论文信息
原文链接:
Learning Hierarchical Modular Networks for Video Captioning | IEEE Journals & Magazine | IEEE Xplore
原文代码
GitHub - MarcusNerva/HMN: [CVPR2022] Official code for Hierarchical Modular Network for Video Captioning. Our proposed HMN is implemented with PyTorch.
所属期刊/会议:
CVPR 2022
所用数据集
MSR-VTT、MSVD、VATEX
论文总结
What:
1、文章作者提出了一个分层模块化网络(HMN),在生成字幕之前,以四个粒度连接视频表示和语言语义:实体、动词、谓词和句子。每个级别由一个模块实现,以将相应的语义嵌入到视频表示中。
2、提出了一个基于字幕场景图的强化学习模块,以更好地衡量句子的相似性。
Why:
1、现有的方法主要集中在设计复杂的视频编码器,通过对生成的字幕的损失进行梯度反向传播,以隐式的方式学习有效的视觉表示。(但是缺乏一定的可解释性)相反,我们建议通过直接对齐视频和字幕的嵌入来学习视频表示。
2、检测出的实体可能会有冗余,未出现在caption gt中
Challenge:
①视频中的实体识别问题:如何识别准,如何识别全
现有方法:
1、优化编码器(使得生成的编码提取和存储更多的视频信息),忽视了视频特征和语言特征之间的语义距离
2、在生成Caption之前缩小视频特征和语言特征之间的语义距离(现有的Video Caption model基本都是采用encoder-decoder的模型)然而,这些方法要么专注于全局句子,要么关注局部词对应,无法利用不同粒度的对齐。
②识别出的实体检测出的实体可能会有冗余,未出现在caption gt中
Idea:
总的来说为了解决上述问题,我们提出了一种分层模块化网络(HMN)[20],以实体、谓词和句子三个粒度直接将视觉表示与文本对应物对齐(见图 1)。实体突出显示标题中最有可能提到的视觉对象,并由标题中的实体 1 监督。实体通常用作视频字幕的基石,可以是动作的主题或对象以及修饰符。在语言中,谓词是指包含动词的句子或从句的一部分,并陈述有关主语的内容。在视频字幕的上下文中,谓词根据字幕描述以突出显示的对象为条件的动作表示。
为了解决Challenge①设计粒度不同的编码器来对视频中不同粒度的信息进行编码
为了解决Challenge②我们提出了一个实体模块来突出显示标题中最有可能提到的主要对象,从而减少由不重要对象引起的噪声量和后续处理的计算负荷。
Model:
本文提出的模型采用编码器-解码器方案,如图2所示,其中实体、动词、谓语和句子模块作为编码器,描述生成器作为解码器。我们还设计了一个基于场景图的奖励,通过强化学习来调节我们的模型。我们的模型将对象、运动和上下文特征作为输入。实体模块首先选择主要对象,这些对象最有可能在标题中提到。然后,谓词模块利用输出的主体对象和运动特征构造动作表示。同时,动词模块仅根据运动特征单独生成动作表示。接下来,句子模块将这些对象和动作表征以及上下文特征结合起来,为输入视频生成全局表征。在这些步骤中,通过使用多个语言头缩小其在联合嵌入空间中的距离,提高了多层视频表示与相应语言成分之间的一致性。最后,描述生成器将所有这些编码的多层次视觉特征生成字幕。我们将在以下几节中介绍每个模块。

论文翻译
Abstract
视频字幕旨在为给定的视频剪辑生成自然语言描述。现有方法主要侧重于通过预测字幕和真实文本之间的逐字比较进行端到端表示学习。尽管取得了重大进展,但这种监督方法忽略了视觉和语言实体之间的语义对齐,这可能会对生成的字幕产生负面影响。在这项工作中,我们提出了一个分层模块化网络,在生成字幕之前,以四个粒度连接视频表示和语言语义:实体、动词、谓词和句子。每个级别由一个模块实现,以将相应的语义嵌入到视频表示中。此外,我们提出了一个基于字幕场景图的强化学习模块,以更好地衡量句子的相似性。大量的实验结果表明,该方法在microsoft研究视频描述语料库(MSVD)、MSR-video to text (MSR-VTT)和video-and-TEXt (VATEX)三个广泛使用的基准数据集上优于最先进的模型。
索引术语-视频字幕,分层模块化网络,场景图奖励,强化学习。
Introduction
