文章目录
- 用AI解释AI
- 目的
- 思路
- 成功解释实例
- 失败例子
- 评估解释结果
- 结果分析
- 方法小结
- 整体评估
- 缺点与改进
- 其他槽点
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索。
用AI解释AI来自openAI的论文: Language models can explainneurons in language models
官网Blog地址:https://openai.com/research/language-models-can-explain-neurons-in-language-models
AI涉及到的神经网络模型是一个黑盒子,关于AI的可解释性一直也是研究的一个热点,现有研究有从不同目的,不同角度对这个黑盒子做了一些可解释性的解读。
用AI解释AI
目的
这篇论文是从单一神经元(Neuron)的角度来进行研究的,主要目的就是要解释/预测/复现某个神经元在模型中的作用。主要原理是根据神经元何时激活(Activate),来猜测它的作用。
例如:
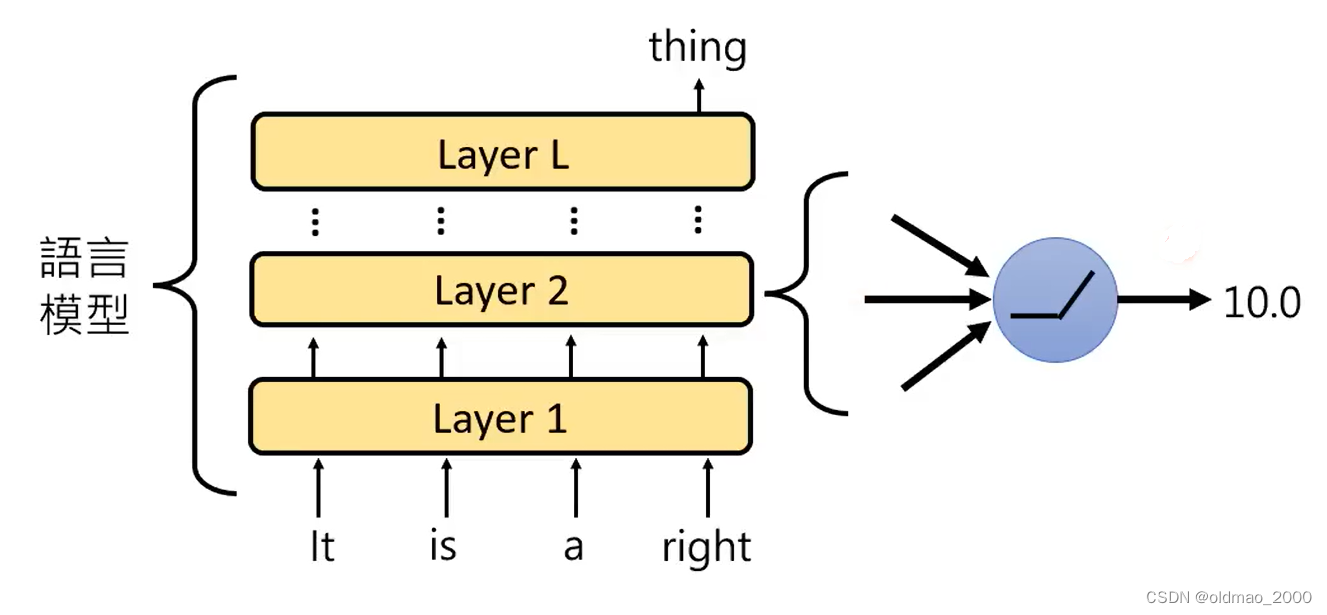
在上图的多层Transformer模型中,可以吃一个句子,预测该句子的下一个词。这个模型中有一个神经元,每次读到句子中包含有right、correct等词汇的时候,其输出score比较高,就给其冠名“正确神经元”
在文章We Found An Neuron in GPT-2中,就使用了这个原理。这里的“An”不是定冠词,而是这个神经元的名字。估计作者是看过周星星的电影的,跟“有间客栈”里面的“有间”有异曲同工之处。
作者发现在GPT-2中的第31层892号位上的神经元有一个特定的作用。

如图所示,蓝色代表892号神经元的输出,颜色越深输出越高,虽然每次得分高的词不一样,但是这些词都在单词“an”的前面,也就是说当下一个单词要输出“an”的时候,892号神经元就会Activate,所以得名:An Neuron
当然不是每个神经元都这么容易看出其作用,openAI提出使用GPT-4来解释神经元的作用,也就是这节的内容主旨:用AI解释AI。
思路
将不同句子丢到GPT-2中,查看某个神经元的Activate状态(下图中颜色越深Activate分数越高),将神经元的Activate状态丢进GPT-4,让GPT-4给出这个神经元作用的解释。

openAI给出了如何让GPT-4吃Activate状态(每个单词都对应神经元的输出score,具体格式看下面,这里要对输出score做normalization,使其取值范围从0-10)的Prompt。
We’re studying neurons in a neural network, Each neuron looks for some particular thing in a short document. Look at the parts of the document the neuron activates for and summarizein a single sentence what the neuron is looking for. Don’t list examples of words.
