前言
群聊中未读消息如何设计,以及是推消息还是拉去消息如何选择是需要讨论的。推送消息是推送全量消息还是推送信号消息让客户端再去拉取。其中方案如何选型会比较纠结。
首先基本的推拉结合思路是在线用户推送消息。用户离线的话上线去拉取消息。这是简单的推拉结合。问题在于群聊消息的特点有发送消息比较频繁。假设群里面有一秒钟发送了100条消息。如果推送的话一个人需要推送一百次。但是拉取的话只需要一次就可以拉取所有消息。但是通过 信号消息这样的方案使得设计非常复杂。详情看这篇文章。
目前已经写的文章有。并且有对应视频版本。
git项目地址 【IM即时通信系统(企聊聊)】点击可跳转
sprinboot单体项目升级成springcloud项目 【第一期】
前端项目技术选型以及页面展示【第二期】
分布式权限 shiro + jwt + redis【第三期】
给为服务添加运维模块 统一管理【第四期】
微服务数据库模块【第五期】
netty与mq在项目中的使用(第六期(废弃))】
分布式websocket即时通信(IM)系统构建指南【第七期】
分布式websocket即时通信(IM)系统保证消息可靠性【第八期】
分布式websocket IM聊天系统相关问题问答【第九期】
什么?websocket也有权限!这个应该怎么做?【第十期】
分布式ID是什么,以美团Leaf为例改造融入自己项目【第十一期】
IM聊天系统为什么需要做消息幂等?如何使用Redis以及Lua脚本做消息幂等【第12期】
微信发送一条消息经历哪些过程。企业微信以及钉钉的IM架构对比【第13期】
微信群为什么上限是500人,IM设计系统中的群聊的设计难点【第14期】
【分布式websocket】RocketMQ发送消息保证消息最终一致性需要做哪些处理?【第15期】
B站上面关注我呐 B站和CSDN同名,B站1000粉丝后建群。然后B站关注我后可以私信CSDN来的,然后后面我建群的时候拉你!
群聊中消息已读未读如何设计
数据模型设计
在群聊系统中,管理未读消息的两种常见方法是:记录每个用户与每条消息之间的已读/未读状态,以及记录用户的最后一次阅读消息ID。每种方法都有其优缺点,适用于不同的场景。
结论
如果你的系统需要精确跟踪每条消息的阅读状态,或者需要支持复杂的消息阅读状态查询,可以选择记录每个用户与每条消息之间的已读/未读状态。
如果你的系统更注重性能和可扩展性,或者只需要基本的未读消息功能,记录用户的最后一次阅读消息ID是一个更高效的选择。
通常,考虑到性能和实现的复杂度,许多现代的群聊系统倾向于使用记录最后一次阅读消息ID的方法。这种方法能够满足大多数场景的需求,同时保持系统的高效和简洁。
我们采用 记录用户的最后一次阅读消息ID。
CREATE TABLE yan_im_read(
user_id VARCHAR(255) NOT NULL,
group_id VARCHAR(255) NOT NULL,
last_read_message_id BIGINT,
count int
);
具体未读这块会在下一篇离线消息设计中说明
设计思路
功能实现
- 发送消息:
当用户发送消息时,将消息存入消息表,并为每个接收者在用户-会话关系表中的未读消息数加一。
对于群聊,为群内每个成员(除了发送者)的未读消息数加一。 - 阅读消息:
当用户打开一个聊天窗口时,系统将该会话的未读消息数重置为0,并更新最后阅读时间或最后阅读的消息ID。
同时,前端展示未读消息数,并将其清零。 - 查询未读消息数:
用户登录或在主界面时,系统查询用户-会话关系表,获取每个会话的未读消息数,以及总的未读消息数。
这些信息用于在用户的聊天列表中显示每个聊天窗口的未读消息数,以及应用图标上显示的总未读数。
群聊中消息推送模型采用推送还是用户自己拉取
** 模式一 推送模式(Push)**
在推送模式下,当有新消息时,服务器主动将消息推送给客户端。这种模式可以实现实时通信,用户体验较好。
优点:
实时性:用户可以即时接收到消息,无需主动查询,提高了通信的实时性。
减轻客户端负担:客户端无需定时向服务器发送查询请求,减少了网络请求和资源消耗。
缺点:
服务器负担较重:需要服务器跟踪每个客户端的连接状态,并实时推送消息。
可能存在消息丢失:在网络不稳定或客户端离线时,推送的消息可能会丢失。
模式二 拉取模式(Pull)
- 在拉取模式下,客户端定时向服务器发送请求,查询是否有新消息。如果有,客户端再拉取这些新消息。
