一、论文信息
1 标题
Diffusion models in text generation: a survey
2 作者
Qiuhua Yi, Xiangfan Chen, Chenwei Zhang, Zehai Zhou, Linan Zhu, Xiangjie Kong
3 研究机构
1 College of Computer Science and Technology, Zhejiang University of Technology, HangZhou, China
2 School of Faculty of Education, University of Hong Kong, Hong Kong, China
二、主要内容
这篇论文是一项关于扩散模型在文本生成领域应用的综合调查研究。论文首先介绍了扩散模型的背景和发展,然后详细探讨了扩散模型在条件文本生成、无约束文本生成和多模态文本生成三个部分的应用。此外,论文还对扩散模型和基于自回归的预训练模型(PLMs)进行了多维度的详细比较,突出了它们各自的优势和局限性。论文认为将PLMs集成到扩散模型中是一个有价值的研究方向,并讨论了扩散模型在文本生成中面临的当前挑战,提出了潜在的未来研究方向,例如提高采样速度以解决可扩展性问题和探索多模态文本生成。
在论文的引言部分,作者详细介绍了扩散模型的发展历程,从最初的概念提出到在图像生成领域的应用,再到自然语言处理(NLP)领域的探索。以下是扩散模型发展的主要阶段:
-
起源(2015年):扩散模型的概念最早可以追溯到2015年,当时Sohl-Dickstein等人提出了扩散概率模型(DPM)。然而,在接下来的几年中,这些模型并没有得到广泛的开发和应用。
-
图像生成领域的突破(2020年):Google的研究者在2020年对模型的细节进行了改进,引入了去噪扩散概率模型(DDPM),并将它们应用于图像生成领域,逐渐将扩散模型引入了研究者的视野。
-
进一步的改进(2020年后):在DDPM之后,去噪扩散隐式模型(DDIM)进一步改进了DDPM的去噪过程,为后续的扩散模型奠定了基础。
-
在NLP领域的应用:扩散模型在图像和音频生成领域取得成功后,研究者开始探索将其应用于NLP领域。由于文本数据的离散性与图像数据的连续性不同,研究者提出了两种主要方法来解决这一挑战:一种是通过嵌入层将离散文本映射到连续表示空间;另一种是保留文本的离散性,并将扩散模型推广到处理离散数据。
-
文本生成的进展:在过去两年中,扩散模型在文本生成任务中取得了显著的成果。例如,通过条件图像生成方法,Palette展示了扩散模型在图像到图像翻译中的巨大潜力。此外,GLIDE、DALL·E 2和Imagen等模型在文本到图像生成领域取得了新的最先进结果。
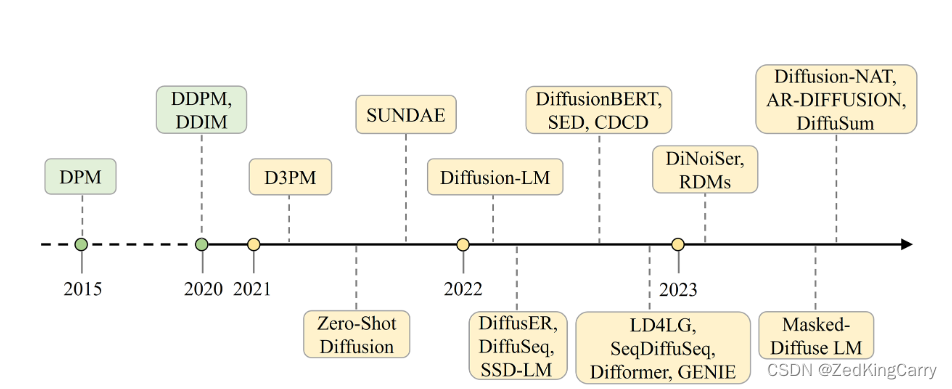
引言部分强调了扩散模型在生成连续空间内容(特别是图像和音频)方面的成功,并探讨了如何将这些模型适应于文本生成任务,指出了在NLP领域应用扩散模型所面临的挑战和取得的进展。
三、相关研究
论文提到了多种深度学习生成模型,包括变分自编码器(VAE)、生成对抗网络(GANs)、基于流的生成模型和扩散模型。特别指出,扩散模型在图像和音频生成领域取得了巨大成功,并且已经开始应用于自然语言处理(NLP)领域。
文本生成任务的细分子任务:
模式下,论文详细介绍了多种扩散模型及其在文本生成任务中的应用。以下是这些模型的详细介绍及其内容:
文本驱动的生成
-
DiffuSeq:这是一个开创性的模型,它将扩散模型应用于序列到序列(SEQ2SEQ)文本生成任务。DiffuSeq 引入了部分噪声的概念,即有选择地对目标序列施加高斯噪声,同时保留源句子嵌入的完整性。这种方法允许对目标文本进行受控的破坏,从而增强生成过程。
-
DiffuSum:DiffuSum 扩展了条件扩散模型的应用,特别是在文本摘要任务中。与 DiffuSeq 类似,DiffuSum 也使用部分噪声,但它进一步加入了匹配损失和多类别对比损失等组件,以提高生成文本的质量和相关性。
-
