文章目录
- 前期准备
- 1. 浏览器开启远程控制指令
- (1)Edge
- (2)Chrome
- 2. 执行python代码
- (1)先启动浏览器后执行代码
- (2)通过代码启动浏览器
- (3)Bug问题记录
- 1)python可读取浏览器所有标签标题,但检索网页元素失败
- 2)浏览器开启程序,但python程序无法链接浏览器进行自动控制
- 3. 爬取效果
- 3. 完整代码共享
- 3.1 包含Excel部分的完整代码
- 3.2 爬虫部分的完整代码
说明:本记录是在Windows系统上执行的!
起因是:博导要求统计一下国内某个领域的专家情况,统计主持国家自然科学基金的副教授和教授都有哪些大牛!
于是:本人去[NSFC]:https://kd.nsfc.cn/ 下载全部的历史基金项目书。。。。工作量太大就……半自动化实现吧!!!
前期准备
1. python Selenium库
2. Edge浏览器 或 Chrome浏览器
1. 浏览器开启远程控制指令
- 无论是哪种浏览器,都需要使用终端独立运行浏览器的远程调试模式。
- 开启方式:加入指令(–remote-debugging-port=9222 --user-data-dir=“D:\selenium\AutomationProfile”)
需要进入目标浏览器的根目录! 不然就输入全路径!
(1)Edge
.\msedge.exe --remote-debugging-port=9222 --user-data-dir=“D:\selenium\AutomationProfile”
(2)Chrome
.\chrome.exe --remote-debugging-port=9222 --user-data-dir=“D:\selenium\AutomationProfile”

2. 执行python代码
(1)先启动浏览器后执行代码
-
必须是先执行上述步骤,开启了浏览器的远程调试端口后,才能通过下方代码进行控制。
-
add_experimental_option("debuggerAddress", "127.0.0.1:9222")这句话是关键!
from selenium import webdriver
from selenium.webdriver.edge.options import Options
class Test:
def edge(self):
edge_driver_path = executable_path=r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
chrome_options = Options()
# chrome_options.binary_location = edge_driver_path # 传入驱动地址
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # "127.0.0.1:9222"其中,9222是浏览器的运行端口
# 让浏览器带着这个配置运行
# chrome_options.add_experimental_option('detach', True) # 通过option参数,设置浏览器不关闭
driver = webdriver.Edge(options=chrome_options, keep_alive=True)
driver.implicitly_wait(10) # 页面元素查找的等待时间
self.driver = driver
pass
def chrome_drive(self, drive='chrome'):
edge_driver_path = executable_path = r'D:\Program Files\Google\Chrome\Application'
if drive == 'chrome':
chrome_options = webdriver.ChromeOptions()
# chrome_options.binary_location = edge_driver_path # 传入驱动地址
# chrome_options.add_experimental_option('detach', True) # 通过option参数,设置浏览器不关闭
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=chrome_options, keep_alive=False)
driver.implicitly_wait(10) # 页面元素查找的等待时间
self.driver = driver
pass
(2)通过代码启动浏览器
- 这个时候被注释掉的
.binary_location = edge_driver_path是关键! - 这种情况下,需要下载对应的驱动软件(.exe)
- 博主在笔记本电脑上首次尝试Selenium时就下载了驱动软件!但后来在台式电脑使用相同代码时发现,压根不需要下载什么驱动软件!
- 只需要使用终端提前启动浏览器的调试模型即可。 (这是弯路、坑)
- 因为,如果是通过代码启动浏览器的调试模型,需要配置路径,然后保证程序关闭后浏览器依旧运行!麻烦!!!
