💡💡💡本文内容:教会你用自己数据集训练YOLOv9模型
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥50+ ,冲刺100+🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

models/detect/yolov9.yaml

ELAN models.common.RepNCSPELAN4:
从模块名字不难看出核心是Re-parameter + CSPNet + ELAN。
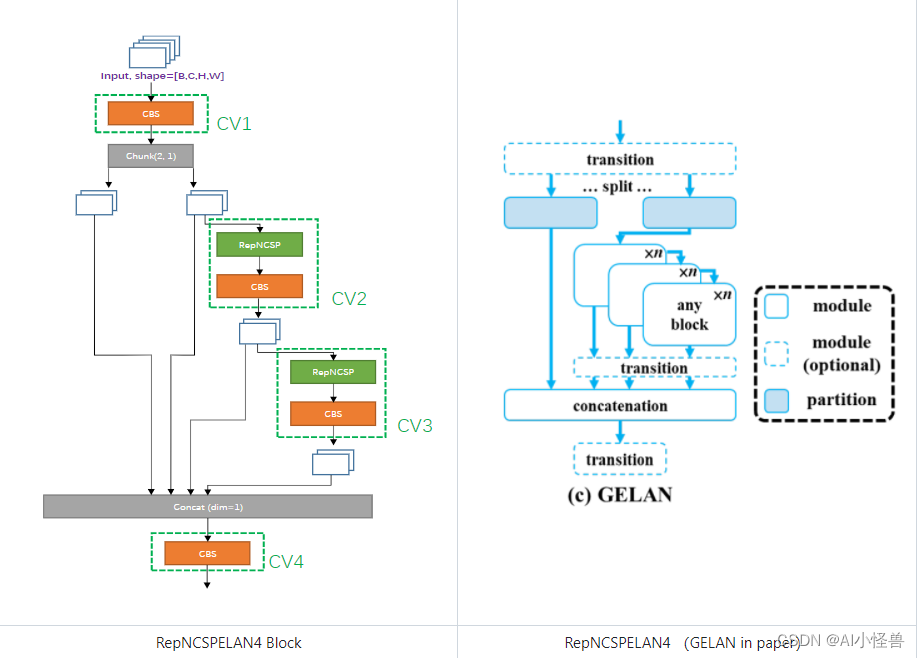
ELAN-SPP models.common.SPPELAN:
该模块与早前yolo版本中的SPPF结构基本一致,如下图。

ADown models.common.ADown:
该模块在yolov9-c.yaml与yolov9-e.yaml结构中出现,替代了模型中部分CBS模块。
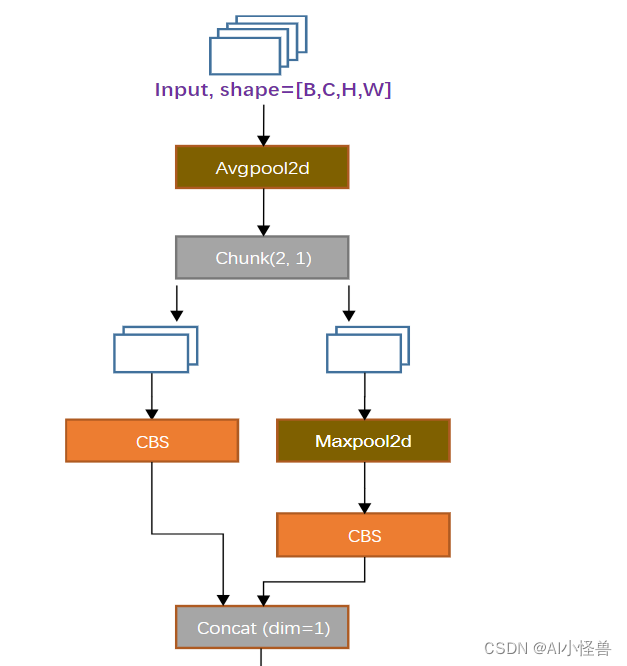
来自:YOLOv9结构详解 - 知乎 (zhihu.com)
2.NEU-DET数据集介绍
NEU-DET钢材表面缺陷共有六大类,一共1800张,
类别分别为:'crazing','inclusion','patches','pitted_surface','rolled-in_scale','scratches'
2.1数据集划分
通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()2.2 通过voc_label.py生成txt
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["crazing","inclusion","patches","pitted_surface","rolled-in_scale","scratches"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()2.YOLOv9训练自己的数据集
2.1 修改NEU-DET.yaml
path推荐使用全路径
path: ./data/NEU-DET # dataset root dir
train: train.txt # train images (relative to 'path') 118287 images
val: val.txt # val images (relative to 'path') 5000 images
# number of classes
nc: 6
# class names
names:
0: crazing
1: inclusion
2: patches
3: pitted_surface
4: rolled-in_scale
5: scratches2.2 修改train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
# parser.add_argument('--weights', type=str, default=ROOT / 'yolo.pt', help='initial weights path')
# parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--weights', type=str, default='weights/yolov9-c.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/detect/yolov9-c.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/NEU-DET/NEU-DET.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-high.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')2.3 开启训练
python train_dual.py2.4 训练可视化






![ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接。](https://img-blog.csdnimg.cn/direct/b6491bfe2e2046fd8ffe0262c50f795a.png)