一、论文
本文介绍被机器学习顶级国际会议NeurIPS 2023接收的论文 "Understanding and Addressing the Pitfalls of Bisimulation-based Representations in Offline Reinforcement Learning",https://arxiv.org/abs/2310.17139
开源代码
https://github.com/zanghyu/Offline_Bisimulation
二、背景
1.)强化学习中的状态表示学习
强化学习作为机器学习基本模式之一受到了广泛的关注,然而当考虑到更贴近现实的控制任务时,深度强化学习方法的适用性仍然受到制约,这主要是由于强化学习智能体与环境的交互方式的限制。因为现实世界中,许多应用都是基于高维传感器输入的,如图像等数据。在这种高维观测空间进行强化学习的策略更新往往导致样本效率的降低,进而加大了对数据量的需求,弱化了深度强化学习的应用潜力。原则上,能够有效抽象高维观测数据并提升深度强化学习样本效率的方法是状态表征学习。状态表征学习, 与无监督学习中的表征学习算法类似,是将智能体在环境当中的观测通过一定的辅助任务映射到低维表征空间的方法,其使用的辅助任务能够通过引入一定归纳偏置进而令映射后的低维表征存在某些特定特征。
2.)考虑因果不变性的互模拟表示学习算法
因果不变性,即给定一系列特征时,我们只关注在不同条件下与目标变量始终必要相关的特征,基于这些不变特征上构建的预测器理论上能够很好地推广到数据分布中所有可能的变化。考虑因果不变性的状态表征方法的核心技术手段是利用类似于自监督学习的算法,通过预定义的辅助任务使智能体学到与强化学习任务相关的环境内在结构和特征。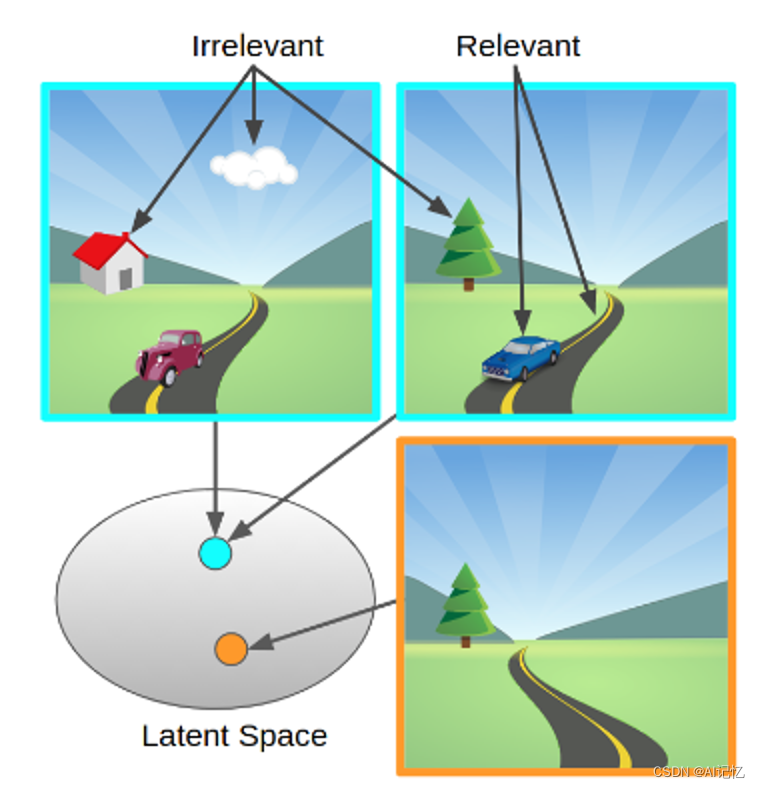
图片来自DBC论文[1]
如图所示,在一个驾驶任务中,需要区分出哪些特征是和任务相关的(如,道路,车),哪些是无关的(如,房子,树)等信息。对于该驾驶任务而言,上面两幅图对应的状态应该在特征空间内非常接近,因为它们与任务相关的信息基本完全一致;而右下角的图由于既没有车,道路形式也与上面两幅图不同,因此在特征空间中的距离应该和上面两幅图的较远。这类问题其实核心是在考虑表征与控制任务之间的关系,确切的说,是考虑的表征的因果不变性。这其中最具有代表性的算法为以互模拟度量为核心的表示学习算法[1,2,3]。其中,以SimSR算法[3]为例,给定奖励函数r(x,a),转移函数P(⋅|x,a),策略π 的情况下,有:
从该式可以看出,该算子可以通过迭代更新达到不动点,而达到该不动点时表示这个算子对应的表征ϕ(x)和ϕ(y) 能够表示图像观测x 和y 在隐空间上的距离,而这个距离是通过两个状态的奖励之差以及他们对应的下一状态之间的距离来加权得到的。DBC算法[1]、MICo算法[2]、SimSR算法[3]等以互模拟为核心的算法都在强化学习上取得了不错的效果,大幅提高了强化学习的样本效率。
3.)离线强化学习
一般而言,强化学习算法往往需要大量的数据才能实现最佳性能。在收集数据成本高昂的情况下,离线强化学习方法通过学习以前收集的数据中的有效策略, 提供了一种有吸引力的替代方案。然而,从有限的数据中捕捉环境的复杂结构仍然是离线强化学习方法面临的挑战。这涉及到在离线数据上预训练状态表征, 然后在固定表示上学习策略。虽然受到各种动机的驱使,以前的方法主要可以分为两类:i)通过预测和控制环境的某些方面的辅助任务来隐式塑造代理对环境的表示,例如,最大化访问状态的多样性[4,5],依据子轨迹上的不同样本的关注度进行对比学习[6],或者捕捉环境的时间相关信息[7];ii)利用行为度量(如互模拟度量)通过评估状态表征上行为的相似性,来捕捉环境中的复杂结构。 前一种方法在离线强化学习设置中理论和实践上都验证了它们的有效性,而 后一种方法在数据有限的情况下的适应性尚不清楚。
三、方法
1.)Motivation
多个最近的研究表明,在离线任务上,相比 各种自监督目标而言,基于互模拟的算法的结果明显较差。通过建立贝尔曼算子和互模拟关系算子之间的联系,我们发现在离线环境中经常出现的transition的缺失可能会破坏互模拟原则。这意味着在有限数据集上互模拟估计可能失效。 具体来说,我们定义互模拟误差和互模拟贝尔曼残差如下:
接着我们可以建立二者之间的联系,以实现互模拟理论的实际应用:
因此我们可以通过最小化互模拟贝尔曼残差来最小化互模拟误差。此外,在数据集固定且有限的情况下,有以下定理:
