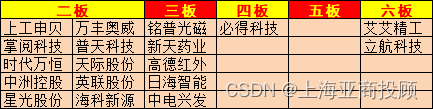
先更新数据库,还是先更新缓存?
1.先更新数据库,再更新缓存
2.先更新缓存,再更新数据库

1.先更新数据库,再更新缓存
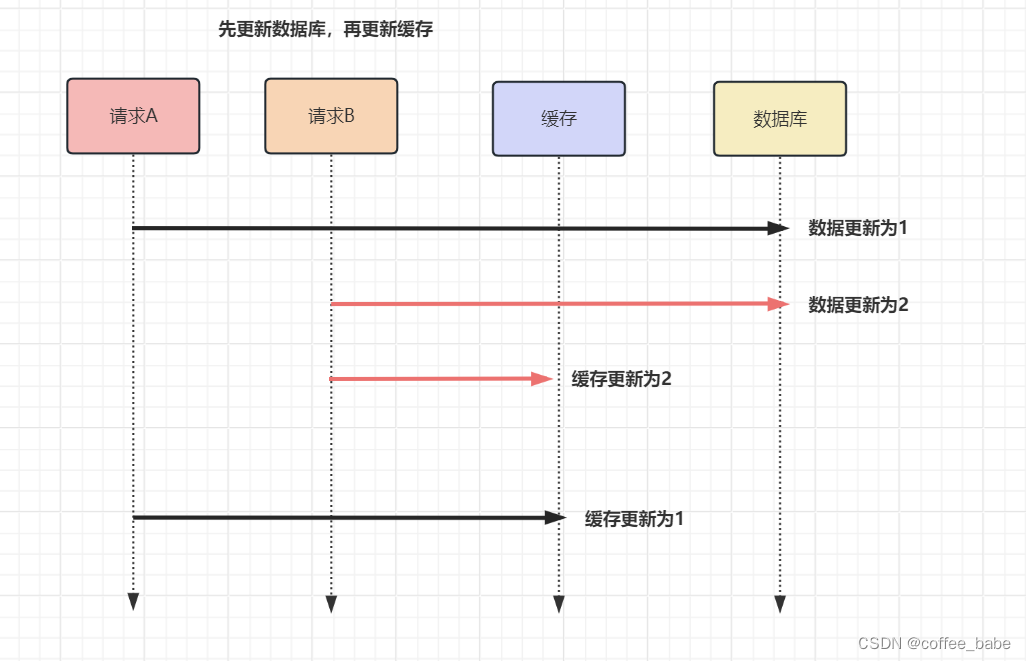
举个例子,比如【请求A】和【请求B】两个请求,同时更新【同一条】数据,
则可能出现图中的顺序:
【请求A】先将数据库的数据更新为1,然后在更新缓存前,【请求B】将数据库的数据更新为2,紧接着把缓存更新为2,然后【请求A】更新缓存为1.此时,数据库中的数据是2,而缓存中的数据却是1,出现了缓存和数据库中的数据不一致的现象
2.先更新缓存,再更新数据库。
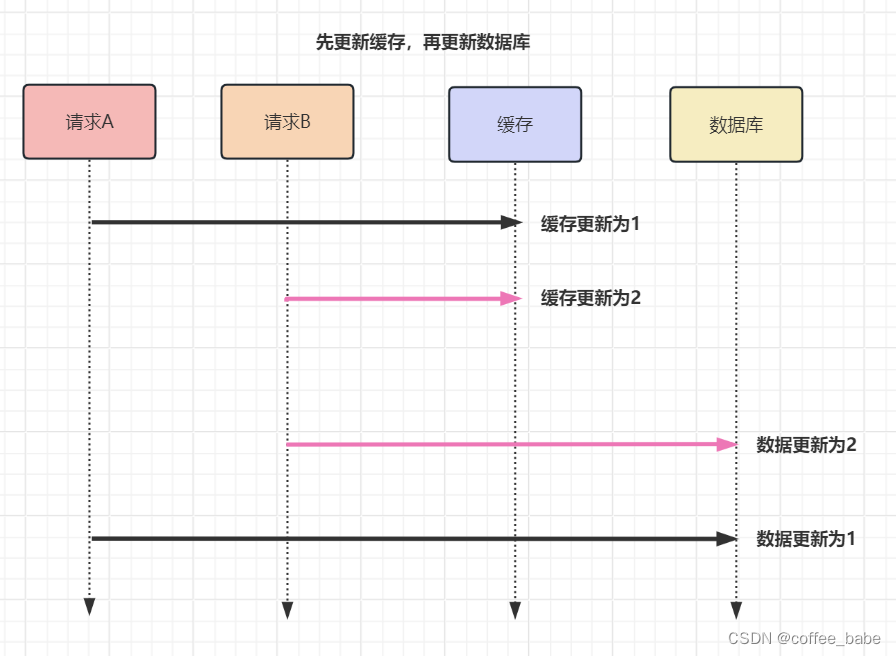
举个例子,【请求A】和【请求B】两个请求,同时更新【同一条】数据,
则可能出现这样的顺序:
【请求A】先将缓存的数据更新为1,然后在更新数据库前,【请求B】来了,将缓存的数据更新为2,紧接着把把数据库更新为2,然后【请求A】将数据库的数据更新为1.此时,数据库中的数据是1,而缓存中的数据却是2,出现了缓存和数据库中的数据不一致的现象
结论
所以,无论是【先更新数据库,再更新缓存】,还是【先更新缓存,再更新数据库】,
这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现
缓存和数据库中的数据不一致的现象
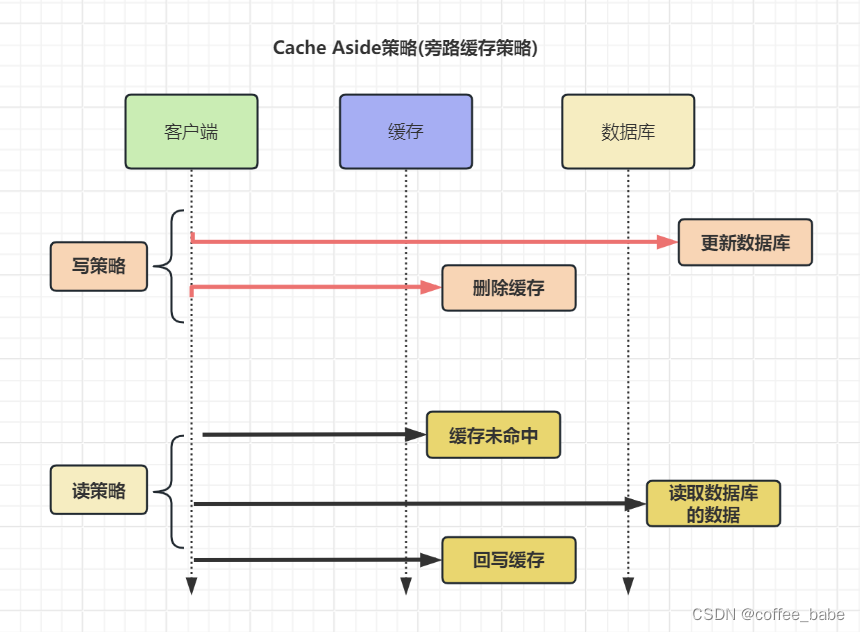