近年来,用自然语言(也称为视频字幕)自动描述视频引起了相当大的关注。VideoCaption在许多应用中,起着至关重要的作用,如残疾辅助、视频检索和人机交互[1]、[2]、[3]、[4]、[5]、[6]、[7]。尽管取得了重大进展,但由于视频内容的多样性,它仍然是一个具有挑战性的问题,例如出现在视频中的几十个对象,但字幕中仅提到了其中的两个或三个对象。现有的方法可以大致分为两类。第一类侧重于开发有效的编码器,以便学习更好的视频表示[8],[9],[10],[11],[12],[13],[14]。例如,视频中的对象之间的空间和时间关系已经利用图来学习丰富的表示[9],[10]。此外,时间动态和门融合网络已被用于学习更丰富的视频字幕表达[11],[12]。虽然这些方法在视频字幕上表现良好,但优化目标是以逐字方式制定的,因为生成标题,忽略了视频表示和语言表示之间的关系。第二类侧重于在生成字幕 [15]、[16]、[17] 之前缩小视频表示和语言对应物之间的语义差距。Pan等人[15]提出学习视频的全局嵌入和整个标题的表示之间的对齐。在[16],[17],[18],[19]中,名词和动词与视觉表示相关联,以探索细粒度级别的视频语言对应关系。实证演示表明,这一系列方法能够生成更准确的标题。然而,这些方法要么专注于全局句子,要么关注局部词对应,无法利用不同粒度的对齐。
为了解决上述问题,我们提出了一种分层模块化网络(HMN)[20],以实体、谓词和句子三个粒度直接将视觉表示与文本对应物对齐(见图 1)。实体突出显示标题中最有可能提到的视觉对象,并由标题中的实体 1 监督。实体通常用作视频字幕的基石,可以是动作的主题或对象以及修饰符。在语言中,谓词(Predicte)是指包含动词的句子或从句的一部分,并陈述有关主语的内容。在视频字幕的上下文中,谓词根据字幕中的高亮物体描述动作表示。

这些谓词有助于减少从多含义动词到特定视频动作嵌入的对应错误,例如踢足球和弹钢琴中的play。句子对齐根据整个标题捕获场景的全局视图,使生成的标题具有合理的含义。在这三种视觉文本对齐(每一种都作为一个模块实现)的帮助下,我们的模型显著提高了标题质量。
虽然HMN已被证明在最先进的方法中表现良好,但仍有几个问题需要解决。首先,在HMN的谓词模块中,简单的BiLSTM不能很好地模拟视觉动作表示内部的融合以及视觉动作和对象表示之间的融合。其次,谓词模块可以学习强实体-动作耦合(例如,当实体是“自行车”时总是预测“骑”,但基本事实可以是“推”)。第三,与现有方法类似,HMN对生成的字幕采用逐字监督,这些字幕不能反映相似但不完全相同的表达之间的相似性,例如“海滩上男人旁边的女人”与“海滩上男人旁边的女人”。
本文从三个方面对HMN进行改进。
首先,我们使用不同的技术,包括变压器、(Bi) lstm及其组合,广泛探索视觉动作和对象表示内部和之间的融合方案。
其次,我们设计了一个独立的动词模块作为谓词模块的补充组件,旨在增加生成动词的灵活性。
第三,我们设计了一个基于场景图的奖励,通过强化学习来调节我们的模型,该模型能够在较少受词序干扰的情况下测量句子相似度。配备了这些新颖的设计,所提出的方法在三个广泛使用的基准数据集上优于最先进的方法。
本文的贡献总结如下:
1、我们提出了一个分层模块化网络,在生成标题之前,在四个粒度上学习多层视觉表示,并将它们与它们的语言对口物:实体、动词、谓语和句子相关联。
2、我们提出了一个基于Transformer的实体模块来学习选择最有可能在标题中提到的主要对象。
3、为了更好地测量句子相似度,我们提出了一个强化学习模块,其中基于场景图的奖励被设计成鼓励生成的字幕在语义上更接近其groundtruth,并且对词序有更大的容忍度。
我们的方法在三个广泛使用的基准上表现优于最先进的模型:msr -视频到文本(MSR-VTT),视频和文本(VATEX)和微软研究视频描述语料库(MSVD)。
Related Work
模板和深度模型:近年来,使用经典和深度学习方法在视频字幕方面取得了重大进展。在早期,字幕模板[21]和[22]已经被用来解决这个问题。这些方法首先生成对象和动作的单词,然后将这些单词放入预定义的句子模板中以获得完整的标题。尽管取得了成功,但一个主要的限制是它们不能生成具有灵活句型的标题。近年来,许多基于卷积神经网络(cnn)和递归神经网络(rnn)的方法被开发出来,以实现灵活的视频字幕[2],[4],[7]。Venugopalan等[1]提出了一种基于长短期记忆(long - short-term memory, LSTM)的模型[23],使用每帧的CNN特征作为输入,顺序生成标题词。