正文共:888 字 7 图,预估阅读时间:1 分钟
前面我们使用PyTorch将Tesla M4跑起来之后(成了!Tesla M4+Windows 10+Anaconda+CUDA 11.8+cuDNN+Python 3.11),一直有个问题,那就是显存容量的问题。
测试中,使用的Python脚本中有这样几行:
size = (10240, 10240)
input_cpu = torch.randn(size)
input_gpu = input_cpu.to(torch.device('cuda'))其中,torch是深度学习框架PyTorch库的一个常用缩写;randn是PyTorch中的一个函数,用于生成具有标准正态分布(也称为高斯分布)的随机数(均值为0,方差为1);而size定义了生成张量的形状和大小,(10240, 10240)表示创建一个二维张量,第一维度有1024行,第二维度有1024列,得到一个1024*1024的矩阵,每个点对应一个浮点数,一共有1,048,576个浮点数。
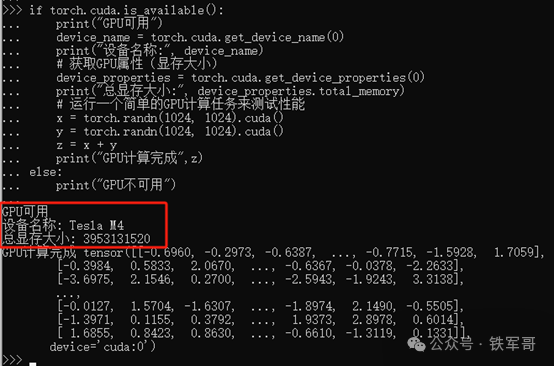
从输出的数值来看,每个浮点数有4位小数点,整数位至少为1位,还分正负,最多有20万种可能,如果按照2为底数来计算,至少需要2的16次方(262144)才能包含;通过查阅资料,randn生成的浮点数使用float32保存,占用4字节空间。
于是,当我们将张量定义到(102400, 102400)时,出现了内存不足的情况,提示需要41,943,040,000字节,这么算下来每个浮点数确实是占用4字节大小的内存。
当我们将张量定义到(51200, 51200)时,出现了显存不足的情况,提示需要9.77 GB的显存。如果也按照每个浮点数占用4字节大小,一共是10,485,760,000字节,按照1024进制计算,一共是9.765625 GB,跟提示的9.77 GB相符。
如此说来,执行等量的运算,CPU运算占用的内存与GPU运算占用的显存是一样的,那Tesla M4这4 GB的小显存有点吃亏啊,看来得换成24 GB的大显存才好使啊,但是24 GB显存的Tesla P40是全高双插槽的GPU,得换大个的服务器才能使,还得再等等。
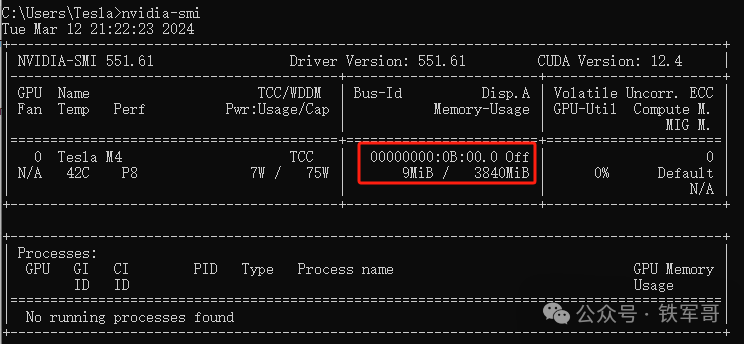
而按照回显显示的3840MB(3953131520字节)大小,最多可以分配31436*31436个浮点数,实际设置成(30000,30000)执行一下。
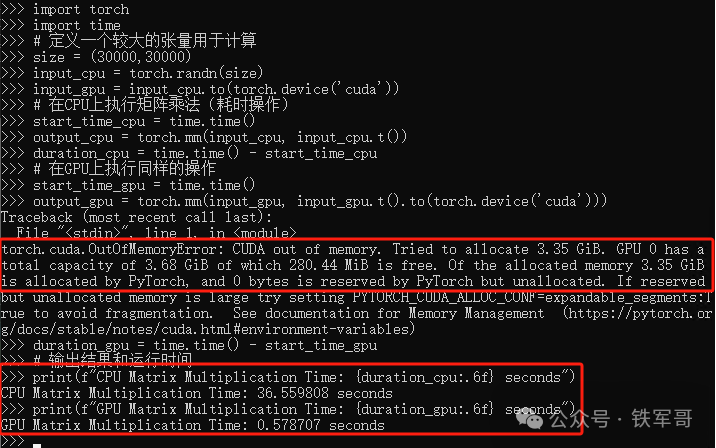
提示CUDA out of memory,还是超了,虽然只需要3.35 GB显存,但为什么会超呢?而且运算中有提示,显存的3.35 GB已经分配给了PyTorch(Of the allocated memory 3.35 GiB is allocated by PyTorch),那为什么会需要两个3.35 GB显存呢?