Cache Aside策略
Cache Aside(旁路缓存)策略,该策略可以细分为【读策略】和【写策略】
写策略的步骤:
1.更新数据库中的数据;
2.删除缓存中的数据
读策略的步骤:
1.如果读取的数据命中了缓存,则直接返回数据
2.如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户
但是【写策略】中的数据库和缓存操作又有不同的顺序:
1.先删除缓存,再更新数据库
2.先更新数据库,再删除缓存
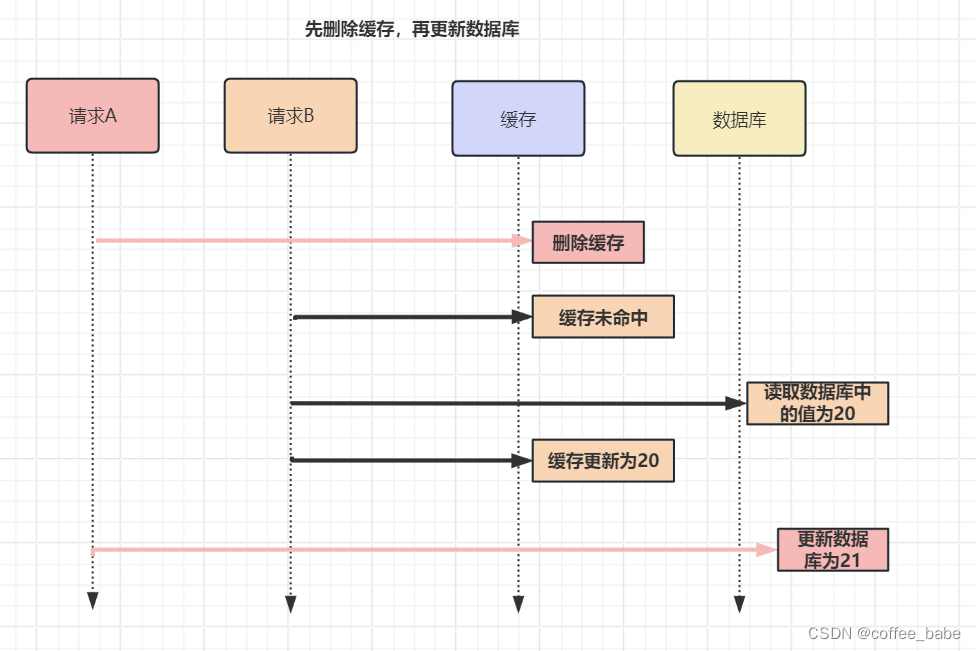
1.先删除缓存,再更新数据库。
举个例子,以用户表的场景来分析。
假设某个用户的年龄是20,请求A要更新用户年龄为21,所以它会删除
缓存中的内容。这时,另一个请求B要读取这个用户的年龄,它查询缓存
发现未命中后,会从数据库中读取到年龄为20,并且写入到缓存中,然后
请求A继续更改数据库,将用户的年龄更新为21.
最终,该用户年龄在缓存中是20(旧值),在数据库中是21(新值),缓存和
数据库的数据不一致。可以看到,先删除缓存,再更新数据库,在【读+写】并发的时候,还是会出现缓存和数据库的数据不一致的问题
解决方案:
针对【先删除缓存,再更新数据库】方法在【读+写】并发请求
而造成缓存不一致的解决办法是【延迟双删】:
