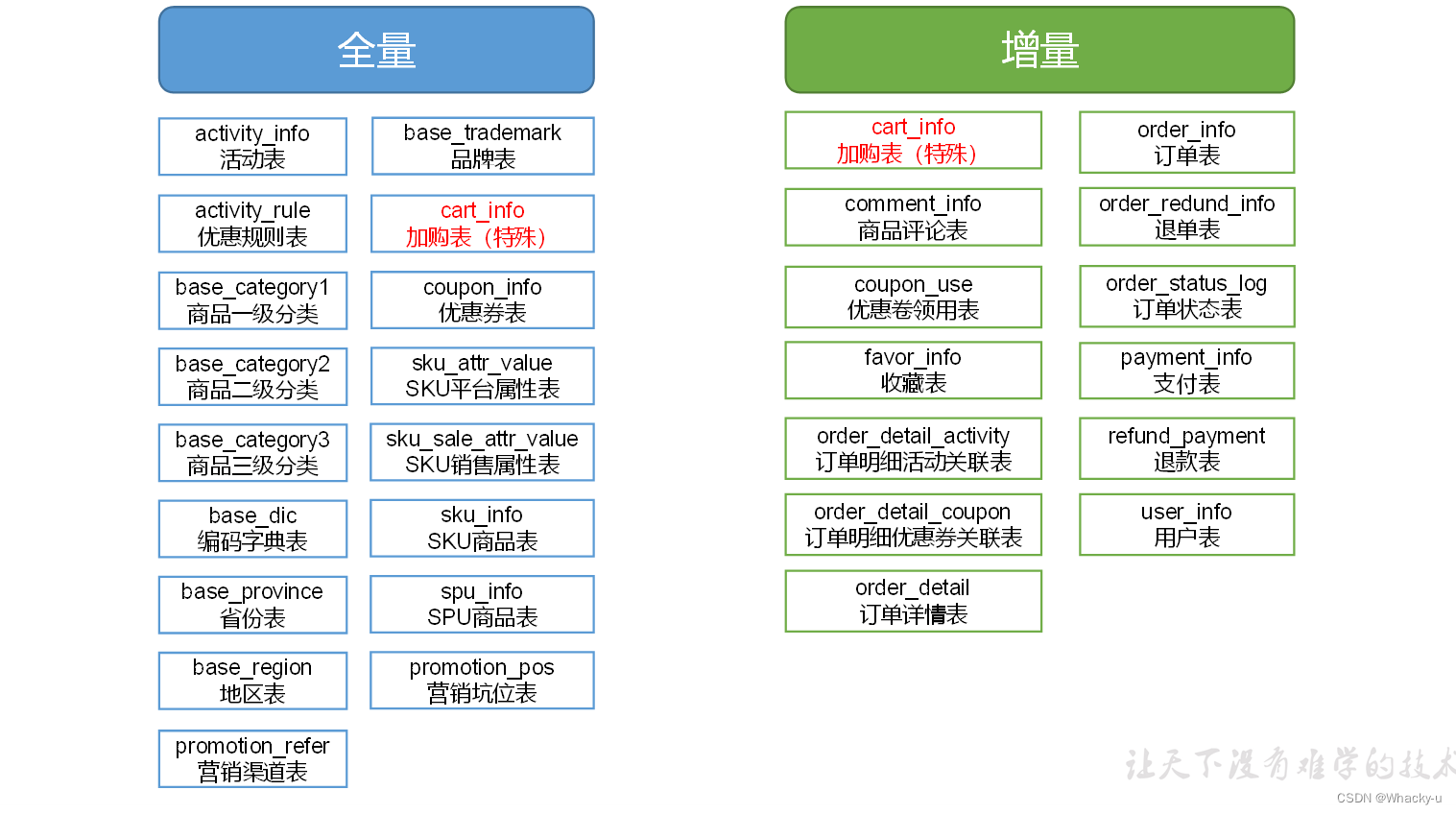
1、数据库和数据仓库的区别:
数据仓库就是data warehouse,数据小卖店,相当于是对数据加工,计算然后对外提供服务,而不是单纯的存储
2、数据流转过程中数据仓库中的数据源部分
数据源部分的数据**不是只同步数据库当前状态的数据,**因为数据库中的数据不会保存海量数据,只会保存近几年的数据,
而数据源应该是汇总数据库中的数据,就是数据库中增添一些数据就汇总到数据仓库中的数据源中,
因为数据库只保留最近一些的数据,太久远的数据会存放到磁盘中,需要的时候数据库会拉取这部分数据。
所以数据源相当于需要一个独立的部分,单独用来存储数据,数据仓库不会直接从数据库拉取数据
3、需要明确的是,项目分为采集部分和数据仓库部分,是两个相互独立的部分
1、采集
架构部分可以看第一个讲义文件,有项目架构的介绍,版本的介绍,和搭建集群的思路【这个主要了解一下就可以】
采集涉及两部分:行为数据和业务数据。
业务数据通过MySQL存储,而行为日志数据通过对日志文件处理使用flume以及kafka存储到集群中
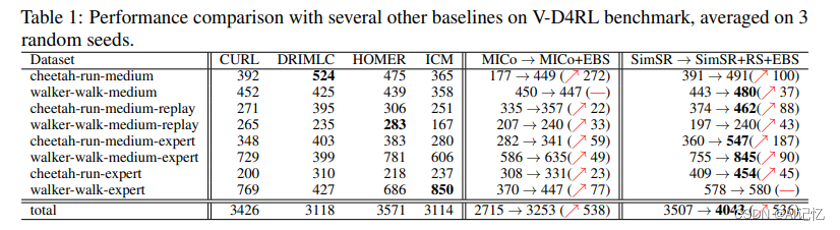
- 系统数据流程图:
1.1、行为数据
1)行为日志
// 第一份讲义的第8页开始
这部分行为日志是json文件
所以如果想要用的话,需要将文件转成一行的格式,就是一长行
因为在hive或者spark中,加载数据到表格中,解析数据的时候,就是只能解析一行json文件
// 这里可以用插件fehelper,进行整理json代码
用户行为日志的内容,主要包括用户的各项行为信息以及行为所处的环境信息。
收集这些信息的手段通常为埋点。
行为日志分为两类: 页面日志、启动日志
1、页面浏览日志
- common : 环境信息
- actions : 动作信息
