目录
消息队列的功能
消息中间件必备
池化思想以及弹性线程池的设计
弹性连接池 [核心参数:初始连接数,最大连接数,最大空闲时间]
弹性线程池 [核心参数:coreThreadCount, maxThreadCount]
引言:为啥要把消息队列,池化技术放在一块进行思考,我觉着它们都利用队列容器来解耦合。都有着类似的思想在其中。也都有着生产者消费者的设计思想和理念在里面。
消息队列的功能
基本作用:用于数据交换。中间层容器。
- 大流量消峰
- 异步解耦
经常听到上述说法。但是这些晦涩专业名词背后的隐含功能是什么?
大流量消峰,那就是过度一下,避其锋芒。先囤起来,然后将其均衡负载给消费者组件,保证系统的可用性,不因为大流量而崩溃无法服务。具体一点,你的服务器,Redis,MySQL各自的承受能力都不一样,直接全部流量照单全收可能会造成服务崩溃。所以缓一缓,排个队。
异步:提高响应速度,快速响应客户。将客户请求封装成消息放入消息队列即可。不用同步等待消息处理即可返回给客户。(非关键路径上的操作可异步)
解耦:利用MQ做中间层,就很像设计模式中的抽象层。可以将生产者组件和消费者组件给分隔开来,不用耦合在一起,使得系统变得简单。分隔开的组件可以单独扩展,而不会造成牵一发而动全身。
其他功能:队列本身的顺序性,来满足消息必须按顺序投递的场景;利用队列 + 定时任务来实现消息的延时消费;



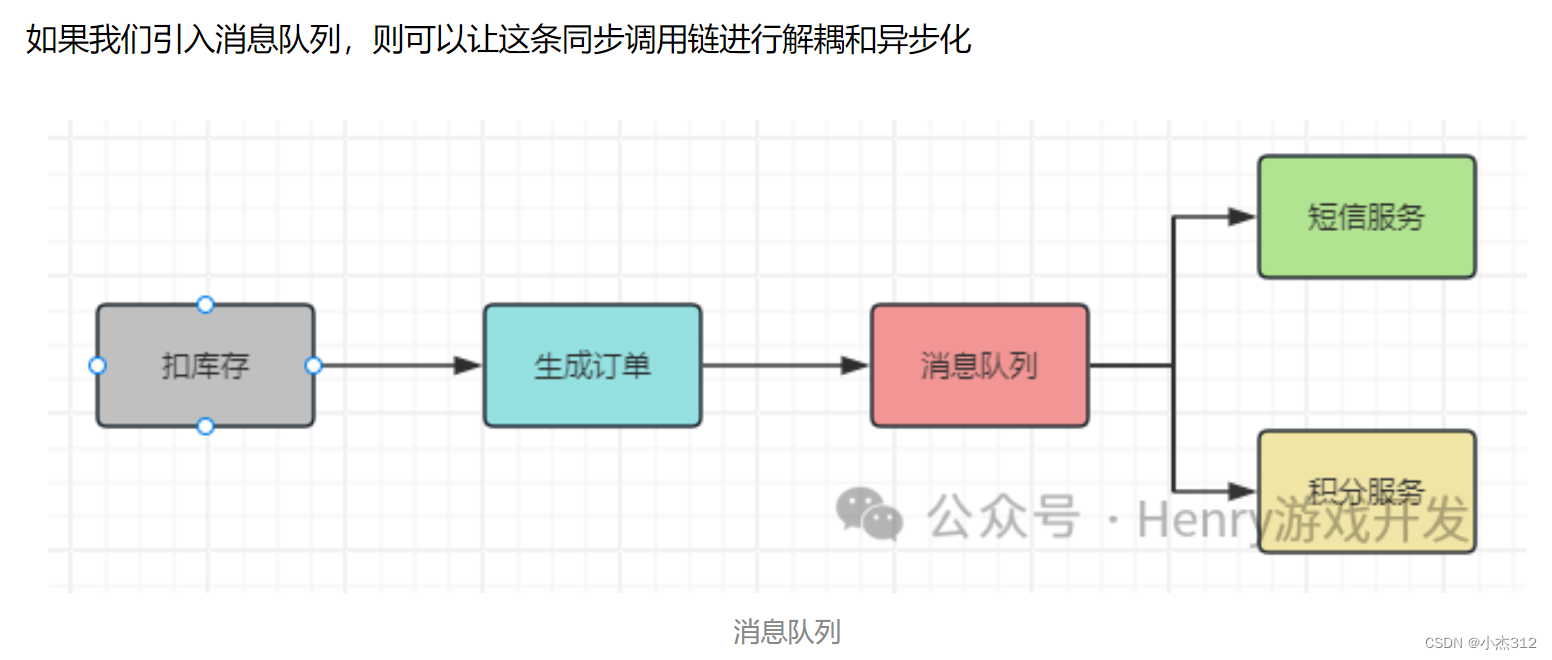

所谓的“削峰填谷”就是指缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡。消息引擎系统的另一大好处在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
消息中间件必备
说白了,消息中间件,或者说消息引擎系统。它相较于简单的消息队列,它功能更多,包括持久化避免消息丢失呀,高可用呀,高可靠呀,可扩展等更多那种分布式系统下的系统特征。
作为消息队列中间件,需要具备以下能力:(为啥会有下面种种的需求?可以思考下的,简单的想一想用了消息中间件之后,生产者消费者都依赖它。它如果挂掉了,肯定是灾难性的。它的下游服务全都没了。所以它必须高可靠、高可用呀。)
