八股学习是看别人面试被问到的问题,然后把它发给GPT,让gpt讲一讲,自己再理解一下,真的很想拿offer,想去暑期实习啊啊啊啊啊
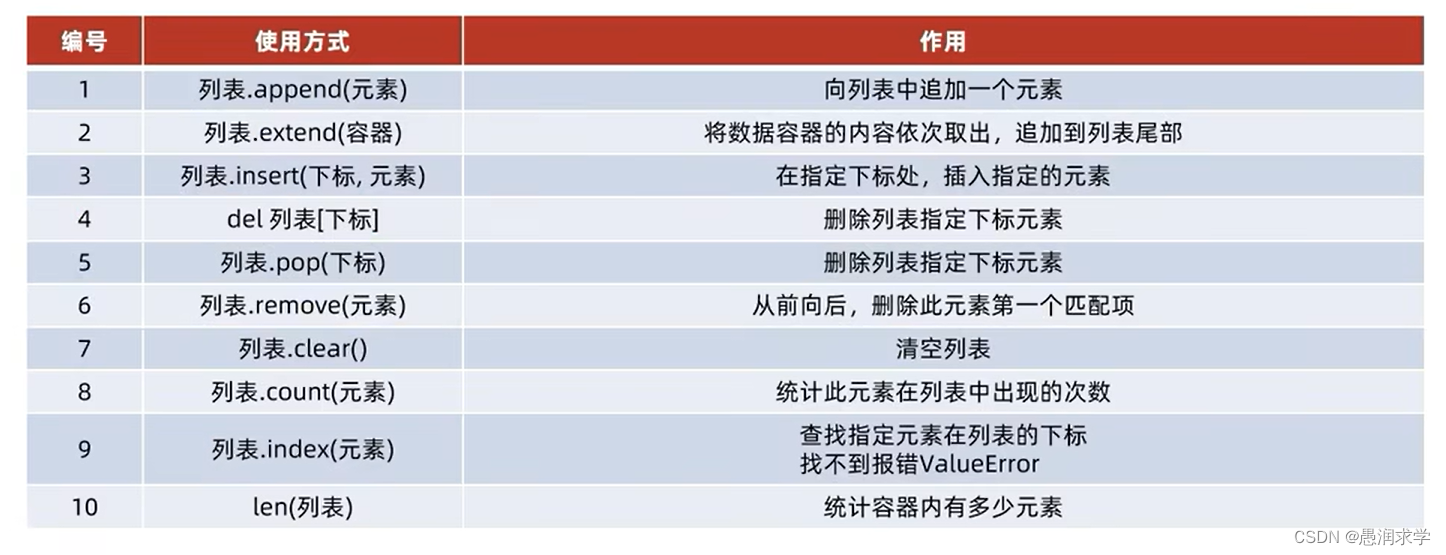
你用过什么 SpringBoot 里的什么注解?Spring Boot 中有很多常用的注解,我可以列举一些我用过的:
@SpringBootApplication:标识一个 Spring Boot 应用的主类,通常放在程序的入口类上。
@RestController:结合了@Controller和@ResponseBody,用于定义 RESTful 风格的控制器。
@Service:标识一个类为服务层组件,通常用于定义业务逻辑。
@Repository:标识一个类为数据访问层组件,通常用于对数据库进行操作。
@Autowired:用于自动装配依赖,可以标注在字段、构造方法、Setter 方法上。
@RequestMapping:用于映射请求路径到控制器方法,可以指定 HTTP 方法和路径。
@PathVariable:用于获取请求路径中的参数值。
@RequestParam:用于获取请求参数的值。
@ResponseBody:将方法返回的对象序列化为 JSON 或 XML,并写入响应体中。
@ExceptionHandler:用于捕获全局异常或特定异常,并进行统一处理。
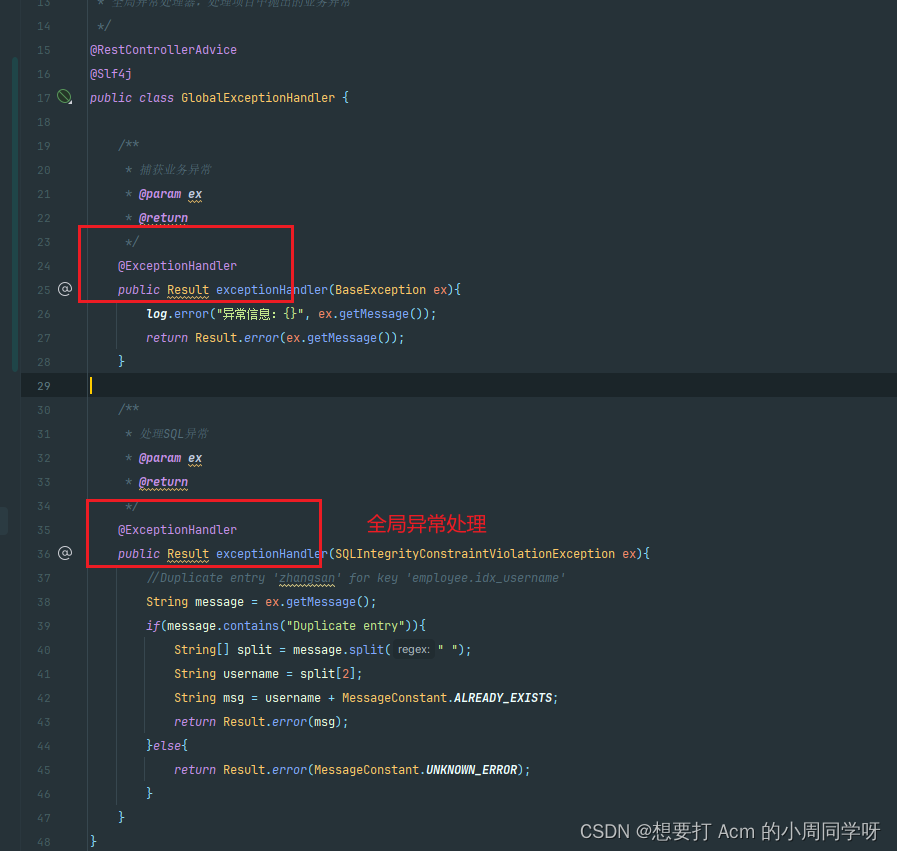
@Validated:用于对 Controller 方法参数进行校验。
对参数进行校验
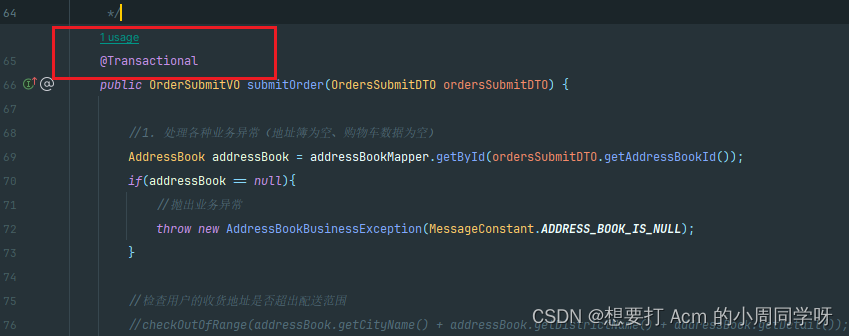
@Transactional:用于声明事务管理,可以标注在类或方法上。
这些注解是 Spring Boot 中常用的一些注解,用于简化开发、提高效率,帮助快速搭建基于 Spring Boot 的应用。
红黑树和B+树之间的区别
红黑树和 B+ 树是两种常用的数据结构,用于实现高效的数据存储和检索。它们在不同的场景下有着不同的应用和特点。
红黑树(Red-Black Tree):
红黑树是一种自平衡的二叉查找树,每个节点上都带有额外的存储位表示节点的颜色,可以是红色或黑色。
红黑树具有如下性质:
每个节点不是红色就是黑色。
根节点是黑色的。
每个叶子节点(NIL 节点,空节点)是黑色的。
如果一个节点是红色的,则它的两个子节点都是黑色的。
从任意一个节点到其每个叶子节点的路径都包含相同数量的黑色节点。
红黑树的自平衡性保证了插入、删除等操作的时间复杂度为 O(log n),是一种高效的动态数据结构,常被用于实现关联数组和集合。
B+ 树(B+ Tree):
B+ 树是一种多路搜索树,通常用于数据库和文件系统中的索引结构。
B+ 树的特点包括:
每个节点最多含有 m 个子节点(m 阶)。
除根节点和叶子节点外,其他节点至少包含 ceil(m/2) 个子节点。
所有叶子节点在同一层上,并且用指针相互连接,形成一个有序链表。