(3)Bug问题记录
1)python可读取浏览器所有标签标题,但检索网页元素失败
- 部分网页不支持爬取!特别是当网页开启F12的开发人选项后,会出现无法查找元素的问题。
- 此时,关闭 “开发人选项” 即可。
2)浏览器开启程序,但python程序无法链接浏览器进行自动控制
- 关闭原有浏览器,重新打开浏览器(需搭配命令:–remote-debugging-port=9222 --user-data-dir=“xxx folder”
3. 爬取效果
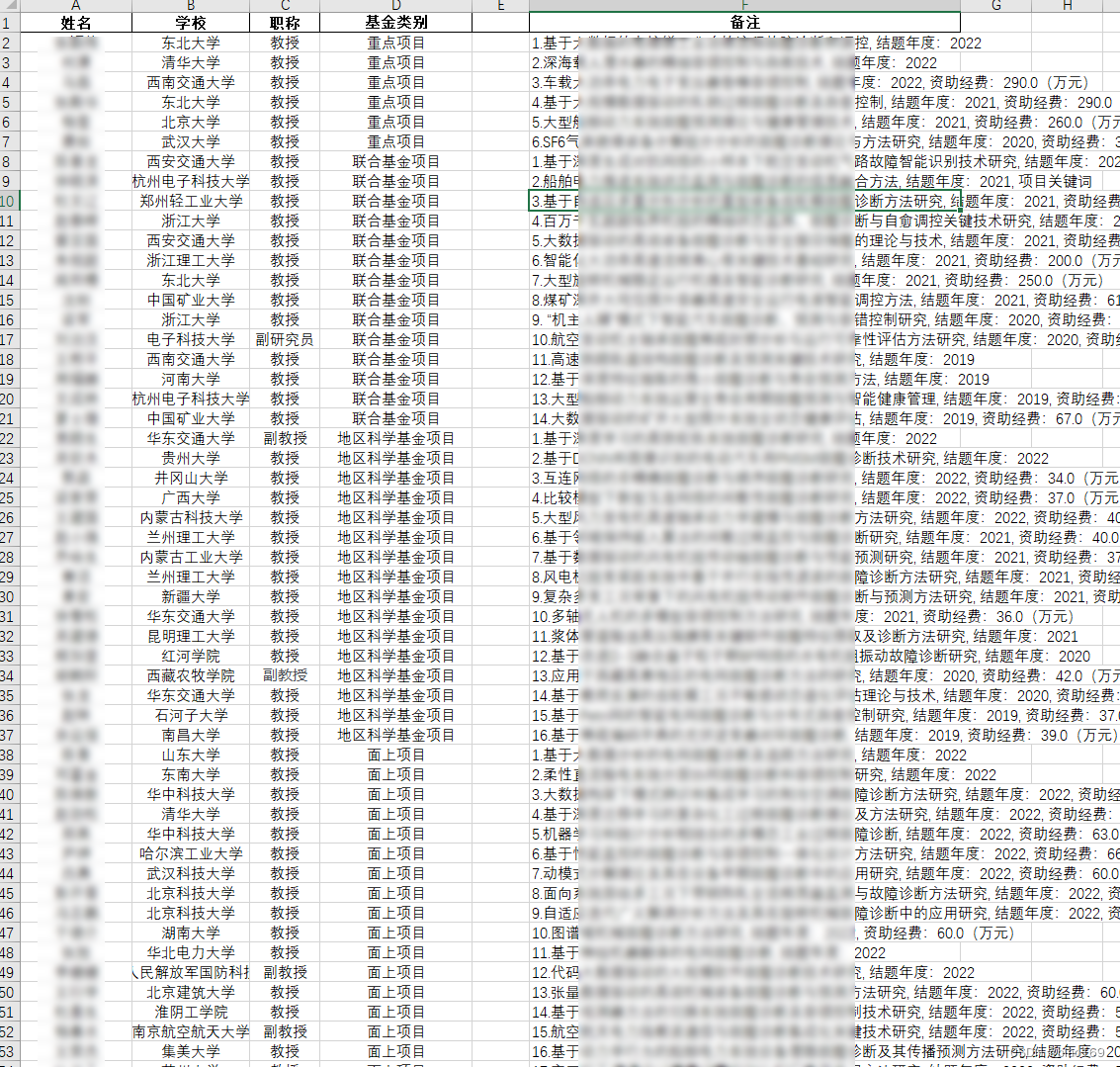
3. 完整代码共享
以下代码主要实现了:
- 浏览器标签页的翻动和选择
- 爬取 – 青塔网检索”国家自然科学基金项目“的作者信息,并保存到表格。
- 爬取 – NSFC”国家自然科学基金项目“的作者信息,并保存到表格。
- 爬取 – 国际某个领域专家的作者信息,并保存到表格。
3.1 包含Excel部分的完整代码
包含Excel部分的完整代码见:资源文件
3.2 爬虫部分的完整代码
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.action_chains import ActionChains
# '.\chrome.exe --remote-debugging-port=9222 --user-data-dir=“D:\selenium\AutomationProfile” n "*" --ws --allow-insecure-unlock --nodiscover --authrpc.addr 127.0.1.2 --authrpc.port 8545'
# '.\chrome.exe --remote-debugging-port=9222 --user-data-dir=“D:\selenium\AutomationProfile”'
class Web_Browser:
def __init__(self, drive='chrome'):
self.driver = None
# self.edge()
self.chrome_drive()
def edge(self):
# edge_driver_path = executable_path=r'D:\Program Files\Google\Chrome\Application\chromedriver.exe'
edge_driver_path = executable_path=r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
chrome_options = Options()
# chrome_options.binary_location = edge_driver_path
# 配置浏览器
# 添加User-Agent到Chrome选项中
# chrome_options.add_argument("--user-agent=windows 10 Edge")
# "127.0.0.1:9222"其中,9222是浏览器的运行端口
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
# 让浏览器带着这个配置运行
# chrome_options.add_experimental_option('detach', True) # 通过option参数,设置浏览器不关闭
driver = webdriver.Edge(options=chrome_options, keep_alive=True)
# driver = webdriver.Chrome( options=chrome_options)
print('===================')
# driver.get('www.baidu.com')
driver.implicitly_wait(10)
self.driver = driver
def chrome_drive(self, drive='chrome'):
edge_driver_path = executable_path = r'D:\Program Files\Google\Chrome\Application\chromedriver.exe'
if drive == 'chrome':
chrome_options = webdriver.ChromeOptions()
# chrome_options.binary_location = edge_driver_path
# chrome_options.add_experimental_option('detach', True) # 通过option参数,设置浏览器不关闭
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=chrome_options, keep_alive=False)
self.driver = driver
driver.implicitly_wait(10)
self.opened_windows_dict = None
pass
def get_all_opened_windows(self):
driver = self.driver
cw = driver.current_window_handle
res = {}
# 获取已打开的标签页的信息
tabs = driver.window_handles
for t in tabs:
driver.switch_to.window(t)
res[str(driver.title)] = str(t)
self.opened_windows_dict = res
driver.switch_to.window(cw)
print('已打开的标签页的信息:',)
for k in res: print(f"\t{k}: {res[k]}")
return res
def switch_window(self, key):
driver = self.driver
cw = driver.current_window_handle
# 获取已打开的标签页的信息
tabs = driver.window_handles