- displays : 曝光信息
- page : 页面信息
- err : 错误信息
- ts : 进入当前页面的时间戳
2、App启动日志
- common : 环境信息
- start : 启动信息
- err : 错误信息
- ts : 启动app的时间戳
2)行为数据采集模块
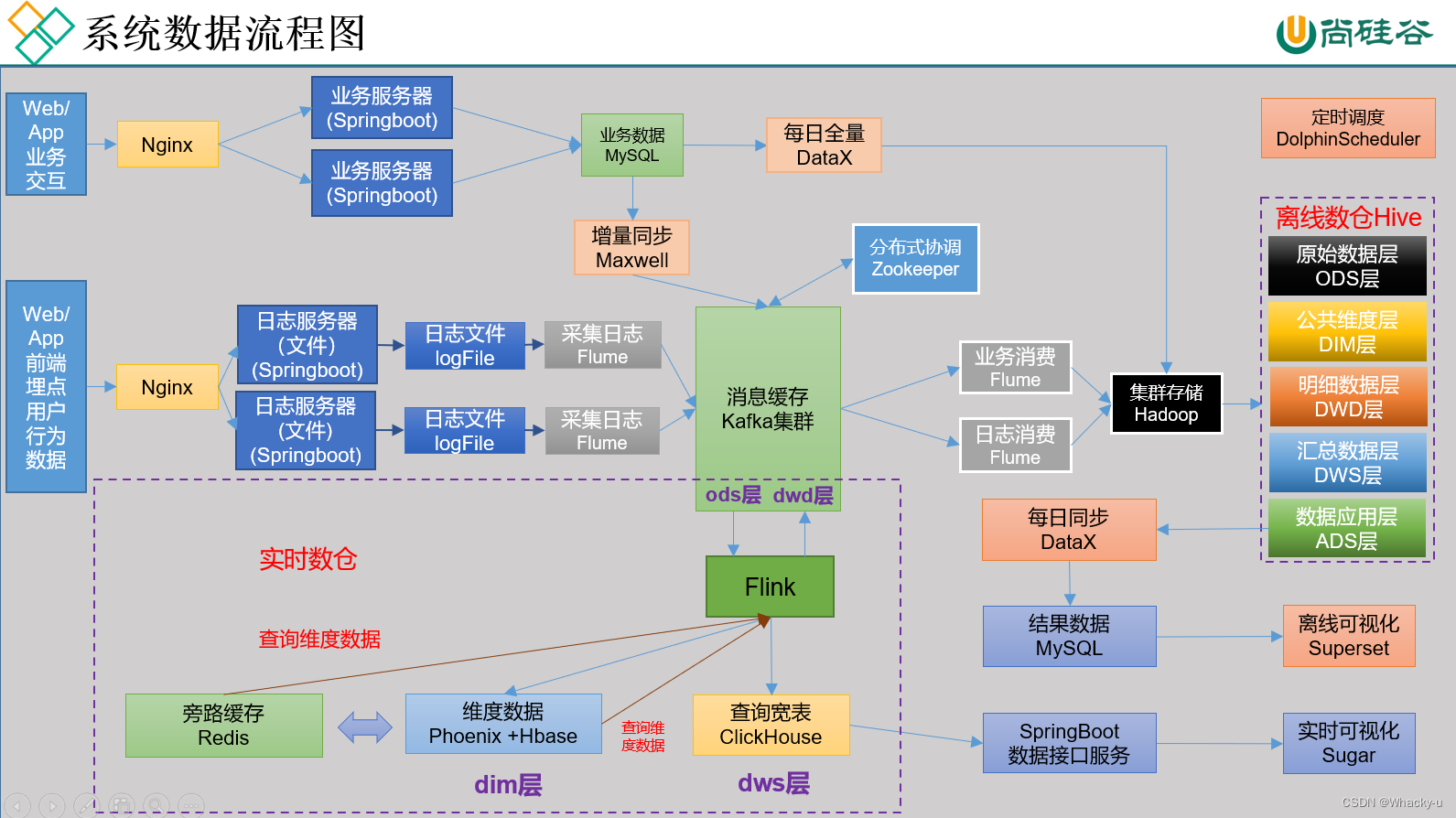
1、模块流程图
2、按照上图描述安装步骤
-
安装虚拟机,这里可以用课程资料里的模板机hadoop100,也可以用自己的hadoop_base
-
之后克隆三台虚拟机,这里我们是hadoop106、hadoop107、hadoop108。更改主机名,ip地址,ip映射,主机映射
-
设置免密登录
-
安装JDK
-
数据模拟:
这个指的是,我们项目用到的行为日志和业务数据都是我们自己模拟的,这是需要java程序或者mysql数据,我们按照上图中的lg.sh脚本,已经将相关的java程序和配置文件加载到文件夹applog中
-
安装hadoop、zookeeper、kafka、flume
【
需要先装zookeeper再安装kafka,因为需要先启动zookeeper才能启动kafka。另外hadoop、zookeeper、kafka是集群搭建。意思是三台主机都需要,并且进行相应配置。
**而flume是单点的,哪里需要就在哪里装,**就是一个传数据的。另外在配置flume的时候,选择TailDirSource和KafkaChannel,不要sink了
比如我们如果在hadoop106这台主机上装了模拟数据生成的程序,生成数据后我们需要将数据上传到hdfs,这就只需要在hadoop106上装有flume
】
-
flume日志采集配置