The activation format is token<tab>activation. Activation values range from 0 to 10. A neuron finding what it’s looking for is represented by a non-zero activation value. The higher the activation value, the stronger the match.
输入实例1:
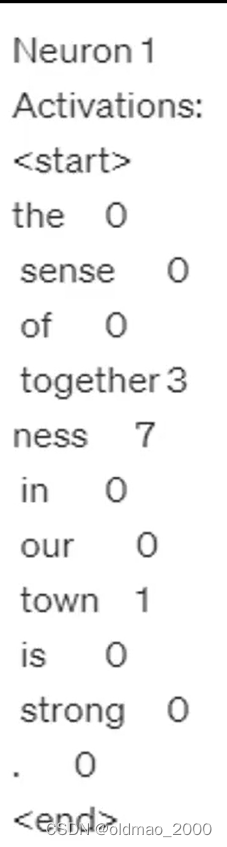
这个输入效果并不好,因为神经元对大多数单词都不会有激活,因此太多未激活的状态会使得GPT-4难以更精准的分析,因此过滤到score为0的单词再次输入:

最后提问得到的结果如下:

成功解释实例

解释:words and phrases related to performing actions correctly or properly.

descriptive comparisonses pecially similes(明喻). 这个神经元作用比较抽象,作用是比较描述或明喻。


解释: repetitions of a similar word or an evolving sequence of words. 找出重复出现的词,或者有重复模式的词组。
失败例子

解释:words related to general concepts, titles, and partial terms.一般概念等
实际上,这些词都出现在错误单词或者乱码单词后面。

解释:numbers, ordinal terms,and possessive constructions.
实际上是当前面有规律的序列被打破的时候,这个神经元就会激活。
评估解释结果
原理就是用GPT-4这个大模型来角色扮演,让其模拟某一个神经元。给出的Prompt如下:
神经元 #1938 的功用是寻找 words and phrases related to performing actions correctly or properly.
給一個句子 if their applications are executed properly
请问神元神经元 #1938 读到最后一个 token 会输出多少数值 ?
GPT-4会给出结果:9
Ground Truth会是什么呢,可将句子丢入GPT-2看答案:

Ground Truth与GPT-4的答案可以转化为Explaination Score(取值范围为0~1,具体转化方法要看原文)
实际使用的Prompt例子如下:
We’re studying neurons in a neural network, Each neuron looks for some particular thing in a short document. Look at an explanation of what the neuron does, and try to predict its activations on a particular token.
The activation format is token <tab> activation, and activations range from 0 to 10. Most activations will be 0.