由于视频表示在该任务中起着关键作用,Yao等人[6]开发了一种时间注意机制来建模视频中的全局时间结构,该机制根据文本生成RNN的状态聚合相关视频片段。除了图像和运动特征外,音频特征也被用来丰富视频表现[24],[25]。为了从大量输入中找到有用的信息,Chen等人[5]提出了一个PickNet模型来从视频中选择信息帧,这也可以减少后期处理的计算成本。另一方面,Wang等人[26]和Pei等人[27]利用记忆网络有效组织大量视觉特征,从而提高字幕质量。现有的方法主要集中在设计复杂的视频编码器,通过对生成的字幕的损失进行梯度反向传播,以隐式的方式学习有效的视觉表示。相反,我们建议通过直接对齐视频和字幕的嵌入来学习视频表示。
以对象为中心的视频字幕:物理实体通常作为字幕中的主体或对象,在字幕中起着至关重要的作用。利用场景中的物体来生成字幕已经得到了很多关注。在[13]中,Zhang等人提出通过GRU[28]模块从时间轨迹捕获目标动态。Aafaq等人[12]利用对象标签来增强视觉表示的语义。另一方面,Zheng等人[17]通过注意机制对对象之间的相互作用进行建模。在[9]和[10]中,通过图卷积网络[29]对对象之间的关系进行建模,以增强对象级表示。这些方法可以在挖掘详细视频信息时很好地生成字幕。
然而,一个潜在的问题是,所有检测到的对象都被使用了,但在现实中,只有一小部分在标题中被提及。因此,生成的字幕的质量可能会有噪声。与这些方法不同的是,我们提出了一个实体模块来突出显示标题中最有可能提到的主要对象,从而减少由不重要对象引起的噪声量和后续处理的计算负荷。
用于字幕的Transformer:已经开发了许多变压器模型,并应用于许多自然语言处理和视觉问题[30],[31],[32],[33],[34],[35],[36],[37],[38],[39]。同样,在视频字幕任务中也探索了Transformer。在[9]中,使用两个转换器作为对象信息和场景信息的语言解码器。另一方面,Li等[40]设计了一个全局门控图推理模块,以取代自注意机制来捕捉对象的短期空间关系和对象的长期转换依赖关系。与这些方法不同,部分受到DETR[41]的启发,我们提出了一个基于变压器的实体模块,从视频中检测到的大量实体中预测主要对象。
用于字幕的场景图:最近基于场景图开发了许多字幕方法[42],[43],[44]。在[42]中,使用物体的空间位置和人-物交互标签来构建场景图。相比之下,Zhong等[43]从输入图像的场景图中选择重要的子图,并将每个选择的子图解码为单个目标句子。在[44]中,图形表示通过视频字幕的元概念得到增强。我们注意到,现有的方法在视觉方面构建场景图,以增强后期字幕解码器的视觉表示。相比之下,我们的场景图是从文本方面构建的,即生成的说明文字和真实的说明文字,它们用于度量相似度,从而作为约束模型的损失。
用于字幕的强化学习:基于强化学习(RL)的视频字幕方法已经被开发出来,可以有效地减轻曝光偏差[45]和不可微损失[46]、[47]、[48]、[49]、[50]、[51]、[52]。在[11]和[51]中,直接使用生成字幕的CIDEr[53]分数来优化字幕模型。不同的是,Liu等人[46]设计了一个上下文感知策略,将上下文视觉注意变化考虑在内。Rennie等人[48]提出了一种强化学习方法,该方法利用自己的测试时间推理模块的输出,减轻了估计奖励和归一化的计算复杂性。在[52]中,Zhang等人将视频字幕过程视为语言依赖树生成过程,并提出了一种树状结构的强化学习算法来优化字幕模型。与这些基于n-gram(非连续单词)计算奖励的方法不同,我们设计了一个基于场景图的奖励来更好地描述视频字幕,比如物体之间的关系和物体的属性。这种设计有助于跳过n-gram中一些不重要的单词。
大型模型:受CLIP等图像-文本预训练成功的启发[54],一些作品研究了视频文本预训练并取得了显著的成功[55],[56],[57]。UniVL[55]提出通过四个自监督任务学习大规模叙事视频的视频和文本表示,包括掩码语言建模、掩码帧建模、视频文本对齐和语言重建。在CLIP成功的基础上,CLIP4Caption[56]利用视频文本匹配任务进一步优化其文本和视觉编码器。文献[57]提出了视频事件边界预测任务和文本描述生成,目的是使模型能够更好地理解视频中的事件。LAVENDER[58]提出通过使用相同的屏蔽语言建模作为所有预训练和下游任务的公共接口,统一多个视频文本任务(例如,文本到视频检索、视频问答和视频字幕)。另一方面,大型语言模型,如InstructGPT[59],已经以零拍摄的方式用于解决视频字幕任务。VidIL[60]利用图像语言模型(CLIP和BLIP[61])将视频内容转换为帧级字幕,然后使用一些带有InstructGPT的提示生成视频字幕。在[62]中,使用冻结的GPT-2[63]模型学习软提示以生成视频帧导向的字幕。由于缺乏域内训练,零射击方法的表现远远落后于传统的字幕方法。当使用相同的预训练CLIP特征时,我们的方法可以获得比预训练方法UniVL和CLIP4Caption更好的性能。