- 因为我们行为日志产生的程序,也就是模拟数据生成的java程序装在了hadoop106上,所以flume也装在hadoop106上。但因为模拟数据生成的日志json文件是竖着的,我们需要排列成一长行的样子,后面才可以用上,所以我们需要在flume的source部分加上一个拦截器进行处理数据
- 编写flume配置文件,我们只需要taildir的source,以及kafka类型的channel
- 之后先启动zookeeper,然后是启动Kafka,再启动flume
- 就可以模拟数据了,lg.sh test 100 ,就会通过模拟数据生成的数据经过flume自动存到kafka中,之后如果想要实时处理或者离线处理,都可以从Kafka中拿去数据进行处理,计算
1.2、业务数据
首先需要安装MySQL,这里有脚本,可以直接使用
但是最后更改权限部分需要自己再单独执行以下,就是脚本中有部分没有发挥作用
mysql -uroot -p000000 -- 登录MySQL
-- 然后执行下面两个命令
alter user 'root'@'%' identified with mysql_native_password by '000000';
flush privileges;
1)模拟数据
使用远程连接软件连接上数据库后,将数据库脚本文件gmall导入,里面都是表结构和一些默认数据
后续会通过模拟程序,继续生成业务数据
gmall中会有所有的表结构文件
但是只有必要的数据,并不是所有的表都有数据,之后还是需要json模拟生成数据加到数据库中
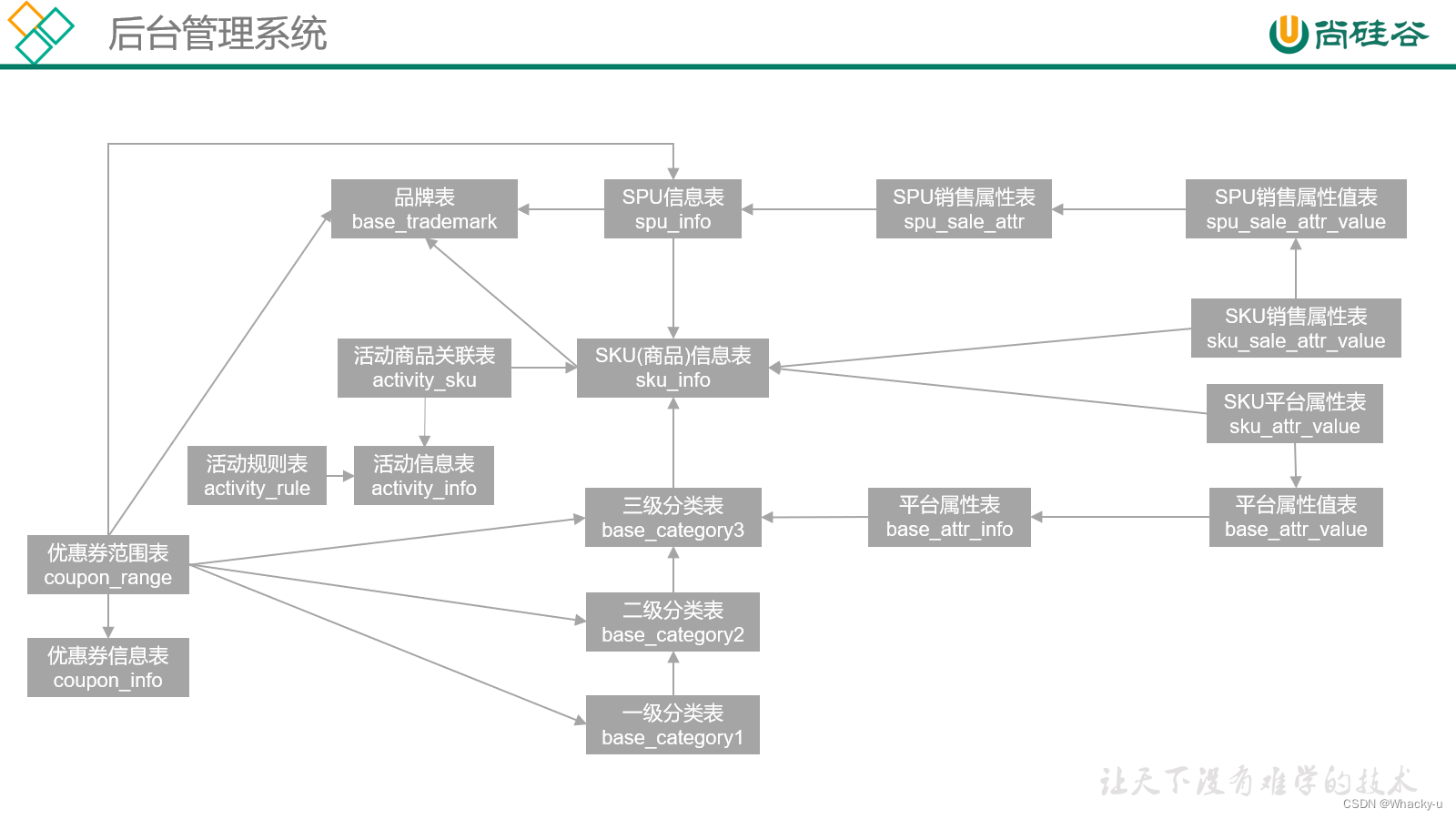
2)业务结构关系
主要涉及电商业务以及后台管理两部分
// 看业务数据部分讲义的第13页
补充一个知识点:
对于支付表中的数据,在订单下单时自动插入支付记录,这是一个系统自动执行的操作,通常不会被认为是每日的增量数据。原因在于,这种插入操作是订单下单时自动触发的,而不是在每日的数据处理流程中产生的。
