文章链接:https://arxiv.org/pdf/2403.06845.pdf
项目文档:https://drivedreamer2.github.io/
自动驾驶是最近几年非常火热的方向,那LLM和视频生成在自动驾驶领域有哪些应用呢?今天和大家一起学习一下最新的一篇工作————DriveDreamer-2。
DriveDreamer-2展示了在生成多视角驾驶视频方面的强大能力。DriveDreamer-2可以根据用户的描述生成驾驶视频,这提高了合成数据的多样性。此外,DriveDreamer-2的生成质量超过了其他最先进的方法,并有效地增强了下游任务。

世界模型在自动驾驶中表现出优势,特别是在生成多视角驾驶视频方面。然而,在生成定制驾驶视频方面仍然存在重大挑战。DriveDreamer-2,它是在DriveDreamer框架的基础上增加了一个大语言模型(LLM),用于生成用户定义的驾驶视频。具体而言,首先引入了一个LLM接口,将用户的query转换为agent轨迹。随后,根据这些轨迹生成符合交通规则的高精地图。最后提出了统一的多视角模型,以增强生成的驾驶视频的时间和空间一致性。DriveDreamer-2是第一个能够生成定制驾驶视频的世界模型,它可以以用户友好的方式生成不常见的驾驶视频(例如,车辆突然变道插车)。另外,实验结果表明,生成的视频提高了驾驶感知方法(例如,3D检测和跟踪)的训练效果。此外,DriveDreamer-2的视频生成质量超过了其他最先进的方法,展示了FID和FVD分别为11.2和55.7的得分,相对改进约为30%和50%。
介绍
近年来,自动驾驶的世界模型引起了行业和学术界的广泛关注。由于其出色的预测能力,自动驾驶世界模型有助于生成各种各样的驾驶视频,甚至包括长尾场景。生成的驾驶视频可以用于增强各种驾驶感知方法的训练,对自动驾驶的实际应用非常有益。
自动驾驶中的世界建模面临着巨大的挑战,这是由于其固有的复杂性和大量的采样空间所致。早期的方法通过将世界建模纳入鸟瞰图(BEV)语义分割空间中来缓解这些问题。然而,这些方法主要是在模拟自动驾驶环境中探索世界模型。
在自动驾驶技术的最新发展中,世界模型的发展取得了重大进展。这一进展得益于利用先进的扩散模型,如DriveDreamer、Drive-WM、MagicDrive、Panacea,以及像GAIA1、ADriver-I 这样的大语言模型的集成。这些复杂的模型在推动世界建模能力的界限方面发挥了关键作用,使研究人员和工程师能够深入研究越来越复杂和逼真的驾驶场景。然而,值得注意的是,这些方法中大多数都严重依赖结构化信息(例如3D框、高精地图和光流)或真实世界的图像帧作为条件。这种依赖不仅限制了交互性,还限制了生成视频的多样性。
为了解决上述挑战,我们提出了DriveDreamer-2,这是第一个以用户友好的方式生成多样化驾驶视频的世界模型。与之前依赖于特定数据集或复杂注释的结构化条件的方法不同,DriveDreamer-2强调通过模拟各种交通条件并提供用户友好的文本提示来生成定制的驾驶视频。
具体而言,交通模拟任务已经分解为生成前景条件(自车和其他agent车辆的轨迹)和背景条件(车道边界、车道分隔线和人行横道的高精地图)。对于前景生成,构建了一个函数库来微调大语言模型(LLM),使其能够根据用户的文本输入生成agent车辆的轨迹。对于背景条件,提出了使用扩散模型来模拟道路结构的高精地图生成器。在这个过程中,先前生成的agent车辆轨迹被作为条件输入,这使得高精地图生成器能够学习驾驶场景中前景和背景条件之间的关联。