Neuron 4
Explanation of neuron 4 behavior: the main thing this neuron does is find present tense verbs ending in 'ing
Text: l am
Last token activation, considering the token in the context in which it appeared in the text:
这个例子中的神经元激活条件是判断现在进行时的动词。这个例子最后的词是“am”,所以GPT-4给出的激活分数为0。如果Prompt中的Text为:l am swimming,这个时候激活分数则为10。
结果分析
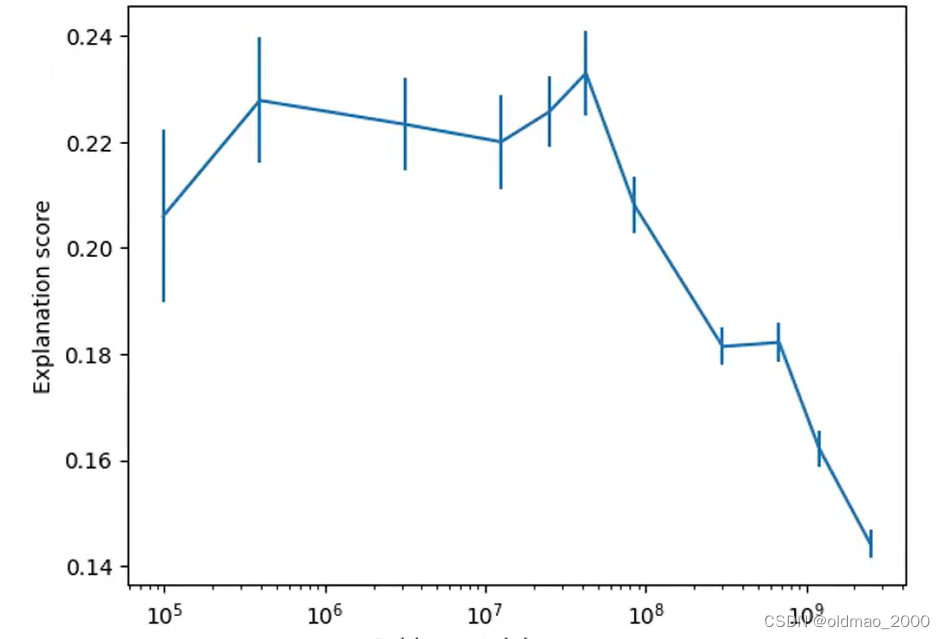
上图中横轴是模型的参数多少,越多表示模型越大;
