网络爬虫框架scrapy
(配置型爬虫)
什么是爬虫框架?
- 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合
- 爬虫框架是个半成品,帮助用户实现专业网络爬虫
scrapy框架结构("5+2"结构)
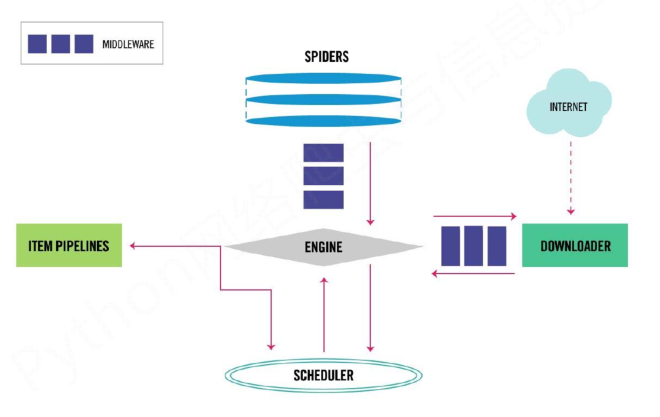
- spider:
- 解析downloader返回的响应(Response)
- 产生爬取项(scraped item)
- 产生额外的爬去请求(Request) 需要用户编写配置代码
- engine(引擎):
- 控制所有模块之间的数据流
- 根据条件触发事件 不需要用户修改
- scheduler(调度器):
- 对所有爬取请求进行调度处理 不需要用户修改
- downloader(下载器):
- 根据请求下载网页 不需要用户修改
- item pipelines():
- 以流水线处理spider产生的爬取项
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
- 可能操作包括:清理、检验和查重爬取项中的HTML数据,将数据存储到数据库中 需要用户编写配置代码
- downloader middleware(中间件):
- 目的:实施engine、scheduler和downloader之间进行用户可配置的控制
- 功能:修改、丢弃、新增请求或响应 用户可以编写配置代码
- spider middleware(中间件):
- 目的:对请求和爬去项的再处理
- 功能:修改、丢弃、新增请求或爬取项 用户可以编写配置代码
数据流

- 1.Engine从Spider处获得爬取请求(Request)
- 2.Engine将爬取请求转发给Scheduler,用于调度
- 3.Engine从Scheduler处获得下一个爬取的请求
- 4.Engine将爬取请求通过中间件发送给Downloader
- 5.爬取网页后,Downloader形成响应(Response),通过中间件(Middleware)发给Engine
- 6.Engine将收到的响应通过中间件发送给Spider处理
- 7.Spider处理响应后产生爬取项(scraped item)和新的爬取请求(Requests)给Engine
- 8.Engine将爬取项发送给Item Pipeline(框架出口)
- 9.Engine将爬取请求发送给Scheduler

- Engine控制各模块数据流,不间断从Scheduler处获得爬取请求,直到请求为空
- 框架入口:Spider的初始爬取请求
- 框架出口:Item Pipeline
scrapy命令行
格式
scrapy <command> [options] [args]
** 常用命令 **
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject [dir] |
| genspider | 创建一个爬虫 | scrapy genspider [options] [domain] |
| settings | 获得爬虫配置信息 | scrapy settings [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有的爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell [url] |
demohttps://python123.io/ws/demo.html
创建工程
scrapy startproject python123demo

创建爬虫
scrapy genspider demo python123.io
//生成了一个名为demo的spider
//在spider目录下增加代码文件demo.py(该文件也可以手工生成)
** demo.py文件 **
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['http://python123.io/']
def parse(self, response):
pass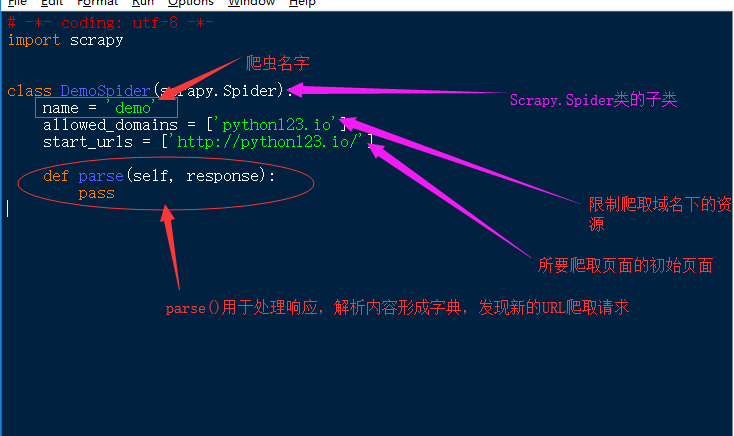
配置产生的spider爬虫
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
#存储文件名demo.html
file_name = response.url.split('/')[-1]
with open(file_name,"wb") as f:
f.write(response.body)
self.log('Saved file %s' % file_name)#日志
*** 另一个版本 **
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
#start_urls = ['http://python123.io/ws/demo.html']
def start_requests(self):
urls = [
'http://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
#存储文件名demo.html
file_name = response.url.split('/')[-1]
with open(file_name,"wb") as f:
f.write(response.body)
self.log('Saved file %s' % file_name)#日志
运行爬虫
scrapy crawl demoScrapy爬虫数据类型
- Request类
- Response类
- Item类
Request类
class scrapy.http.Request()- Request对象表示一个HTTP请求
- 由Spider生成,由Downloader执行
| 属性 | 方法 |
|---|---|
| .url | Requests对应的请求URL地址 |
| .method | 对应的请求方法,'GEt'、'POST'等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy | 复制该请求 |
Response类
class scrapy.http.Response()- Response对象表示一个HTTp响应
- 由Downloader生成,由Spider处理
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
Item类
class scrapy.item.Item()- Item对象表示一个从HTML页面中提取的信息内容
- 由Spider生成,由Item Pipeline处理
- Item类似字典类型,可以按照字典类型操作
Scrapy爬虫的使用步骤
- 创建一个工程和Spider模板
- 编写Spider
- 编写Item Pipeline
- 优化配置策略
scrapy爬虫信息提取方法
- Beautifui Soup
- lxml
- re
- XPath Selector
- CSS Selector
本文由博客群发一文多发等运营工具平台 OpenWrite 发布