伪代码示例。加了个睡眠时间,主要是为了确保请求A在睡眠的时候,请求B能够在这一段时间内完成【从数据库读取数据,再把缺失的缓存写入缓存】的操作,然后请求A睡眠完,再删除缓存。所以请求A的睡眠时间就需要大于请求B【从数据库读取数据+写入缓存】的时间。但是具体睡眠多久其实我们是没法准确预估的,需要进行统计,所以这个方案尽可能保证一致性而已,极端情况下,依然也会出现缓存不一致的现象,因此,还是比较建议用【先更新数据库,再删除缓存】的方案
#删除缓存
redis.delKey(X);
#更新数据库
db.update(X);
#睡眠
Thread.sleep(N);
#再删除缓存
redis.delKey(X);
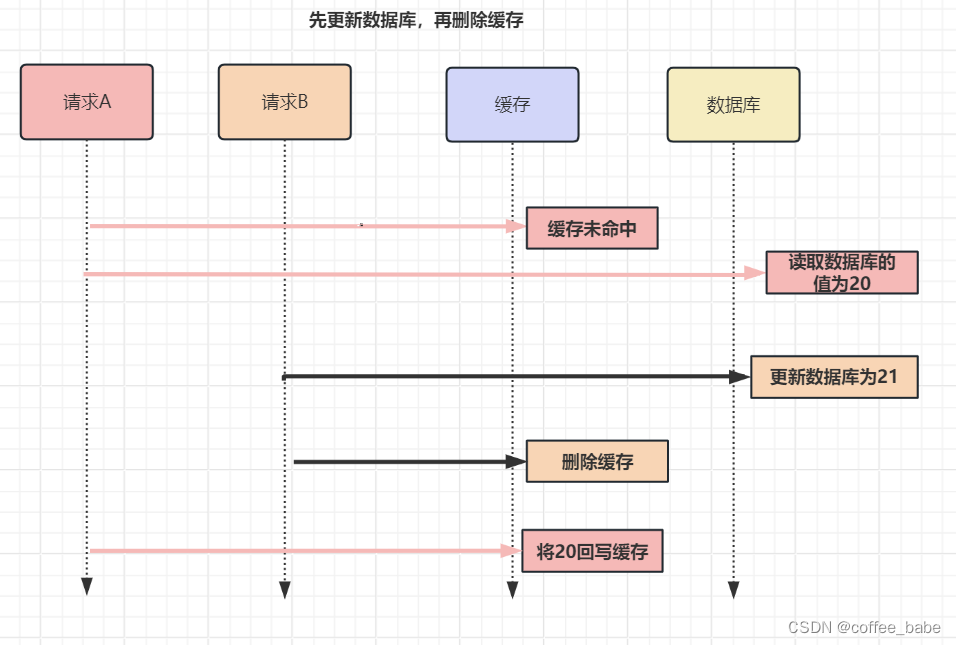
2.先更新数据库,再删除缓存
继续用【读+写】请求的并发的场景来分析。
假如某个用户数据在缓存中不存在,请求A读取读取数据时从数据库中查询到年龄为20,在未写入缓存中时另一个请求B更新数据。它更新数据库中的年龄为21,并且清空缓存。这时请求A把数据库中读到的年龄为20的数据写入到缓存中。最终,该用户年龄在缓存中是20,数据库中是21,缓存和数据库数据不一致。
分析
从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题,但是在实际中,这个问题出现的概率并不高。因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求B已经更新了数据库并且删除了缓存,请求A才更新完
