一、Huggingface介绍
1、Huggingface定位
NLP自从Transformer模型出现后,处理方式有大统一的趋势,首先回答几个基础问题:
1、自然语言处理究竟要做一件什么事呢?自然语言处理最终解决的是分类问题,但是它不仅仅输出一个分类的预测结果,关键的在于构建一个聪明的模型,不光能学习不同数据集的问题,还能处理不同类别的问题。
2、如何培养模型的学习能力?自然语言处理就像我们读书一样,要训练它的阅读能力、学习能力、理解能力,给出的是一系列阅读材料,然后想办法让它理解语言,不仅仅是一个分类的专项技能,这里就涉及到注意力机制了,通过设置学习任务每一段只关注其中部分语料,并分配好权重,通过训练得到比较好的效果。之后基于注意力模型搭建复杂的神经网络,以获取强大的学习能力。
3、NLP中的核心门派:BERT系(五岳剑派),GPT系(魔教),BERT有点像做完形填空,GPT有点像写小作文。现在NLP已到了大模型时代,已经在拼海量的数据量和参数,目前GPT系列已经取得很大成功,但是是大模型,个人要训练很是很麻烦的,也有些开源的大模型,先从调优做起!
4、如何开始NLP呢?引出这个问题,也是Huggingface的关键理念了,历史上有很多NLP的算法,但是实事已经证明大部分没啥用,有用的就是Transformer这一系列的模型了,而Huggingface就是集大成者于一身,包括了当下NLP所有核心模型,只需要一行代码就可以调用BERT模型,GPT模型及其训练好的权重参数!其次,Huggingface它不仅是一个工具包,更是一个社区,也是NLP大佬们的舞台。当然kaggle也是个不错的平台,结合着用!
2、Huggingface调用示例
Huggingface这个包基本调用即可,先安装包pip install:
pip install transformers开箱即用,方便:
import warnings
warnings.filterwarnings("ignore")
from transformers import pipeline#用人家设计好的流程完成一些简单的任务
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)结果:
[{'label': 'POSITIVE', 'score': 0.9598049521446228},
{'label': 'NEGATIVE', 'score': 0.9994558691978455}]
测试很方便,如果有包不好下载,找镜像、先download安装包之后再安装。
二、Transformer模型
1、注意力机制(Attention model)
Transformer可以说大名鼎鼎了,NLP领域大哥大级别,一统天下好多年了,而且是CV界新秀,开场即巅峰。它的基础在于注意力机制,先来吴恩达老师对Transformer细节的架构图:

可以看出Transformer有Encoder、Decoder两部分组成,采用Multi-Head Attention(多头注意力)提取文本特征,形成编码器,最终也通过两层Multi-Head Attention进行解码,Transformer核心就是Attention Model。
什么是注意力?注意力是稀缺的,而环境中信息量非常之大,比如人类的视觉神经每秒收到位的信息,圆圆超过大脑的处理能力,但人类从远古祖先中继承了一项本能经验“并非感官的所有输入都是一样的”,大脑会将关注点集中在一小部分信息中,这便是注意力。认知觉醒中提到一种凭感觉学习的方法,核心思路便是先用感性能力帮助自己选择,再用理性能力帮助自己思考。这个过程中凭感觉学习中的感觉就类似于注意力,注意力模型就是通过训练找到潜意识里的感觉,分别出重要的信息!
回到注意力模型,源于机器翻译,并快速推广到了其他应用领域,有三个重要概念:查询(query)、键(key)和值(value),用Q、K、V分别代替。查询相当于自主性提示,触发感觉得信息,比如突然看到学校的照片,回想起求学经历,query相当于这张照片,键和值的理解要花点时间,键相当于概述求学经历,值相当于求学经历的细节,在哪个教室听哪位老师讲课等等。

回到NLP中,用这幅图好理解Attention在做什么(图里是自注意力模型,query就是语料自身,Attention is All you need!):