DiffusER:DiffusER 与传统扩散模型不同,它将文本编辑操作(如插入、删除和编辑)视为噪声的形式。这种方法充分考虑了文本的离散特性,使得生成的文本更加灵活和多样化。
-
SeqDiffuSeq:这是一个基于编码器-解码器Transformer架构的模型,它结合了自适应噪声计划和自条件技术,显著提高了文本生成的质量和速度。自适应噪声计划允许模型根据生成过程中的需要调整噪声水平,而自条件技术则使得模型能够在生成过程中利用先前生成的文本作为条件。
-
Zero-Shot Diffusion:这个模型首次将扩散模型应用于条件文本生成任务。它受到编码器-解码器架构的启发,将源语言句子作为条件输入到Transformer编码器中,并将带噪声的目标语言句子输入到解码器中。
-
GENIE:GENIE 是一个大规模预训练的扩散语言模型,它使用掩蔽源序列作为编码器的输入,并结合了连续段落去噪训练方法。GENIE 展示了在生成高质量和多样性文本方面的有效性,为各种自然语言处理任务开辟了新的可能性。
-
RDMs (Reparameterized Diffusion Models):RDMs 引入了重参数化和随机路由机制,简化了训练过程,并提供了灵活的采样方法。然而,目前 RDMs 只能生成固定长度的句子。
-
Diffusion-NAT:Diffusion-NAT 将离散扩散模型(DDM)和 BART 结合起来,用于非自回归文本生成。它将推理和去噪过程统一为一个掩蔽标记恢复任务,专注于条件文本生成任务。
-
CDCD (Continuous Denoising Diffusion):CDCD 通过引入得分插值和时间扭曲技术,改进了扩散模型的训练过程,在语言建模和机器翻译任务中取得了优异的性能。
-
DiNoiSer:DiNoiSer 认为,仅仅通过嵌入将离散标记映射到连续空间并不足以消除文本的离散性质。因此,DiNoiSer 使用自适应噪声水平和放大噪声规模来进行反离散训练,利用源条件来提高多个条件文本生成任务的性能。
-
Difformer:Difformer 是一个基于 Transformer 架构的去噪扩散模型,它通过引入锚定损失函数、嵌入层的层归一化模块以及高斯噪声的噪声因子,解决了连续嵌入空间中扩散模型的挑战。
-
AR-DIFFUSION:AR-Diffusion提出了一个多级扩散策略和动态移动速度,能够即使在很少的解码步骤下也展现出强大的性能,它提供了一种新的视角,将传统的自回归方法与扩散模型的优势结合起来。
这些模型展示了扩散模型在条件文本生成任务中的多样性和潜力,它们通过不同的方法和技术创新地解决了生成过程中的挑战,提高了生成文本的质量和多样性。
细粒度可控文本生成
细粒度控制生成(Fine-grained control generation)是一种文本生成方法,它接受细粒度的控制条件(如情感、主题、风格等)作为输入,并且引入了一个条件变量 ( c ),用来表示控制属性:
-
Diffusion-LM:是一个基于连续扩散的可控语言模型,它已经被成功应用于六种细粒度控制生成任务。Diffusion-LM 在处理各种控制文本生成任务时,尽管在困惑度、解码速度和收敛速度方面还有优化和改进的空间,但它展示了扩散模型在提高文本生成任务中的可控性方面的潜力。
-
Masked-Diffuse LM:这个模型受到语言学特征的启发,提出了在前向过程中应用策略性软遮蔽来破坏文本,并通过对直接文本预测进行迭代去噪的方法。与 Diffusion-LM 相比,这个模型通过五项可控文本生成任务展示了更低的训练成本和更好的性能。
-
Latent Diffusion Energy-Based Model (LDEBM):这个模型结合了扩散模型和潜在空间能量模型,使用扩散恢复似然学习来解决采样质量和不稳定性问题。在多个具有挑战性的任务中,如条件响应生成和情感可控生成,LDEBM 展示了卓越的解释性文本建模性能。
这些方案展示了细粒度控制生成的多样性和灵活性,允许模型根据特定的控制条件生成具有特定属性的文本。这种方法为生成具有特定情感色彩、主题或风格的文本提供了新的可能性,并且在自然语言处理的多个领域中都有着广泛的应用前景。