- 优点:
简单可靠:客户端主动拉取,可以根据需要重试,减少了消息丢失的风险。
服务器处理简单:服务器不需要跟踪客户端的连接状态,只需响应客户端的请求。 - 缺点:
延迟:用户接收到消息的速度取决于拉取的频率,可能无法做到实时通信。
增加客户端负担:客户端需要定时发送请求,增加了网络请求和资源消耗。
模式三 推送通知后客户端拉取消息
在这种策略中,当群聊中有新消息时,服务器不直接发送消息内容,而是发送一个有新消息的通知给群成员,由客户端在收到通知后主动向服务器拉取新消息。
优点:
减轻了服务器推送的压力,尤其是在高并发场景下。
更灵活,可以根据客户端的实际情况(如网络状况、用户设置等)决定是否拉取新消息。
方便实现对离线消息的处理,客户端上线后可以主动拉取期间的所有新消息。
缺点:
实时性略差,用户收到消息有一定的延迟。
客户端逻辑更复杂,需要实现拉取新消息的逻辑。
结合使用
在实际应用中,为了兼顾实时性和系统资源的有效利用,往往会结合推送和拉取两种模式:
- 推送+拉取:对于实时性要求高的消息,如即时聊天消息,采用推送模式,确保用户能够及时收到。对于实时性要求不高的信息,如离线消息或通知,可以在用户上线时通过拉取模式获取。
- 状态同步:使用推送模式进行实时消息通信,同时,客户端在特定情况下(如启动、网络恢复等)主动拉取最新状态,以确保没有遗漏的消息。
- 根据消息优先级去选择推送或者拉取:还可以根据消息的优先级和类型,选择不同的推送策略。对于重要或紧急的消息,可能采用直接推送的方式;而对于普通消息,则采用通知加拉取的方式
- 注意事项
推送策略:在推送模式下,需要合理设计推送策略,比如使用消息队列管理待推送消息,以应对高并发场景。
拉取策略:在拉取模式下,需要考虑合理的拉取频率,避免过于频繁导致的资源浪费,或过于稀疏导致的实时性不足。
用户体验:在设计消息推送模型时,应考虑到用户体验,提供稳定、可靠、及时的消息服务。
实时推送的优化策略
1.消息队列优化
利用消息队列来管理消息的发送。当有新消息时,先将消息发送到消息队列中,然后使用消费者服务批量从队列中取出消息进行处理和推送。这种方式可以有效地平衡负载,提高消息处理的效率。
2.分批推送
对于大群聊,一次性向所有成员推送可能会导致服务器压力过大。可以将群成员分批,每批包含一定数量的用户,然后逐批推送。这样既可以减轻服务器压力,又可以避免网络拥塞。
3.WebSocket连接池
对于基于WebSocket或长连接的推送方式,使用连接池来管理和复用连接。这样可以减少频繁建立和断开连接的开销,提高推送效率。
4. 监控和调优
持续监控推送系统的性能指标,如推送延迟、失败率等。根据监控结果调整批处理大小、分批策略和资源分配,以达到最优的推送效率。
MQ批量消费逻辑
先说明一下消费什么。批量消费可以解决什么问题。在之前的消息链路消息有落库的环节。
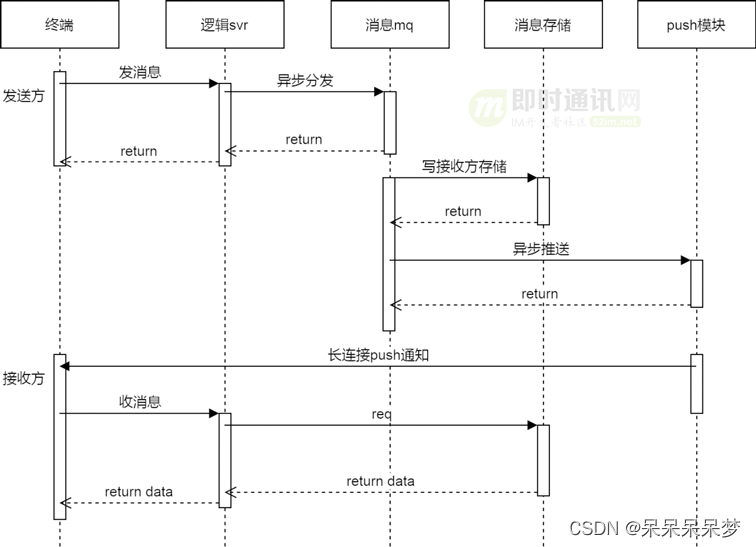
落库的话需要监听mq然后消费这条消息进行落库。这里采用的策略是批量落库。避免发送一条消息保存一条消息这样的频繁访问数据库。
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
@Service
@RocketMQMessageListener(topic = "yourTopic", consumerGroup = "yourConsumerGroup", consumeMode = ConsumeMode.CONCURRENTLY, consumeThreadMax = 10, messageModel = MessageModel.CLUSTERING)
public class MyBatchConsumerService implements RocketMQListener<List<MessageExt>> {
@Override
public void onMessage(List<MessageExt> messages) {
for (MessageExt message : messages) {
// 处理每条消息
System.out.println(new String(message.getBody()));
}
// 实现批量处理逻辑
}
}
配置消费者属性
