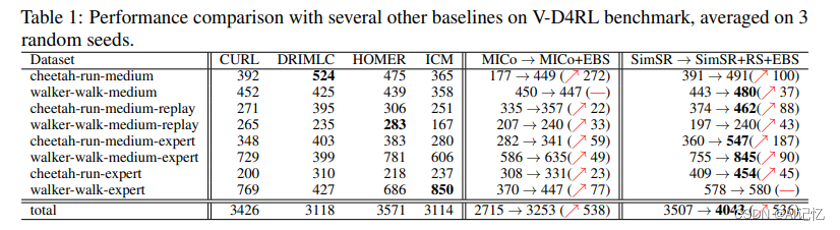
MoCoGAN: Decomposing Motion and Content for Video Generation
引用: Tulyakov S, Liu M Y, Yang X, et al. Mocogan: Decomposing motion and content for video generation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 1526-1535.
论文链接: [1707.04993] MoCoGAN: Decomposing Motion and Content for Video Generation
代码链接:GitHub - sergeytulyakov/mocogan: MoCoGAN: Decomposing Motion and Content for Video Generation
简介
视频中的视觉信号可以分为内容和运动。内容指定了视频中的对象,而运动描述了它们的动态。基于这一先验知识,我们提出了运动和内容分解的生成对抗网络(MoCoGAN)框架用于视频生成。所提出的框架通过将一系列随机向量映射到一系列视频帧来生成视频。每个随机向量由内容部分和运动部分组成。在内容部分保持固定的同时,运动部分被实现为一个随机过程。由于短视频剪辑中的内容通常保持不变,因此使用高斯分布对内容空间进行建模,并使用相同的实现来生成视频剪辑中的每一帧。从运动空间采样是通过循环神经网络实现的,在训练期间学习网络参数。为了以无监督的方式学习运动和内容的分解,引入了一种新的对抗性学习方案,利用图像和视频鉴别器。在几个具有挑战性的数据集上进行的广泛实验结果,以及与最先进方法的定性和定量比较,验证了所提出框架的有效性。此外,展示了MoCoGAN允许生成具有相同内容但不同运动的视频,以及具有不同内容但相同运动的视频。
首先,由于视频是执行各种动作的物体视觉信息的时空记录,因此生成模型除了学习物体的外观模型之外,还需要学习物体的合理物理运动模型。如果学习到的物体运动模型不正确,则生成的视频可能包含执行物理上不可能的运动的物体。其次,时间维度带来了巨大的变化。考虑一个人在进行深蹲运动时可以有的速度变化量。每种速度模式都会产生不同的视频,尽管视频中人类的外表是相同的。第三,随着人类进化到对运动敏感,运动伪影特别容易察觉。
我们认为,假设视频剪辑是潜在空间中的一个点,会不必要地增加问题的复杂性,因为具有不同执行速度的相同动作的视频由潜在空间中的不同点表示。此外,这种假设迫使每个生成的视频剪辑具有相同的长度,而真实世界视频剪辑的长度却各不相同。另一种(可能更直观、更有效)的方法是假设图像的潜在空间,并考虑通过遍历潜在空间中的点来生成视频剪辑。不同长度的视频片段对应于不同长度的潜在空间轨迹。

此外,由于视频是关于执行动作(运动)的对象(内容),因此图像的潜在空间应进一步分解为两个子空间,其中第一个子空间(content subspace)中一个点的偏差导致视频剪辑中的内容变化,第二个子空间(motion subspace)中的偏差导致时间运动。通过这种建模,具有不同执行速度的动作视频只会导致运动空间中轨迹的遍历速度不同。分解运动和内容可以更可控地生成视频过程。通过在固定运动轨迹的同时改变内容表示,我们可以获得不同物体执行相同运动的视频。通过在固定内容表示的同时改变运动轨迹,我们可以获得同一物体执行不同运动的视频,如图 1 所示。
Generative Adversarial Networks
GANs由一个生成器和一个鉴别器组成。生成器的目标是生成类似于真实图像的图像,而鉴别器的目标是将真实图像与生成的图像区分开来。设 x x x 是从图像分布 p X p_X pX中绘制的实数图像, z z z是 Z I ≡ R d Z_I ≡ R^d ZI≡Rd 中的随机向量。让 G I G_I GI 和 D I D_I DI 成为图像生成器和图像鉴别器。生成器将$ z$ 作为输入并输出一个图像 x ~ = G I ( z ) \tilde { x } = G _ { I } ( z ) x~=GI(z),该图像具有与 x x x 相同的支持。将 G I ( z ) G_I(z) GI(z) 的分布记为 $p_{G_I} $。鉴别器估计从 p X p_X pX 绘制输入图像的概率。理想情况下,如果 x ∼ p X x ∼ p_X x∼pX ,则 D I ( x ) = 1 D_I(x) = 1 DI(x)=1,如果 x ~ ∼ p ~ G I \tilde { x } \sim \tilde { p } _ { G _ { I } } x~∼p~GI,则 D I ( x ~ ) = 0 D _ { I } ( \tilde { x } ) = 0 DI(x~)=0。 G I G_I GI 和 D I D_I DI 的训练是通过求解:
