文章目录
- 1、YOLOv9 介绍
- 2、测试
- 2.1、官方Python测试
- 2.1.1、正确的脚本
- 2.2、Opencv dnn测试
- 2.2.1、导出onnx模型
- 2.2.2、c++测试代码
- 2.3、测试统计
- 3、自定义数据及训练
- 3.1、准备工作
- 3.2、训练
- 3.3、模型重参数化
1、YOLOv9 介绍
YOLOv9 是 YOLOv7 研究团队推出的最新目标检测网络,它是 YOLO(You Only Look Once)系列的最新迭代。YOLOv9 在设计上旨在解决深度学习中信息瓶颈问题,并提高模型在不同任务上的准确性和参数效率。
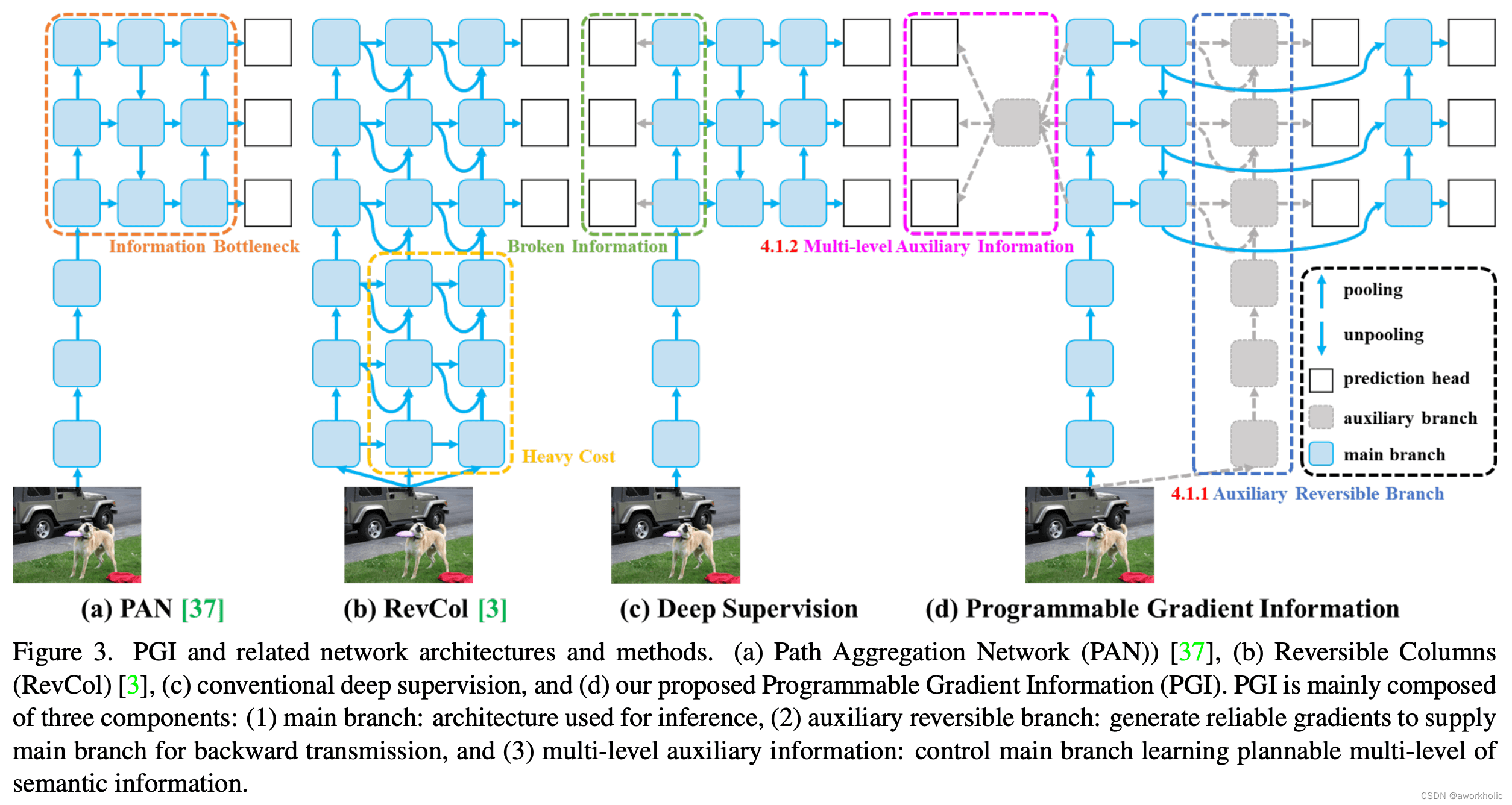
-
Programmable Gradient Information (PGI):YOLOv9 引入了可编程梯度信息(PGI)的概念,这是一种新的辅助监督框架,用于生成可靠的梯度信息,以便在训练过程中更新网络权重。PGI 通过辅助可逆分支来解决深度网络加深导致的问题,并提供完整的输入信息以计算目标函数。
-
Generalized Efficient Layer Aggregation Network (GELAN):YOLOv9 设计了一种新的轻量级网络架构 GELAN,它基于梯度路径规划。GELAN 通过使用传统的卷积操作,实现了比基于深度可分离卷积的最先进方法更好的参数利用率。
-
高效的性能:YOLOv9 在 MS COCO 数据集上的目标检测任务中取得了优异的性能,超越了所有先前的实时目标检测方法。它在准确性、参数利用率和计算效率方面都显示出了显著的优势
-
适用于不同规模的模型:PGI 可以应用于从轻量级到大型的多种模型,并且可以用于获得完整的信息,使得从头开始训练的模型能够达到或超越使用大型数据集预训练的最先进的模型。
-
改进的网络架构:YOLOv9 在网络架构上进行了改进,包括简化下采样模块和优化无锚点预测头。这些改进有助于提高模型的效率和准确性。训练策略:YOLOv9 遵循了 YOLOv7 AF 的训练设置,包括使用 SGD 优化器进行 500 个周期的训练,并在训练过程中采用了线性预热和衰减策略。
-
数据增强:YOLOv9 在训练过程中使用了多种数据增强技术,如 HSV 饱和度、值增强、平移增强、尺度增强和马赛克增强,以提高模型的泛化能力。
总的来说,YOLOv9 通过其创新的 PGI 和 GELAN 架构,以及对现有训练策略的改进,提供了一种高效且准确的目标检测解决方案,适用于各种规模的模型和不同的应用场景。
2、测试
使用Pip在一个Python>=3.8环境中安装ultralytics包,此环境还需包含PyTorch>=1.7。这也会安装所有必要的依赖项。
git clone https://github.com/WongKinYiu/yolov9.git
cd yolov9
pip install -r requirements.txt
提供的cooc预训练模型性能如下
| Model | Test Size | APval | AP50val | AP75val | Param. | FLOPs |
|---|---|---|---|---|---|---|
| YOLOv9-N (dev) | 640 | 38.3% | 53.1% | 41.3% | 2.0M | 7.7G |
| YOLOv9-S | 640 | 46.8% | 63.4% | 50.7% | 7.1M | 26.4G |
| YOLOv9-M | 640 | 51.4% | 68.1% | 56.1% | 20.0M | 76.3G |
| YOLOv9-C | 640 | 53.0% | 70.2% | 57.8% | 25.3M | 102.1G |
| YOLOv9-E | 640 | 55.6% | 72.8% | 60.6% | 57.3M | 189.0G |
2.1、官方Python测试
python detect.py --weights yolov9-c.pt --data data\coco.yaml --sources bus.jpg
注意,这里可能出现一个错误 fix solving AttributeError: 'list' object has no attribute 'device' in detect.py,在官方issues中可以找到解决方案,需要在将 detect.py 文件下面这种nms不分代码调整为
# NMS
with dt[2]:
pred = pred[0][1] if isinstance(pred[0], list) else pred[0]
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Second-stage classifier (optional)
之后重新运行正常。
以预训练的 yolov9-c.pt 模型为例测试:
CPU 0.8ms pre-process, 1438.7ms inference, 2.0ms NMS per image