每日的增量数据通常指的是在每日的数据处理过程中,通过比较昨日和今日数据的差异,来确定今日新增、更新或删除的数据。而订单下单时自动插入支付记录这个操作通常不会被包括在这个范畴内,因为它不是在每日的数据处理过程中产生的变化。
所以,虽然订单下单时会有支付记录插入,但这个操作不会被当做每日的增量数据。相反,每日的增量数据更关注于每日数据处理周期内的变化,比如订单状态的更新、支付状态的改变等。
1.3、数据采集流程
【不过这个hadoop启动的脚本不是 hdp.sh 而是hadoop.sh】
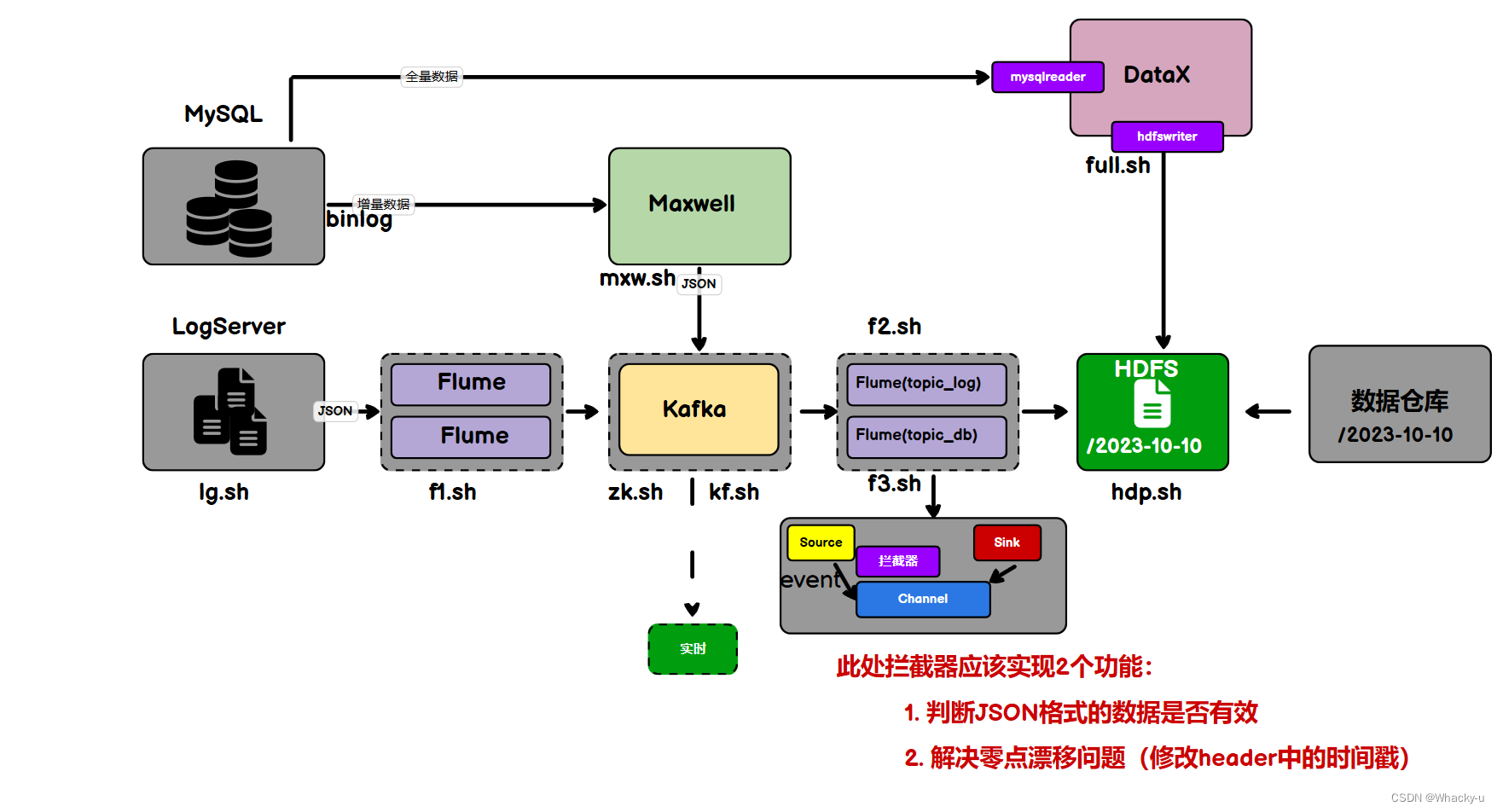
增量数据主要用于实时数仓的处理
全量数据是离线数仓项目中用到比较多的
另外这两个数据采集的软件各不相同,Maxwell是用于采集增量数据然后放置于Kafka中用于实时数仓的项目处理
1)Maxwell同步数据
先打开zookeeper,然后打开Kafka,执行msw.sh脚本,运行Maxwell,开始同步数据
但是历史数据的同步分为全量和增量数据的同步,直接执行msw.sh脚本是实时同步MySql的变更数据【增量数据】
但有时只有增量数据是不够的,我们可能需要使用到MySQL数据库中从历史至今的一个完整的数据集。这就需要我们在进行增量同步之前,先进行一次历史数据的全量同步。这样就能保证得到一个完整的数据集。
/* 但其实业务数据去采集全量数据可以用不同的软件,不是用Maxwell !!!!!!!!!!!! */
//提供了一个bootstrap功能
// 这个可以同步一张表得全部数据
/opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table activity_info --config /opt/module/maxwell/config.properties