-
1. 消息持久化:确保在系统故障时消息不会丢失。
-
2. 高可用性和容错性:通过集群和故障转移机制确保系统的稳定运行。
-
3. 消息确认和可靠传递:保证消息被正确接收和处理。
-
4. 负载均衡:在多个生产者和消费者间有效分配消息。
-
5. 扩展性:支持根据负载增加节点以扩展系统。
所以最好kafka这些不要叫做消息队列,而要叫做 Apache Kafka 是一款开源的消息引擎系统。根据维基百科的定义,消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递
消息引擎系统还要设定具体的传输协议,即我用什么方法把消息传输出去,有点对点和发布订阅两种模式
-
1. 点对点模式:多个生产者向同一个队列发送消息,每个消息只能由一个消费者消费。
-
2. 发布订阅模式:多个发布者向相同的主题发送消息,而订阅者也可能存在多个。每个消息都能被多个订阅者获取和处理。一份消息数据是否可以被多次消费?
-

池化思想以及弹性线程池的设计
池化思想实现:其本质我觉得就是生产者和消费者模式。简化版本的消息中间件。不能用于分布式,没有高可靠、高可用。
生活例子:健身房中有限的跑步机数目,假如说总共也就10台机子。老板平时开个4台用,节约能源。然后呢?客户少的时候,可以直接用现成打开了的机器。人开始多起来了,新来的客户就需要打开新的机器使用。总有个极限,今天生意过于火爆,人太多了,并且都想用跑步机,十台机器全开了。后续的客户咋办呢?只能给人说,客户要不您等待个一定时间,先玩玩别的。时间到了还没有空闲机器,客户心情不悦,我们也只得给客户说声抱歉。
弹性连接池 [核心参数:初始连接数,最大连接数,最大空闲时间]
流程:
- 最开始在初始化的时候就创建好固定数目的初始化连接数。并且设置好初始化连接数,最大连接数,最长空闲时间这三参数。选择用队列容器存储创建的连接。
- 如果 cnt_size < init_size,说明有空闲连接,直接拿来复用。
- 否则 cnt_size >= init_size && cnt_size < max_size,说明没有空闲连接,但是也没超出资源范围,申请创建新的连接,拿来用。