非叶子节点仅包含键值信息,而实际数据都存储在叶子节点中。
B+ 树的叶子节点形成了一个有序的数据链表,支持范围查询和顺序遍历。
B+ 树常被用于数据库的索引结构,能够快速定位到数据块,提高检索效率,同时支持范围查询和有序输出。
总的来说,红黑树适合于内存中的动态数据结构,而 B+ 树适合于外部存储的索引结构,两者在实际应用中有着不同的优势和适用场景。
讲一讲索引
MySQL 索引是一种帮助数据库系统快速定位数据的数据结构,它可以加快数据检索速度并提高查询效率。MySQL 支持多种类型的索引,包括主键索引、唯一索引、普通索引、全文索引等。下面是一些常见的 MySQL 索引及其特点:
主键索引(Primary Key Index):
主键索引是一种唯一索引,用于唯一标识数据库表中的每一行数据。
主键索引的值不能为 NULL,并且每一行数据的主键值必须唯一。
在创建表时,可以通过 PRIMARY KEY 关键字定义主键索引。
唯一索引(Unique Index):
唯一索引确保索引列的值在整个表中是唯一的,但允许索引列的值为 NULL。
与主键索引不同的是,唯一索引可以有多个,每个索引可以包含一个或多个列。
在创建表时,可以通过 UNIQUE 关键字定义唯一索引。
普通索引(Normal Index):
普通索引是最基本的索引类型,在检索数据时会按照索引列的顺序进行检索,加快查询速度。
普通索引可以包含一个或多个列,可以通过 CREATE INDEX 命令创建。
全文索引(Full-Text Index):
全文索引是用于全文搜索的索引类型,支持对文本字段进行全文搜索。
全文索引通常用于对大段文本内容进行搜索,如文章、博客等。
全文索引在 MySQL 中可以用于 MyISAM 和 InnoDB 存储引擎。
组合索引(Composite Index):
组合索引是包含多个列的索引,可以提高查询效率,特别是在多个列上进行筛选时。
组合索引的顺序非常重要,应根据查询条件和排序需求进行合理的设计。
空间索引(Spatial Index):
空间索引是用于空间数据类型的索引,如地理信息系统(GIS)中的点、线、面等。
空间索引可以帮助加速空间数据的检索和空间查询操作。
索引的使用需要权衡查询性能和存储成本,并根据实际情况进行设计和优化。不正确的索引使用可能会导致查询性能下降,因此在设计和使用索引时需要谨慎考虑。
解释一下epoll的执行流程、怎么用epoll实现多路复用、epoll怎么使用
Poll 是 Linux 下的一种 I/O 复用机制,用于处理大量并发连接的网络应用。它可以监控多个文件描述符,当其中任意一个文件描述符就绪时,通知应用程序进行相应的 I/O 操作。下面是 EPoll 的执行流程以及如何使用 EPoll 实现多路复用的简要介绍:
EPoll 的执行流程:
创建 EPoll 实例:使用 epoll_create 函数创建一个 EPoll 实例,并获取对应的文件描述符。