for t in tabs:
driver.switch_to.window(t)
if key in str(driver.title): cw = t
break
# driver.switch_to.window(cw)
self.driver = driver
pass
def open_new_window(self, driver=None, url=None, delay_t=0.6):
'''# 打开新标签页'''
driver = self.driver if not driver else driver
old_handle = driver.window_handles # 获取已打开的标签页的信息
# driver.find_element("body").send_keys(Keys.CONTROL + 't') # 没有实体会报错
# driver.execute_script("window.open('','_blank');") # 可能被拦截
driver.switch_to.new_window('tab')
time.sleep(delay_t)
if len(driver.window_handles) >len(old_handle): return True
driver.execute_script(f"window.open('{url if url else ''}');")
time.sleep(delay_t)
if len(driver.window_handles) >len(old_handle): return True
return False
def func1(self, xlsx):
""" 学术网 """
for p in range(50):
# self.switch_window('故障诊断')
driver = self.driver
web = driver.find_element(by=By.XPATH, value='//*[@id="search_body"]/div[2]/div[3]/div[1]/div[2]/div[1]/div[3]/div[2]/div/div[2]/div[2]/div/div')
web1 = web.find_elements(by=By.CLASS_NAME, value='inner-content')
print('web1 len=', len(web1))
num = 0
for i, w in enumerate(web1):
try:
# '//*[@id="search_body"]/div[2]/div[3]/div[1]/div[2]/div[1]/div[3]/div[2]/div/div[2]/div[2]/div/div'
#
a = w.find_element(by=By.XPATH, value=f'//div[{1+i}]/div/div[2]/div[1]/div[1]/div/a/strong/span/span').text
try:
b = w.find_element(by=By.XPATH, value=f'//div[{1 + i}]/div/div[2]/div[3]/p[2]').text
school = str(b).split(',')
for s in school:
if 'university' in s.lower(): b = s[1:]
except: b = None
c = w.find_element(by=By.XPATH, value=f'//div[{1 + i}]/div/div[2]/div[3]/p[1]').text
d = None
e = None
f = None
try:
h_index = w.find_element(by=By.XPATH, value=f'//div[{1 + i}]/div/div[2]/div[2]/div/span[1]/span[3]').text
paper = w.find_element(by=By.XPATH, value=f'//div[{1 + i}]/div/div[2]/div[2]/div/span[2]/span[3]').text
cite = w.find_element(by=By.XPATH, value=f'//div[{1 + i}]/div/div[2]/div[2]/div/span[3]/span[3]').text
f = f"H-index: {h_index}, papers: {paper}, cites: {cite}"
except: pass
g = None
h = w.find_element(by=By.XPATH, value=f'//div[{1 + i}]/div/div[2]/div[1]/div[1]/div/a')
h = 'https://www.aminer.cn/' + h.get_attribute('href')
print(a, b ,c, g)
xlsx.input_data(a,b,c,d,e,f,g, h)
num += 1
except: pass
print('记录:', num)
# aa = driver.find_elements(by=By.XPATH, value='//*[@id="search_body"]/div[2]/div[3]/div[1]/div[2]/div[1]/div[3]/div[2]/div/div[2]/div[3]/ul/li')
# aa = aa[-1]
aa = driver.find_element(by=By.CLASS_NAME, value='ant-pagination-next')