//但是上面的table 后面跟的是需要同步的表名字,需要自己根据情况去更改
2)业务数据部分需要另外一个flume进程
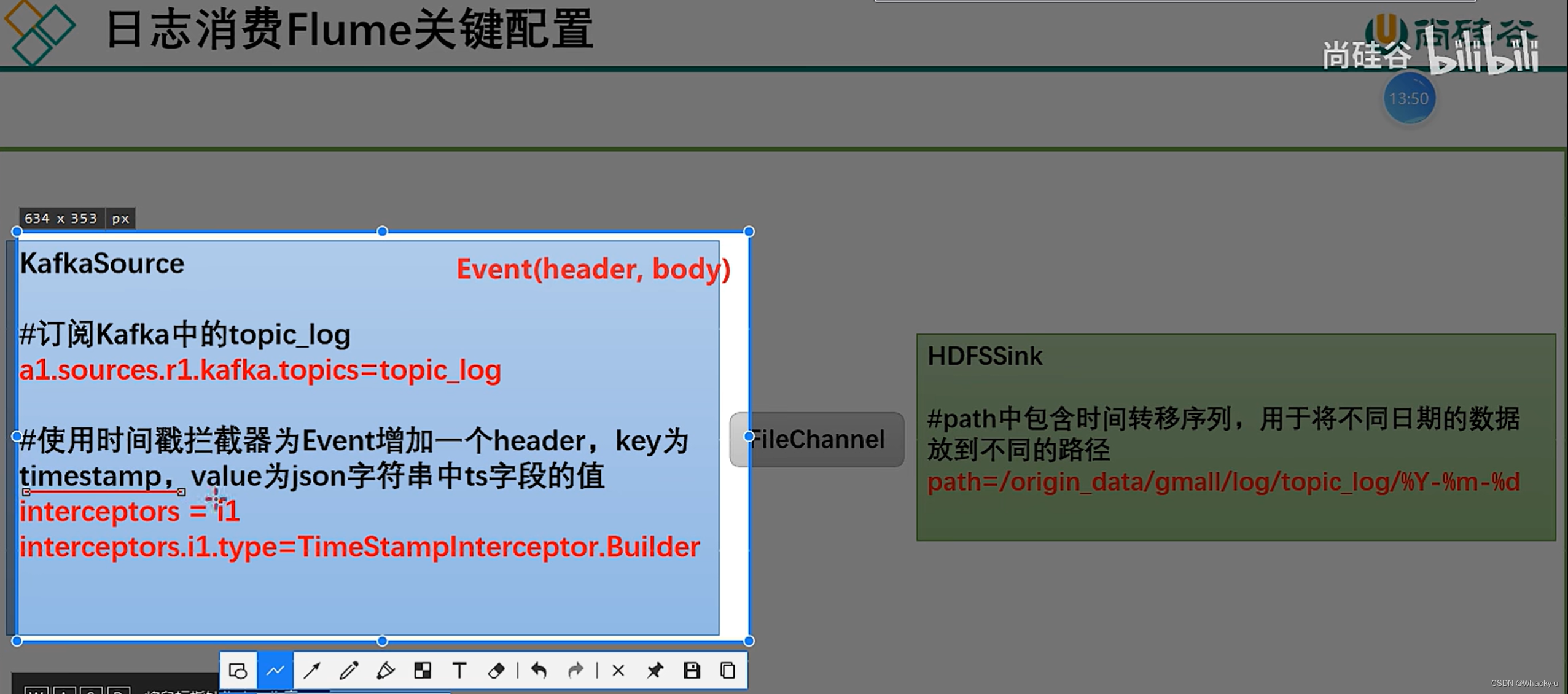
这是在hadoop107上面,不是Hadoop106上进行配置
但是这里有一个零点漂移的问题。就是有一个几秒的时间差,就会把文件存储错位置,因为他是按照时间戳【这是flume采集到数据自动加上的时间戳】,时间,就是具体的日期去存储的,可以看下面的图
解决方式就是通过加上一个拦截器
这样就会让时间戳,也就是header的时间和body的时间是一样的
所以最后加上拦截器的目的就是保证时间一致,另外json的格式是正确的

这里从kafka中拉取得数据只有行为数据,可以看flume配置文件中,拉去Kafka中得主题只是行为数据得主题
之后会通过别的软件拉取业务数据得全量数据
// 配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop106:9092,hadoop107:9092,hadoop108:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder
1.4、数据同步策略
本项目中,全量同步采用DataX,增量同步采用Maxwell
1)增量方案对比

2)dataX同步全量数据(存在两种模式)
解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
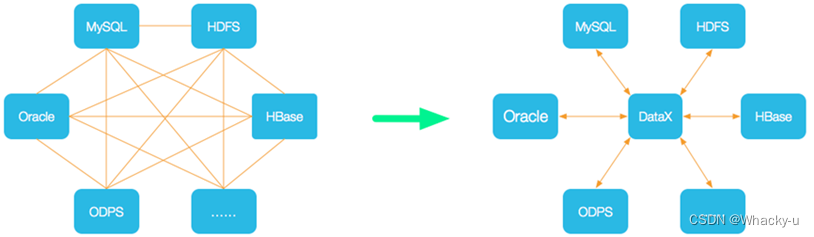
使用方法还是比较简单的,只需根据自己同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中,然后执行如下命令提交数据同步任务即可。
