part 1:
C++中new的用法(不过就是)如下(几种用法):
1: new<数据类型>
分配:
指定类型的,大小为1的,内存空间;
int *i = new int;
//注意!如果写:
//int i = new int;
//不行,会报错2: new<数据类型>(<初值> )
分配:
指定类型的,大小为1的,内存空间;用括号中的值初始化变量
int *i = new int(2);3:new<数据类型>[<内存单元个数>]
分配:
指定类型的,大小为(方框内数字)n的,内存空间
用方框中的数字n:初始化空间的大小(数组元素个数)
内存形式为数组
int* i = new int[5]; char* i = new char[5];附:part1
定义多维数组变量或数组对象,产生一个指向数组首个元素的指针
返回的类型:保持 除最左边维数外的 所有维数
int *p1 = new int[10];
返回一个指向int型的指针int*
int (*p2)[10] = new int[2][10];
返回一个,指向int[10]这样的一维数组的,指针int (*)[10]
int (*p3)[2][10] = new int[5][2][10];
返回一个指向二维数组int[2][10]这种类型的指针int (*)[2][10]
但是我们在这里需要特别提醒(注意):
在这里我们无论是上述三种情况中的哪一种情况
在new语句的赋值语句的左侧的变量,无论如何情况:
这个变量都是,都只能是,都必须是一个指针!!!
而并不像是在我们后面在数据结构的
数据结构与算法基础(王卓)(5):关于(单)链表较复杂的操作_宇 -Yu的博客-CSDN博客
当中说的那样,开辟的空间类型可以直接在赋值语句左侧直接有该类型的变量
左侧只能放置指向该类型的指针!!!
附:part2
C++中new动态创建二维数组的一般格式:
TYPE (*p)[N] = new TYPE [][N];
p的类型:TYPE*[N];即:指向一个有N列元素数组的指针
不指定数组的列数(创建二维数组):
int **p;
例:
int **p = new int* [10];
//int*[10]表示一个有10个元素的指针数组
for (int i = 0; i != 10; ++i)
p[i] = new int[5];不写new和用new的部分区别:
必须需要指针接收,一处初始化,多处使用
前面所说的:
在new语句的赋值语句的左侧的变量,无论如何情况:
这个变量都是,都只能是,都必须是一个指针!!!
指的就是我们这里说的,用来接收的指针
需要delete销毁
new创建对象直接使用堆空间而局部不用new定义对象则使用栈空间
new对象指针用途广泛,比如作为函数返回值、函数参数等
频繁调用场合并不适合new,就像new申请和释放内存一样
例:
用new创建对象:(pTest:用来接收对象指针)
int* pTest = new int();
delete pTest;不用new创建对象:(直接用声明定义)
int mTest;不用new创建对象,使用完后不需要手动释放(写delete函数)
类的析构函数会自动执行(释放操作)
而new申请的对象,只有调用到delete时才会执行析构函数
如果程序退出而没有执行delete则会造成内存泄漏
用new创建对象时释放类指针:
int* pTest = false;类指针如果未经过对象初始化,则不需要delete释放
part 2:
中,需要建一个新表来返回两表合并后的结果(最终合并后的表):
1.1:
最开始我们想得很简单,就是利用实参把新表传回去:
int Merge(Sqlist A, Sqlist B, Sqlist& C)
{
Sqlist* C = new Sqlist;
//验证我们开辟空间出来以后的C
//是一个线性表还是一个指针
Sqlist D;
D = C;
return true;
}但是此时的这个验证开辟空间的C是线性表还是指针的设计还存在一个问题(纰漏):
我们哪怕删了这里开辟空间的语句