在生成的交通结构化条件的基础上,采用DriveDreamer 框架来生成多视角驾驶视频。值得注意的是,在DriveDreamer框架内引入了统一的多视角视频模型(UniMVM),旨在统一视图内和跨视图的空间一致性,增强生成驾驶视频的整体时间和空间一致性。
大量的实验结果表明,DriveDreamer-2能够生成多样化的用户定制视频,包括车辆突然变道等不寻常的场景(如图1所示)。此外,DriveDreamer-2可以生成质量高的驾驶视频,其FID为11.2,FVD为55.7,相对于之前表现最好的方法,改进了约30%和约50%。此外,还进行了实验验证,证明DriveDreamer-2生成的驾驶视频可以增强各种自动驾驶感知方法的训练,其中检测和跟踪的性能分别提高了约4%和约8%。
本文的主要贡献总结如下:
-
提出了DriveDreamer-2,这是第一个以用户友好的方式生成多样化驾驶视频的世界模型。
-
提出了一种交通模拟pipeline,仅使用文本提示作为输入,可用于生成驾驶视频的多样化交通条件。
-
提出了UniMVM,以无缝方式整合了视图内和视图间的空间一致性,提高了生成的驾驶视频的整体时空一致性。
-
大量实验表明DriveDreamer-2能够制作多样化的定制驾驶视频。此外,与先前性能最佳的方法相比,DriveDreamer-2将FID和FVD提高了约30%和约50%。此外,DriveDreamer-2生成的驾驶视频提高了各种驾驶感知方法的训练效果。
相关工作
世界模型
世界模型的主要目标是建立动态环境模型,赋予agent对未来的预测能力。在早期的探索中,变分自编码器(VAE)和长短期记忆网络(LSTM)被用来捕捉转换动态和渲染功能,在各种应用中取得了显著的成功。
构建驾驶世界模型面临着独特的挑战,主要源于现实世界驾驶任务中固有的高样本复杂性。为了解决这些挑战,ISO-Dream 引入了将视觉动态显式分解为可控和不可控状态的方法。MILE 在鸟瞰图(BEV)语义分割空间内战略性地将世界建模纳入其中。最近,DriveDreamer、GAIA1、ADriver-I 和 Drive-WM 探索了在现实世界中训练驾驶世界模型,利用了强大的扩散模型或自然语言模型。然而,这些方法中大多数都严重依赖结构化信息(例如3D框、高精地图和光流)作为条件。这种依赖不仅限制了交互性,还限制了生成的多样性。
视频生成
视频生成和预测是理解视觉世界的关键技术。在视频生成的早期阶段,探索了诸如变分自编码器(VAEs)、基于流的模型和生成对抗网络(GANs)等方法。语言模型也被用于复杂的视觉动态建模。近年来的进展使得扩散模型将其影响扩展到了视频生成领域。值得注意的是,视频扩散模型在生成具有逼真帧和流畅过渡的高质量视频方面表现出优越能力,提供了增强的可控性。这些模型可以无缝地适应各种输入条件,包括文本、canny、素描、语义地图和深度图。在自动驾驶领域,DriveDreamer-2利用强大的扩散模型来学习视觉动态。
交通模拟
驾驶模拟器是自动驾驶开发的基石,旨在提供一个受控环境,模拟真实世界的条件。LCTGen利用LLM将详细的语言描述编码为向量,然后利用生成器生成相应的模拟场景。这种方法需要非常详细的语言描述,包括agent的速度和方向等信息。TrafficGen理解交通场景中的内在关系,使得在同一地图内生成多样化且合法的交通流成为可能。
CTG通过使用手动设计的损失函数来生成交通模拟,这些损失函数符合交通约束条件。CTG++通过利用GPT-4将用户的语言描述转换为损失函数,指导场景级别的条件扩散模型生成相应的场景,进一步扩展了CTG。在DriveDreamer-2中,我们构建了一个函数库来微调LLM,实现了用户友好的文本到交通模拟,消除了复杂的损失设计或复杂的文本提示输入。