但是需要注意的是,使用dataX的时候,一定要先提前在hdfs中创建目标路径下需要的文件夹!!!!!,否则会提示找不到目标路径
python bin/datax.py path/to/your/job.json //最后这个json文件名是自己定义的
//可以使用如下命名查看DataX配置文件模板。
python bin/datax.py -r mysqlreader -w hdfswriter //其中setting用于对整个job进行配置,content用户配置数据源和目的地。
在讲义中举了例子,MySQL同步到hdfs中
需要注意的是,null值的处理
//这部分去看同步数据讲义的第7-8页
MySQLreader这里分为两种模式,一种是写清楚详细的id属性的TableMode,另一种是在json中写查询语句即可的QuerySQLMode,在编辑好json文件后,按照模板编写
之后就是运行,可以直接输入命令行
python bin/datax.py job/base_province_sql.json //后面job/base_province_sql.json,是路径和自己编写的文件名
3)dataX传参
dataX是可以传参的
通常情况下,离线数据同步任务需要每日定时重复执行,故HDFS上的目标路径通常会包含一层日期,以对每日同步的数据加以区分,也就是说每日同步数据的目标路径不是固定不变的,因此DataX配置文件中HDFS Writer的path参数的值应该是动态的。为实现这一效果,就需要使用DataX传参的功能。
DataX传参的用法如下,在JSON配置文件中使用${param}引用参数,在提交任务时使用-p"-Dparam=value"传入参数值,具体示例如下。
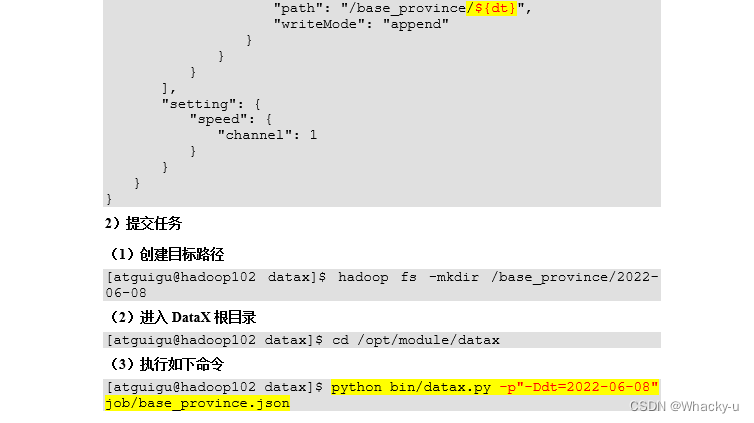