对于注意力的公式推导,参考视频讲的不错:注意力机制的本质|Self-Attention|Transformer|QKV矩阵_哔哩哔哩_bilibili
Q、K的作用在于确定V的权重,因为只有K的话不能计算出来所有V所需要的权重,假设用 a(q,k)来表示q与k对应的注意力权重,则预测值f(q):

a是任意能刻画相关性的函数,但需要归一化,我们以高斯核(注意力分数)为例(包括softmax函数);公式变形为:,矩阵的变形不再赘述,公式如下图所示。特别的,当Q、K、V为同一矩阵时,即为自注意力模型。
![]()
2、Transformer
三、调用流程概述
首先原始文本用Tokenizer进行分词处理得到输入的文本,然后通过模型进行学习,学习之后进行处理、预测分析。而且huggingface有个好处,分词器、数据集、模型都封装好了!很方便。

1、Tokenizer
Tokenizer会做3件事:
- 分词,分字以及特殊字符(起始,终止,间隔,分类等特殊字符可以自己设计的)
- 对每一个token映射得到一个ID(每个词都会对应一个唯一的ID)
- 还有一些辅助信息也可以得到,比如当前词属于哪个句子(还有一些MASK,表示是否是原来的词还是特殊字符等)
其中AutoTokenizer可以自动根据模型来判断采用哪个分词器:
from transformers import AutoTokenizer#自动判断
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"#根据这个模型所对应的来加载
tokenizer = AutoTokenizer.from_pretrained(checkpoint)输入文本:
raw_inputs = [
"I've been waiting for a this course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)打印结果(得到两个字典映射,'input_ids',一个tensor集合,每个词所对应的ID集合;attention_mask,一个tensor集合,表示是否是原来的词还是特殊字符等):
{'input_ids': tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 2023, 2607, 2026, 2878,
2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0,
0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])}
如果想根据id重新获得原始句子,如下操作:
tokenizer.decode([ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 2023, 2607, 2026, 2878,2166, 1012, 102])生成的文本会存在特殊字符,这些特殊字符是因为人家模型训练的时候就加入了这个东西,所以这里默认也加入了(google系的处理)
"[CLS] i've been waiting for a this course my whole life. [SEP]"
2、模型的加载
模型的加载直接指定好名字即可(先不加输出层)
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
model打印出来模型架构,就是DistilBertModel的架构了,能看到embeddings层、transformer层,看得还比较清晰:
DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(1): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(2): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(3): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(4): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(5): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
看下输出层的结构,这里**表示分配字典,按照参数顺序依次赋值:
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)torch.Size([2, 15, 768])
3、模型基本逻辑
根据上面代码总结模型的逻辑:input——>词嵌入——>Transformer——>隐藏层——>Head层。
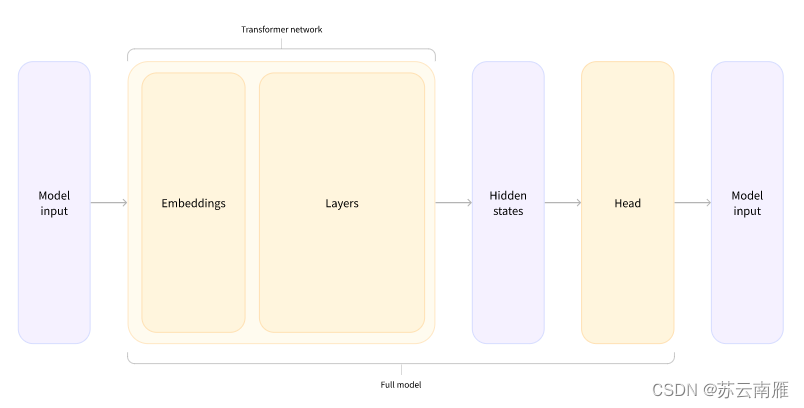
4、加入输出头
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)这里就得到分类后的结果:
torch.Size([2, 2])
再来看看模型的结构:
model
DistilBertForSequenceClassification(
(distilbert): DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(1): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(2): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(3): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(4): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(5): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=2, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
之后采用softmax进行预测:
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[1.5446e-02, 9.8455e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward0>)
id2label这个我们后续可以自己设计,标签名字对应都可以自己指定:
model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}