【Python】科研代码学习:十二 PEFT
PEFT 简单训练教程 简单推理教程 Adapter 适配器 Merge Adapter 架构关系
【HF官网-Doc-PEFT:API】PEFT (Prameter-Efficient Fine-Tuning):参数高效的微调HF 提供的 PEFT 库PEFT 让大的预训练模型可以很快适应到各种下游的任务中,并且没有进行全参微调,因为全参微调的时间、算力花费比较大。 两个很重要的模块:PeftConfig :提供 peft 的配置PeftModel:提供 peft 的模型 最常见的是使用 LoRA (Low-Rank Adaptation ) 作为 PEFT 技术PeftConfig 就使用了 LoraConfig from peft import LoraConfig, TaskType
peft_config = LoraConfig( task_type= TaskType. SEQ_2_SEQ_LM, inference_mode= False , r= 8 , lora_alpha= 32 , lora_dropout= 0.1 )
然后,加载一个预训练模型get_peft_model,把模型和 peft_config 传进去,变成 peftmodel
0.19
%
0.19\%
0.19% from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_model
model = AutoModelForSeq2SeqLM. from_pretrained( "bigscience/mt0-large" )
model = get_peft_model( model, peft_config)
model. print_trainable_parameters( )
"output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
然后直接提供 TrainingArguments 和 Trainer 训练即可 training_args = TrainingArguments(
output_dir= "your-name/bigscience/mt0-large-lora" ,
learning_rate= 1e-3 ,
per_device_train_batch_size= 32 ,
per_device_eval_batch_size= 32 ,
num_train_epochs= 2 ,
weight_decay= 0.01 ,
evaluation_strategy= "epoch" ,
save_strategy= "epoch" ,
load_best_model_at_end= True ,
)
trainer = Trainer(
model= model,
args= training_args,
train_dataset= tokenized_datasets[ "train" ] ,
eval_dataset= tokenized_datasets[ "test" ] ,
tokenizer= tokenizer,