# v = '#search_body > div.ant-tabs.ant-tabs-top.a-aminer-core-search-index-searchPageTab.ant-tabs-line.ant-tabs-no-animation > div.ant-tabs-content.ant-tabs-content-no-animated.ant-tabs-top-content > div.ant-tabs-tabpane.ant-tabs-tabpane-active > div.a-aminer-core-search-index-componentContent > div.a-aminer-core-search-c-search-component-temp-searchComponent > div.view > div:nth-child(2) > div > div:nth-child(2) > div.paginationWrap > ul > li.ant-pagination-next'
# aa = driver.find_element(by=By.CSS_SELECTOR, value=v)
# 创建一个ActionChains对象,用于执行鼠标动作
action_chains = ActionChains(driver)
# 将鼠标移动到链接元素上并点击
action_chains.move_to_element(aa).click().perform()
print(f'第{p+1}页 --> 第{p+2}页')
try:
xlsx.make_frame()
xlsx.save_excel()
except: pass
time.sleep(5)
pass
def func2(self, xlsx=None):
for p in range(50):
self.switch_window('青塔')
driver = self.driver
web = driver.find_element(by=By.XPATH,
value='//*[@id="app"]/div[2]/div[1]/div/div[2]/div[2]/div/div[2]')
web1 = web.find_elements(by=By.CLASS_NAME, value='list-item')
print('web1 len=', len(web1))
num = 0
for i, w in enumerate(web1):
# try:
# //*[@id="app"]/div[2]/div[1]/div/div[2]/div[2]/div/div[2]
# '//*[@id="app"]/div[2]/div[1]/div/div[2]/div[2]/div/div[2]/div/div[2]/div[2]/div[2]/div[1]/div[2]'
# //*[@id="app"]/div[2]/div[1]/div/div[2]/div[2]/div/div[2]/div/div[1]/div[2]/div[2]/div[1]/div[1]
b = w.find_element(by=By.XPATH, value=f'//div[2]/div[1]/div[1]/div[2]')
print(b)
b = b.text
print('b=', b)
a = w.find_element(by=By.XPATH, value=f'//div[2]/div[2]/div[1]/div[2]').text
print('a=', a)
c = None
d = None
e = w.find_element(by=By.XPATH, value=f'//div[1]/div[1]').text
print('e=', e)
year = w.find_element(by=By.XPATH, value=f'//div[2]/div[2]/div[2]/div[2]').text
money = w.find_element(by=By.XPATH, value=f'//div[2]/div[1]/div[2]/div[2]').text
print('year=', year, 'money=', money)
e = f"{e}, 立项: {year}, 资助: {money}"
jijin = w.find_element(by=By.XPATH, value=f'//div[2]/div[3]/div[1]/div[2]').text
domain = w.find_element(by=By.XPATH, value=f'//div[2]/div[3]/div[2]/div[2]').text
print('jijin=',jijin, 'domain=', domain)
f = f"{jijin}, 领域: {domain}"
g = None
h = None
print(i, '-----------', i)
print(a, b, c, d, e, f)
xlsx.input_data(a, b, c, d, e, f, g, h)
num += 1
break
# except: pass
print('记录:', num)
break
aa = driver.find_element(by=By.XPATH, value=f'//*[@id="app"]/div[2]/div[1]/div/div[2]/div[2]/div/div[3]/button[2]')
# 创建一个ActionChains对象,用于执行鼠标动作
action_chains = ActionChains(driver)
# 将鼠标移动到链接元素上并点击
action_chains.move_to_element(aa).click().perform()
print(f'第{p + 1}页 --> 第{p + 2}页')
try:
xlsx.make_frame()
xlsx.save_excel()
except:
pass
time.sleep(5)
pass
def func3(self, xlsx=None):
for p in range(50):
self.switch_window('大数据知识管理服务门户')
driver = self.driver
d = driver.find_element(by=By.CLASS_NAME, value='container_list_right')
print('d==', d)
# web = driver.find_element(by=By.XPATH,
# value='//*[@id="app"]/div[1]/div[3]/div/div[3]/div[1]/div')
web = d.find_element(by=By.XPATH, value='//div[1]/div')
