mailIco'}) # 第一个参数传递标记名称,第二个传递字典关键词
# print(a)
# 取出文本信息,并用列表表达式表示出来
mail = [i.text for i in a]
tel = [i.text for i in soup.findAll(name = 'p', attrs={'class':'telIco'})]
print(mail)
print(tel)
输出:

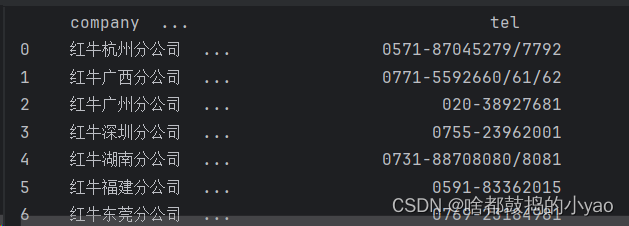
那我们来整理一下,然后将其变成表:
import requests # 提取网页源代码包
import re
import bs4
url = r'http://www.redbull.com.cn/about/branch'
response = requests.get(url) # 发送链接请求,将会反应以2开头的状态码,证明访问正常
soup = bs4.BeautifulSoup(response.text) # 转换字符类型
company = re.findall('<h2>(.*?)</h2>', response.text) # 只选择规律内部的文字
add = re.findall("<p class='mapIco'>(.*?)</p>", response.text) # 只选择规律内部的文字
a = soup.findAll(name = 'p', attrs={'class':'mailIco'}) # 第一个参数传递标记名称,第二个传递字典关键词
mail = [i.text for i in a]
tel = [i.text for i in soup.findAll(name = 'p', attrs={'class':'telIco'})]
import pandas as pd # 后面会讲的函数,利用里面的函数可将其整理变成表
out = pd.DataFrame({'company': company,'add': add, 'mail': mail, 'tel': tel})
print(out)
输出:
二手房数据(静态网页)
注意:发送链接请求,将会反应以2开头的状态码,证明访问正常(若不是,我们通过网页监视器来找请求头,然后添加)
请求头如何查找:
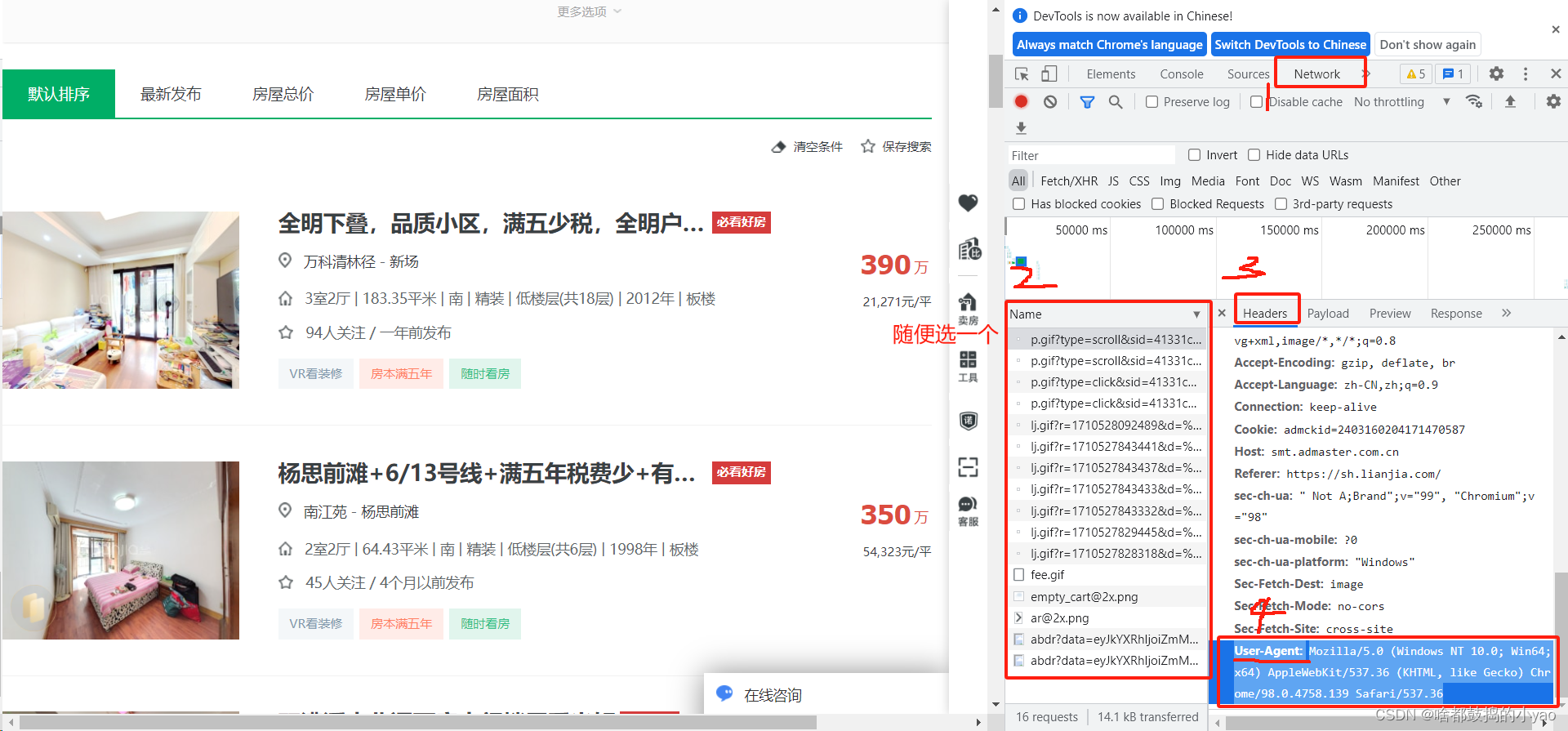
对于爬取的对象,用红牛例子中讲的方法,在网页监视器中指针定位。

import pandas as pd
import requests # 提取网页源代码包
import re
import bs4
# 1.请求信息
url = r'https://sh.lianjia.com/ershoufang/pudong/pg1/'
# 发送链接请求,将会反应以2开头的状态码,证明访问正常(若不是,我们通过网页监视器来找请求头,然后添加)
Headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'