data_collator= data_collator,
compute_metrics= compute_metrics,
)
trainer. train( )
保存部分,跟一般的模型一样。但它只存储那些额外训练的参数,因此保存后的文件很小。 model. save_pretrained( "output_dir" )
我们加载 peftmodel 的话,需要使用比如 AutoPeftModel.from_pretrained 方法加载 from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM. from_pretrained( "ybelkada/opt-350m-lora" )
tokenizer = AutoTokenizer. from_pretrained( "facebook/opt-350m" )
model = model. to( "cuda" )
model. eval ( )
inputs = tokenizer( "Preheat the oven to 350 degrees and place the cookie dough" , return_tensors= "pt" )
outputs = model. generate( input_ids= inputs[ "input_ids" ] . to( "cuda" ) , max_new_tokens= 50 )
print ( tokenizer. batch_decode( outputs. detach( ) . cpu( ) . numpy( ) , skip_special_tokens= True ) [ 0 ] )
"Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."
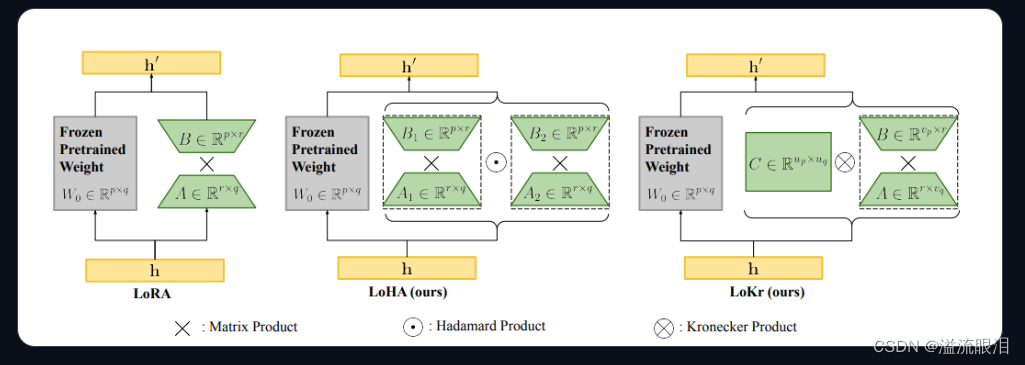
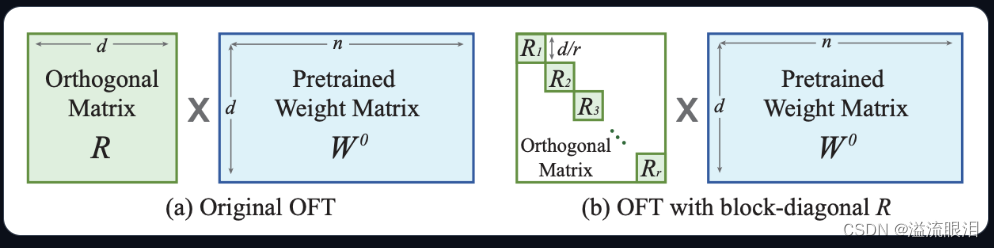
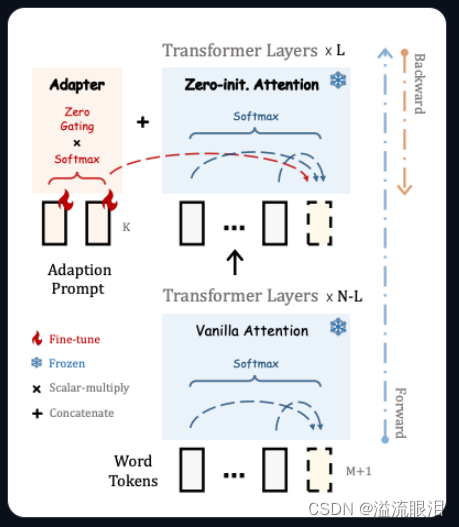
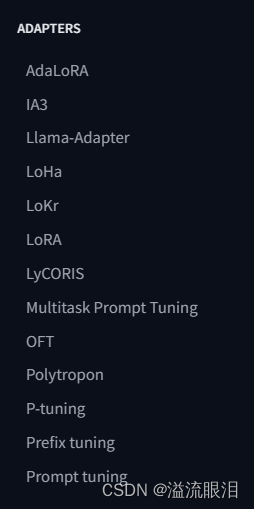
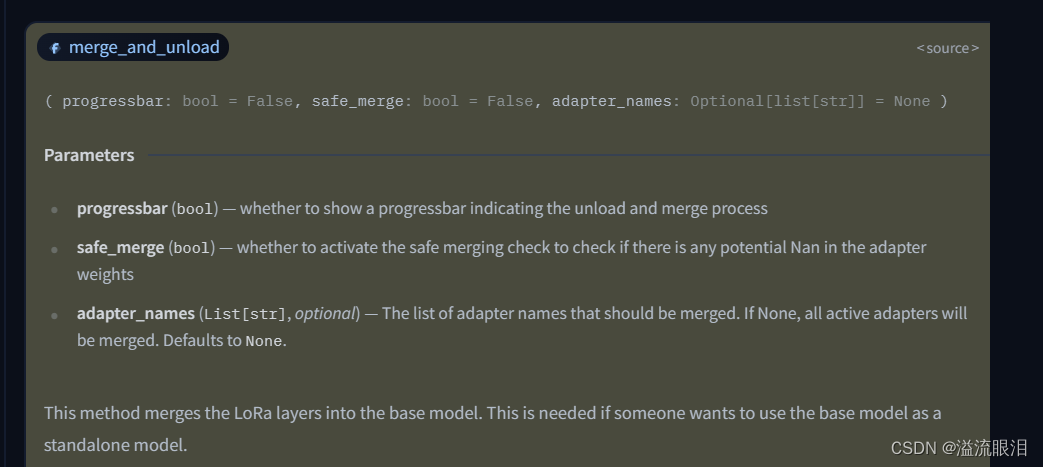
※ Adapter-based 方法在冻结的注意力层和全连接层之后添加了额外的可训练参数 PEFT 支持的几个 AdapterLoRA (Low-Rank Adaptation):最受欢迎的一个PEFT方法LoHa (Low-Rank Hadamard Product):使用了 Hadamard product 方法LoKr (Low-Rankd Kronecker Product) :使用了 Kronecker Product 方法OFT (Orthogonal Finetuning):方法如下图Llama-Adapter:让 Llama 适配成接受指令模型 (instruction-following model)在 PEFT 库中,可以按照对应的模型和任务,选择想用的 AdapterAdapter 都有它自己的 SpecificPeftModel 和 SpecificPeftConfigIA3LoRAP-tuningPrefix tuningPrompt tuning 在实际过程中,由于基座模型和 adapter 适配器 分开加载,可能会遇到延迟问题merge_and_unload() 方法,把 adapter 权重与底座模型权重融合起来。