Sqlist* C = new Sqlist;依然不影响最后程序运行的结果(成功)
1.2:
取消形参线性表C,验证我们单独开辟创建的C是指针还是线性表:
int Merge(Sqlist A, Sqlist B)//, Sqlist& C)
{
Sqlist* C = new Sqlist;
Sqlist D;
D = C;
}结果:
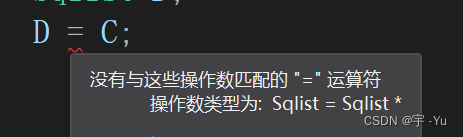
这无疑说明了,我们new的C是一个指针,依然符合我们前面所介绍的new语句的基本格式规范
所以,想要程序运行成功(修改这个错误),只需要将其中的赋值语句改为:
D = *C;即可正确运行;注意(切记):
这里在C前面加的符号必须是“ * ”,而不能是“&”
我们总是习惯性地在地址前面去加“&”,那是我们忘了:
&是取址运算符
*才是取值运算符
2:
我们也可以直接设置返回合并以后的表:(这样就不用再设置一个实参来返回新表了)
Sqlist Merge(Sqlist A, Sqlist B)
{
Sqlist* C = new Sqlist;
return *C;
}
3:
前面我们一直都在自己写开辟空间的函数语句,但是到这里我们才突然发现:
我们前面已经写了初始化的InitList( )函数了,所以直接写初始化函数就行:
int Merge(Sqlist A, Sqlist B, Sqlist& C)
{
InitList(C);
return true;
}当然,我们也可以根据(参考)前面我们写的初始化的函数的定义,手写初始化语句:
4.1:
原InitList函数中指针传值的写法:(指针传值)
int Merge(Sqlist A, Sqlist B, Sqlist *C)
{
C.elem = (Poly*)malloc(MAXlength * sizeof(Poly*));
if (!C.elem)
exit(OVERFLOW);
C.length = 0;
return OK;
}4.2:
原InitList函数中引用传值的写法:(引用传值)
int Merge(Sqlist A, Sqlist B, Sqlist& C)
{
C.elem = new Poly[100]; //在堆区开辟动态内存
if (!C.elem)//分配失败
exit(OVERFLOW);
C.length = 0;
return OK;
}
关于线性表的初始化的每一步操作的详细解释和分析,详见:
数据结构与算法基础(王卓)(2):线性表的初始化_宇 -Yu的博客-CSDN博客(的结尾)
part 3:
new:
详见:C语言日记 26 指针与函数,动态存储分配_宇 -Yu的博客-CSDN博客
例6-10 开辟空间以存放一个二维数组。
源程序:
#include <iostream>
using namespace std;
int main()
{
int i, j;
int** p;
p = new int* [4];
//开始分配4行8列的二维数据
for (i = 0; i < 4; i++)p[i] = new int[8];
for (i = 0; i < 4; i++) //给二维数组放入数据
{
for (j = 0; j < 8; j++)p[i][j] = j * i;
}
//打印数据
for (i = 0; i < 4; i++)
for (j = 0; j < 8; j++)
{
if (j == 0) cout << endl;
cout << p[i][j] << "\t";
}
for (i = 0; i < 4; i++)
delete[] p[i];
delete[] p;
return 0;
}//1
结果:

这里的
p = new int* [4];
他想表示的,应该就是所谓
int(*p)[8];
的这个意思,但是对于开辟二级(维)指针空间的使用规则和规范,书上没有明确说明,比如:
p = new int(*p) [4];
就不行:
所以,开辟这种多维指针类型的二级(维)指针空间的使用规则和规范到底是什么?!