} # 表示为浏览器请求头
response = requests.get(url, headers=Headers)
# print(response) # 查看是否为2
# 2.转换内容
soup = bs4.BeautifulSoup(response.text)
# 3.抓取内容
a = soup.findAll(name='a', attrs={'data-el': 'region'}) # 小区信息
name = [i.text.strip() for i in a] # strip是去除空格的
# print(name)
b = [i.text for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})] # 提取该内容是如何的
# print(b)
c = [i.text.split('|') for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})] # 我们发现他是用|隔开的,我们就用列表的方法弄开
# print(c)
Type = [i.text.split('|')[0].strip() for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})] # 我们发现第一列是房子类型,即可全部提取出来
# print(Type)
size = [float(i.text.split('|')[1].strip()[:-2]) for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})] # 我们提取面积的内容,再将纯数字取出,再转化成浮点类型
# print(size)
direction = [i.text.split('|')[2].strip() for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})]
# print(direction)
zhuangxiu = [i.text.split('|')[3].strip() for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})]
# print(zhuangxiu)
flool = [i.text.split('|')[4].strip() for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})]
# print(flool)
year = [i.text.split('|')[5].strip() for i in soup.findAll(name='div', attrs={'class': 'houseInfo'})]
# print(year)
total = [float(i.text[:-1]) for i in soup.findAll(name='div', attrs={'class': 'totalPrice totalPrice2'})]
# print(total)
price = [i.text for i in soup.findAll(name='div', attrs={'class': 'unitPrice'})]
# print(price) 查看之后做切片取值
price = [i.text[:-3] for i in soup.findAll(name='div', attrs={'class': 'unitPrice'})]
# print(price)
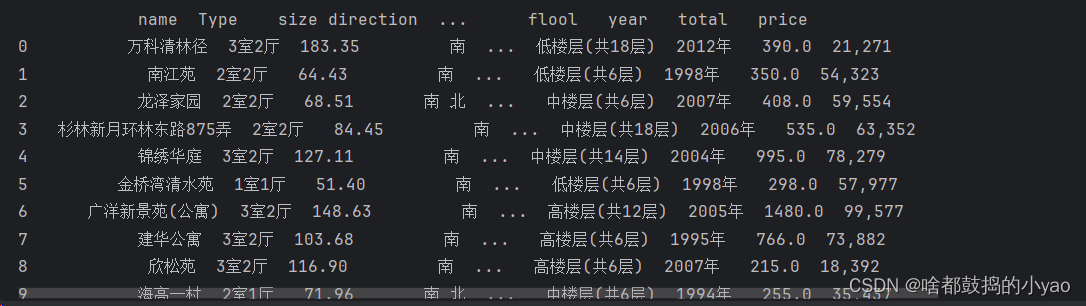
out = pd.DataFrame({'name':name,'Type':Type,'size':size,'direction':direction,'zhuangxiu':zhuangxiu,'flool':flool,'year':year,'total':total,'price':price})
print(out)
输出:
豆瓣读书(动态网页)
异步存储在动态网站
在当前页无法找到存储,但可以找到异步页
js文件或者是xhr
在开发者工具刷新下界面,选中Network
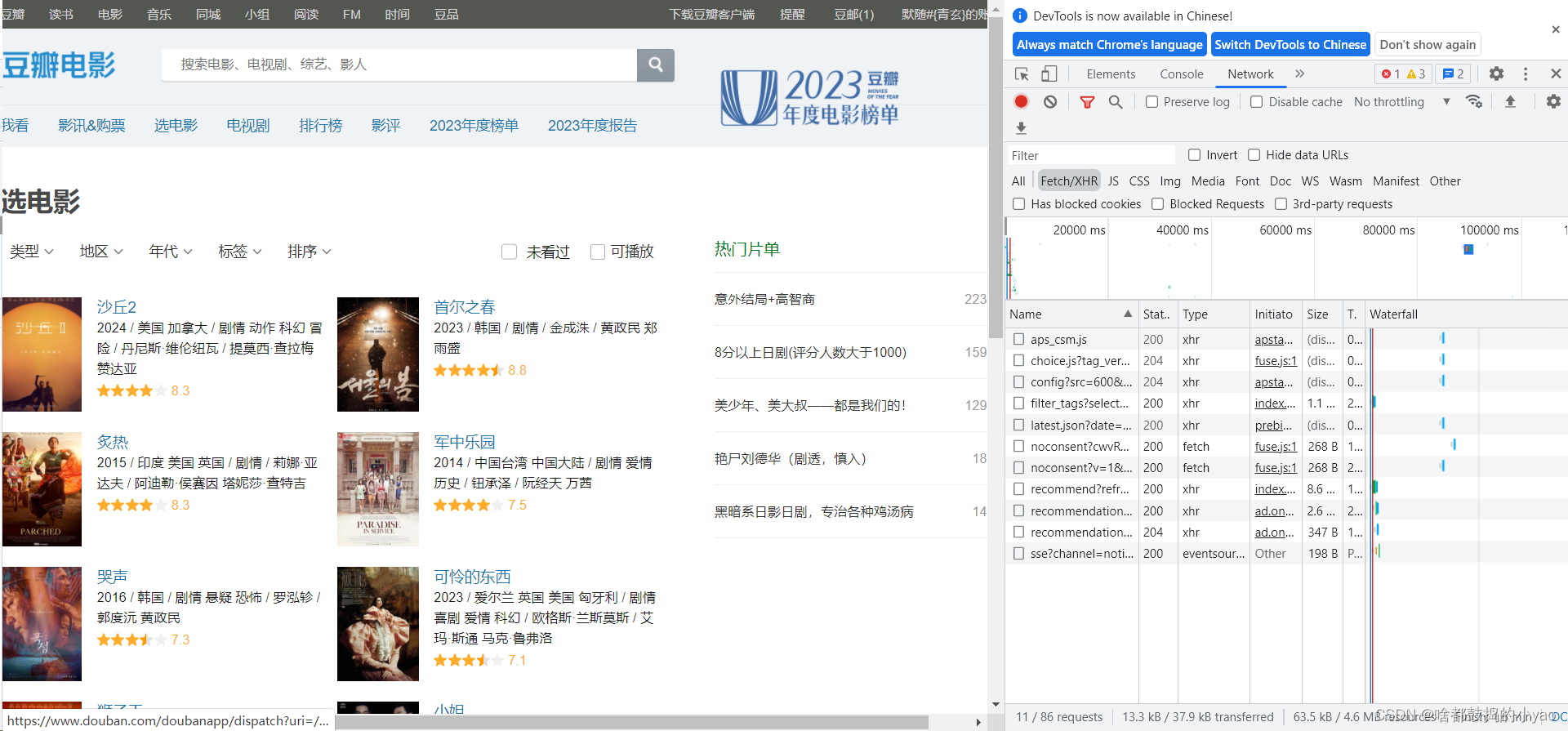

我们根据规律发现如下代码:
import re
import requests
url = r'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1,%E6%96%87%E8%89%BA&start=0&genres=%E5%96%9C%E5%89%A7&countries=%E7%BE%8E%E5%9B%BD&year_range=2010,2019'
Headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'
} # 表示为浏览器请求头
response = requests.get(url, headers=Headers)
# print(response) # 查看是否为2
print(response.text)
id = re.findall('"id":"(.*?)"', response.text)
directors = re.findall('"directors":\["(.*?)"\]',response.text)
title = re.findall('"title":"(.*?)"', response.text)
print(id)
print(directors)
print(title)
输出:



![[大模型]ollama本地部署自然语言大模型](https://img-blog.csdnimg.cn/img_convert/33137f9e58f1daebe0f9e93126122b18.png)