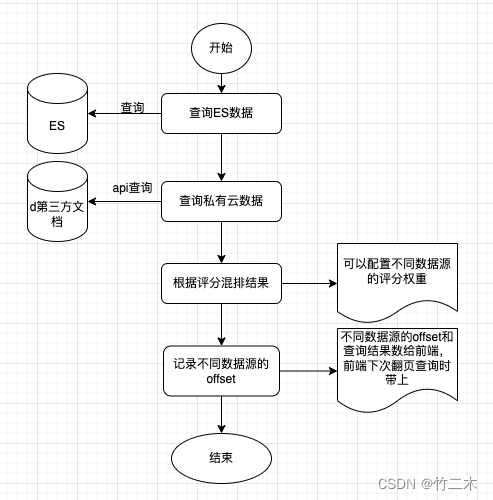
如何创建自己的自定义ChatGPT
目录
- 如何创建自己的自定义ChatGPT
-
- 大型语言模型(LLM)
- GPT模型
- ChatGPT
- OpenAI API
- LlamaIndex
- LangChain
- 参考
推荐超级课程:
- Docker快速入门到精通
- Kubernetes入门到大师通关课
本文将记录如何使用OpenAI GPT-3.5模型、LlamaIndex和LangChain创建自己的自定义ChatGPT.

大型语言模型(LLM)
大型语言模型(LLM)是一种人工智能(AI)算法,它使用深度学习技术和大规模数据集来理解、总结、生成和预测新内容。术语生成式AI与LLM密切相关,实际上,LLM是一种生成式AI,专门设计用于帮助生成基于文本的内容。LLM是专为自然语言处理任务而设计并经过广泛训练的模型。这些模型在大量文本数据上接受训练,使它们能够生成与人类语言非常相似的文本。它们具有理解语境细微差别并回答问题的能力。此外,LLM还可以针对特定任务进行微调,例如翻译、总结和情感分析。由OpenAI开发的GPT(生成预训练变换器)模型系列是LLM的著名实例。这些GPT模型是广泛认可的ChatGPT应用程序的核心组件,我们将在下一部分进行详细探讨。
GPT模型
OpenAI是开创了GPT模型系列的研究机构。这些模型经过训练,可以理解自然语言和代码,并根据其输入生成文本输出。它们的GPT-3和GPT-4模型(用于构建著名的ChatGPT应用程序)是游戏改变者。在得到GPT-3和GPT-4之前,还有GPT-1和GPT-2,这两个模型都是令人印象深刻的语言模型,但在数据集和能力方面存在局限性。GPT-3有1750亿参数,使其能够提供类似人类的回应。通常很难区分GPT-3的回应和人类回应。现在世界正在等待GPT-4,这是GPT-3的更好版本。OpenAI最先进的系统,GPT-4,有1万亿参数,使其更加显著和有影响力。如果您有兴趣深入了解GPT模型的构建和训练过程,我建议参考这篇全面的研究论文。
ChatGPT
ChatGPT是一个基于Web的聊天机器人应用程序,专为优化对话交互而设计和微调。它利用OpenAI强大的GPT-3模型,以便与人类进行无缝和引人入胜的对话。ChatGPT的重点在于创建对话,让它能够以聊天方式生成文本,以便用于代码解释甚至撰写诗歌等任务。基本上,ChatGPT是一个应用程序,GPT-3模型是其基础智能。ChatGPT这个命名方式源于它是一个基于GPT模型基础上构建的面向聊天的应用程序。
OpenAI API
正如我之前提到的,OpenAI构建了GPT LLM模型系列,包括GPT-3和GPT-4。使用这些GPT,您可以构建应用程序来草稿文档、编写计算机代码、回答关于知识库的问题、分析文本等。OpenAI提供API,以便与这些模型进行交互和使用在我们自己的应用程序中。要通过OpenAI API使用GPT模型,我们需要发送一个包含输入和您的API密钥的请求,并接收包含模型输出的响应。
像GPT-3和GPT-4这样的模型是在大规模的公共数据集上预训练的,这使得它们在开箱即用时具有令人难以置信的自然语言处理能力。但是,如果无法访问自己的私有数据,它们的效用是有限的。OpenAI提供的API允许我们使用自定义数据集利用它们的模型的能力。这意味着我们可以使用我们的专有数据训练GPT模型,并将这些模型集成到我们的应用程序中。在这个示例中,我将深入探讨使用提供的PDF文件中的一系列研究论文训练gpt-3.5-turbo模型的过程。随后,我将演示创建一个与ChatGPT类似的聊天机器人,能够根据这些研究论文的内容回答问题。
LlamaIndex
LlamaIndex(以前被称为gpt-index)是一个数据框架,提供了与外部数据(例如您的私有数据)连接LLM的简单灵活界面。它允许开发人员将来自PDF、PowerPoints、Notion和Slack等应用程序以及Postgres和MongoDB等数据库的数据连接到LLM。该框架包括连接器,用于摄取数据源和数据格式,以及构造数据的方法,使其可以轻松与LLM一起使用。这些数据被索引成优化了LLM的中间表示。然后,LlamaIndex通过查询引擎、聊天界面和基于LLM的数据代理,支持自然语言查询和会话与您的数据。它使您的LLM能够在大规模的私有数据上访问和解释,而无需重新训练模型以适应新数据。
LlamaIndex从您的文档数据创建矢量化索引,使查询变得非常高效。然后,它使用此索引根据查询与数据之间的相似度确定文档的最相关部分。检索到的信息随后被合并到发送给GPT模型的提示中,为其提供回答您问题所需的上下文。
LangChain
LangChain是一个强大的库,旨在简化与大型语言模型(LLMs)提供程序(如OpenAI、Cohere、Bloom、Huggingface等)的交互。LangChain的独特提议是创建链条,即一个或多个LLMS之间的逻辑链接。
LLM的复杂性,例如它们的频繁更新和大量参数,已经造成了提供者之间激烈的竞争。为了简化利用这些模型的过程,LangChain提供了API,抽象出许多与克隆代码、下载训练权重和手动配置设置相关的挑战。基本上,LangChain提供了一个应用程序编程接口(API),以便访问和与LLM进行交互,促进无缝集成,使您能够充分利用LLM在各种用例中的潜力。
LlamaIndex有效地利用了LangChain的LLM模块,并提供了灵活性,可以自定义所使用的基础LLM —— 默认选项是OpenAI的text-davinci-003模型。所选定的LLM用于构建LlamaIndex内的响应,并有时还在索引创建过程中发挥作用。
LlamaIndex和LangChain的无缝组合为使用专有数据训练GPT模型和开发应用程序提供了一种无缝的方法。以下步骤概述了使用自定义数据训练GPT模型并创建使用该模型的Chatbot应用程序的过程。在这种情况下,我使用了GPT-3.5模型(gpt-3.5-turbo)。数据索引使用LlamaIndex实现,而与OpenAI API的集成由LangChain促成。
- 安装所需的软件包
首先,您需要安装以下必要的Python软件包:openai、PyPDF2(用于读取PDF文件的Python库)、llama_index、langchain和gradio(一个Python UI库)。
pip install openai
pip install PyPDF2
pip install langchain==0.0.148
pip install llama-index==0.5.6
pip install gradio