GPU 0.7ms pre-process, 41.3ms inference, 1.4ms NMS per image
以预训练的简化模型 yolov9-c-converted.pt 为例测试:
CPU 0.9ms pre-process, 704.8ms inference, 1.6ms NMS per image
GPU 0.4ms pre-process, 22.9ms inference, 1.5ms NMS per image
从推理时间上,可以看出 converted 之后的模型执行时间降低了50%=,这个归功于模型重参数化,可以查看本文章最后一节内容。
2.1.1、正确的脚本
其实上面是错误的使用方式,可能库还没完善。目前推理、训练、验证个截断针对不同模型使用脚本文件是不同的
# inference converted yolov9 models
python detect.py --source './data/images/horses.jpg' --img 640 --device 0 --weights './yolov9-c-converted.pt' --name yolov9_c_c_640_detect
# inference yolov9 models
python detect_dual.py --source './data/images/horses.jpg' --img 640 --device 0 --weights './yolov9-c.pt' --name yolov9_c_640_detect
# inference gelan models
python detect.py --source './data/images/horses.jpg' --img 640 --device 0 --weights './gelan-c.pt' --name gelan_c_c_640_detect
2.2、Opencv dnn测试
2.2.1、导出onnx模型
按照惯例将pt转换为onnx模型,
python export.py --weights yolov9-c.pt --include onnx
输出如下:
(yolo_pytorch) E:\DeepLearning\yolov9>python export.py --weights yolov9-c.pt --include onnx
export: data=E:\DeepLearning\yolov9\data\coco.yaml, weights=['yolov9-c.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 v0.1-30-ga8f43f3 Python-3.9.16 torch-1.13.1+cu117 CPU
Fusing layers...
Model summary: 604 layers, 50880768 parameters, 0 gradients, 237.6 GFLOPs
PyTorch: starting from yolov9-c.pt with output shape (1, 84, 8400) (98.4 MB)
ONNX: starting export with onnx 1.14.0...
ONNX: export success 9.6s, saved as yolov9-c.onnx (194.6 MB)
Export complete (14.7s)
Results saved to E:\DeepLearning\yolov9
Detect: python detect.py --weights yolov9-c.onnx
Validate: python val.py --weights yolov9-c.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov9-c.onnx')
Visualize: https://netron.app
2.2.2、c++测试代码
测试代码和 yolov8一样。
参考前面博文 【opencv dnn模块 示例(23) 目标检测 object_detection 之 yolov8】训练部分。
2.3、测试统计
这里仅给出 yolov9-c-converted 的测试数据
python (CPU):704ms
python (GPU):22ms
opencv dnn(CPU):760ms
opencv dnn(GPU):27ms (使用opencv4.8相同的代码,gpu版本结果异常,cpu正常)
以下包含 预处理+推理+后处理:
openvino(CPU): 316ms
onnxruntime(GPU): 29ms
TensorRT:19ms
3、自定义数据及训练
3.1、准备工作
基本和yolov5以后的训练一样了,可以参考前面博文 【opencv dnn模块 示例(23) 目标检测 object_detection 之 yolov8】训练部分。
准备数据集,一个标注文件夹,一个图片文件夹,以及训练、测试使用的样本集图像序列(实际使用),

文件 myvoc.yaml 描述了数据集的情况,简单如下:
train: E:/DeepLearning/yolov9/custom-data/vehicle/train.txt
val: E:/DeepLearning/yolov9/custom-data/vehicle/val.txt
# number of classes
nc: 4
# class names
names: ["car", "huoche", "guache", "keche"]
3.2、训练
之后直接训练,例如使用 yolov9-c 模型训练,脚本如下:
python train_dual.py --device 0 --batch 8 --data custom-data/vehicle/myvoc.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 50 --close-mosaic 15
运行过程前3次可能出现 AttributeError: 'FreeTypeFont' object has no attribute 'getsize' 错误,可以选择更新 Pillow 版本即可。
(yolo_pytorch) E:\DeepLearning\yolov9>python train_dual.py --device 0 --batch 8 --data custom-data/vehicle/myvoc.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 50 --close-mosaic 15
train_dual: weights='', cfg=models/detect/yolov9-c.yaml, data=custom-data/vehicle/myvoc.yaml, hyp=hyp.scratch-high.yaml, epochs=50, batch_size=8, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=0, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs\train, name=yolov9-c, exist_ok=False, quad=False, cos_lr=False, flat_cos_lr=False, fixed_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, min_items=0, close_mosaic=15, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
YOLO v0.1-61-g3e4f970 Python-3.9.16 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce GTX 1080 Ti, 11264MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, cls_pw=1.0, obj=0.7, obj_pw=1.0, dfl=1.5, iou_t=0.2, anchor_t=5.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.9, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.15, copy_paste=0.3
ClearML: run 'pip install clearml' to automatically track, visualize and remotely train YOLO in ClearML
Comet: run 'pip install comet_ml' to automatically track and visualize YOLO runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=4
from n params module arguments
0 -1 1 0 models.common.Silence []
1 -1 1 1856 models.common.Conv [3, 64, 3, 2]
2 -1 1 73984 models.common.Conv [64, 128, 3, 2]
3 -1 1 212864 models.common.RepNCSPELAN4 [128, 256, 128, 64, 1]
4 -1 1 164352 models.common.ADown [256, 256]
5 -1 1 847616 models.common.RepNCSPELAN4 [256, 512, 256, 128, 1]
6 -1 1 656384 models.common.ADown [512, 512]
7 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1]
8 -1 1 656384 models.common.ADown [512, 512]