DriveDreamer-2

上图2 展示了DriveDreamer-2的整体框架。首先提出了一种定制的交通模拟,用于生成前景agent轨迹和背景高精地图。具体而言,DriveDreamer-2利用微调的LLM将用户提示转换为agent轨迹,然后引入高精地图生成器,使用生成的轨迹作为条件来模拟道路结构。
利用定制的交通模拟pipeline,DriveDreamer-2能够为后续的视频生成提供生成多样化的结构化条件。在DriveDreamer的架构基础上,提出了UniMVM框架,统一了视图内和视图间的空间一致性,从而增强了生成的驾驶视频的整体时间和空间一致性。在接下来的部分中,我们将深入探讨定制交通模拟和UniMVM框架的细节。
定制交通模拟
在提出的定制交通模拟pipeline中,构建了一个轨迹生成函数库来微调LLM,从而将用户提示转换为包括变道和掉头等机动在内的多样化agent轨迹。此外,该pipeline还整合了高精地图生成器来模拟背景道路结构。在这个阶段,先前生成的agent轨迹作为条件输入,确保生成的高精地图符合交通约束。接下来将详细介绍LLM的微调过程和高精地图生成器的框架。
LLM轨迹生成的微调 传统的交通模拟方法需要详细指定参数,包括agent的速度、位置、加速度和任务目标等细节。为了简化这个复杂的过程,我们提出利用构建的轨迹生成函数库对LLM进行微调,从而实现将用户友好的语言输入高效地转换为全面的交通模拟场景。如图3所示,构建的函数库包含18个函数,包括agent函数(转向、匀速、加速和刹车)、行人函数(行走方向和速度)以及其他实用函数,如保存轨迹。
基于这些函数,手动策划了用于微调LLM(GPT-3.5)的文本到Python脚本对。这些脚本包括一系列基本场景,如变道、超车、跟随其他车辆和执行掉头。此外,我们还包括了更不寻常的场景,如行人突然穿越和车辆切入车道。以用户输入"一辆车切入"为例,相应的脚本包括以下步骤:首先生成切入的轨迹(agent.cut_in()),然后生成相应的自车轨迹(agent.forward()),最后利用实用工具中的保存函数直接输出自车和其他agent的轨迹数组格式。有关更多细节,请参阅补充材料。在推理阶段,遵循将提示输入扩展到预定义的模板,微调后的LLM可以直接输出轨迹数组。

高精地图生成 一个全面的交通模拟不仅涉及前景agent的轨迹,还需要生成背景高精地图元素,如车道和人行横道。因此,提出了高精地图生成器,以确保背景元素与前景轨迹不冲突。在高精地图生成器中,将背景元素的生成形式化为条件图像生成问题,其中条件输入是BEV轨迹地图,目标是BEV 高精地图 。与以往主要依赖于轮廓条件(边缘、深度、框、分割地图)的条件图像生成方法不同,所提出的高精地图生成器探索了前景和背景交通元素之间的相关性。
具体来说,高精地图生成器建立在图像生成扩散模型的基础上。为了训练生成器,策划了一个轨迹到高精地图的数据集。在轨迹地图中,分配不同颜色来表示不同的agent类别。同时,目标高精地图包括三个通道,分别表示车道边界、车道分隔线和人行横道。在高精地图生成器内部,使用2D卷积层的堆栈来整合轨迹地图条件。然后,利用[65]将生成的特征图无缝集成到扩散模型中(有关更多架构细节,请参见补充材料)。
在训练阶段,扩散前向过程逐渐将噪声添加到潜在特征中,产生噪声潜在特征。然后,训练来预测我们添加的噪声,并通过优化高精地图生成器进行优化:
(1)
其中时间步长是从均匀采样的。如下图4所示,利用提出的高精地图生成器可以基于相同的轨迹条件生成多样化的高精地图。值得注意的是,生成的高精地图不仅符合交通约束(车道边界位于车道分隔线的两侧,人行横道位于交叉口),而且与轨迹无缝集成。

UniMVM
利用定制交通模拟生成的结构化信息,可以通过DriveDreamer的框架生成多视角驾驶视频。然而,先前方法中引入的视图注意力不能保证多视角一致性。为了缓解这个问题,利用图像或视频条件生成多视角驾驶视频。虽然这种方法增强了不同视图之间的一致性,但却以降低生成效率和多样性为代价。在DriveDreamer-2中,我们在DriveDreamer框架中引入了UniMVM。UniMVM旨在统一生成具有和不具有相邻视图条件的多视角驾驶视频,从而确保在不影响生成速度和多样性的情况下保持时间和空间一致性。
公式 在多视角视频数据集中,是具有个视图的个图像序列,其中高度为,宽度为。设表示第个视图的样本,则多视角视频的联合分布可以通过以下方式获得
(2)
公式2表明,相邻视图视频可以通过多个生成步骤扩展,这是低效的。在提出的UniMVM中,从公式2中汲取灵感来扩展视图。然而,与Drive-WM 需要独立生成视图不同,UniMVM将多个视图统一为一个完整的补丁。具体来说,按照{FL,F,FR,BR,B,BL}的顺序连接多视角视频,以获得空间统一的图像。然后,我们可以获得多视角驾驶视频分布:
(3)
其中表示所有视图之一的mask。如图5所示,将UniMVM的范例与DriveDreamer 和Drive-WM 进行了比较。与这些对应方法相比,UniMVM将多个视图统一为一个完整的patch,用于视频生成而不引入跨视图参数。此外,通过调整mask ,可以完成各种驾驶视频生成任务。具体来说,当设置为mask未来帧时,UniMVM可以基于第一帧的输入实现未来视频预测。将m设置为mask{FL,FR,BR,B,BL}视图使UniMVM能够实现多视角视频外描,利用前视视频输入。此外,当m设置为mask所有视频帧时,UniMVM可以生成多视角视频,定量和定性实验验证了UniMVM能够生成时间和空间一致的视频,并提高了生成效率和多样性。

视频生成 基于UniMVM的公式,驾驶视频可以在DriveDreamer 的框架内生成。具体而言,我们的方法首先统一交通结构化条件,从而产生高精地图序列和3D框序列(是视频剪辑的帧数,是类别数)。
需要注意的是,3D框序列可以从agent轨迹中导出,而3D框的大小则根据相应的agent类别确定。与DriveDreamer不同,DriveDreamer-2中的3D框条件不再依赖于位置embedding和类别embedding。相反,这些框直接投影到图像平面上,起到控制条件的作用。这种方法消除了像DriveDreamer中引入额外控制参数的方式。
我们采用三个编码器将高精地图、3D框和图像帧embedding到潜在空间特征、和中。然后,我们将空间对齐的条件、与连接起来,以获得特征输入,其中是通过前向扩散过程从生成的嘈杂潜在特征。对于视频生成器的训练,通过去噪分数匹配优化所有参数(详见补充材料)。
实验
实验细节
数据集 训练数据集源自nuScenes数据集,包括700个训练视频和150个验证视频。每个视频包含大约20秒的录制镜头,由六个全景摄像头捕获。以12Hz的帧率计算,这累积到大约100万个可用于训练的视频帧。按照[56,58]的做法,预处理nuScenes数据集以计算12Hz的注释。具体来说,高精地图和3D框被转换为BEV视角以训练高精地图生成,这些注释被投影到像素坐标以训练视频生成。
