文章目录
- 一、HashMap的基本结构
- 1.数组与链表的结构
- 1.1 数组
- 1.2 链表
- 2.红黑树的简单介绍
- 3.Node节点的组成
- 二、HashMap的哈希函数
- 1.hashCode()方法的作用
- 2.位运算与哈希值的计算
- 3.扰动函数的作用
- 思考:为什么HashMap源码中使用位运算
在Java编程语言中,HashMap是一个至关重要的数据结构,它提供了键值对存储的高效方式。对于开发者来说,了解HashMap的内部工作原理不仅能够帮助提升编程技能,还能在实际应用中更好地利用这种数据结构。本文是“HashMap源码解析”的第一部分,我们将深入探讨HashMap的结构、哈希函数以及碰撞处理机制。
一、HashMap的基本结构
1.数组与链表的结构
1.1 数组
是一个线性表数据结构,它用一组连续的内存空间来存储一组具有相同类型的数据结构。
特点:
- 静态数据结构:数组在创建时就有固定的大小,一旦创建,其大小不可改变。
- 每一个元素都有索引,且是连续的,通过索引下标查询数据时间复杂度为O(1)。故,查询快~
- 数组的大小是固定的,所以当数组需要插入、删除时,就涉及到了扩容,Java中数组是不支持动态扩容的。故,插入、删除慢~
- 边界检查:Java数组在访问元素时会进行边界检查,如果越界,会抛出ArrayIndexOutOfBoundsException。
1.2 链表
是一系列节点组成的集合,不要求连续的内存空间,每个节点存储着指向下个节点的引用。
特点:
- 不是连续的内存空间存储,查询时需要遍历全链表。故,查询慢O(n)~但是如果查询头节点、尾节点,可以直接通过方法获取O(1)
- 链表的长度不是固定的,可以动态增加或减少
- 链表插入或删除数据的时候,可以通过改变节点的指针实现。故,插入、删除快~时间复杂度O(1)
- 无边界检查:链表不进行边界检查,访问节点时不会抛出ArrayIndexOutOfBoundsException。
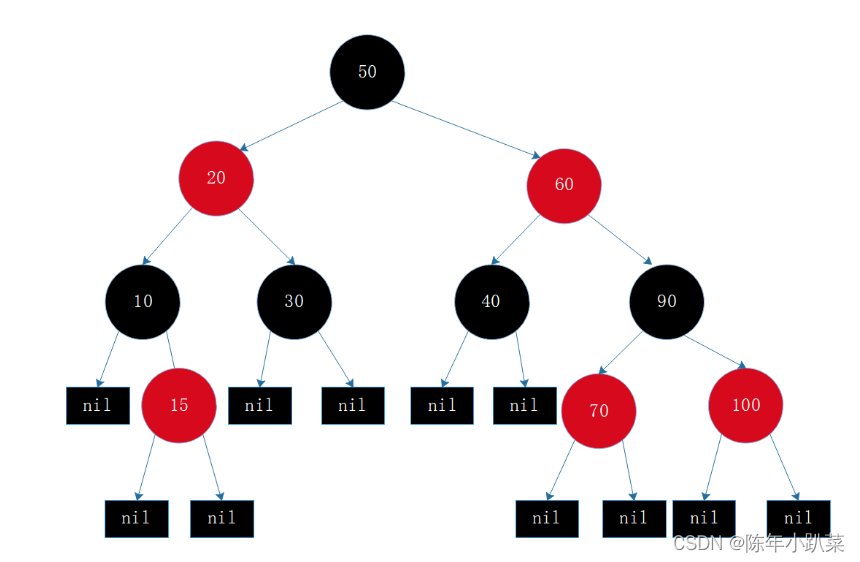
2.红黑树的简单介绍
是一个黑色完美平衡的二叉树,即任意节点到每个叶子节点路径中黑色节点的数量相同,这一特性又称黑高。
特点:
- 节点要么是红色,要么是黑色
- 两个红色节点不能相连
- 根节点一定是黑色的
- 黑高
- 每个叶子节点(NIL)是黑色的
3.Node节点的组成
- final int hash; # 节点键的hash值,HashMap使用这个哈希值来快速定位数组的索引,存储和检索键值对
- final K key; # 节点key,键是唯一标识,用于获取值
- V value; # 节点键对应的值
- Node<K,V> next; # 节点指向的下一个节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
return o instanceof Map.Entry<?, ?> e
&& Objects.equals(key, e.getKey())
&& Objects.equals(value, e.getValue());
}
}
二、HashMap的哈希函数
1.hashCode()方法的作用
- hashCode()是Object类的方法
- 通过hashCode()方法可以进行字符串加密生成哈希码,且不可逆。通过哈希码确定键值对的位置