9 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1]
10 -1 1 656896 models.common.SPPELAN [512, 512, 256]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 7] 1 0 models.common.Concat [1]
13 -1 1 3119616 models.common.RepNCSPELAN4 [1024, 512, 512, 256, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 5] 1 0 models.common.Concat [1]
16 -1 1 912640 models.common.RepNCSPELAN4 [1024, 256, 256, 128, 1]
17 -1 1 164352 models.common.ADown [256, 256]
18 [-1, 13] 1 0 models.common.Concat [1]
19 -1 1 2988544 models.common.RepNCSPELAN4 [768, 512, 512, 256, 1]
20 -1 1 656384 models.common.ADown [512, 512]
21 [-1, 10] 1 0 models.common.Concat [1]
22 -1 1 3119616 models.common.RepNCSPELAN4 [1024, 512, 512, 256, 1]
23 5 1 131328 models.common.CBLinear [512, [256]]
24 7 1 393984 models.common.CBLinear [512, [256, 512]]
25 9 1 656640 models.common.CBLinear [512, [256, 512, 512]]
26 0 1 1856 models.common.Conv [3, 64, 3, 2]
27 -1 1 73984 models.common.Conv [64, 128, 3, 2]
28 -1 1 212864 models.common.RepNCSPELAN4 [128, 256, 128, 64, 1]
29 -1 1 164352 models.common.ADown [256, 256]
30 [23, 24, 25, -1] 1 0 models.common.CBFuse [[0, 0, 0]]
31 -1 1 847616 models.common.RepNCSPELAN4 [256, 512, 256, 128, 1]
32 -1 1 656384 models.common.ADown [512, 512]
33 [24, 25, -1] 1 0 models.common.CBFuse [[1, 1]]
34 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1]
35 -1 1 656384 models.common.ADown [512, 512]
36 [25, -1] 1 0 models.common.CBFuse [[2]]
37 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1]
38[31, 34, 37, 16, 19, 22] 1 21549752 models.yolo.DualDDetect [4, [512, 512, 512, 256, 512, 512]]
yolov9-c summary: 962 layers, 51006520 parameters, 51006488 gradients, 238.9 GFLOPs
AMP: checks passed
optimizer: SGD(lr=0.01) with parameter groups 238 weight(decay=0.0), 255 weight(decay=0.0005), 253 bias
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning E:\DeepLearning\yolov9\custom-data\vehicle\train.cache... 998 images, 0 backgrounds, 0 corrupt: 100%|██████████| 998/998 00:00
val: Scanning E:\DeepLearning\yolov9\custom-data\vehicle\val.cache... 998 images, 0 backgrounds, 0 corrupt: 100%|██████████| 998/998 00:00
Plotting labels to runs\train\yolov9-c4\labels.jpg...