- 若是 cnt_size >= max_size,等一个check_out_time的超时时间(也就是最大空闲时间嘛),如果期间结束还没有空出的连接给等待了超时时间的客户使用,只能抛出错误。说明下资源紧张啥的。
- 另外:不在上述范围顺序,还需要存在一个检测的线程,异步定时检测,如果当前维护的连接数 > init_size && 多余的连接空闲时间超出了 最大空闲时间。这块资源无端占用就可以释放出来,节约系统资源。
这个池化技术的思想大家都懂,就是避免大量的临时创建销毁的时间占用过大,以及充分利用申请的系统资源。
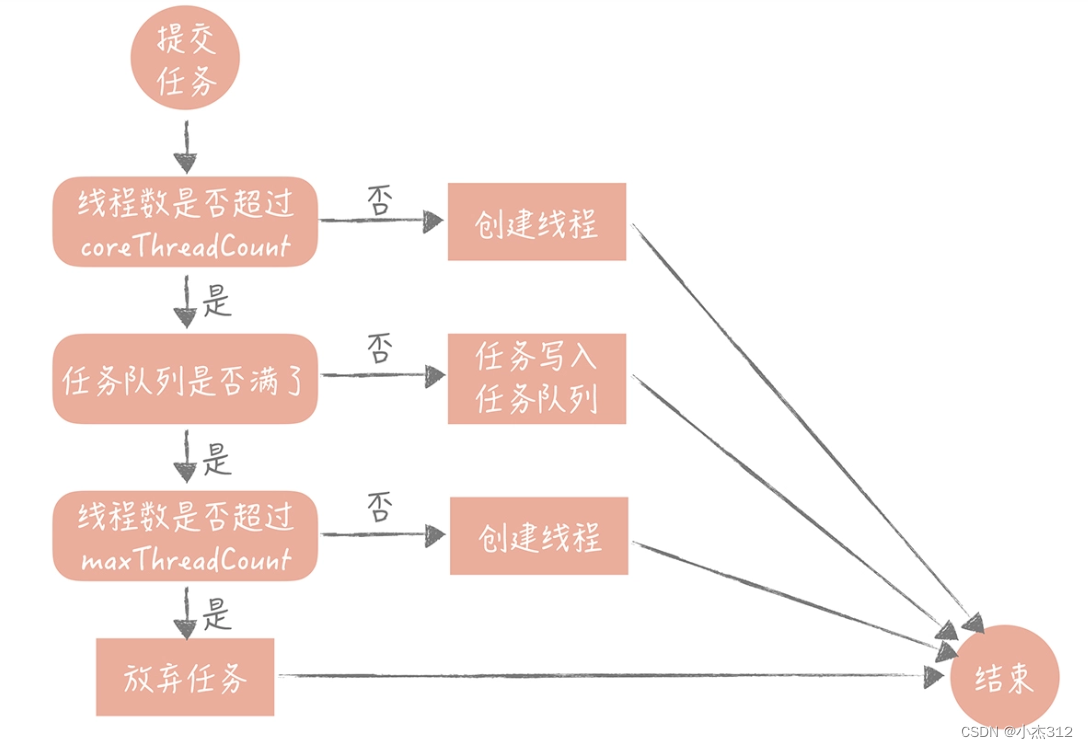
弹性线程池 [核心参数:coreThreadCount, maxThreadCount]
JDK线程池处理流程:
- threadCount < coreThreadCount 时候,如果有空闲线程,直接拿来用,否则创建新的线程拿来用。
- threadCount >= coreThreadCount && threadCount < maxThreadCount 时候,将企图将任务放入任务队列,等待空闲线程处理
- 如果任务队列满了。才继续创建新的线程来处理任务。
- threadCount > maxThreadCount,并且任务队列满了的话,只能返回错误,任务队列没满则放入任务队列等待处理。
CPU密集型 VS IO密集型的选择
上述的JDK线程池的实现就适合CPU密集型。为什么这么说,它尽量的在避免创建过多的线程导致大量的线程间切换的代价。线程达到核心线程数之后,任务来了先尝试往任务队列中放,而不是直接创建新的线程处理。
线程数过多的代价是什么?跨CPU处理器和跨CPU处理器内部的核心。大量缓存失效,大量上下文切换,多处理器通信的代价。
CPU密集型和IO密集型的线程数设计(单CPU处理器架构下)
业内一般支持,CPU密集型下,将线程数设计在CPU核心数左右。
IO密集型,将线程数设计在CPU核心数的2倍左右。 (大量的线程可能在阻塞等待IO,多创建一些线程来充分利用好CPU的多核架构)