在application.properties或application.yml中配置消费者的属性,特别是consumeMessageBatchMaxSize,这个属性决定了消费者每次批量拉取处理的消息最大数量。
rocketmq:
consumer:
consumeMessageBatchMaxSize: 10
如果需要更细致地控制消费者的配置,可以通过编程方式自定义消费者。这通常涉及到创建DefaultMQPushConsumer的实例,并设置相关属性。
@Configuration
public class RocketMQConsumerConfig {
@Value("${rocketmq.name-server}")
private String nameServer;
@Value("${rocketmq.consumer.group}")
private String consumerGroup;
@Bean
public DefaultMQPushConsumer batchConsumer() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(consumerGroup);
consumer.setNamesrvAddr(nameServer);
consumer.setConsumeMessageBatchMaxSize(10); // 设置批量消费的大小
consumer.subscribe("YourTopic", "*"); // 订阅主题
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
// 实现批量消息处理逻辑
msgs.forEach(msg -> {
System.out.println(new String(msg.getBody()));
});
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();
return consumer;
}
}
. 注意事项
- 消息大小限制:确保批量消费的总消息大小不超过RocketMQ的限制(默认不超过4MB)。
- 异常处理:在批量处理消息时,确保有适当的异常处理机制。如果批量中的某个消息处理失败,需要决定是重试整个批次还是仅重试失败的消息。
- 性能测试:在实际部署前,进行充分的性能测试,以确定最优的consumeMessageBatchMaxSize值。过大或过小的批量大小都可能影响消费效率。
通过上述配置和建议,可以在Spring Boot应用中有效地实现RocketMQ的批量消费,提高消息处理的效率和应用性能。
介绍群聊模式三
当群聊中有新消息时,服务器不直接发送消息内容,而是发送一个有新消息的通知给群成员,由客户端在收到通知后主动向服务器拉取新消息。这种模式实现起来暂时有点复杂。先按照简单的推拉结合处理。但是可以保留着思路,然后后面解决。
方案概述
- 信号消息推送:当有新消息发送到群聊时,服务器不会直接将完整的消息内容推送给所有群成员。相反,它只发送一个信号消息,通知客户端有新消息可用。
- 客户端拉取消息:收到信号消息后,客户端会主动向服务器发起请求,拉取自上次更新以来的所有新消息。
方案优点
减少带宽消耗:由于不是所有的消息内容都通过推送发送,这种方案可以显著减少网络带宽的消耗。
提高效率:客户端可以根据实际需要批量拉取消息,减少网络请求的次数,提高数据同步的效率。
保证消息完整性:通过拉取机制,即使在网络不稳定的情况下,客户端也能确保最终获取到所有的消息,避免消息丢失。
支持离线消息:当用户离线时,信号消息可以被服务器暂存,用户上线后再拉取所有未读消息,保证消息的完整同步。
方案实现要点
信号消息设计:信号消息应包含足够的信息,以便客户端知道从哪里开始拉取新消息。例如,可以包含最新消息的ID或时间戳。
消息存储:服务器需要有效地存储和管理消息,以支持高效的消息拉取操作。通常需要对消息进行索引,以便快速查询到新消息。
拉取策略:客户端可以实现智能的拉取策略,例如,在用户查看群聊时主动拉取新消息,或者在收到多个信号消息时合并请求,减少服务器的负载。
错误处理和重试机制:为了保证消息的完整性,客户端在拉取消息时应该实现错误处理和重试机制,确保在网络不稳定时也能成功获取消息。
适用场景
这种结合推送和拉取的方案非常适合消息量大、用户基数广的群聊系统,尤其是在需要优化网络资源消耗、保证消息可靠传递的场景下。同时,这种方案也适用于需要支持离线消息同步的应用。