max G I min D I F I ( D I , G I ) \max _ { G _ { I } } \min _ { D _ { I } } F _ { I } ( D _ { I } , G _ { I } ) GImaxDIminFI(DI,GI)
F 1 ( D 1 , G 1 ) = E x ∼ p X [ − log D I ( x ) ] + E z ∼ p Z [ − log ( 1 − D I ( G I ( z ) ) ) ] F _ { 1 } ( D _ { 1 } , G _ { 1 } ) = E _ { x \sim p _ { X } } \left[ - \log D _ { I } ( x ) \right] + E _ { z \sim p _ { Z } } [ - \log ( 1 - D _ { I } ( G _ { I } ( z ) ) ) ] F1(D1,G1)=Ex∼pX[−logDI(x)]+Ez∼pZ[−log(1−DI(GI(z)))]
Goodfellow等[1]表明,如果有足够能力的 D I D_I DI和 G I G_I GI以及足够的训练迭代, p G I p_{G_I} pGI的分布会收敛到 p X p_X pX。因此,从随机向量输入 z z z 中,网络 G I G_I GI 可以合成类似于从真实分布 p X p_X pX 中绘制的图像。
最近,[2]通过提出视频GAN(VGAN)框架,将GAN框架扩展到视频生成。设 $ v ^ { L } = \left[ x ^ { ( 1 ) } , \ldots , x ^ { ( L ) } \right]$ 是具有$ L 帧的视频剪辑。 V G A N 中的视频生成是通过用基于时空 C N N 的视频生成器和鉴别器 帧的视频剪辑。VGAN中的视频生成是通过用基于时空CNN的视频生成器和鉴别器 帧的视频剪辑。VGAN中的视频生成是通过用基于时空CNN的视频生成器和鉴别器G_{VL}$和$D_{VL}$替换基于CNN的图像生成器和鉴别器GI和DI来实现的。视频生成器 GVL 将随机向量 z ∈ Z V L ≡ R d z \in Z _ { V ^ { L } } \equiv R ^ { d } z∈ZVL≡Rd 映射到固定长度的视频剪辑 v ~ L = [ x ~ ( 1 ) , … , x ~ ( L ) ] = G V L ( z ) \tilde { v } ^ { L } = \left[ \tilde { x } ^ { ( 1 ) } , \ldots , \tilde { x } ^ { ( L ) } \right] = G _ { V^L } ( z ) v~L=[x~(1),…,x~(L)]=GVL(z),视频鉴别器 $D_{V^L} $将真实视频剪辑与生成的视频剪辑区分开来。理想情况下,如果从 p V L p_{V^L} pVL 采样 v L v^L vL,则 D V L ( v L ) = 1 D_{V^L}(v^L) = 1 DVL(vL)=1,如果从视频生成器的分布 $p_{G_{V^L}} $采样 v ~ L \tilde{v}^L v~L,则 D V L ( v ~ L ) = 0 D _ { V^L } ( \tilde { v } ^ { L } ) = 0 DVL(v~L)=0。TGAN框架[3]也将随机向量映射到固定长度的片段。不同之处在于,TGAN将表示固定长度视频的随机向量映射到表示视频剪辑中各个帧的固定数量的随机向量,并使用图像生成器进行生成。TGAN训练没有使用普通的GAN框架来最小化Jensen-Shannon散度,而是基于WGAN框架[4],并最小化了推土机距离。
Motion and Content Decomposed GAN
在MoCoGAN中,假设图像在 Z I ≡ R d Z_I≡R^d ZI≡Rd的潜在空间中,其中 z ∈ Z I z∈Z_I z∈ZI的每个点代表一个图像, K K K帧的视频由潜在空间中长度为 K K K的路径表示, [ z ( 1 ) , … , z ( K ) ] \left[ z ^ { ( 1 ) } , \ldots , z ^ { ( K ) } \right] [z(1),…,z(K)]。通过采用这种公式,可以通过不同长度的路径生成不同长度的视频。此外,通过在潜在空间中以不同的速度遍历相同的路径,可以生成以不同速度执行的相同动作的视频。