缓存的情况。而一旦请求A早于请求B删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据,所以不会出现这种不一致的情况。所以,【先更新数据库+再删除缓存】的方案,是可以保证数据一致性的,再加上一个【过期时间】,就算在这期间存在缓存数据不一直,有过期时间来兜底,这样也能达到最终一致。
【先更新数据库,再删除缓存】存在的问题:
前面的分析都是建立再这两个操作都能同时执行成功的情况下,如果在删除缓存(第二个操作)的时候失败了,导致缓存中的数据是旧值,如果没有前面的过期时间兜底的话,后续的请求就会一直是缓存中的就数据
【先更新数据库,再删除缓存】的方案虽然保证了数据库与缓存的数据一致性,但是每次更新数据的时候,缓存的数据都会被删除,这样会对缓存的命中率带来影响。所以,如果业务对缓存命中率有很高的要求,可以采用【更新数据库+更新缓存】的方案,因为更新缓存并不会出现缓存未命中的情况,但是这个方案,前面提到,在两个更新请求并发执行的
时候,会出现数据不一致的问题,因为更新数据库和更新缓存这两个操作是独立的,我们又没有对操作做任何并发控制,那么当两个线程并发更新它们的话,就会因为写入顺序的不同造成数据不一致需要增加一些手段来解决这个问题,有两种做法
- 1.在更新缓存前先加个分布式锁,保证同一时间之运行一个请求更新缓存,就不会产生并发问题了,但是引入锁之后,对于写入性能就会带来影响
- 2.在更新完缓存时,给缓存加上较短的过期时间,这样即时出现缓存不一致的情况,缓存的数据也会很快过期,对业务来说也可以接受
如何保证【先更新数据库,再删除缓存】这两个操作能执行成功?
