TransUNet是一个非常经典的图像分割模型。该模型出现在Transformer引入图像领域的早期,所以结构比较简单,但是实际上效果却比很多后续花哨的模型更好。所以有必要捋一遍pytorch实现TransUNet的整体流程。
首先,按照惯例,先看一下TransUNet的结构图:
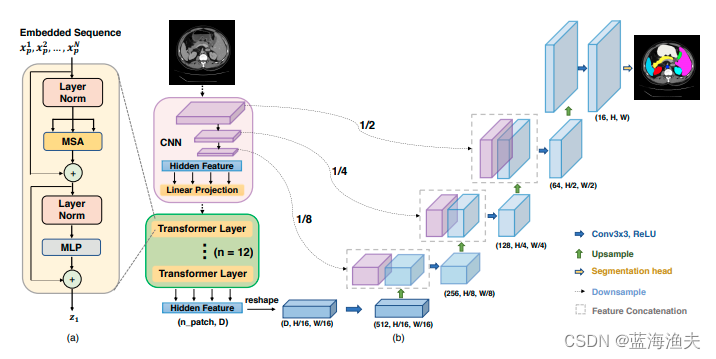
根据结构图,我们可以看出,整体结构就是基于UNet魔改的。
1,具体结构如下:
1. CNN-Transformer混合编码器:TransUNet使用卷积神经网络(CNN)作为特征提取器,生成特征图。然后,从CNN特征图中提取的1x1 patches通过patch embedding转换为序列,作为Transformer的输入。这种设计允许模型利用CNN的高分辨率特征图。
2. Transformer编码器:Transformer编码器由多头自注意力(Multihead Self-Attention, MSA)和多层感知器(MLP)块组成。这些层处理输入序列,捕获全局上下文信息。
3. 级联上采样器(Cascaded Upsampler, CUP):为了从Transformer编码器的输出中恢复空间分辨率,TransUNet引入了CUP。CUP由多个上采样步骤组成,每个步骤包括一个2x上采样操作、一个3x3卷积层和一个ReLU激活层。这些步骤将特征图从低分辨率逐步上采样到原始图像的分辨率。
4. skip connection:TransUNet采用了U-Net的u形架构设计,通过跳跃连接(skip-connections)将编码器中的高分辨率CNN特征图与Transformer编码的全局上下文特征结合起来,以实现精确的定位。
5. 解码器:解码器部分使用CUP来从Transformer编码器的输出中恢复出最终的分割掩码。这包括将Transformer的输出特征图与CNN特征图结合,并通过上采样步骤恢复到原始图像的分辨率。
我们只需要实现其每个模块,然后安装UNet拼装成整体就可以了。
2,首先实现的是编码器分支的卷积部分:
每个卷积模块可以使用resnet的一个块,或者自己实现一个
class EncoderBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, base_width=64):
super().__init__() # 初始化父类
self.downsample = nn.Sequential( # 下采样层,用于降低特征图的维度
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
width = int(out_channels * (base_width / 64)) # 计算中间通道数
self.conv1 = nn.Conv2d(in_channels, width, kernel_size=1, stride=1, bias=False) # 第一个卷积层
self.norm1 = nn.BatchNorm2d(width) # 第一个批量归一化层
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=2, groups=1, padding=1, dilation=1, bias=False) # 第二个卷积层
self.norm2 = nn.BatchNorm2d(width) # 第二个批量归一化层
self.conv3 = nn.Conv2d(width, out_channels, kernel_size=1, stride=1, bias=False) # 第三个卷积层
self.norm3 = nn.BatchNorm2d(out_channels) # 第三个批量归一化层
self.relu = nn.ReLU(inplace=True) # ReLU激活函数
def forward(self, x):
x_down = self.downsample(x) # 下采样操作
x = self.conv1(x) # 第一个卷积操作
x = self.norm1(x) # 第一个批量归一化
x = self.relu(x) # ReLU激活
x = self.conv2(x) # 第二个卷积操作
x = self.norm2(x) # 第二个批量归一化
x = self.relu(x) # ReLU激活
x = self.conv3(x) # 第三个卷积操作
x = self.norm3(x) # 第三个批量归一化
x = x + x_down # 残差连接
x = self.relu(x) # ReLU激活
return x3,实现ViT模块
多头注意力实现如下:
class MultiHeadAttention(nn.Module):
def __init__(self, embedding_dim, head_num):
super().__init__() # 调用父类构造函数
self.head_num = head_num # 多头的数量
self.dk = (embedding_dim // head_num) ** (1 / 2) # 缩放因子,用于缩放点积注意力
self.qkv_layer = nn.Linear(embedding_dim, embedding_dim * 3, bias=False) # 线性层,用于生成查询(Q)、键(K)和值(V)
self.out_attention = nn.Linear(embedding_dim, embedding_dim, bias=False) # 输出线性层
def forward(self, x, mask=None):