进一步假设 Z I Z_I ZI 被分解为内容子空间 $Z_C $和运动子空间 Z M Z_M ZM : Z I = Z C × Z M Z_I = Z_C × Z_M ZI=ZC×ZM,其中 $Z_C = R^ d_C , , , Z_M = R^ d_M$ , d = d C + d M d = d_C + d_M d=dC+dM。内容子空间对视频中与运动无关的外观进行建模,而运动子空间对视频中与运动相关的外观进行建模。例如,在一个人微笑的视频中,内容代表人的身份,而动作代表人的面部肌肉结构的变化。一对人的身份和面部肌肉配置代表了人的面部形象。这些对的序列代表了该人微笑的视频剪辑。通过将人的外表与另一个人的外表交换,可以表示另一个人微笑的视频。
使用高斯分布对内容子空间进行建模: z C ∼ p Z C ≡ N ( z ∣ 0 , I d C ) z _ { C } \sim p _ { Z _ { C } } \equiv N ( z | 0 , I _ { d _ { C } } ) zC∼pZC≡N(z∣0,IdC),其中 I d C I_{d_C} IdC 是大小为 d C × d C d_C × d_C dC×dC 的单位矩阵。基于对短视频剪辑中内容基本相同的观察,使用相同的实现 z C z_C zC 在视频剪辑中生成不同的帧。视频剪辑中的运动由运动子空间 Z M Z_M ZM的路径建模。用于生成视频的向量序列表示为:
[ z ( 1 ) , . . . , z ( K ) ] = [ [ z C z M ( 1 ) ] , . . . , [ z C z M ( K ) ] ] [ z ^ { ( 1 ) } , . . . , z ^ { ( K ) } ] = [ \begin{bmatrix} z _ { C } \\ z ^{(1)} _ { M } \end{bmatrix} , . . . , \begin{bmatrix} z _ { C } \\ z _ { M } ^ { ( K ) } \end{bmatrix} ] [z(1),...,z(K)]=[[zCzM(1)],...,[zCzM(K)]]
由于 Z M Z_M ZM 中并非所有路径都对应于物理上合理的运动,因此需要学会生成有效的路径,在MoCoGAN中使用递归神经网络对路径生成过程进行建模。
设 R M R_M RM 为递归神经网络。在每个时间步,它从高斯分布中采样的向量作为输入: ϵ ( k ) ∼ p E ≡ N ( ϵ ∣ 0 , I d E ) ) \epsilon ^ { ( k ) } \sim p _ { E } \equiv N ( \epsilon | 0 , I _ { d_E } )) ϵ(k)∼pE≡N(ϵ∣0,IdE)) 并输出一个 Z M Z_M ZM 中的向量,用作运动表示。设 R M ( k ) R_M(k) RM(k) 是时间 k k k 处递归神经网络的输出。然后, z M ( k ) = R M ( k ) z^{(k)}_M = R_M(k) zM(k)=RM(k)。直观地说,递归神经网络的功能是将一系列独立且相同分布的随机变量 [ ϵ ( 1 ) , … , ϵ ( K ) ] \left[ \epsilon ^ { ( 1 ) } , \ldots , \epsilon ^ { ( K ) } \right] [ϵ(1),…,ϵ(K)] 映射到表示视频中动态的相关随机变量序列 [ R M ( 1 ) , … , R M ( K ) ] \left[ R _ { M } ( 1 ) , \ldots , R _ { M } ( K ) \right] [RM(1),…,RM(K)]。在每次迭代中注入噪声可模拟每个时间步的未来运动的不确定性。我们使用单层GRU网络实现 R M R_M RM [5]。