报错是在output_gpu = torch.mm(input_gpu, input_gpu.t().to(torch.device('cuda')))后面,在这条命令里:
input_gpu是已经在CUDA GPU设备上的张量,对应input_gpu = input_cpu.to(torch.device('cuda')),表示将位于CPU上的张量input_cpu 转移到GPU设备上,约等于input_gpu = torch.randn(size),但实际效果有所不同,具体等会看;
input_gpu.t()中的.t()用于计算并返回张量的转置(行变成列、列变成行);
torch.mm()函数则是进行矩阵乘法运算,即对input_gpu与它的转置input_gpu.t()进行矩阵乘法运算。
那要这么看,我是不是可以仅对GPU进行运算?
import torch
import time
output_gpu = None
size = (30000,30000)
input_gpu = torch.randn(size)
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t())
duration_gpu = time.time() - start_time_gpu
output_gpu = None
print(f"GPU Matrix Multiplication Time: {duration_gpu:.6f} seconds")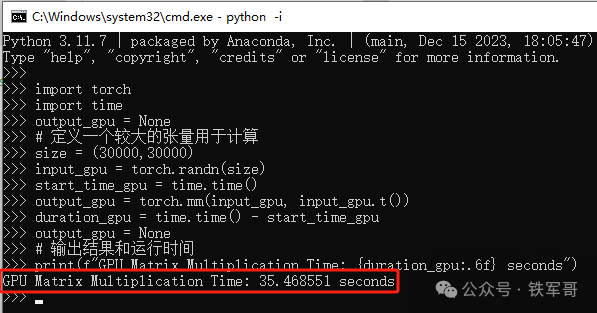
难道可行?这次GPU没有报错,但出现了一个问题,没有调用GPU设备,还是使用CPU运算的。
调用GPU设备试一下。
import torch
import time
size = (30000,30000)
input_gpu = torch.randn(size, device=torch.device('cuda'))
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t())
duration_gpu = time.time() - start_time_gpu
output_gpu = None
print(f"GPU矩阵乘法运行时间: {duration_gpu:.6f} 秒")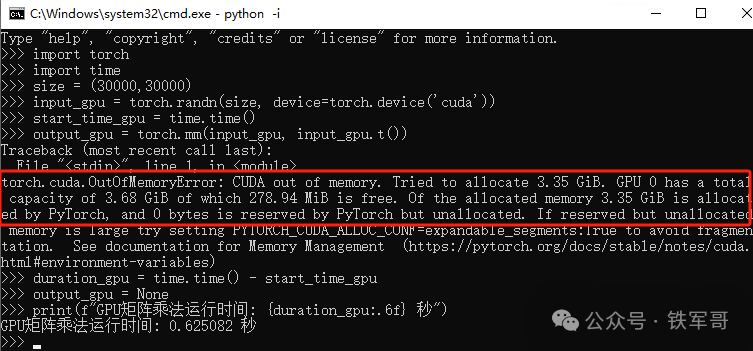
接下来,我们考虑为什么会占用2个3.35 GB,应该是input_gpu占用了3.35 GB,之后input_gpu.t()又要占用3.35 GB,导致显存不足;及时如此,生成的结果还可能会占用1个3.35 GB,这样一来,显存明显就不够了。
这样的话,实际应该按照1920 MB来计算张量,也就是(21000,21000),测试一下。
import torch
import time
size = (21000,21000)