纵轴是模型中神经元的Explaination Score,分数越高表示该模型可解释性越好。
可以看出,小模型的神经元比较好解释。

上图中是对同一个模型,不同层的神经元的可解释性的分析结果。从图中可以看到,底层的神经元可解释性较好,高层的神经元通常会看到更多的信息,其激活条件就更为抽象。
利用GPT-4来对GPT-2中的神经元进行解释,最终得到平均Explaination Score为0.15,虽然这个分数看上去很低,但是与人类亲自出马的结果0.18相比较,还算不错,换而言之,大多数神经元都没有办法很好的解释。

方法小结
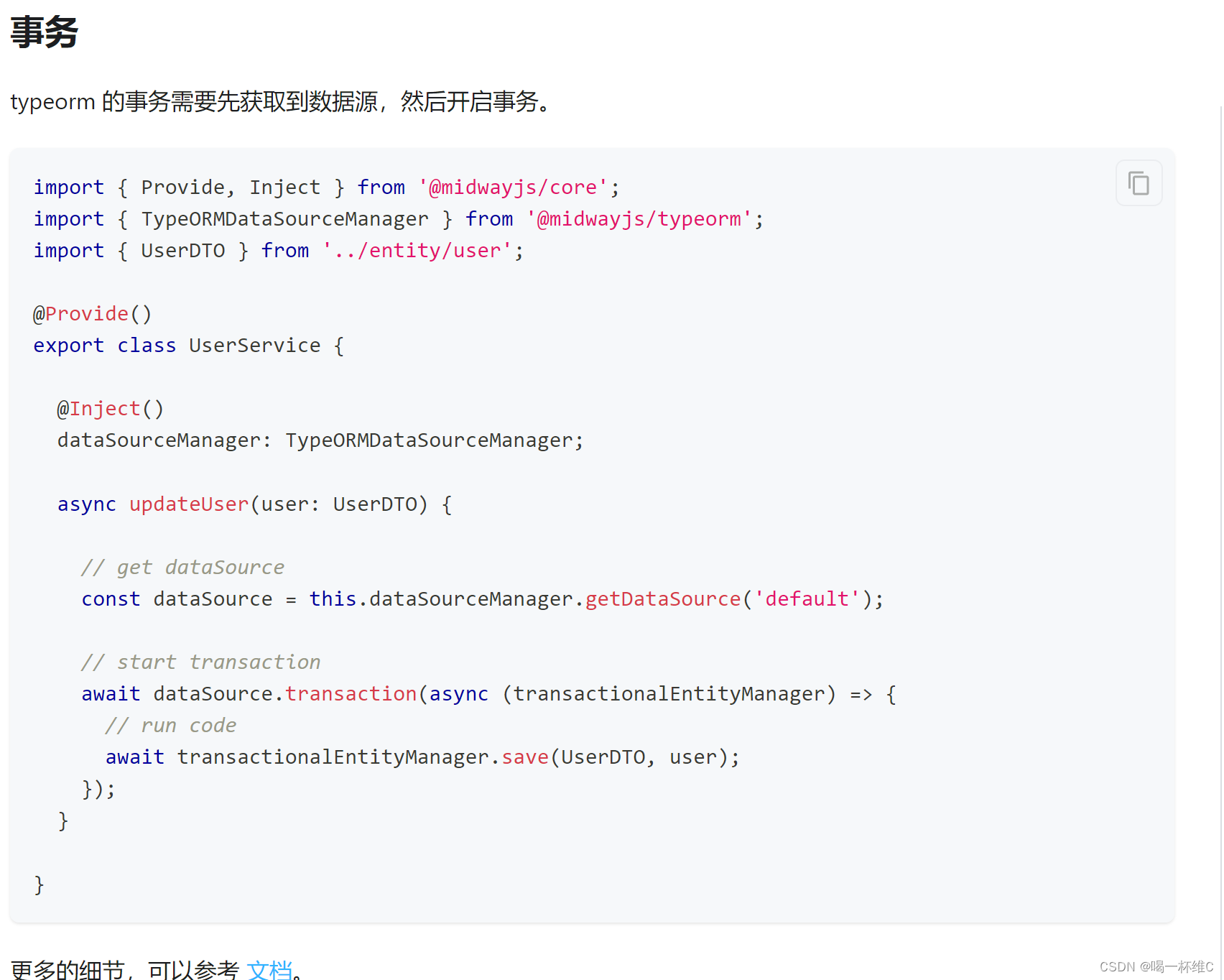
- 先找到一个我们想要解释的模型
- 吃不同的句子,得到某个神经元的激活分数
- 将上一步的结果输入到解释模型,得到某个神经元的作用解释
