快手联合浙江大学、新加坡国立大学发布了DragAnything ,利用实体表示实现对任何物体的运动控制。该技术可以精确控制物体的运动,包括前景、背景和相机等不同元素。
该项目提供了对实体级别运动控制的新见解,通过实体表示揭示了像素级运动和实体级运动之间的差异。与拖动像素范式不同,
DragAnything能够使用实体表示实现真正的实体级别运动控制。用户可以通过绘制轨迹与SAM进行互动。该项目能够精确控制物体的运动,生成高质量的视频。
用户轨迹与SAM的交互

论文阅读

-
基于轨迹的可控生成的新见解揭示了像素级运动和实体级运动之间的差异。
-
DragAnything与拖动像素范例不同,它可以通过实体表示实现真正的实体级运动控制。
与DragNUWA的比较
DragNUWA导致第一排外观失真,第三排失控的天空和船,不正确的镜头运动(第五排),而DragAnthing可以精确控制运动。

更多的可视化拖动任何东西
提出的DragAnything可以在实体级精确控制物体的运动,产生高质量的视频。利用Co-Track实现了第20帧像素运动的可视化。

各种各样的运动控制
提出的DragAnything可以实现多种运动控制,如控制前景、背景和相机。

Badcase for DragNUWA
当前模型受到基础模型(稳定视频扩散)的性能限制,无法生成具有非常大运动的场景。这可能是由于运动过度,超过了基础模型的生成能力,导致视频质量崩溃。

摘要
我们提出了DragAnything,它利用实体表示来实现可控视频生成中任何对象的运动控制。与现有的运动控制方法相比,DragAnything具有几个优势。首先,基于轨迹的交互更人性化,当获取其他指导信号(例如,掩码、深度图)是劳动密集型时。用户只需要在交互过程中画一条线(轨迹)。其次,我们的实体表示作为一个开放域嵌入,能够表示任何对象,使包括背景在内的各种实体的运动控制成为可能。最后,我们的实体表示允许对多个对象进行同时和不同的运动控制。广泛的实验表明,我们的方法在FVD、FID和用户研究方面取得了最先进的性能,特别是在对象运动控制方面,我们的方法在人工投票中超过了以前的方法(例如,DragNUWA)26%。
动机

启示1
物体上的轨迹点不能代表实体。从DragUNWA的像素运动轨迹可以看出,拖动云的像素点并不会导致云移动,相反,它会导致摄像机向上移动。这表明模型无法感知我们控制云的意图,这意味着单个点不能代表云。
启示2
对于轨迹点表示范式,靠近拖动点的像素受到的影响更大,导致更大的运动。通过比较,我们观察到在DragNUWA合成的视频中,靠近拖动点的像素表现出更大的运动。然而,我们期望的是物体按照提供的轨迹作为一个整体移动,而不是单个像素的运动。

方法
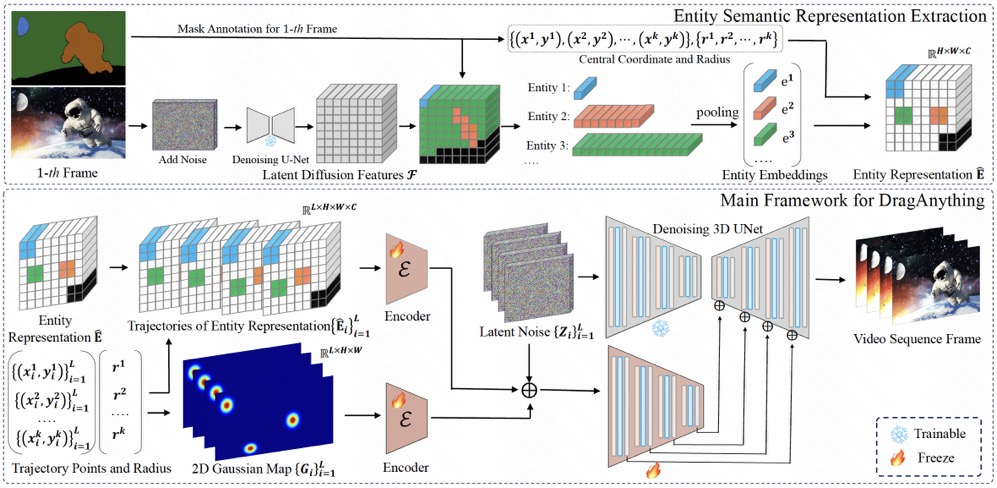
该体系结构包括两个部分:
-
实体语义表示抽取。基于实体掩码指标提取扩散模型的潜在特征作为对应的实体表示。
-
DragAnything的主框架。利用相应的实体表示和二维高斯表示来控制实体的运动。
感谢你看到这里,也欢迎点击关注下方公众号或者关注本公众号的官方读者交流群,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习💗~