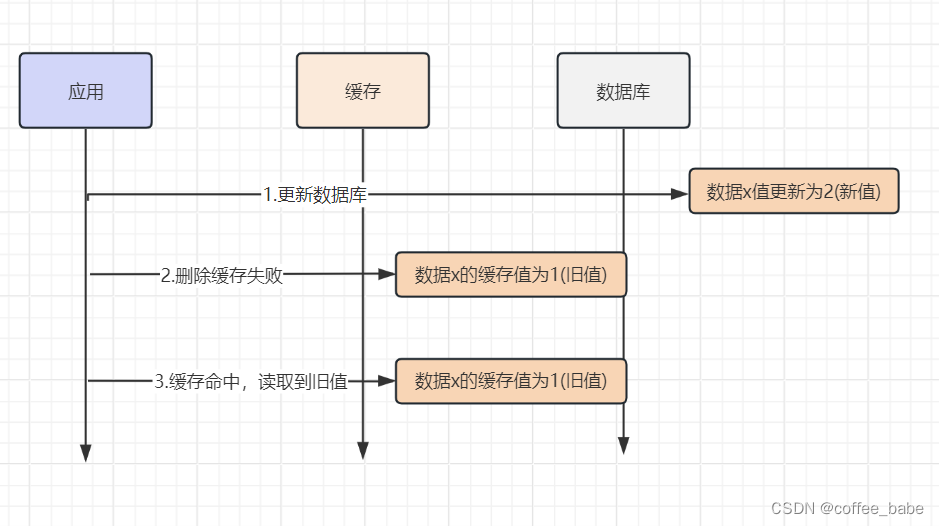
举个例子:
应用要把数据X的值从1更新为2,先成功更新了数据库,然后在Redis缓存
中删除X的缓存,但是这个操作却失败了,这个时候数据库中的X的新值为2,Redis中的X的缓存值为1,出现了数据库和缓存数据不一致的问题。
那么后续有访问数据X的请求,会先在Redis中查询,因为缓存中并没有删除,所以缓存命中,但是读到的却是旧值1.其实不管先操作数据库,还是先操作缓存,只要第二个操作失败都会出现数据不一致的问题,解决方案有两种:
- 1.重试机制
- 2.订阅MySQL binlog,再操作缓存
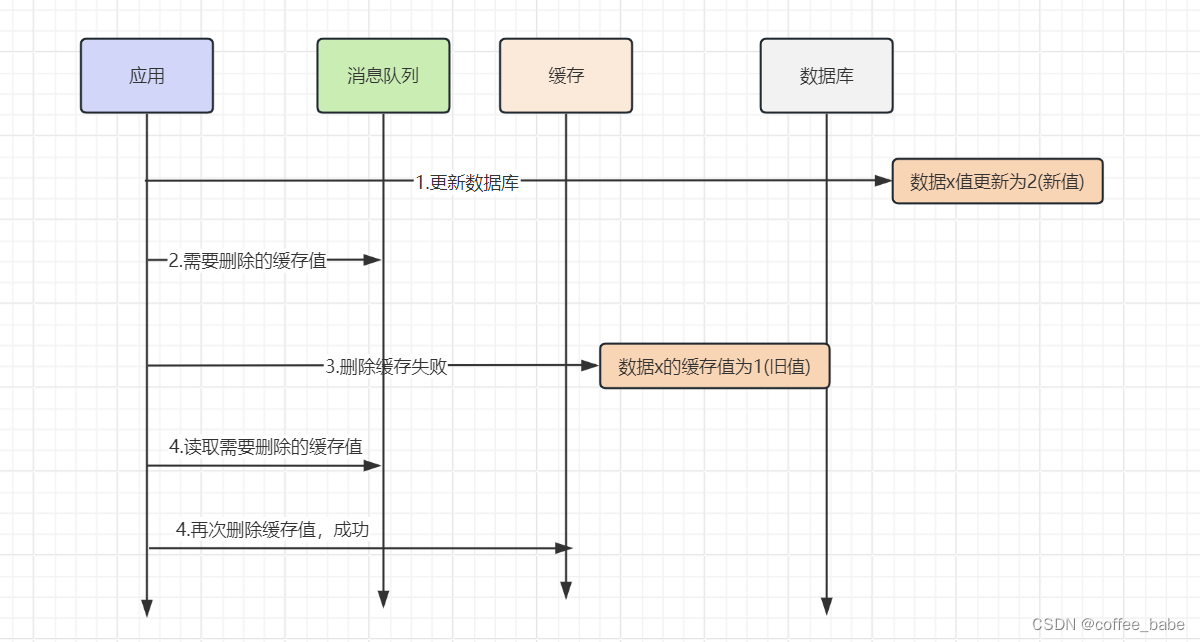
1.重试机制。
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
- 1.1 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过一定的次数,还是没有成功,就需要向业务层发送报错消息了
- 1.2 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试
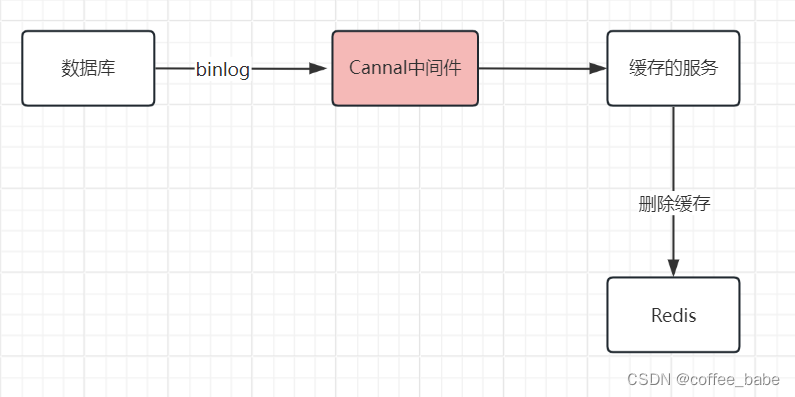
2.订阅MySQL binlog,再操作缓存
【先更新数据库,再删除缓存】的策略第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在binlog里。于是我们就可以通过订阅binlog日志,拿到具体要操作的数据,然后再执行缓存删除,阿里开源的Cannal中间件就是基于这个实现的。