这代表应用互模拟算子并最小化相关的互模拟贝尔曼残差并不能保证学得的表征对下游任务足够充分。理想情况下,如果我们能够获取不动点,那么我们就可以直接最小化近似值和不动点之间的误差(即互模拟近似误差)。然而,由于数据集的静态性和不完整性,明确获取不动点是不可行的。
2.)Method
2.1)Expectile-based Bisimulation Operator
我们借助统计学中的expectile概念来让固定数据集上的互模拟算子尽量实现“样本内更新“的效果,以尽量避免数据集外样本的外推误差错误。因此我们定义算子如下: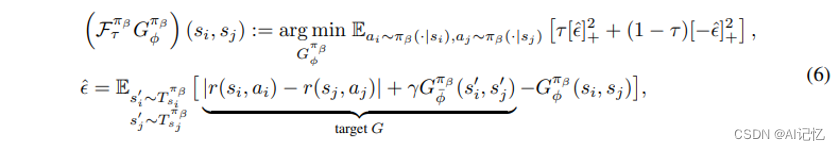
根据该式,我们可以得出以下引理及定理:
该式说明,当𝜏 →1 时,我们实际上是在对数据集中的动作(a'i,a'j)近似求取最大的G∼((si,ai),(sj,aj))。当 我们设定 𝜏 = 1 时,基于期望分位数的互模拟算子实现了完全的样本内学习,即我们只考虑在数据集中具有对应动作的状态对;当𝜏 →0.5 时,该式退化为原本的互模拟等式,变为行为策略的互模拟贝尔曼残差的期望。
2.2)Reward Scaling
此外,我们额外分析了reward scale对bisimulation operator的影响。具体来说:
我们可以建立拟合价值函数的边界:
他们说明了确保与互模拟度量的实例化保持一致,然后选择最大可能的reward scale来最小化状态价值误差是至关重要的。
四、实验结果
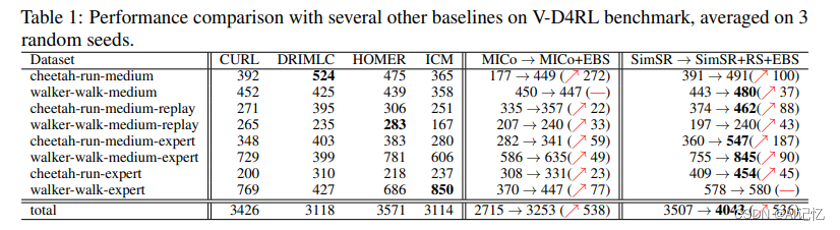
我们在基于物理状态输入的D4RL数据集和基于图像输入的V-D4RL数据集上分别进行了测试,测试结果如下:
五、展望与应用
强化学习中的表征学习对于控制任务而言至关重要,将来的一个重要研究方向是将大模型为基础的文本或图像信息与控制任务对应的状态表征做进一步对齐。这里,互模拟为基础的表征算法可能是一个重要的未来研究方向,可能对多模态数据与控制任务的对齐起到关键性作用。
六、参考:
[1]: Amy Zhang, Rowan Thomas McAllister, Roberto Calandra, Yarin Gal, Sergey Levine: Learning Invariant Representations for Reinforcement Learning without Reconstruction. ICLR 2021
[2]: Pablo Samuel Castro, Tyler Kastner, Prakash Panangaden, Mark Rowland: MICo: Improved representations via sampling-based state similarity for Markov decision processes. NeurIPS 2021: 30113-30126
[3]: Hongyu Zang, Xin Li, Mingzhong Wang: SimSR: Simple Distance-Based State Representations for Deep Reinforcement Learning. AAAI 2022: 8997-9005
[4]: Hao Liu, Pieter Abbeel: Behavior From the Void: Unsupervised Active Pre-Training. NeurIPS 2021: 18459-18473
[5]: Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, Sergey Levine: Diversity is All You Need: Learning Skills without a Reward Function. ICLR (Poster) 2019
[6]: Mengjiao Yang, Ofir Nachum: Representation Matters: Offline Pretraining for Sequential Decision Making. ICML 2021: 11784-11794
[7]: Max Schwarzer, Nitarshan Rajkumar, Michael Noukhovitch, Ankesh Anand, Laurent Charlin, R. Devon Hjelm, Philip Bachman, Aaron C. Courville: Pretraining Representations for Data-Efficient Reinforcement Learning. NeurIPS 2021: 12686-12699