训练 对于agent轨迹生成,我们使用GPT-3.5作为LLM。随后,利用构建的文本到脚本数据集来微调GPT3.5,使其成为具有专业轨迹生成知识的LLM。所提出的高精地图生成器基于SD2.1,其中ControlNet参数可训练。高精地图生成器经过55K次训练迭代,batch大小为24,分辨率为512×512。对于视频生成器,利用了SVD强大的视频生成能力,并对所有参数进行微调。在视频生成器的训练过程中,模型经过了200K次迭代训练,batch大小为1,视频帧长度为 = 8,视图数量为 = 6,空间大小为256×448。所有实验均在NVIDIA A800 (80GB) GPU上进行,并使用AdamW优化器,学习率为。
评估 进行了大量的定性和定量实验来评估DriveDreamer-2。对于定性实验,可视化定制驾驶视频生成,以验证DriveDreamer-2能够以用户友好的方式生成多样化的驾驶视频。此外,进行了UniMVM和其他生成范式的可视化比较,以展示DriveDreamer-2在生成时间和空间一致性的视频方面的优势。对于定量实验,使用逐帧Fréchet Inception距离(FID)和Fréchet视频距离(FVD)作为度量标准。此外,StreamPETR 基于ResNet-50 骨干,在相同分辨率256×448上进行训练,以评估我们生成的结果对3D目标检测和多目标跟踪的改进。更多细节可以在补充材料中找到。
用户定制驾驶视频生成
DriveDreamer-2提供了一个用户友好的界面来生成驾驶视频。如图1a所示,用户只需输入一个文本提示(例如,在雨天,有一辆车突然变道切入)。然后DriveDreamer-2会生成与文本输入对齐的多视角驾驶视频。图6展示了另外两个定制的驾驶视频。上面一个展示了自车在白天变换车道的过程。下面一个展示了一个意外的行人在夜间横穿马路,促使自车刹车以避免碰撞。值得注意的是,生成的视频展示了出色的逼真度,我们甚至可以观察到高亮灯在行人身上的反射。

生成视频质量评估
为了验证视频生成质量,我们将DriveDreamer-2与各种驾驶视频生成方法在nuScenes验证集上进行了比较。为了进行公平比较,在三种不同的实验设置下进行了评估——无图像条件、有视频条件和有第一帧多视角图像条件。实验结果如表1所示,表明DriveDreamer-2在所有三种设置下始终实现了高质量的评估结果。具体来说,在没有图像条件的情况下,DriveDreamer-2实现了25.0的FID和105.1的FVD,相对于DriveDreamer实现了显著改进。此外,尽管受限于单视角视频条件,与使用三视角视频条件的DriveWM相比,DriveDreamer-2在FVD上表现出39%的相对改进。此外,当提供第一帧多视角图像条件时,DriveDreamer-2实现了11.2的FID和55.7的FVD,远远超过所有先前的方法。

为了进一步验证生成数据的质量,利用生成的驾驶视频来增强3D目标检测和多目标跟踪的训练。具体来说,利用nuScenes训练集中的所有结构化条件生成驾驶视频,将这些视频与真实视频结合起来,在下游任务上训练StreamPETR。实验结果如下面表2和表3所示。当使用初始帧作为条件时,生成的视频在增强下游任务性能方面表现出有效性。3D检测指标mAP和NDS分别相对提高了2.8%和3.9%。此外,跟踪指标AMOTA和AMOTP分别显示了相对增强8.0%和1.6%。

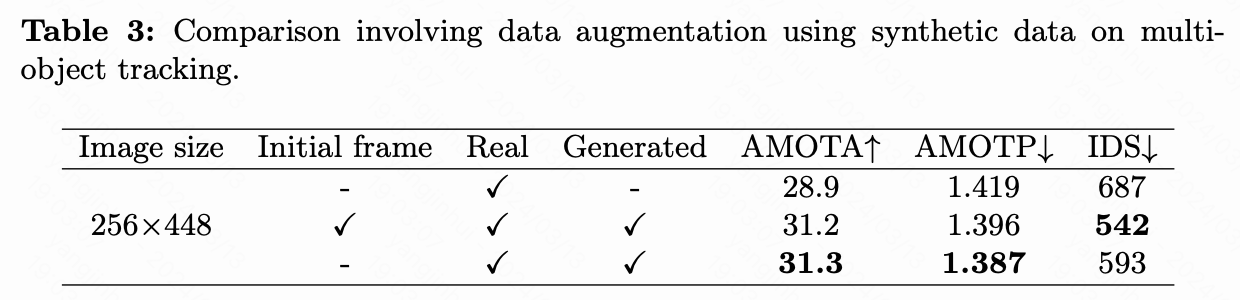