4)dataX同步全量数据
由于dataX同步数据需要类似flume一样的配置文件,但是每一个配置文件都需要写数据库中表的格式
有很多表,每一个表都需要写列名字和属性类别,比较多,所以就写了一个dataX配置生成器,这里由于数据库是在hadoop106上,所以把代码中的主机名改成hadoop106,在资料中的就是已经改好的
之后编写一个脚本文件,就可以执行命令,对17张表使用datax进行同步全量数据
// 在同步数据的讲义第11到18页
5)增量表数据同步
// 在第三个同步数据的讲义中第19页到26页
1、同步从Maxwell获取的MySQL业务增量数据
-
配置kafka到hdfs的flume配置文件,之前配置的Kafka到hdfs的是关于行为日志数据的,现在是关于业务增量数据的,这个的脚本命令是叫做:f3.sh。【Flume需要将Kafka中topic_db主题的数据传输到HDFS】
-
另外需要编写拦截器。
这个是涉及到时间戳的问题,因为使用Maxwell会涉及到一个ts的参数,不像行为日志采集的时候直接把时间就获取到,Maxwell获取时间不是操作时间,是因为他涉及到一系列步骤,从你写下sql语句,到binlog获取时间,再到Maxwell获取时间,再去链接MySQL等等不像行为数据直接同步数据,因为sql涉及到代码操作和连接mysql以及sql语句生效运作这些环节
另外,就是我们在对表进行同步的时候,涉及到多个表,不像行为日志,就是只有一个日志文件,在Kafka中也就是一个主题,主题下不用再去划分,所以需要获取各个表的名字,所以就需要编写拦截器
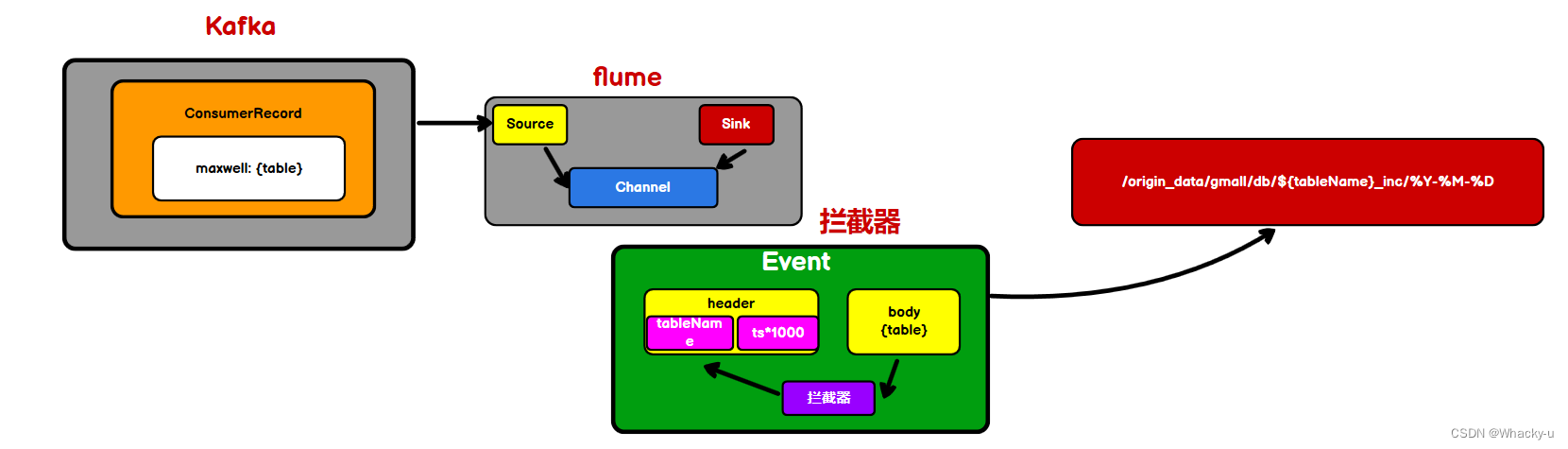
2、增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
就是之前说的那个bootstrap