# web1 = web.find_elements(by=By.CLASS_NAME, value='list-item')
# print('web1 len=', len(web1))
num = 0
for i, w2 in enumerate(range(6)):
w = web
try:
# //*[@id="app"]/div[1]/div[3]/div/div[3]/div[1]/div
# //*[@id="app"]/div[1]/div[3]/div/div[3]
# //*[@id="app"]/div[1]/div[3]/div/div[3]/div[1]/div/div[2]/div[2]/div[1]
b = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[3]/div[4]/a')
b = b.text
# print('b=', b)
a = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[2]/div[4]/a').text
# print('a=', a)
c = None
d = None
e = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[1]/div[1]/p/a').text
# print('e=', e)
year = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[3]/div[3]').text
money = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[3]/div[1]').text
# print('year=', year, 'money=', money)
e = f"{e}, {year}, {money}"
jijin = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[2]/div[3]').text
domain = w.find_element(by=By.XPATH, value=f'//div[{i+1}]/div[2]/div[1]').text
# print('jijin=',jijin, domain)
f = f"{jijin}, {domain}"
g = None
h = None
print(i+1, '-----------', i+1)
print(a, b, c, d, e, f)
xlsx.input_data(a, b, c, d, e, f, g, h)
num += 1
# break
except: pass
print('记录:', num)
# break
# aa = driver.find_element(by=By.CLASS_NAME, value=f'btn-next')
# # 创建一个ActionChains对象,用于执行鼠标动作
# action_chains = ActionChains(driver)
# # 将鼠标移动到链接元素上并点击
# action_chains.move_to_element(aa).click().perform()
print(f'第{p + 1}页 --> 第{p + 2}页')
try:
xlsx.make_frame()
xlsx.save_excel()
except:
pass
break
# time.sleep(5)
pass
def func4(self, xlsx=None, key='Google2'):
if key == 'Google': self.switch_window('Google')
else: self.switch_window('必应')
driver = self.driver
data = xlsx.read_excel()
# print(data['姓名'])
for i, name in enumerate(data['姓名']):
school = data['学校'][i]
text = f'{school}{name}是不是教授'
print(f'search [{i+1}]: {name} -》 ', text)
if key == 'Google': web = driver.find_element(by=By.XPATH, value='//*[@id="APjFqb"]')
else: web = driver.find_element(by=By.XPATH, value='//*[@id="sb_form_q"]')
web.clear()
web.send_keys(text)
if key == 'Google': web = driver.find_element(by=By.XPATH, value='//*[@id="tsf"]/div[1]/div[1]/div[2]/button')
else: web = driver.find_element(by=By.XPATH, value='//*[@id="sb_form_go"]')
# try:
web.click()
# except: pass
time.sleep(5)
num = 0
if __name__ == '__main__':
from temp import Make_Excel, input_data_list, input_data
xlsx = Make_Excel()
web = Web_Browser()
web.get_all_opened_windows()
# web.switch_window('故障诊断')
''' 学术网 '''
web.func1(xlsx) # 学术网
# web.func2(xlsx) # 青塔网
# web.func3(xlsx) # NSFC官网
# web.func4(xlsx, ) # goole搜索网
# xlsx.make_frame()
# xlsx.save_excel()
pass