EMQX 5.0水平扩展能力得到了指数级提升,能够更可靠地承载更大规模的物联网设备连接量。
在EMQX5.0正式发布前的性能测试中,我们通过一个23节点的EMQX集群,全球首个达成了1亿MQTT连接+每秒100万消息吞吐,这也使得EMQX 5.0成为目前为止全球具突出扩展性的MQTT Broker。
4.x时代:使用Mnesia构建EMQX集群
Mnesia介绍
EMQX 4.x版本存储采用的是Erlang/OTP自带的分布式数据库Mnesia,它具备以下优点:
- **Embedded:**和MySQL、PostgeresSQL等数据库不同,Mnesia和EMQX是运行在同一个操作系统进程的(类似于SQLite)。因此EMQX可以以非常快的速度读取路由、会话等相关信息。
- **Transactional:**Mnesia支持事务且具有ACID保证。而且这些保证是针对整个集群所有节点生效的。EMQX在数据一致性很重要的地方使用Mnesia事务,例如更新路由表、创建规则引擎规则等。
- **Distributed:**Mnesia表会复制到所有EMQX节点。这能提高EMQX 的分布式的容错能力,只要保证一个节点存活数据就是安全的。
- **NoSQL:**传统的关系型数据库使用SQL与数据库进行交互。而Mnesia直接使用Erlang表达式和内置的数据类型进行读写,这使得与业务逻辑的整合非常顺利,并消除了数据编解码的开销。
在Mnesia集群中,所有节点都是平等的。它们中的每一个节点都可以存储一份数据副本,也可以启动事务或执行读写操作。
Mnesia集群使用全网状拓扑结构:即每个节点都会与集群中其它所有的节点建立连接,每个事务都被会复制到集群中的所有节点。如下图所示:

**Mnesia的问题
正如我们上面所讨论的,Mnesia数据库有很多非常显著的优点,EMQX也从中获得了非常大的收益。但其全连接的特性,限制了其集群的水平扩展能力,因为节点之间的链接数量随着节点数量的平方而增长,保持所有节点完全同步的成本越来越高,事务执行的性能也会急剧下降。
这意味着EMQX的集群功能有以下限制:
- **水平扩展能力不足。**在4.x我们不建议在集群节点过多,因为网状拓扑中的事务复制的开销会越来越大;我们一般建议是使用节点数保持在3~7个,并尽量提供单节点的性能。
- **节点数增多会增大集群脑裂的可能性。**节点数越多、节点间的链接数也会急剧增多,对节点间的网络稳定性的要求更高。当产生脑裂后,节点自愈会导致节点重启并有数据丢失的风险。
尽管如此,EMQX凭借独特的架构设计和Erlang/OTP强大的功能特性,实现了单个集群1000万MQTT连接的目标。同时,EMQX能够以集群桥接的方式,通过多个集群承载更大规模的物联网应用。
但随着市场的发展,单个物联网应用需要承载越来越多的设备和用户,EMQX需要具备更强大的扩展性和接入能力,以支持超大规模物联网应用。
5.x时代:使用Mria构建大规模集群
Mria是Mnesia的一个开源扩展,为集群增加了最终的一致性。前文所述的大多数特性仍然适用于它,区别在于数据如何在节点间进行复制。
Mria从全网状拓扑结构转向网状+星型状拓扑结构。每个节点承担两个角色中的一个:核心节点(Core)或复制者节点(Replicant)。
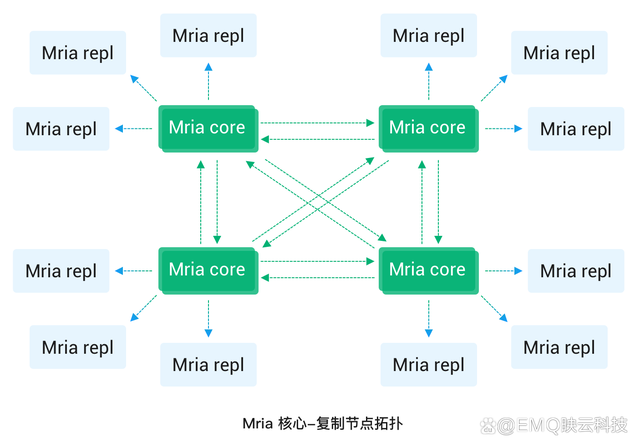
**Core和Replicant节点行为
Core节点的行为与4.x中的Mnesia节点一致:Core节点使用全连接的方式组成集群,每个节点都可以发起事务、持有锁等。因此,EMQX 5.0仍然要求Core节点在部署上要尽量的可靠。
Replicant节点不再直接参与事务的处理。但它们会连接到Core节点,并被动地复制来自Core节点的数据更新。Replicant节点不允许执行任何的写操作。而是将其转交给Core节点代为执行。
另外,由于Replicant会复制来自Core节点的数据,所以它们有一份完整的本地数据副本,以达到最高的读操作的效率,这样有助于降低EMQX路由的时延。
我们可以将这种数据复制模型当做无主复制和主从复制的一种混合。这种集群拓扑结构解决了两个问题:
- 水平可扩展性(如前文提到,我们已经测试了有23个节点的EMQX集群)
- 更容易的集群自动扩展,并无数据丢失的风险
由于Replicant节点不参与写操作,当更多的Replicant节点加入集群时,写操作的延迟不会受到影响。这允许创建更大的EMQX集群。
另外,Replicant节点被设计成是无状态的。添加或删除它们不会导致集群数据的丢失、也不会影响其他节点的服务状态,所以Replicant节点可以被放在一个自动扩展组中,从而实现更好的DevOps实践。