这样的话,使用新的模型就和一开始单独的模型没有区别了。 比如我使用的是 LoraAdapter,查阅该方法progressbar :是否显示进度条safe_merge:使用安全合并,检查适配器中是否有 Nan 权重adapter_names:要合并的适配器名字的列表 当然这些参数都可以用默认值。我们只要对 PeftModel 调用该方法即可返回合并后的 model 。 from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM. from_pretrained( "tiiuae/falcon-40b" )
peft_model_id = "smangrul/falcon-40B-int4-peft-lora-sfttrainer-sample"
model = PeftModel. from_pretrained( base_model, peft_model_id)
merged_model = model. merge_and_unload( )
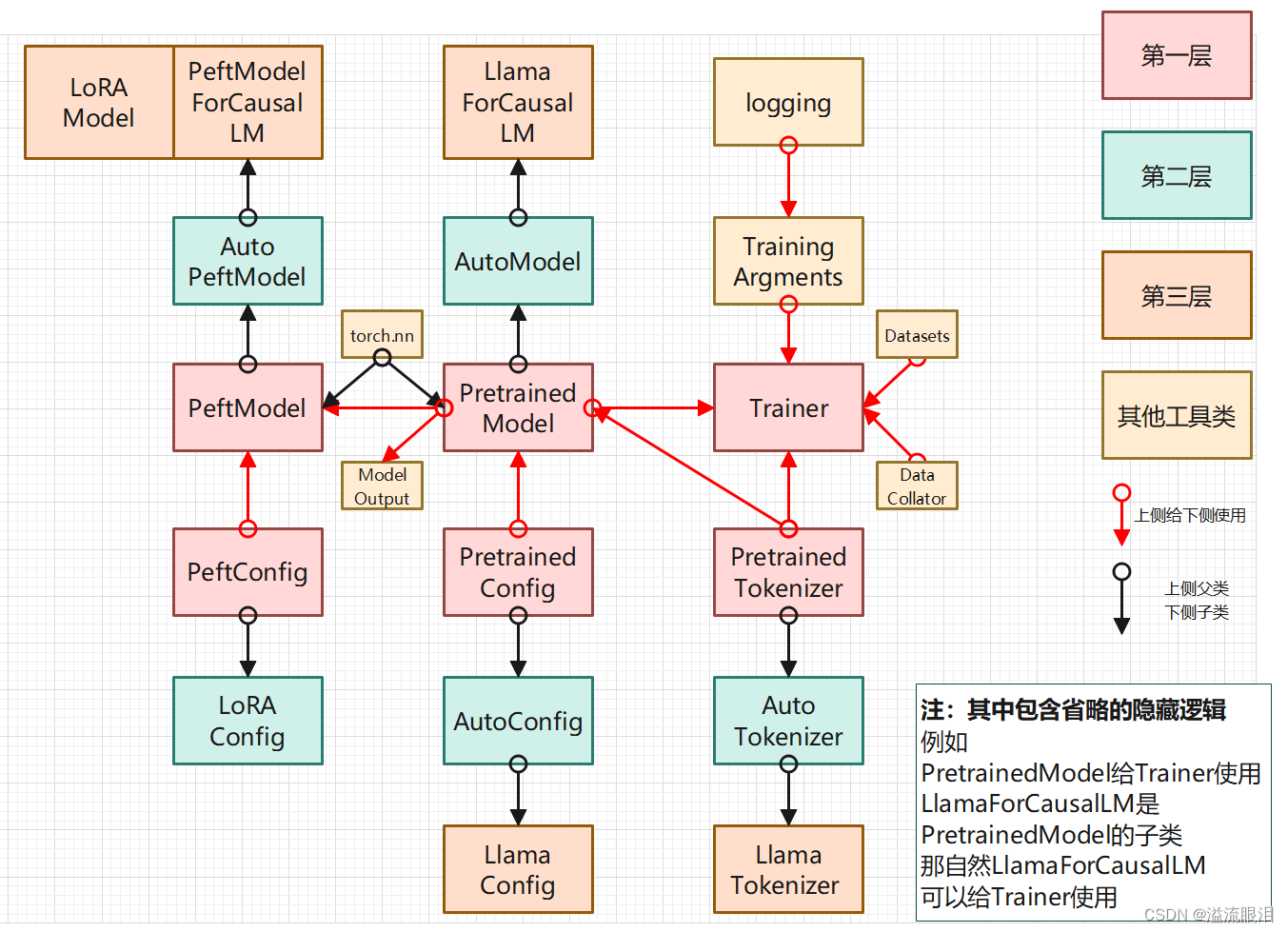
粗看上面关系有点乱,还是得看一下源码PeftModel 是从 torch.nn 继承过来的,按照不同的任务,使用不同的子类,比如 PeftModelForCausalLMLoRAModel 等,是从 BaseTuner 继承过来的,Tuner 也是继承自 torch.nn,但这个是按照使用不同的适配器分类的,并且它建议是使用 LoRAConfig,这个是 PeftConfig 的子类 PeftModel 更靠近 PretrainedModel,有 save_pretrained, from_pretrained 等方法。PeftModelForCausalLM 还有 generate 方法LoRAModel 更靠近 Adapter,有 merge_and_unload, delete_adapter 等方法它里面大部分的基类和使用到的网络几乎都是 torch.nn,因此大部分跟 PretrainedModel 可以接壤 即根据我的查询,LoRAModel 等并不是 PeftModelForCausalLM / PeftModel 的子类(有待存疑)LoRAModel 来训练,PeftModel 来推理,是可以的。LoRAModel 可以通过 merge_and_unload() 方法转成 torch.nn,也就相当于 PretrainedModel。

![[linux]信号处理:信号编码、基本API、自定义函数和集合操作的详解](https://img-blog.csdnimg.cn/5ce31febe5694246877a6f48a48faf62.png)