qkv = self.qkv_layer(x) # 通过线性层生成Q、K、V
query, key, value = tuple(rearrange(qkv, 'b t (d k h) -> k b h t d', k=3, h=self.head_num)) # 将Q、K、V重塑为多头注意力的格式
energy = torch.einsum("... i d , ... j d -> ... i j", query, key) * self.dk # 计算点积注意力的能量
if mask is not None: # 如果提供了掩码,则在能量上应用掩码
energy = energy.masked_fill(mask, -np.inf)
attention = torch.softmax(energy, dim=-1) # 应用softmax函数,得到注意力权重
x = torch.einsum("... i j , ... j d -> ... i d", attention, value) # 应用注意力权重到值上
x = rearrange(x, "b h t d -> b t (h d)") # 重塑x以准备输出
x = self.out_attention(x) # 通过输出线性层
return xMLP实现如下:
# 定义MLP模块
class MLP(nn.Module):
def __init__(self, embedding_dim, mlp_dim):
super().__init__() # 调用父类构造函数
self.mlp_layers = nn.Sequential( # 定义MLP的层
nn.Linear(embedding_dim, mlp_dim),
nn.GELU(), # GELU激活函数
nn.Dropout(0.1), # Dropout层,用于正则化
nn.Linear(mlp_dim, embedding_dim), # 线性层
nn.Dropout(0.1) # Dropout层
)
def forward(self, x):
x = self.mlp_layers(x) # 通过MLP层
return x
一个Transformer编码器块由归一化层,多头注意力,MLP和残差连接组成,实现如下:
# 定义Transformer编码器块
class TransformerEncoderBlock(nn.Module):
def __init__(self, embedding_dim, head_num, mlp_dim):
super().__init__() # 调用父类构造函数
self.multi_head_attention = MultiHeadAttention(embedding_dim, head_num) # 多头注意力模块
self.mlp = MLP(embedding_dim, mlp_dim) # MLP模块
self.layer_norm1 = nn.LayerNorm(embedding_dim) # 第一层归一化
self.layer_norm2 = nn.LayerNorm(embedding_dim) # 第二层归一化
self.dropout = nn.Dropout(0.1) # Dropout层
def forward(self, x):
_x = self.multi_head_attention(x) # 通过多头注意力模块
_x = self.dropout(_x) # 应用dropout
x = x + _x # 残差连接
x = self.layer_norm1(x) # 第一层归一化
_x = self.mlp(x) # 通过MLP模块
x = x + _x # 残差连接
x = self.layer_norm2(x) # 第二层归一化
return xTransformer 编码器由多层Transformer块堆叠而成,其中block_num代表的就是堆叠的层数
# 定义Transformer编码器
class TransformerEncoder(nn.Module):
def __init__(self, embedding_dim, head_num, mlp_dim, block_num=12):
super().__init__() # 调用父类构造函数
self.layer_blocks = nn.ModuleList([ # 创建一个模块列表,包含多个编码器块
TransformerEncoderBlock(embedding_dim, head_num, mlp_dim) for _ in range(block_num)
])
def forward(self, x):
for layer_block in self.layer_blocks: # 遍历每个编码器块
x = layer_block(x) # 通过每个块
return xvit的全部模块已经实现,下面就vit整体结构了。
vit的整体结构就是先将输入图片划分patches,然后将patches做embedding。
vit的分类头是一组额外添加的cl-token,将这个class-token复制batches遍,之后就可以将复制后的class_Token拼接到之前的embedding上了。
之后需要把位置编码加到这个embedding上。
这样,输入的图像特征就被处理好了,转换成了输入给Transformer块的形式。
之后只要输入一个Transformer编码器和一个MLP头,就可以得到vit的输出结果。
如果是分类任务,则class_token就是分类结果,如果不是分类任务,比如分割或者vit作为一个模块,那么输出的就是patches形式的特征图。