1.5、采集流程总结
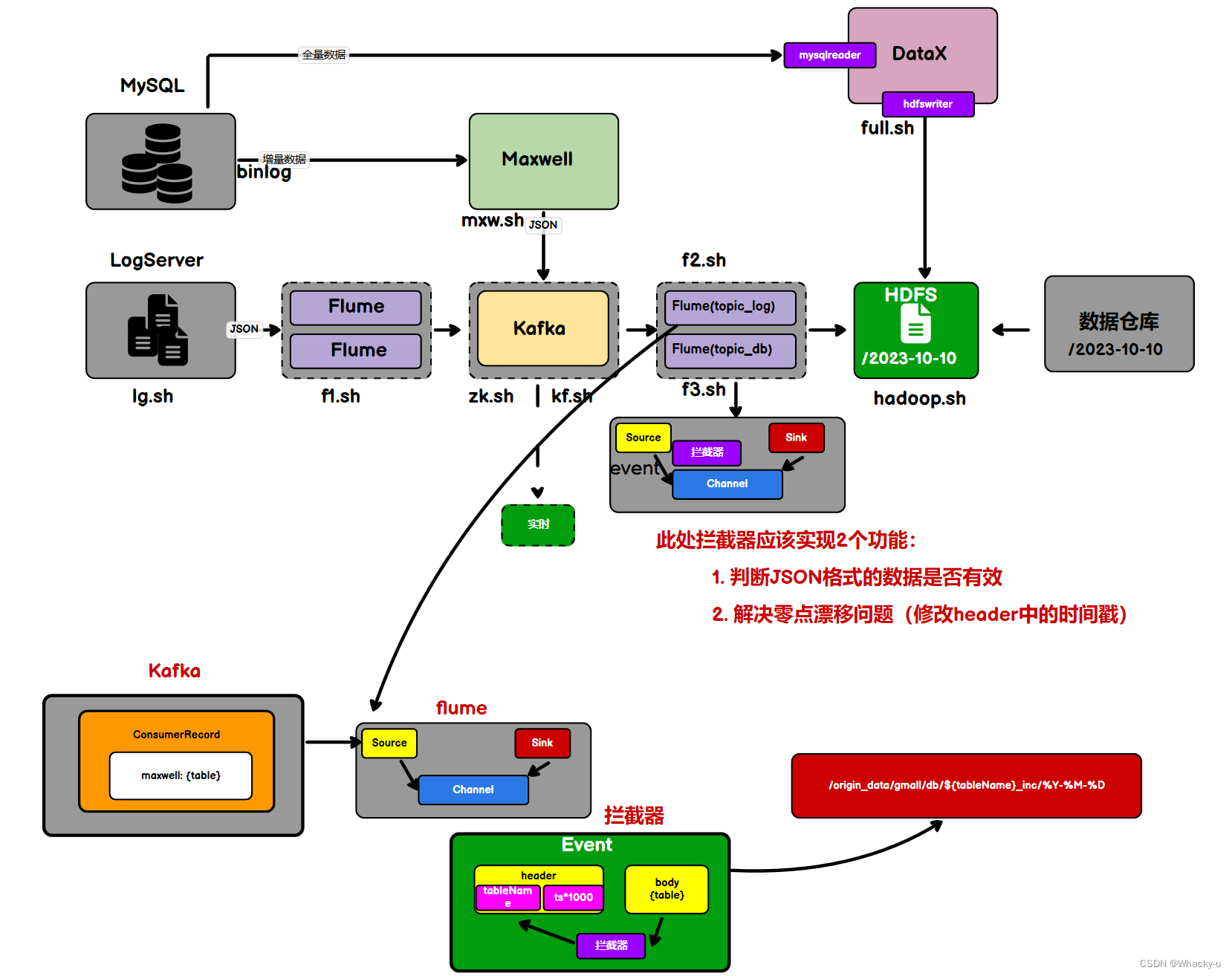
涉及两类数据:行为数据(行为日志)、业务数据(MySQL)
这两类数据,都是通过模拟数据的程序生成,通过脚本文件执行lg.sh,模拟生成行为日志数据和业务数据。
日志数据生成后直接写入/opt/module/applog/log目录下,而业务数据是在下载配置好MySQL后创建名为gmall的数据库,直接将业务数据通过jdbc远程连接,写入数据库中对应的表中
业务数据还需要注意的一个是,它分为增量数据和全量数据,增量数据是通过Maxwell写入到Kafka中,之后Kafka可以通过flume流到hdfs,这一部分的hdfs承载两部分数据,业务数据的增量数据,以及行为日志的数据
增量数据的同步操作还分为两步骤,分别是第一日的全量数据同步,是使用的Maxwell中的bootstrap,之后便是每日的增量数据同步。
另外业务数据的全量数据同步,是利用的dataX,这个是类似flume的一个程序文件,配置好即可使用,只不过每一个表都需要一个配置文件,所以我们就用java写了一个配置文件生成器,因为配置文件需要的其实就是表的名字和id名字和属性类别,
使用编写好的拦截器,运行java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar
有多少表就会生成多少表的json配置文件
编写使用好的配置文件运行的脚本,就可以执行dataX了,使用命令 full.sh all。这样就可以做到将表中全量数据统一同步到hdfs中
需要明确的是,业务数据分为:增量数据和全量数据,这两类数据分别拥有一些表,没有重复,因为有的表适合增量处理,有的表适合用全量数据去处理。在hdfs中增量数据后面文件名会加上一个“inc”,而全量数据会加上一个“full”