此外,DriveDreamer-2能够在没有图像条件的情况下生成高质量的驾驶视频。去除图像条件会导致生成内容的多样性增加,从而进一步提高下游任务的性能指标。具体而言,与基线相比,3D检测的mAP和NDS分别显示了3.8%和4.4%的相对改善,而跟踪任务的AMOTA和AMOTP分别显示了8.3%和2.3%的提升。
消融研究
我们进行了消融研究,以探究扩散骨干和提出的UniMVM的影响,结果如下表4所示。与DriveDreamer中使用的SD1.4相比,SVD 提供了更丰富的视频先验知识,导致了17.2的FID和94.6的FVD。引入SVD导致FVD几乎提高了70%。此外,还注意到FID略有下降,我们推测这归因于引入了跨视图模块,破坏了SVD学习空间特征的能力。
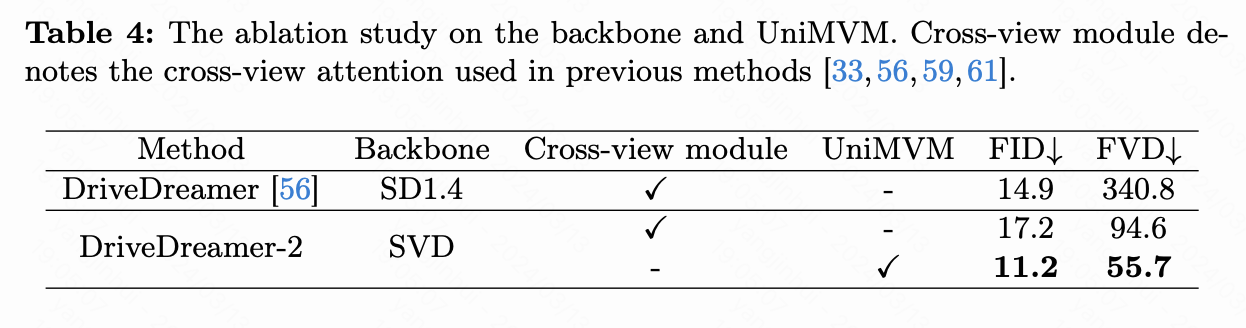
为了充分发挥SVD在多视图视频生成中的潜力,我们提出了UniMVM,它统一了对视图内和视图间的约束,实现了显著的FID和FVD得分,分别为11.2和55.7。与DriveDreamer相比,这分别表示了约30%和约80%的相对改善。如下图7所示,在每个比较对中,上排是由未使用UniMVM的DriveDreamer-2生成的,而下排是由使用UniMVM的DriveDreamer-2生成的。在没有UniMVM的情况下,DriveDreamer-2在视图之间生成了不一致的结果,包括前景车辆和背景结构。引入UniMVM显著提高了生成多视图视频的能力,无论是在前景还是背景方面。定性结果展示了我们的UniMVM在实现多视图一致性方面的卓越能力。

我们还探讨了各种条件对驾驶视频生成的影响,如下面表5和图8所示。图8中的第一行展示了第一帧的真实情况,代表了GT视频的风格。与此同时,第二行显示了第二帧的真实情况,代表了生成的多视角帧的GT。使用初始帧的DriveDreamer-2可以生成与GT视频非常相似的结果,在FID和FVD方面实现了最佳结果,分别为11.2和55.7。使用前视视频的DriveDreamer-2保留了GT场景的一些方面,同时也引入了一些多样性,导致了17.2的FID和94.6的FVD。即使在没有任何图像条件的情况下,DriveDreamer-2也可以生成极具竞争力的结果,实现了FID和FVD分别为25.0和105.1。值得注意的是,在这种情况下,DriveDreamer-2展现出最高的多样性,生成的汽车外观和街道背景与真实情况有很大的不同。


讨论与结论
本文介绍了DriveDreamer-2,这是DriveDreamer框架的创新扩展,开创了用户定制驾驶视频的生成。利用大语言模型,DriveDreamer-2首先将用户query转换为前景agent轨迹。然后,可以使用提出的高精地图生成器生成背景交通条件,其中包括agent轨迹作为条件。生成的结构化条件可以用于视频生成,我们提出了UniMVM来增强时间和空间上的一致性。广泛的实验验证了DriveDreamer-2可以生成不寻常的驾驶视频,比如车辆突然的一些动作。
重要的是,实验结果展示了生成视频在增强驾驶感知方法训练中的效用。此外,DriveDreamer-2在视频生成质量方面表现出色,相比最先进的方法,实现了分别为11.2和55.7的FID和FVD分数。这些分数代表了大约30%和50%的显著相对改进,证实了DriveDreamer-2在多视角驾驶视频生成中的功效和进步。
参考文献
[1] DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术,添加小助手