Cannal模拟MySQL主从复制的交互协议,把自己伪装成一个MySQL的从节点,向MySQL主节点发送dump请求,MySQL收到请求后,就会开始推送binlog给Cannal,Cannal解析binlog字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用.
所以如果要想保证【先更新数据库,再删除缓存】策略第二个操作能执行成功,我们可以使用【消息队列来重试缓存的删除】,或者【订阅MySQL binlog再操作缓存】,这两种方法有一个共同的特点,都是采用异步操作缓存
疑问
为什么是删除缓存,而不是更新缓存?
删除一个数据,相比更新一个数据更加轻量级,出问题的概率更小。在实际业务中,缓存的数据可能不是直接来自数据库表,也许来自多张底层数据表的聚合。比如商品详情信息,在底层可能会关联商品表、价格表、库存表等,如果更新了一个价格字段,那么就要更新整个数据库,还要关联的去查询和汇总各个周边业务系统的数据,这个操作会非常耗时。从另外一个角度,不是所有的缓存数据都是频繁访问的,更新后的
缓存可能会长事件不被访问,所以说,从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是一个更好的方案。
系统设计中有一个设计叫Lazy Loading,适用于那些加载代价大的操作,删除缓存而不是更新缓存,就是懒加载思想的一个应用




![使用ChatGPT高效完成简历制作[中篇]-有爱AI实战教程(五)](https://img-blog.csdnimg.cn/direct/62a31875744f41368b9da06a6c04736a.png)