- 将得到解释输入到模拟模型,评判解释结果是否正确
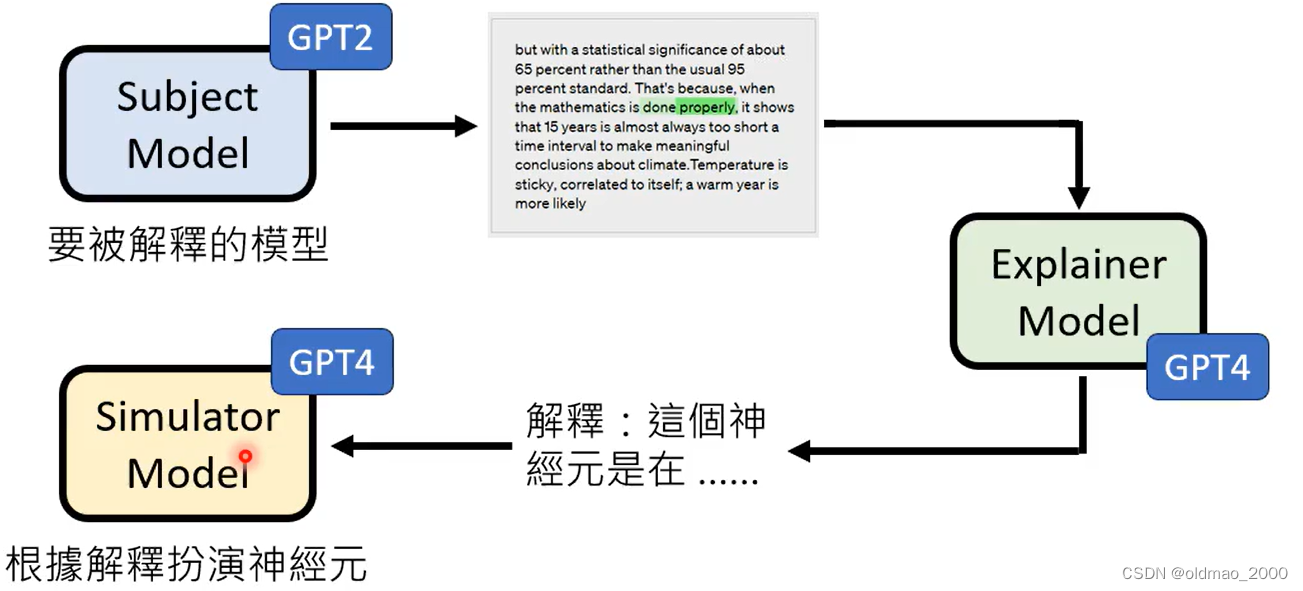
注意:以上3个模型可以不是同一个模型,也可以不是GPT-4
整体评估
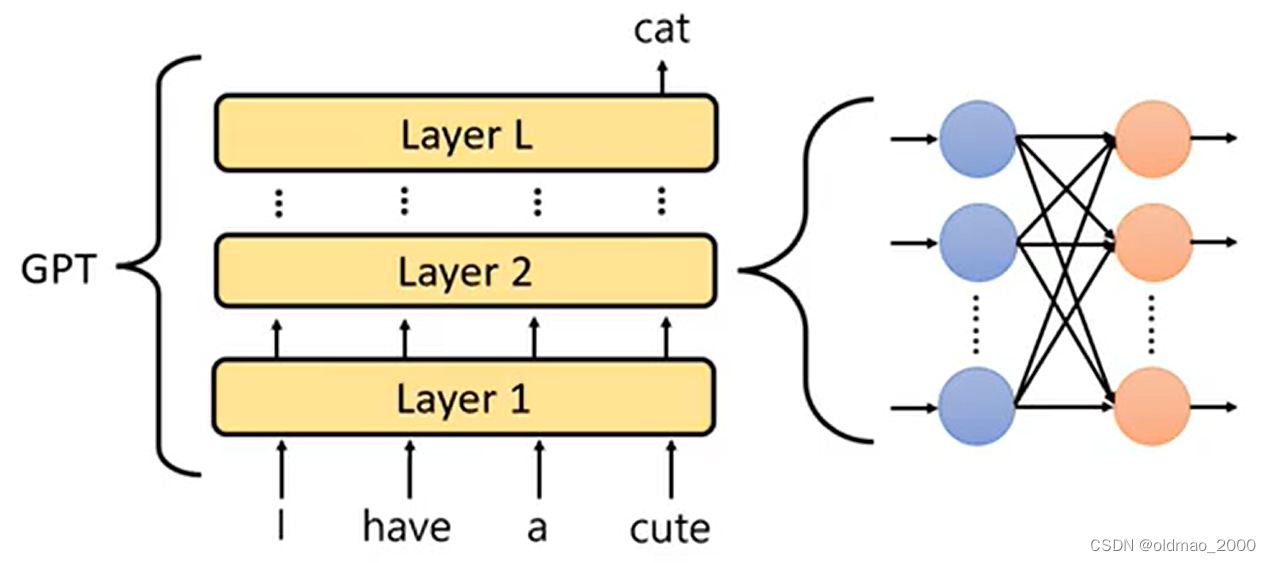
虽然前面是通过单个神经元的激活分数对神经元的作用作了预测,但是从整体上来看,一个模型包含了很多个神经元,每个神经元的重要程度是不一样的,有的神经元比较重要,甚至会影响模型的输出,有的则是摸鱼的存在。因此,有必要从整个模型输出来整体评估神经元的作用。思路如下:
先确定我们要解释的模型:
然后用整个GPT-4模型替换其中某一个神经元:
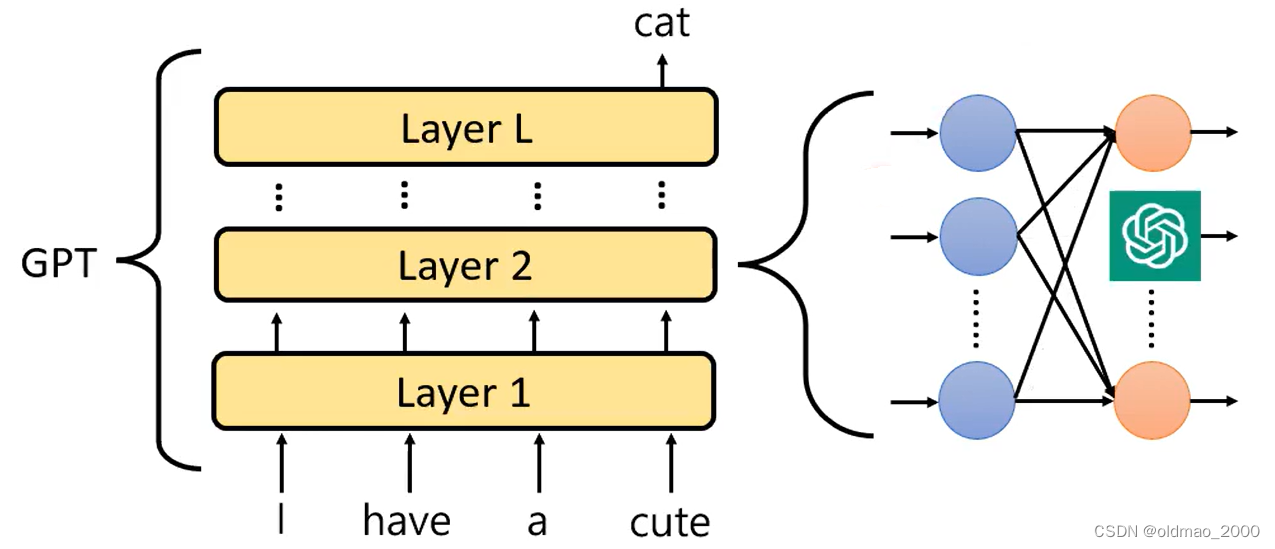
然后考查被替换后的模型的输出是否会有变化,或者说考查其输出的变化程度。其结果如下:
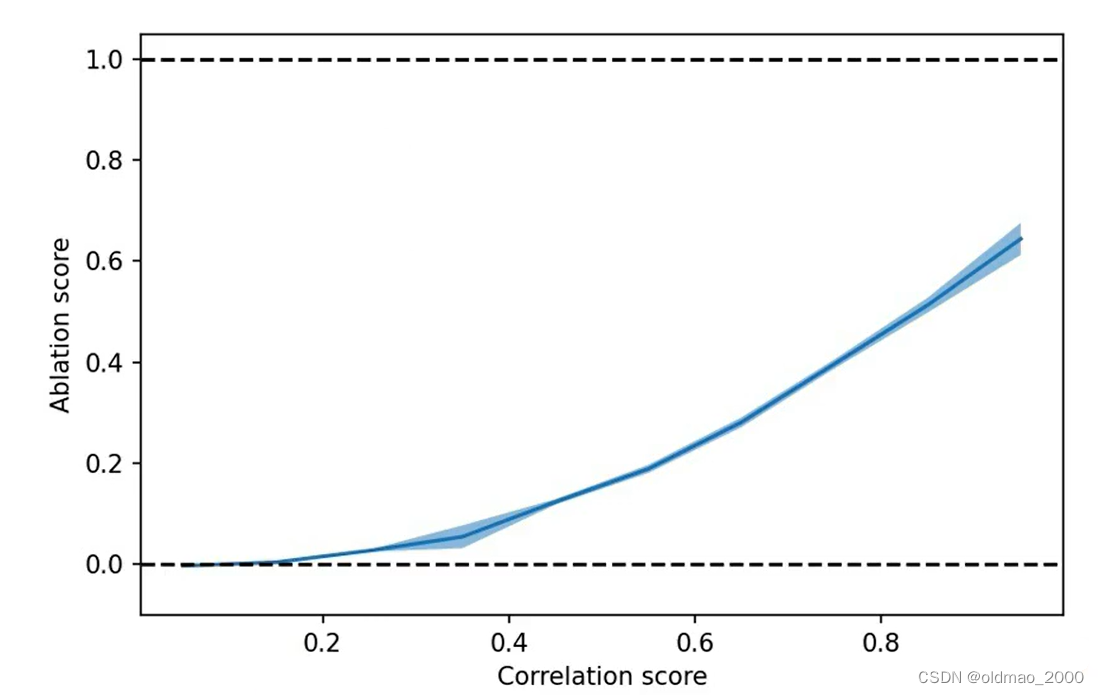
横轴是GPT-4扮演的单个神经元与原模型中单个神经元的输出差异
纵轴代表替换后模型的整体输出与原模型的差异
可以看到两个变量之间是呈正相关的关系,说明研究个体就行,对整体输出的影响不大。
缺点与改进
在测试被解释模型的某个神经元的时候,需要输入大量的句子或文本:
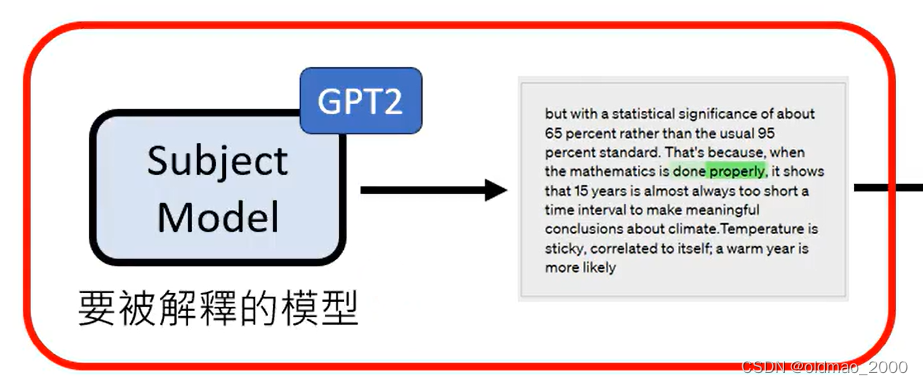
但是大多数句子可能不会激活被解释模型的某个神经元,因此,这里要将没有激活效果的句子剔除。就好比有100种新药对小白鼠进行测试,小白鼠对其中90种药根本没有反应,则没有必要去研究这些无效药,而要将重点放在有药效的10种药上。否则无论激活与否都做为输入丢进GPT-4是不现实的,数据量太大,前面也提到,就算有激活效果的句子,其中无激活效果的词也会被过滤掉。这样的做法会带来一个问题,例如:
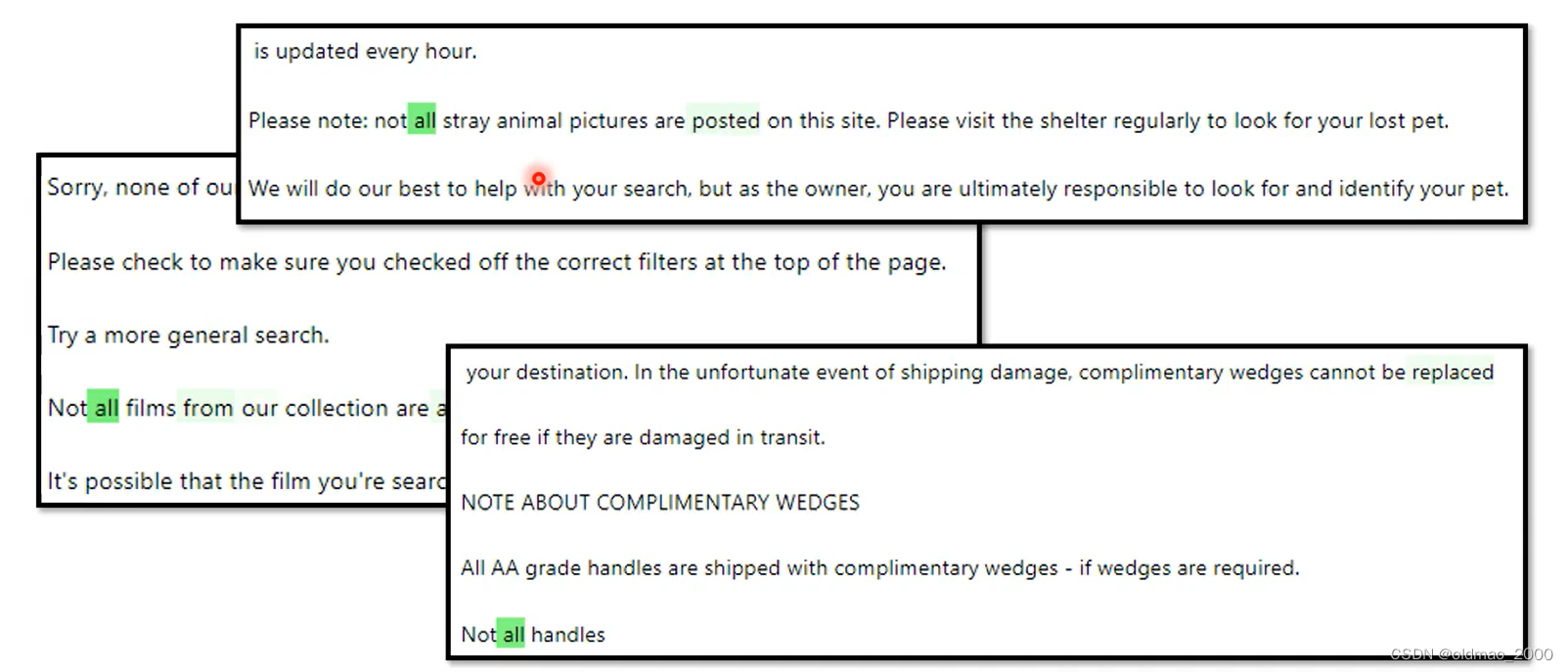
GPT-4比较倾向比较General的解释,因此对这个神经元的激活解释为带有:“all”这个单词,但实际上应该是“not all”才对。
改进方法:
将GPT-4生成的解释丢进GPT-4,让其生成更多类似的语料,这些语料可以用来检测之前生成的解释对不对,例如上面的例子可以有以下Prompt:
The task format is as follows, description .::<answer>example sentence that fits that description</answer>
This task has exactly 10 answer(s) each enclosed in <answer></answer> tags.