理想情况下,hashCode()方法应该为不同的对象生成不同的哈希码,以减少哈希冲突的概率。然而,在实际应用中,可能会出现不同的对象产生相同哈希码的情况,这种现象称为哈希冲突。为了处理哈希冲突,HashMap使用了链表和红黑树的数据结构来存储具有相同或相近哈希码的键值对。
2.位运算与哈希值的计算
在HashMap的源码中大量用到了位运算与运算的地方。
在HashMap中,hashCode()方法返回的哈希码通常是一个整型值。为了将这个哈希码转换成内部数组的索引,HashMap使用了位运算。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里的^是按位异或运算符,>>>是无符号右移运算符。
这种运算可以确保哈希码的高位和低位都被用于索引的计算,从而减少哈希冲突的概率。
3.扰动函数的作用
HashMap的hash方法用于计算键的哈希码,并将其转换为哈希表的索引。这个方法确实使用了位运算来扰动哈希码,但是具体的实现稍微有所不同。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个方法会首先计算键的哈希码h(h = key.hashCode()),然后将其无符号右移16位(h >>> 16),并与原始哈希码进行异或运算。这样做的目的是将高位的特征和低位的特征混合起来,以减少哈希冲突。
然而,这个扰动的哈希码并不直接用作数组的索引。在Java 8中,HashMap的数组长度必须是2的幂,因此数组的索引是通过下面的方式计算的:
(n - 1) & hash
这里的n是数组的长度,hash是上面计算的扰动哈希码。(n - 1)是一个所有位都是1的二进制数(例如,如果n是16,那么(n - 1)是0b1111),这样做的效果是取模运算,但是位运算通常比模运算快得多。
在Java 8中,还有一个重要的优化,当链表的长度超过一定阈值时,链表会转换为红黑树,以提高性能。
思考:为什么HashMap源码中使用位运算
在HashMap中使用位运算是为了提高哈希分布的均匀性,减少哈希冲突的概率,从而提高整体的性能。以下是使用位运算的几个原因:
- 速度:位运算通常比其他数学运算要快,因为它们直接在数字的二进制表示上操作,而现代计算机的CPU对位运算有直接的硬件支持。
- 均匀分布:通过位运算,可以将哈希码的高位和低位混合,从而使得哈希码的每个位都对最终的索引结果产生影响。这样可以减少哈希码中某些位总是为零或总是为一的情况,使得哈希值更加均匀地分布在哈希表中。
- 减少哈希冲突:哈希冲突是指两个不同的键产生了相同的哈希值。通过位运算,可以增加哈希值的独特性,减少冲突的可能性。
- 适应不同容量:HashMap的容量通常是2的幂次方,使用位运算可以很容易地计算出哈希值在哈希表中的位置。例如,如果哈希表的容量是
2^n,那么可以通过hash & (2^n - 1)来计算索引,这里的&是按位与运算符,它等价于hash % 2^n,但执行速度更快。 - 利用CPU缓存:现代CPU缓存行通常是一次性加载一块数据,而位运算可以帮助优化数据的内存布局,使得哈希表中的元素更可能被加载到同一缓存行中,从而提高缓存利用率。
在HashMap中,扰动函数通常包括将哈希码的高16位与低16位进行异或运算,这样可以确保哈希码的每个位都对索引结果有影响,从而提高哈希表的性能。