在进行项目研究时,通常需要搜集开源数据集。但是所能搜集到的数据集通常会存在形式上的差异,比如我想要的是语义分割数据,而搜集到的数据集却是目标检测数据;在这种情况下所搜集的数据就完成没有利用价值了么?不,其还存在价值,我们可以通过模型训练对数据标签的标注粒度进行优化。
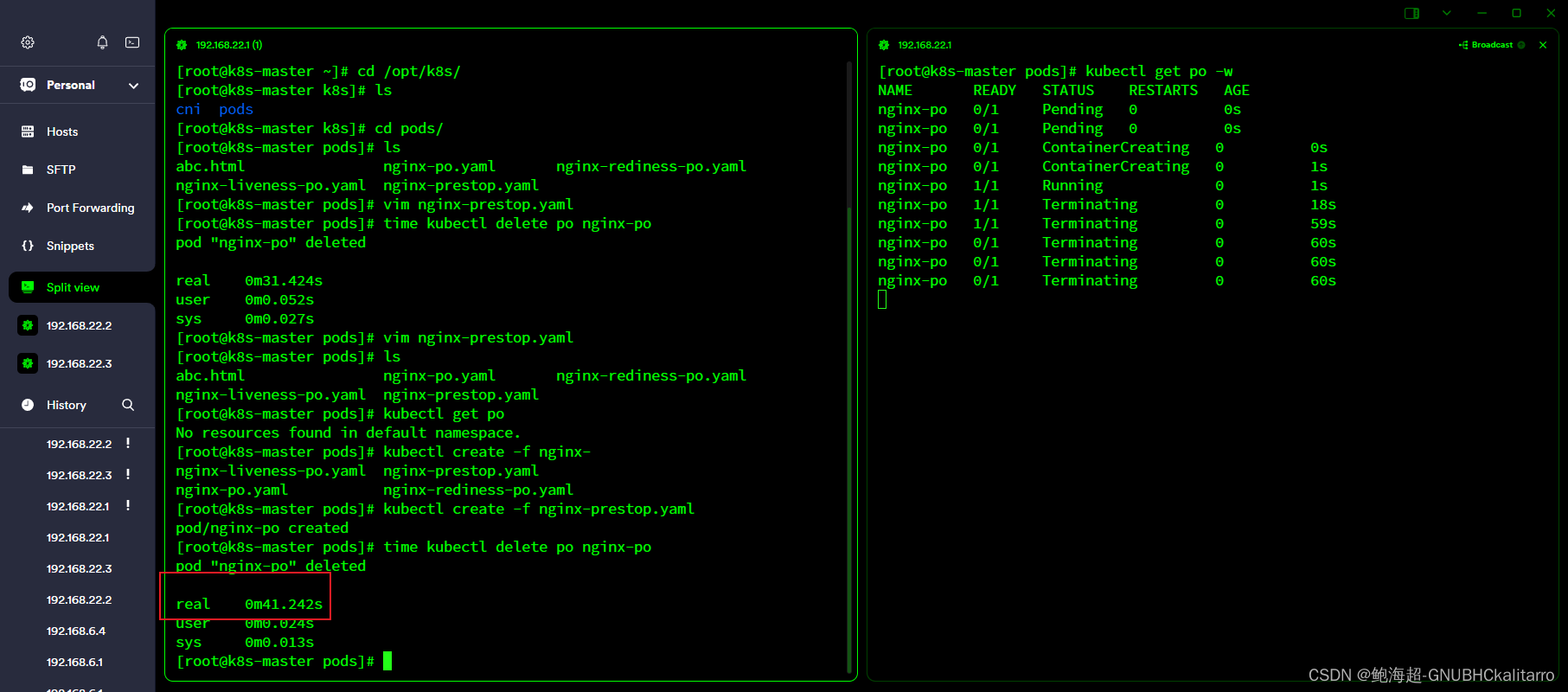
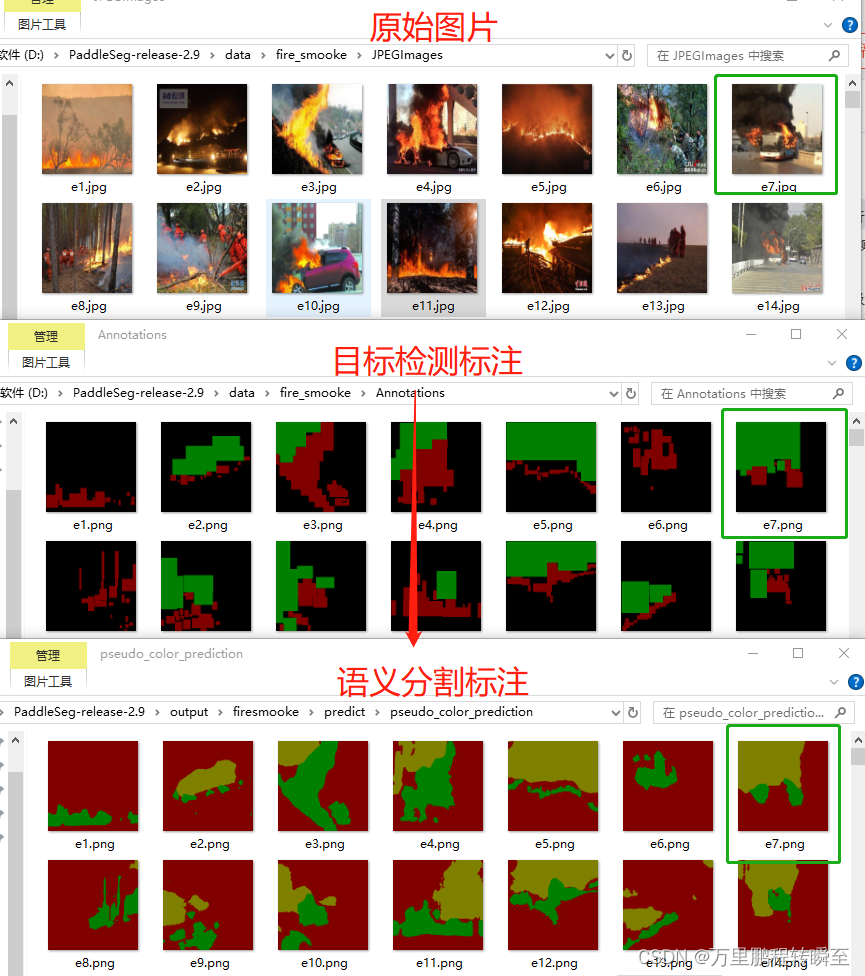
本博文基于paddleseg实现将烟火目标检测数据优化为烟火分割数据。具体效果如下所示:原始的目标检测数据变成了标注更为精准的语义分割数据。关于数据迭代中,在那一轮终止,又或者如果决断伪标签与原始真标签的差异并没有深入(通常目标检测数据的标签直接转换为目标检测后,属于误标注多,漏标注的少;而,基于训练生成的伪标签属于存在误检多的情况,应当基于原始标签对伪标签进行二次约束)。
1、数据标注粒度分析
1.1 图像分类、目标检测、语义分割数据分析
从数据的标注粒度角度论证的,在通用的ai图像领域,有图像分类(场景识别)、目标检测(对象识别)、语义分割(像素识别)。图像分类用于输入图像,输出图像类型的任务(或场景目类别,比如猫狗照片分类、图像风格分类、图像主体成分分类);目标检测用于输入图像,输出图像中所包含的目标位置类别;语义分割为输入图像,输出每一个像素的类别。
在不同的数据标注等级下,标注的粒度与成本是存在差异的。图像分类数据标注