Remember, the answer is always at least one full sentence, not just a word or a phrase.
the term “all” along with related contextual phrases.::
GPT-4生成的语料如下:
<answer>Everyone is excited about the event.</answer>
<answer>All the students attended the lecture.</answer>
<answer>She managed to read all the books on the list.</answer>
<answer>They invited all their friends to the party.</answer>
<answer>All the employees received a bonus this year.</answer>
<answer>He finished all his chores before going out.</answer>
<answer>All the ingredients were mixed together in a bowl.</answer>
<answer>All the lights in the house were turned off.</answer>
改进后的结果如下:
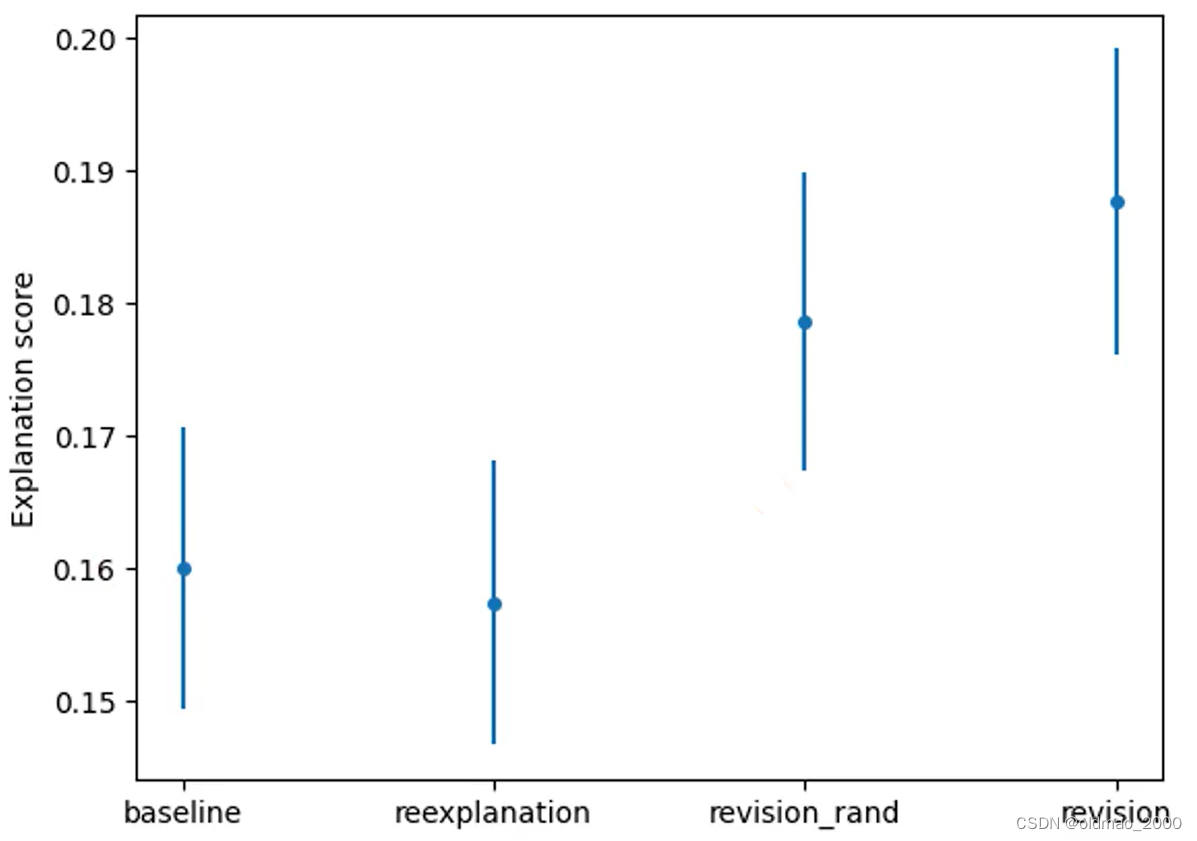
最后一列效果最后,前一列revision_rand是使用随机句子来检测,虽然随机找来的句子不一定适用于检测当前神经元,但聊胜于无。
其他槽点
1.目标质疑:解释单一神经元是否有意义?因为有可能是多个神经元协同合作来完成某个功能(原文有做这方面的尝试);神经元的功能能用语言来描述吗?有些神经元的功能非常抽象(尤其是接近输出层),很可能其功能无法用语言进行描述。
2.方法质疑:如果模拟模型很烂,就算解释模型生成的神经元解释很好,但是模拟模型无法很好的模拟出该神经元的功能;解释模型和模拟模型可能会串通,使用暗语导致Explaination Score虚高。