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs\train\yolov9-c4
Starting training for 50 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
0/49 9.46G 5.685 6.561 5.295 37 640: 0%| | 0/125 00:04Exception in thread Thread-5:
Traceback (most recent call last):
File "D:\Python\anaconda3\envs\yolo_pytorch\lib\threading.py", line 980, in _bootstrap_inner
self.run()
File "D:\Python\anaconda3\envs\yolo_pytorch\lib\threading.py", line 917, in run
self._target(*self._args, **self._kwargs)
File "E:\DeepLearning\yolov9\utils\plots.py", line 300, in plot_images
annotator.box_label(box, label, color=color)
File "E:\DeepLearning\yolov9\utils\plots.py", line 86, in box_label
w, h = self.font.getsize(label) # text width, height
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
WARNING TensorBoard graph visualization failure Only tensors, lists, tuples of tensors, or dictionary of tensors can be output from traced functions
0/49 9.67G 6.055 6.742 5.403 65 640: 2%|▏ | 2/125 00:08Exception in thread Thread-6:
Traceback (most recent call last):
File "D:\Python\anaconda3\envs\yolo_pytorch\lib\threading.py", line 980, in _bootstrap_inner
self.run()
File "D:\Python\anaconda3\envs\yolo_pytorch\lib\threading.py", line 917, in run
self._target(*self._args, **self._kwargs)
File "E:\DeepLearning\yolov9\utils\plots.py", line 300, in plot_images
annotator.box_label(box, label, color=color)
File "E:\DeepLearning\yolov9\utils\plots.py", line 86, in box_label
w, h = self.font.getsize(label) # text width, height
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
0/49 9.67G 6.201 6.812 5.505 36 640: 2%|▏ | 3/125 00:09Exception in thread Thread-7:
Traceback (most recent call last):
File "D:\Python\anaconda3\envs\yolo_pytorch\lib\threading.py", line 980, in _bootstrap_inner
self.run()
File "D:\Python\anaconda3\envs\yolo_pytorch\lib\threading.py", line 917, in run
self._target(*self._args, **self._kwargs)
File "E:\DeepLearning\yolov9\utils\plots.py", line 300, in plot_images
annotator.box_label(box, label, color=color)
File "E:\DeepLearning\yolov9\utils\plots.py", line 86, in box_label
w, h = self.font.getsize(label) # text width, height
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
0/49 10.2G 5.603 6.38 5.564 21 640: 100%|██████████| 125/125 02:44
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 63/63 01:12
all 998 2353 3.88e-05 0.00483 2.16e-05 2.63e-06
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/49 12.1G 5.553 6.034 5.431 40 640: 100%|██████████| 125/125 02:53
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 63/63 01:29
all 998 2353 0.00398 0.0313 0.00276 0.000604
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/49 12.1G 5.061 5.749 5.102 49 640: 100%|██████████| 125/125 07:44
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 63/63 01:26
all 998 2353 0.00643 0.364 0.00681 0.0017
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/49 12.1G 4.292 5.013 4.58 35 640: 100%|██████████| 125/125 08:04
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 63/63 01:28
all 998 2353 0.0425 0.242 0.0273 0.00944
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/49 12.1G 3.652 4.46 4.164 30 640: 34%|███▎ | 42/125 02:45
3.3、模型重参数化