无约束文本生成
无约束文本生成(Unconstrained text generation)是指模型基于训练语料库生成文本,而不依赖于特定的主题或长度限制。以下是论文中提到的无约束文本生成方法的介绍:
-
D3PM (Discrete Denoising Diffusion Models):
- D3PM 开发了一种结构化的分类腐败过程,通过使用标记之间的相似性来实现渐进式腐败和去噪。
- 该模型通过插入 (MASK) 标记来与自回归和基于掩蔽的生成模型建立联系,实现了在字符级文本生成上的强结果,并扩展到大型词汇表(如 LM1B)。
-
DiffusionBERT:
- DiffusionBERT 创造性地提出使用 BERT 作为其骨干来执行文本生成,结合了预训练模型(PLMs)与离散文本的离散扩散模型。
- 该模型针对无条件文本生成问题,特别是在非自回归模型中,展示了在困惑度和 BLEU 分数上的显著改进。
这两种方法展示了扩散模型在无约束文本生成任务中的应用,它们通过不同的技术手段来生成流畅、连贯且有意义的文本,同时也提供了对生成结果多样性的探索。这些模型的提出和应用,为未来的文本生成研究提供了新的方向,尤其是在提高生成质量和多样性方面。
多模态文本生成
多模态文本生成(Multi-mode text generation)是指能够同时处理多种文本生成任务的扩散模型,这些任务可能包括条件文本生成、无约束文本生成,以及其他可能的文本生成模式。以下是论文中提到的多模态文本生成模型的介绍:
-
Self-conditioned Embedding Diffusion (SED):
- SED 提出了一种名为自条件嵌入的连续扩散机制,这种机制学习了一个灵活且可扩展的扩散模型,适用于条件和无条件文本生成。
- 该模型支持文本填充,为探索嵌入空间设计和填充能力奠定了基础。
-
Step-unrolled Denoising Autoencoder (SUNDAE):
- SUNDAE 引入了基于自编码器的展开去噪训练机制,与常规去噪方法相比,它需要更少的迭代次数来收敛。
- 该模型在机器翻译和无条件文本生成任务中表现出良好的性能,并且打破了自回归的限制,可以填补模板中的任意空白模式,为文本编辑和文本修复开辟了新的途径。
-
Latent Diffusion for Language Generation (LD4LG):
- LD4LG 与其他将离散文本通过嵌入转换为连续空间的工作不同,它学习了在预训练语言模型的潜在空间上进行扩散的过程。
- 该框架从无条件文本生成扩展到了条件文本生成,提供了一种新的方法来处理文本生成任务。
-
Semi-autoregressive Simplex-based Diffusion Language Model (SSD-LM):
- SSD-LM 是一种半自回归的扩散语言模型,它在自然词汇空间上执行扩散,通过设计特征实现了灵活的输出长度和模块化控制。
- 在无约束和控制文本生成任务上,SSD-LM 在质量和多样性方面优于自回归基线模型。
这些多模态文本生成模型展示了扩散模型在处理多种文本生成任务方面的潜力和灵活性。它们通过结合不同的生成策略和技术,为生成多样化和高质量的文本提供了新的可能性,并为未来的文本生成研究提供了新的视角和方向。
五、文本扩散模型与预训练语言模型的对比
文本扩散模型和预训练语言模型(PLMs)是两种不同的文本生成方法,它们在多个维度上有着各自的特点和优势。以下是论文中对这两种模型进行的对比:
生成方法
- PLMs:通常采用自回归方法进行文本生成,通过时间序列预测技术,基于先前内容预测下一个可能的词。
- 扩散模型:在NLP中的生成方法与传统自回归方法不同,它们首先通过不断添加噪声(通常是高斯噪声)来获得一个完全不可见的噪声分布,然后通过迭代去噪产生词向量。
处理离散文本
- PLMs:由于文本的离散特性,将单词放入NLP模型中需要特殊处理,主要包括独热编码、分布式表示、词袋表示和词嵌入表示。
- 扩散模型:离散文本扩散模型在处理离散扩散模型时,会将不同标记映射到转换矩阵,而连续文本扩散模型则通过嵌入技术将离散文本编码到连续向量空间。