# 定义ViT模型
class ViT(nn.Module):
def __init__(self, img_dim, in_channels, embedding_dim, head_num, mlp_dim, block_num, patch_dim, classification=True, num_classes=1):
super().__init__() # 调用父类构造函数
self.patch_dim = patch_dim # 定义patch的维度
self.classification = classification # 是否进行分类
self.num_tokens = (img_dim // patch_dim) ** 2 # 计算tokens的数量
self.token_dim = in_channels * (patch_dim ** 2) # 计算每个token的维度
self.projection = nn.Linear(self.token_dim, embedding_dim) # 线性层,用于将patches投影到embedding空间
self.embedding = nn.Parameter(torch.rand(self.num_tokens + 1, embedding_dim)) # 可学习的embedding
self.cls_token = nn.Parameter(torch.randn(1, 1, embedding_dim)) # 类别token
self.dropout = nn.Dropout(0.1) # Dropout层
self.transformer = TransformerEncoder(embedding_dim, head_num, mlp_dim, block_num) # Transformer编码器
if self.classification: # 如果是分类任务
self.mlp_head = nn.Linear(embedding_dim, num_classes) # 分类头
def forward(self, x):
img_patches = rearrange(x, # 将输入图像重塑为patches序列
'b c (patch_x x) (patch_y y) -> b (x y) (patch_x patch_y c)',
patch_x=self.patch_dim, patch_y=self.patch_dim)
batch_size, tokens, _ = img_patches.shape # 获取批次大小、tokens数量和通道数
project = self.projection(img_patches) # 将patches投影到embedding空间
token = repeat(self.cls_token, 'b ... -> (b batch_size) ...', batch_size=batch_size) # 重复cls_token以匹配批次大小
patches = torch.cat((token, project), dim=1) # 将cls_token和投影后的patches拼接
patches += self.embedding[:tokens + 1, :] # 将可学习的embedding添加到patches
x = self.dropout(patches) # 应用dropout
x = self.transformer(x) # 通过Transformer编码器
x = self.mlp_head(x[:, 0, :]) if self.classification else x[:, 1:, :] # 如果是分类任务,使用cls_token的输出;否则,使用patches的输出
return x4,实现解码器的模块
解码器的模块就是卷积模块,接受两个输入:上采样而来的特征图以及skip-connection来的特征图
# 定义解码器中的瓶颈层
class DecoderBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super().__init__() # 初始化父类
self.upsample = nn.Upsample(scale_factor=scale_factor, mode='bilinear', align_corners=True) # 上采样层
self.layer = nn.Sequential( # 解码器层
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x, x_concat=None):
x = self.upsample(x) # 上采样操作
if x_concat is not None: # 如果有额外的特征图进行拼接
x = torch.cat([x_concat, x], dim=1) # 在通道维度上拼接
x = self.layer(x) # 通过解码器层
return x5,组装成模型
所有模块都已经定义完成,下面拿这些模块来组装成模型。
编码器分支由三个卷积模块和一个vit模块组成,输出的x为解码分支最终的特征图,x1,x2,x3分别是三个卷积模块的输出
# 定义编码器
class Encoder(nn.Module):
def __init__(self, img_dim, in_channels, out_channels, head_num, mlp_dim, block_num, patch_dim):
super().__init__() # 初始化父类