input_gpu = torch.randn(size, device=torch.device('cuda'))
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t())
duration_gpu = time.time() - start_time_gpu
print(f"GPU矩阵乘法运行时间: {duration_gpu:.6f} 秒")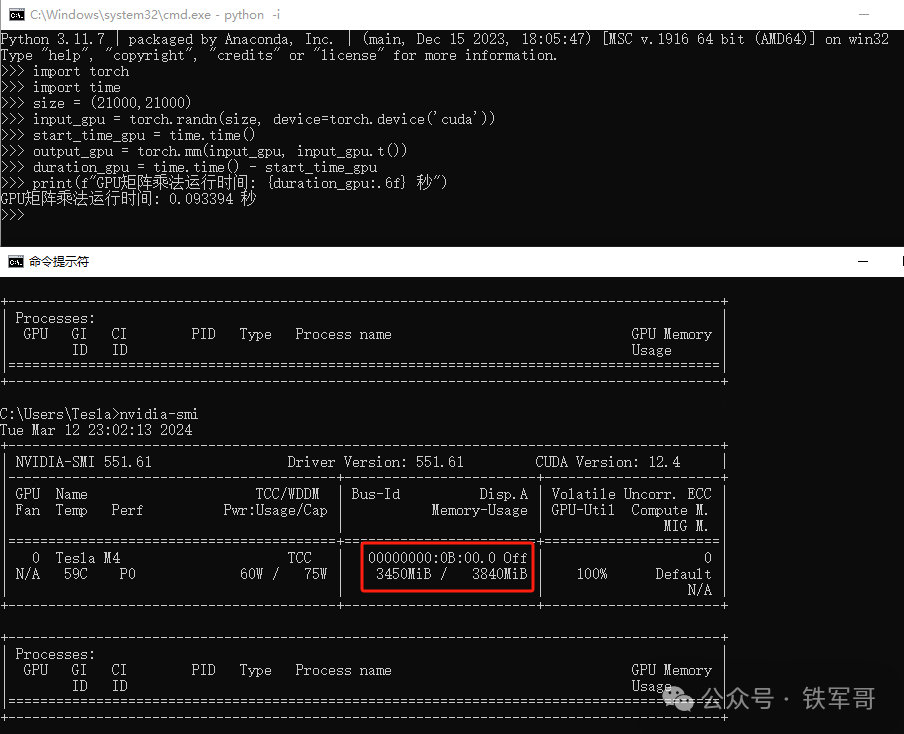
果然,就是这个原因,(21000,21000)实际对应1682 MB显存,两倍的话就是3364 MB,加上一部分其他占用,与最终的3450 MB差不多。
按照这个张量,再对比一下CPU和GPU的性能。
import torch
import time
size = (21000,21000)
input_cpu = torch.randn(size)
input_gpu = input_cpu.to(torch.device('cuda'))
# 在CPU上执行矩阵乘法(耗时操作)
start_time_cpu = time.time()
output_cpu = torch.mm(input_cpu, input_cpu.t())
duration_cpu = time.time() - start_time_cpu
# 在GPU上执行同样的操作
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t().to(torch.device('cuda')))
duration_gpu = time.time() - start_time_gpu
print(f"CPU矩阵乘法运行时间: {duration_cpu:.6f} 秒")
print(f"GPU矩阵乘法运行时间: {duration_gpu:.6f} 秒")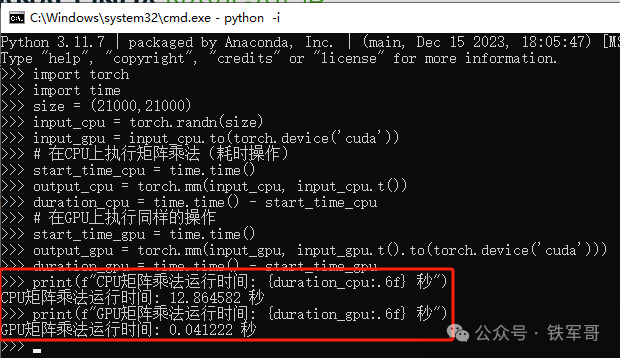
CPU耗时为GPU的312倍,说明GPU的运算效率大约是CPU的312倍吧。

长按二维码
关注我们吧


成了!Tesla M4+Windows 10+Anaconda+CUDA 11.8+cuDNN+Python 3.11
人工智能如何发展到AIGC?解密一份我四年前写的机器学习分享材料
一起学习几个简单的Python算法实现
MX250笔记本安装Pytorch、CUDA和cuDNN
复制成功!GTX1050Ti换版本安装Pytorch、CUDA和cuDNN
Windows Server 2019配置多用户远程桌面登录服务器
Windows Server调整策略实现999999个远程用户用时登录
RDP授权119天不够用?给你的Windows Server续个命吧!
使用Python脚本实现SSH登录设备
配置VMware实现从服务器到虚拟机的一键启动脚本
CentOS 7.9安装Tesla M4驱动、CUDA和cuDNN
使用vSRX测试一下IPsec VPN各加密算法的性能差异