出于性能方面的考虑,不相干数据的复制可以被分成独立的数据流,即多个相关的数据表可以被分配到同一个RLOG Shard(复制日志分片),顺序地把事务从Core节点复制到Replicant节点。但不同的RLOG Shard之间是异步的。
EMQX 5.0集群部署实践
集群架构选择
在EMQX 5.0中,所以如果不做任何调整的话所有节点都默认为Core节点,默认行为和4.x版本是一致的。
可以通过设置emqx.conf中的node.db_role参数或EMQX_NODE__DB_ROLE环境变量,把节点上设置为Replicant节点。
- 请注意,集群中至少要有一个核心节点,我们建议以3个Core+N个Replicant的设置作为开始
Core节点可以接受MQTT的业务流量,也可以纯粹作为集群的数据库来使用。我们建议:
- 在小集群中(3个节点或更少),没有必要使用Core+Replicant复制模式,可以让Core节点承担所有的流量,避免增加上手和使用的难度。
- 在超大的集群中(10个节点或更多),建议把MQTT流量从Core节点移走,这样更加稳定性和水平扩展性更好。
- 在中型集群中,取决于许多因素,需要根据用户实际的场景测试才能知道哪个更优。
异常处理
Core节点对于Replicant节点是无感的,当某一Core节点宕机时,Replicant节点会自动连接到新的Core节点,此过程中客户端不会掉线,但可能导致路由更新延迟;当Replicant节点宕机时,所有连接到该节点的客户端会被断开,但由于Replicant是无状态的,所以不会影响到其他节点的稳定性,此时客户端需要设置重连机制,连接至另一个Replicant节点。
硬件配置要求
网络
Core节点之间的网络延迟建议10ms以下,实测高于100ms将不可用,请将Core节点部署在同一个私有网络下;Replicant与Core节点之间同样建议部署在同一个私有网络下,但网络质量要求可以比 Core节点间略低。
CPU与内存
Core节点需要较大的内存,在不承接连接的情况下,CPU消耗较低;Replicant节点硬件配置与4.x一致,可按连接和吞吐配置估算其内存要求。
监控和调试
对Mria的性能监控可以使用Prometheus或使用EMQX控制台查看。Replicant节点在启动过程中会经历以下状态:
- **bootstrap:**当Replicant节点启动后,需要从Core节点同步最新数据表的过程
- **local_replay:**当节点完成bootstrap时,它必须重放这个过程中产生的的写事务
- **normal:**当缓存的事务被完全执行后,节点即进入到正常运行的状态。后续的写事务被实时地应用到当前节点。大多数情况下,Replicant节点都会保持在这个状态。
Prometheus监控
Core节点
- emqx_mria_last_intercepted_trans:自节点启动以来,分片区收到的交易数量。请注意,这个值在不同的核心节点上可能是不同的。
- emqx_mria_weight:一个用于负载平衡的值。它的变化取决于核心节点的瞬间负载。
- emqx_mria_replicants:连接到核心节点的复制器的数量,为给定的分片复制数据。
- emqx_mria_server_mql:未处理的交易数量,等待发送至复制者。越少越好。如果这个指标有增长的趋势,需要更多的核心节点
Replicant节点
- emqx_mria_lag:复制体滞后,表示复制体滞后上游核心节点的程度。越少越好。
- emqx_mria_bootstrap_time:复制体启动过程中花费的时间。这个值在复制体的正常运行过程中不会改变。
- emqx_mria_bootstrap_num_keys:在引导期间从核心节点复制的数据库记录的数量。这个值在复制体的正常运行中不会改变。
- emqx_mria_message_queue_len:复制进程的消息队列长度。应该一直保持在0左右。
- emqx_mria_replayq_len:复制体的内部重放队列的长度。越少越好。
控制台命令
./bin/emqxevalmria_rlog:status().可以获取关于Mria数据库运行状态的更多信息。
- 注:它可以显示一些shard为down状态,这表明这些分片没有被任何业务应用使用。
结语
全新的底层架构使EMQX 5.0具备了更强的水平扩展能力,在构建满足业务需求的更大规模集群的同时,可以降低大规模部署下的脑裂风险以及脑裂后的影响,有效减少集群维护开销,提供更加稳定可靠的物联网数据接入服务。