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=7, stride=2, padding=3, bias=False) # 第一个卷积层
self.norm1 = nn.BatchNorm2d(out_channels) # 第一个批量归一化层
self.relu = nn.ReLU(inplace=True) # ReLU激活函数
self.encoder1 = EncoderBottleneck(out_channels, out_channels * 2, stride=2) # 第一个编码器瓶颈层
self.encoder2 = EncoderBottleneck(out_channels * 2, out_channels * 4, stride=2) # 第二个编码器瓶颈层
self.encoder3 = EncoderBottleneck(out_channels * 4, out_channels * 8, stride=2) # 第三个编码器瓶颈层
self.vit_img_dim = img_dim // patch_dim # ViT的图像维度
self.vit = ViT(self.vit_img_dim, out_channels * 8, out_channels * 8, # ViT模型
head_num, mlp_dim, block_num, patch_dim=1, classification=False)
self.conv2 = nn.Conv2d(out_channels * 8, 512, kernel_size=3, stride=1, padding=1) # 第四个卷积层
self.norm2 = nn.BatchNorm2d(512) # 第四个批量归一化层
def forward(self, x):
x = self.conv1(x) # 第一个卷积操作
x = self.norm1(x) # 第一个批量归一化
x1 = self.relu(x) # ReLU激活
x2 = self.encoder1(x1) # 第一个编码器瓶颈层
x3 = self.encoder2(x2) # 第二个编码器瓶颈层
x = self.encoder3(x3) # 第三个编码器瓶颈层
x = self.vit(x) # 通过ViT模型
x = rearrange(x, "b (x y) c -> b c x y", x=self.vit_img_dim, y=self.vit_img_dim) # 重塑特征图
x = self.conv2(x) # 第四个卷积操作
x = self.norm2(x) # 第四个批量归一化
x = self.relu(x) # ReLU激活
return x, x1, x2, x3 # 返回多个特征图
解码分支接受编码分支的输出x,以及三个卷积模块的输出x1,x2,x3,
# 定义解码器
class Decoder(nn.Module):
def __init__(self, out_channels, class_num):
super().__init__() # 初始化父类
self.decoder1 = DecoderBottleneck(out_channels * 8, out_channels * 2) # 第一个解码器瓶颈层
self.decoder2 = DecoderBottleneck(out_channels * 4, out_channels) # 第二个解码器瓶颈层
self.decoder3 = DecoderBottleneck(out_channels * 2, int(out_channels * 1 / 2)) # 第三个解码器瓶颈层
self.decoder4 = DecoderBottleneck(int(out_channels * 1 / 2), int(out_channels * 1 / 8)) # 第四个解码器瓶颈层
self.conv1 = nn.Conv2d(int(out_channels * 1 / 8), class_num, kernel_size=1) # 最后一个卷积层,用于输出
def forward(self, x, x1, x2, x3):
x = self.decoder1(x, x3) # 第一个解码器瓶颈层
x = self.decoder2(x, x2) # 第二个解码器瓶颈层
x = self.decoder3(x, x1) # 第三个解码器瓶颈层
x = self.decoder4(x) # 第四个解码器瓶颈层
x = self.conv1(x) # 最后一个卷积层
return x # 返回解码器的输出
整个模型结构:
# 定义TransUNet模型
class TransUNet(nn.Module):
def __init__(self, img_dim, in_channels, out_channels, head_num, mlp_dim, block_num, patch_dim, class_num):
super().__init__() # 初始化父类
self.encoder = Encoder(img_dim, in_channels, out_channels, # 初始化编码器
head_num, mlp_dim, block_num, patch_dim)
self.decoder = Decoder(out_channels, class_num) # 初始化解码器
def forward(self, x):
x, x1, x2, x3 = self.encoder(x) # 编码分支
x = self.decoder(x, x1, x2, x3) # 解码分支
return x # 返回最终输出