当使用new运算符定义一个多维数组变量或数组对象时,它产生一个指向数组第一个元素的指针
返回的类型保持了除最左维数外的所有维数。例如:
int* p1 = new int[10];
开辟了一个一维数组,返回一个指向该int型存储空间的地址(即指针)(int* )
int(*p2)[10] = new int[2][10];
开辟了一个二维数组, (去掉最左边那一维[2], 剩下int[10], 所以)
返回的是一个指向int[10]这种一维数组型存储空间的地址(即指针)(int (*)[10] )
下面,我们再延展(拓展)至三维:
int(*p3)[2][10] = new int[5][2][10];
开辟了一个三维数组, (去掉最左边那一维[5],剩下int[2][10], 所以)返回的是一个指向int[2][10]这种二维数组型存储空间的地址(即指针)(int (*)[2][10])
C++中用new动态创建二维数组的一般格式为:
TYPE (*p)[N] = new TYPE [][N];
TYPE:类型,N:二维数组的列数。
采用这种格式,列数必须指出,而行数无需指定。在这里,p的类型是TYPE*[N],即是指向一个有N列元素数组的指针。
还有一种方法,可以不指定数组的列数:(本例我们这里用的就是这种方法)
int** p;
p = new int*[10];
//注意,int*[10]表示一个有10个元素的指针数组
for (int i = 1; i <= 10; i++)p[i] = new int[5];
{
指针数组:
数组元素为指针的数组,其本质为数组。(例如 int *p[3],定义了p[0],p[1],p[2]三个指针)
}
这里,二级指针**p的指针名p为"int **" 类型(也就是说是一个指向int[10]这种一维数组型存储空间(like:int (*)[10]) 的地址(即指针))
具体赋给二级指针**p指针名p的(一个指向int[10]这种)一维数组(一个(10个元素的)指针数组)型存储空间的地址(即指针))。
我们可以很容易就注意到:
这里的“**p”和我们在C语言日记 25(2) 补充:二维数组与指针理解具体过程详解_宇 -Yu的博客-CSDN博客(里面的:A[3][3],int**p=A;执行p++时,编译器因无法知道长度(列宽:一行有多少列)而用不了)中提到的“(*p)[5]”他们的指针名代表的意义截然不同:
(*p)[5]中的数组名p,其实表示的是一个行地址
和这里完全不一样的地方:p也代表整个二维数组的首(个)元素(整个二维数组的第0行)的内存的首(个元素的)地址;
当然和这里很像的是,它本身代表着一个一维数组,“[5]"表示一维数组包含5个元素
而这里,在开辟存储空间时,**p中的数组名p,表示的是一个一维数组型存储空间的地址
另外,这里这个程序却(是)不能改成
int(*p)[8];
的形式:
#include <iostream>
using namespace std;
int main()
{
int(*p)[8];
int i, j;
p = new int* [4];
//开始分配4行8列的二维数据
for (i = 0; i < 4; i++)p[i] = new int[8];
for (i = 0; i < 4; i++) //给二维数组放入数据
for (j = 0; j < 8; j++)p[i][j] = j * i;
//打印数据
for (i = 0; i < 4; i++)
for (j = 0; j < 8; j++)
{
if (j == 0) cout << endl;
cout << p[i][j] << "\t";
}
for (i = 0; i < 4; i++)
delete[] p[i];
delete[] p;
return 0;
}//1结果:
 这又是为什么?
这又是为什么?
其实原因很简单:
因为我们这里用的p是一个指针数组,而不是一个数组指针;
{
数组指针:
指向数组地址的指针,本质上就是个指针;
指针数组:
数组元素为指针的数组,其本质为数组。(例如 int *p[3],定义了p[0],p[1],p[2]三个指针)
}
不知道他搞什么鸡毛,我感觉明明这俩程序一模一样,结果下面这个程序输入以后全是一堆报错:
#include <iostream>
using namespace std;
int main()
{
int i,j;
p = new int* [4];
int** p;
//开始分配4行8列的二维数据
for (i = 0; i < 4; i++)p[i] = new int[8];
for (i = 0; i < 4; i++) //给二维数组放入数据
{
for (j = 0; j < 8; j++)p[i][j] = j * i;
}
//打印数据
for (i = 0; i < 4; i++)
for (j = 0; j < 8; j++)
{
if (j == 0) cout << endl;
cout << p[i][j] << "\t";
}
//开始释放申请的堆
for (i = 0; i < 4; i++)
delete[] p[i];
delete[] p;
return 0;
}谁能搞清楚是怎么回事???
main()函数的括号部分打成了中文输入法..
麻了,我nm裂开




![[付源码+数据集]Github星标上万,23 个机器学习项目汇总](https://img-blog.csdnimg.cn/img_convert/1f0f7cddcd25b101027a37ea04741c0a.png)