添加事件到 EPoll 实例:使用 epoll_ctl 函数向 EPoll 实例中添加需要监听的文件描述符和关注的事件类型(如读、写、异常等)。
等待事件发生:使用 epoll_wait 函数等待事件的发生,当有事件就绪时,epoll_wait 函数返回就绪事件的数量,并将就绪事件存储在一个数组中。
处理就绪事件:遍历就绪事件数组,根据事件类型进行相应的 I/O 操作。
使用 EPoll 实现多路复用:
创建 EPoll 实例:通过 epoll_create 函数创建一个 EPoll 实例,获取对应的文件描述符。
添加需要监听的文件描述符:使用 epoll_ctl 函数将需要监听的文件描述符添加到 EPoll 实例中,并指定关注的事件类型(如读、写)。
循环等待事件发生:使用 epoll_wait 函数等待事件的发生,当有事件就绪时,epoll_wait 函数返回就绪事件的数量,并将就绪事件存储在一个数组中。
处理就绪事件:遍历就绪事件数组,根据事件类型进行相应的 I/O 操作。
EPoll 的使用示例:
c
#include <sys/epoll.h>
#define MAX_EVENTS 10
int main() {
int epoll_fd, num_events;
struct epoll_event events[MAX_EVENTS];
// 创建 EPoll 实例
epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
perror("epoll_create1");
return 1;
}
// 添加需要监听的文件描述符
struct epoll_event ev;
ev.events = EPOLLIN; // 监听读事件
ev.data.fd = /* your_file_descriptor */;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, /* your_file_descriptor */, &ev) == -1) {
perror("epoll_ctl: EPOLL_CTL_ADD");
return 1;
}
while (1) {
// 等待事件发生
num_events = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
if (num_events == -1) {
perror("epoll_wait");
return 1;
}
// 处理就绪事件
for (int i = 0; i < num_events; i++) {
if (events[i].events & EPOLLIN) {
// 处理读事件
}
// 其他事件类型的处理
}
}
return 0;
}
以上是一个简单的使用 EPoll 实现多路复用的示例代码,具体使用时需要根据实际需求进行适当修改和扩展。
Redis
mysql创建索引需要注意什么?