Method
本文提出的模型采用编码器-解码器方案,如图2所示,其中实体、动词、谓语和句子模块作为编码器,描述生成器作为解码器。我们还设计了一个基于场景图的奖励,通过强化学习来调节我们的模型。我们的模型将对象、运动和上下文特征作为输入。实体模块首先选择主要对象,这些对象最有可能在标题中提到。然后,谓词模块利用输出的主体对象和运动特征构造动作表示。同时,动词模块仅根据运动特征单独生成动作表示。接下来,句子模块将这些对象和动作表征以及上下文特征结合起来,为输入视频生成全局表征。在这些步骤中,通过使用多个语言头缩小其在联合嵌入空间中的距离,提高了多层视频表示与相应语言成分之间的一致性。最后,描述生成器将所有这些编码的多层次视觉特征生成字幕。我们将在以下几节中介绍每个模块。
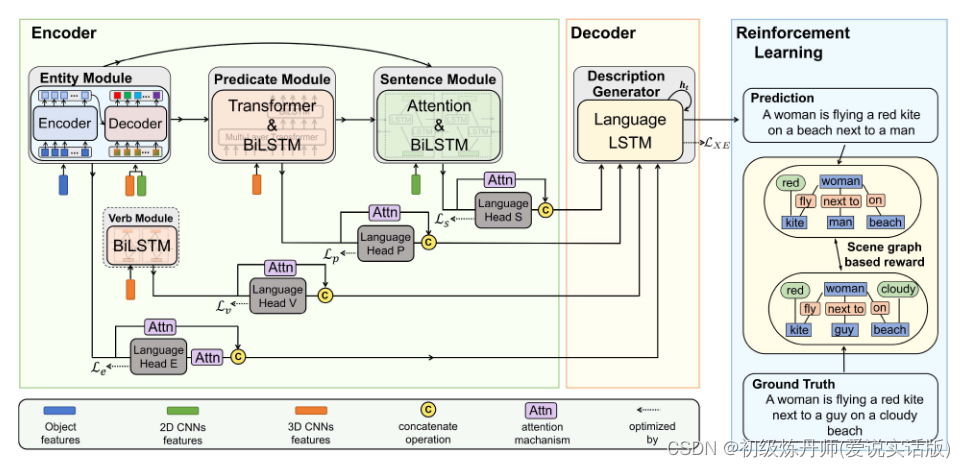
(Fig. 2. Proposed model follows the conventional encoder-decoder structure, where the encoder consists of modules based on entity, verb, predicate, and sentence. The decoder consists of a description generator. The entity module (Section III-B) distinguishes principal video objects from all the detected ones, aligning video and language at the entity level. The predicate and verb modules (Section III-C) generate action representations for the input videos, bridging the video action and the linguistic predicate and verb, respectively. To construct the global representations for the input videos, the sentence module (Section III-D) aggregates context features with the two previously mentioned modules' outputs together, which narrows the video-language semantic gap at the sentence level. Finally, our description generator, gathering the above encoded video features, produces accurate captions for input videos. The scene-graph-based reward (Section III-F) is designed to enhance the robustness.)
a .视频特征提取给定一个视频,我们统一选择T个关键帧,在每个关键帧处收集短距离视频帧作为3D视频立方体。我们使用预训练的目标检测器Faster-RCNN从每个关键帧中提取目标区域[64]。然后,我们根据这些区域的外观相似度和边界框之间的交联度(Intersection over Union, IoU)将这些区域划分为多个聚类。我们使用每个聚类的均值池特征作为初始对象特征O = {oi}L i=1, oi∈Rdo,其中L和do表示视频对象的数量和对象特征的大小。我们还提取了2D上下文特征C = {ci}T i=1和3D运动feature M = {mi}T i=1分别通过预训练的InceptionResNetV2[65]和C3D[66]从关键帧和视频数据集中得到。
(未完待续)