MoCoGAN 由 4 个子网络组成,分别是递归神经网络 R M R_M RM、图像生成器 G I G_I GI ,图像鉴别器 D I D_I DI 和视频鉴别器 D V D_V DV。 D I D_I DI 和 D V D_V DV 都扮演着评判者的角色,对 G I G_I GI 和 R M R_M RM 提出批评。图像鉴别器 $D_I $专门根据单个图像批评 G I G_I GI。它被训练来确定帧是从真实视频剪辑 v v v 还是从 $\tilde { v } 中采样的。另一方面, 中采样的。另一方面, 中采样的。另一方面,D_V$ 根据生成的视频剪辑向 G I G_I GI 提供批评。 D V D_V DV 拍摄固定长度的视频剪辑,例如 T T T 帧,并确定视频剪辑是从真实视频还是从 v ~ \tilde { v } v~中采样的。与基于普通CNN架构的 D I D_I DI不同, D V D_V DV是基于时空CNN架构的。注意到剪辑长度 T T T 是一个超参数,在实验中设置为 16 16 16。还注意到 T T T 可以小于生成的视频长度 K K K。长度为 K K K 的视频可以以滑动窗口方式分成 K − T + 1 K − T + 1 K−T+1 个剪辑,每个剪辑都可以输入到 D V D_V DV 中。视频鉴别器 D_V 还评估生成的运动。由于 G I G_I GI 没有运动的概念,因此对运动部分的批评直接指向了递归神经网络 R M R_M RM。理想情况下,仅 D_V 就足以训练 G I G_I GI 和 R M R_M RM,因为 D V D_V DV 提供静态图像外观和视频动态的反馈。然而,使用 D I D_I DI 显着提高了对抗训练的收敛性。这是因为训练 D I D_I DI 更简单,因为它只需要关注静态外观。图 2 显示了 MoCoGAN 框架的可视化表示。
Categorical Dynamics
视频中的动态通常是分类的(例如,离散的动作类别:走路、跑步、跳跃等)。为了对这个分类信号进行建模,用一个分类随机变量 z A z_A zA 来增强 R M R_M RM 的输入,其中每个实现都是一个热向量。保持实现固定,因为短视频中的动作类别保持不变。 R M R_M RM 的输入由下式给出:
[ [ z A ϵ ( 1 ) ] , ⋯ , [ z A ϵ ( K ) ] ] \left[ \left[ \frac { z _ { A } } { \epsilon ^ { ( 1 ) } } \right] , \cdots , \left[ \frac { z _ { A } } { \epsilon ^ { ( K ) } } \right] \right] [[ϵ(1)zA],⋯,[ϵ(K)zA]]
为了将 z A z_A zA与真实动作类别联系起来,采用InfoGAN学习,并将目标函数扩充为 $F_V(D_I, D_V, G_I, R_M)+ λL_I (G_I, Q) $,其中 L I L_I LI 是生成的视频片段与 z A z_A zA 之间互信息的下限, λ λ λ是超参数,实现了辅助分布 Q Q Q(近似于视频片段上动作类别变量条件的分布)通过将 softmax 图层添加到 D V D_V DV 的最后一个要素图层。使用 λ = 1 λ = 1 λ=1。注意到,当标记的训练数据可用时,可以训练 Q Q Q 输出真实输入视频剪辑的类别标签,以进一步提高性能。
实验
使用 ADAM 进行训练,学习率为 0.0002,动量分别为 0.5 和 0.999。



参考文献
[1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems (NIPS), 2014. 1, 2, 3.
[2] C. Vondrick, H. Pirsiavash, and A. Torralba. Generating videos with scene dynamics. In Advances in Neural Information Processing Systems (NIPS), 2016. 1, 2, 3, 5, 6.
[3] M. Saito, E. Matsumoto, and S. Saito. Temporal generative adversarial nets with singular value clipping. In IEEE International Conference on Computer Vision (ICCV), 2017. 2, 3, 5, 6.
[4] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017. 2, 3.
[5] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Advances in Neural Information Processing Systems (NIPS) Workshop, 2014. 4.