时间复杂度
- PLMs:预训练语言模型的时间复杂度与模型层数、隐藏层维度、注意力头数和训练数据大小等因素有关。
- 扩散模型:扩散模型的时间复杂度通常与采样步数和模型复杂度有关,可能需要多个迭代来从噪声中恢复文本。
生成结果的多样性
- PLMs:由于倾向于选择概率高的词,可能产生相对保守和相似的生成结果。
- 扩散模型:通过引入更多的随机性,生成的文本倾向于展示多样性。
生成方向
- PLMs:自回归模型按照从左到右、逐词的模式生成文本。
- 扩散模型:生成过程从一个原始句子开始,通过添加噪声和迭代去噪来生成句子,这种方法引入了固有的随机性,增强了生成结果的多样性。
总的来说,PLMs和扩散模型在文本生成领域都有其独特的优势和局限性。PLMs在生成质量和生成速度方面表现出色,而扩散模型则在生成多样性方面具有显著优势。根据具体的应用场景和任务需求,可以选择合适的模型来达到最佳的生成效果。
六、进一步探索点:
论文中提出了几个关于扩散模型在文本生成领域的未来研究方向,这些方向为研究者提供了进一步探索的可能性。以下是这些潜在的探索点:
-
零样本任务(Zero-shot tasks):
- 扩散模型作为一种基于概率推断的生成模型,可以在零样本问题上利用训练阶段学到的数据分布特征和先验知识来生成新样本。
- 在NLP领域,可以探索使用扩散模型进行零样本翻译问题,以及在控制生成中满足特定条件的能力。
-
多模态扩散模型(Multimodal diffusion models):
- 构建统一的多模态扩散模型,探索不同模态之间的互补性和相关性,以获得更准确和全面的信息。
- 扩散模型已经能够处理来自不同模态(文本、图像、音频等)的数据,未来的研究可以集中在如何更好地整合这些模态,以提高任务性能,如情感分析、视觉问答和图像描述。
-
与预训练语言模型的结合(Combination with PLMs):
- 探索更高效的将扩散模型与预训练模型结合的方法,例如利用上下文学习、提示学习等技术。
- 结合预训练模型的语言建模能力和扩散模型的生成多样性,可能会产生新的文本生成范式。
-
加速采样过程(Speeding up sampling):
- 设计专门的采样策略或借鉴计算机视觉领域成功的采样策略,以提高扩散模型的采样效率。
- 提高采样速度可以减少生成文本所需的时间,使模型更适合实时或高性能要求的应用场景。
-
设计嵌入空间(Designing embedding space):
- 探索更好的嵌入空间设计策略,以确保原始数据得到适当的表示,避免损失函数崩溃。
- 嵌入空间的学习对于模型性能至关重要,需要研究如何更好地指导嵌入空间的学习过程。
除了上述探索点,我认为扩散模型在文本生成上还有以下探索空间:
- 模型可解释性:提高扩散模型的可解释性,使其生成过程更加透明,用户能够理解模型的决策过程。
- 控制生成质量:研究如何在保持生成多样性的同时,提高生成文本的准确性和一致性。
- 跨语言和跨文化适应性:探索扩散模型在不同语言和文化背景下的适应性和生成能力。
- 长期依赖问题:解决在长文本生成中保持长期依赖关系的问题,确保文本的连贯性和逻辑性。
- 实时交互应用:针对实时交互式应用(如聊天机器人),优化扩散模型以满足低延迟和高响应性的需求。
扩散模型在文本生成上的研究仍处于相对早期阶段,未来有很多机会可以进一步探索和发展。随着技术的进步和新算法的提出,扩散模型有望在多种文本生成任务中发挥更大的作用。
七、总结
这篇论文提供了一个关于扩散模型在文本生成任务中应用的全面概述,总结了最新的研究进展,并从新颖的文本生成任务分类角度对研究进行了分类和总结。论文还从多个角度区分了扩散模型和预训练语言模型,并详细阐述了现有挑战和预期的未来研究方向,为相关领域的研究人员提供了有价值的见解。






![[c++] std::future, std::promise, std::packaged_task, std::async](https://img-blog.csdnimg.cn/direct/ba54893777d441d6ba426e125764dba9.png)