创建索引是数据库优化的重要手段之一,它可以加快查询速度并提高系统性能。在为表创建索引时,需要注意以下几个方面:
选择合适的列:选择经常用于查询条件、连接条件或排序操作的列来创建索引。这些列通常是 WHERE 子句中的列、JOIN 操作中的连接列以及 ORDER BY 子句中的列。
考虑列的选择性:选择性是指索引列中不同值的比例。选择性越高,索引的效果越好。通常情况下,选择性大于 20% 的列适合创建索引。
避免过度索引:不要为表中每个列都创建索引,因为过多的索引会增加写操作的开销,并占用额外的存储空间。只为必要的列创建索引,避免创建冗余或不必要的索引。
注意索引的顺序:对于组合索引,索引列的顺序很重要。应根据查询的频率和条件选择合适的索引顺序,以提高查询性能。
考虑存储引擎的特性:不同的存储引擎对索引的支持和实现方式有所不同。例如,InnoDB 存储引擎的主键索引与数据行关联,而 MyISAM 存储引擎的主键索引与数据行是分开存储的。因此,在选择创建索引时要考虑存储引擎的特性。
定期维护索引:随着数据的增删改操作,索引可能会变得不再有效或失效,因此需要定期对索引进行维护和优化,以确保其性能和效率。
注意影响 DML 操作的索引:插入、更新和删除操作会涉及到索引的维护和更新,因此在为表创建索引时需要考虑 DML 操作对索引维护的影响,并进行适当的优化。
综上所述,创建索引需要综合考虑列的选择、选择性、顺序、存储引擎特性以及维护等方面,以提高查询性能和系统整体性能。
oop的基本概念以及你认为oop为什么会提出
面向对象编程(Object-Oriented Programming,OOP)是一种编程范式,它以对象作为程序的基本单元,将数据与操作封装在一起,以模拟现实世界的问题解决方案。以下是 OOP 的基本概念:
封装(Encapsulation):将数据和操作(方法)封装在对象中,通过限制对对象内部数据的访问来实现数据的保护和安全性。
继承(Inheritance):通过创建一个新的类(子类)来继承现有类(父类)的属性和方法,子类可以重用父类的代码,并且可以在不改变原有结构的情况下添加新的功能或修改已有功能。
多态(Polymorphism):多态性指的是相同的操作对不同的对象可以有不同的解释和行为。通过方法重写(override)和方法重载(overload)实现多态性,提高代码的灵活性和可扩展性。
抽象(Abstraction):抽象是指隐藏对象的具体实现细节,只展现对象的核心特征和功能,使得用户可以忽略不必要的细节,专注于问题的解决。
面向对象编程的提出是为了解决传统的结构化编程模式在处理大型复杂项目时所面临的一些问题,例如:
复用性不足:在结构化编程中,代码复用性较低,往往需要重复编写相似的代码。而 OOP 中的继承和多态机制能够实现更高程度的代码复用,提高了开发效率。
维护困难:在结构化编程中,修改一个功能可能需要在多处进行修改,容易引发错误。而 OOP 中的封装性和抽象性可以将功能封装在对象中,降低了代码的耦合度,使得修改和维护变得更加容易。
可扩展性差:结构化编程往往难以应对需求的变化和功能的扩展,而 OOP 中的继承和多态机制使得系统更容易扩展和演化,使得软件更具有灵活性和可扩展性。
因此,面向对象编程的提出是为了更好地应对软件开发过程中的复杂性和变化性,提高代码的可读性、可维护性、可复用性和可扩展性,从而更好地满足软件开发的需求
在实现一个功能时,既可以使用继承,也可以使用多态。在选择使用继承还是多态时,可以考虑以下几个因素:
功能复用性:如果要实现的功能在多个类之间具有共性,并且这些类之间存在明显的继承关系,那么可以考虑使用继承。通过继承,子类可以继承父类的属性和方法,实现功能的复用。
灵活性:如果要实现的功能具有多样性,且不同类之间可能需要实现不同的行为,那么可以考虑使用多态。通过多态,不同的类可以对同一个方法进行不同的实现,提高了代码的灵活性和可扩展性。
代码结构:如果要实现的功能可以通过在父类中定义虚方法(或抽象方法),并在子类中进行重写来实现,那么可以考虑使用多态。这样可以将功能的实现细节与父类分离,使得代码结构更清晰。
耦合度:如果要实现的功能使用继承会导致类之间的耦合度过高,或者存在较深的继承层次,可能会影响代码的可维护性和扩展性,那么可以考虑使用多态来降低耦合度。
综上所述,选择使用继承还是多态取决于具体的需求和情况。在实践中,可以根据功能的复用性、灵活性、代码结构和耦合度等因素来进行抉择,并根据具体情况选择最合适的实现方式。