这里以 yolov9-c 转换为 yolov9-c-converted 模型为例。
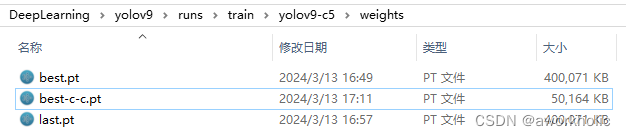
例如在上一节我们已经训练好了一个模型,如下

我们使用如下reparameterization_yolov9-c.py脚本,
import torch
from models.yolo import Model
model_file_path = r'runs\train\yolov9-c5\weights\best.pt'
model_converted_path = r'runs\train\yolov9-c5\weights\best-c-c.pt'
nc = 4
device = torch.device("cpu")
cfg = "./models/detect/gelan-c.yaml"
model = Model(cfg, ch=3, nc=nc, anchors=3)
#model = model.half()
model = model.to(device)
_ = model.eval()
ckpt = torch.load(model_file_path, map_location='cpu')
model.names = ckpt['model'].names
model.nc = ckpt['model'].nc
idx = 0
for k, v in model.state_dict().items():
if "model.{}.".format(idx) in k:
if idx < 22:
kr = k.replace("model.{}.".format(idx), "model.{}.".format(idx+1))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
elif "model.{}.cv2.".format(idx) in k:
kr = k.replace("model.{}.cv2.".format(idx), "model.{}.cv4.".format(idx+16))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
elif "model.{}.cv3.".format(idx) in k:
kr = k.replace("model.{}.cv3.".format(idx), "model.{}.cv5.".format(idx+16))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
elif "model.{}.dfl.".format(idx) in k:
kr = k.replace("model.{}.dfl.".format(idx), "model.{}.dfl2.".format(idx+16))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
else:
while True:
idx += 1
if "model.{}.".format(idx) in k:
break
if idx < 22:
kr = k.replace("model.{}.".format(idx), "model.{}.".format(idx+1))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
elif "model.{}.cv2.".format(idx) in k:
kr = k.replace("model.{}.cv2.".format(idx), "model.{}.cv4.".format(idx+16))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
elif "model.{}.cv3.".format(idx) in k:
kr = k.replace("model.{}.cv3.".format(idx), "model.{}.cv5.".format(idx+16))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
elif "model.{}.dfl.".format(idx) in k:
kr = k.replace("model.{}.dfl.".format(idx), "model.{}.dfl2.".format(idx+16))
model.state_dict()[k] -= model.state_dict()[k]
model.state_dict()[k] += ckpt['model'].state_dict()[kr]
_ = model.eval()
m_ckpt = {'model': model.half(),
'optimizer': None,
'best_fitness': None,
'ema': None,
'updates': None,
'opt': None,
'git': None,
'date': None,
'epoch': -1}
torch.save(m_ckpt, model_converted_path)
运行成功后,多了一个文件 best-c-c.pt 文件,且和官方提供的大小相同
我们进行测试如下,
(yolo_pytorch) E:\DeepLearning\yolov9>python detect.py --weights runs\train\yolov9-c5\weights\best-c-c.pt --source custom-data\vehicle\images\11.jpg --device 0
detect: weights=['runs\\train\\yolov9-c5\\weights\\best-c-c.pt'], source=custom-data\vehicle\images\11.jpg, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=0, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLO v0.1-61-g3e4f970 Python-3.9.16 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce GTX 1080 Ti, 11264MiB)
Fusing layers...
gelan-c summary: 387 layers, 25230172 parameters, 6348 gradients, 101.8 GFLOPs
image 1/1 E:\DeepLearning\yolov9\custom-data\vehicle\images\11.jpg: 480x640 8 cars, 52.2ms
Speed: 0.0ms pre-process, 52.2ms inference, 7.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp39
结果如下图








![[C++]20.实现红黑树。](https://img-blog.csdnimg.cn/direct/17d02ab3098f418aac0a7d1b19d54ab8.gif)