本文为🔗365天深度学习训练营 中的学习记录博客
原作者:K同学啊|接辅导、项目定制
我的环境:
1.语言:python3.7
2.编译器:pycharm
3.深度学习框架Tensorflow/Pytorch 1.8.0+cu111
一、问题引出
CNN能够提取低、中、高层的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。但是如果只是简单地增加深度,会导致梯度爆炸。
最初对于该问题的解决方法是:正则化初始化和中间的正则化层。这样的话可以训练几十层的网络。虽然通过上述方法能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。退化问题说明了深度网络不能很简单地被很好地优化。
直白来讲
假设一个30层的网络跟一个15层的网络,30层的网络解空间是包含了15层网络的解空间的,一般来说30层的性能肯定优于15层的性能。但实验表明30层的网络无论是训练误差还是测试误差均大于15层的网络。因为我们在训练网络时采用的时随机梯度下降,得到的往往不是最优解而是局部最优,因为30层的网络解空间更加复杂,导致利用随机梯度下降无法得到最优解
二、残差网络介绍
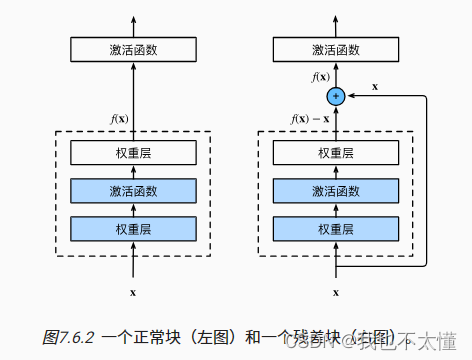
为了解决退化问题,何恺明提出了深度残差网络(ResNet)。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数比较困难,如果我们把网络设计为
,我们可以转换为学习一个残差函数
,只要
就构成了一个恒等映射
.
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
三、Tensorflow代码
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0, True)
tf.config.set_visible_devices([gpu0],"GPU")
import os, PIL, pathlib
import matplotlib.pyplot as plt
data_dir = "E:/TF环境/ResNet50/bird_photos"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
batch_size = 8
img_height = 224
img_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed = 123,
image_size = (img_height, img_width),
batch_size = batch_size
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed = 123,
image_size = (img_height, img_width),
batch_size = batch_size
)
class_names = train_ds.class_names
print(class_names)
plt.figure(figsize = (10, 5))
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()
#再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
from tensorflow.keras.layers import Dropout
import tensorflow as tf
import glob
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, ZeroPadding2D, AveragePooling2D
from tensorflow.keras.layers import Activation, BatchNormalization, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras import layers
def identity_block(input_tensor, kernel_size, filters, stage, block):
# 64,64,256
filters1, filters2, filters3 = filters
name_base = str(stage) + block + 'identity_block_'
# 降维
x = Conv2D(filters1, (1, 1),
name=name_base + 'conv1')(input_tensor)
x = BatchNormalization(name=name_base + 'bn1')(x)
x = Activation('relu',name=name_base + 'relu1')(x)
# 3x3卷积
x = Conv2D(filters2, kernel_size, padding='same',
name=name_base + 'conv2')(x)
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu', name=name_base + 'relu2')(x)
# 升维
x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
x = layers.add([x, input_tensor],name=name_base + 'add')
x = Activation('relu',name=name_base + 'relu4')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block,strides = (2,2)):
filters1, filters2, filters3 = filters
res_name_base = str(stage) + block + '_conv_block_res_'
name_base = str(stage) + block + '_conv_block_'
# 降维
x = Conv2D(filters1, (1, 1), strides = strides ,name=name_base + 'conv1')(input_tensor)
x = BatchNormalization(name=name_base + 'bn1')(x)
x = Activation('relu',name=name_base + 'relu1')(x)
# 3x3卷积
x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu',name=name_base + 'relu2')(x)
x = Conv2D(filters3, (1,1), name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
shortcut = Conv2D(filters3, (1,1),strides = strides ,name=res_name_base + 'conv')(input_tensor)
shortcut = BatchNormalization(name = res_name_base + 'bn')(shortcut)
x = layers.add([x, shortcut],name=name_base + 'add')
x = Activation('relu',name=name_base + 'relu4')(x)
return x
def ResNet50(input_shape=[224, 224, 3], classes=1000):
img_input = Input(shape=input_shape)
x = ZeroPadding2D((3, 3))(img_input) # [230,230,3]
# [112,112,64]
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x) # [112,112,64]
x = BatchNormalization(name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2))(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# [28,28,512]
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# [14,14,1024]
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
# [7,7,2048]
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
# 代替全连接层
x = AveragePooling2D((7, 7), name='avg_pool')(x)
# 进行预测
x = Flatten()(x)
x = Dense(classes, activation='softmax', name='fc1000')(x)
model = Model(img_input, x, name='resnet50')
model.load_weights(
"E:/TF环境/ResNet50/resnet50_weights_tf_dim_ordering_tf_kernels.h5")
return model
model = ResNet50()
model.summary()
opt = tf.keras.optimizers.Adam(learning_rate=1e-7)
model.compile(
optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
epochs = 10
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
)
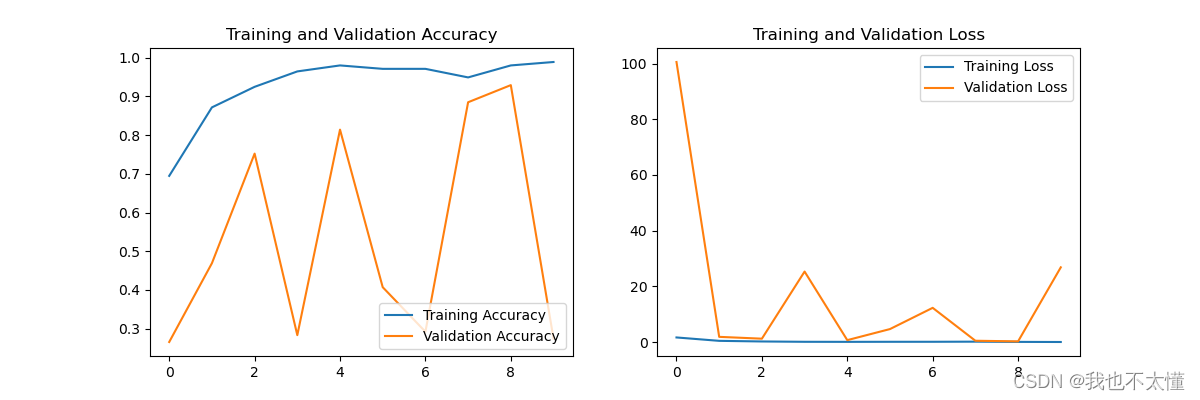
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
for images,labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(2,4,i+1)
plt.imshow(images[i].numpy().astype("uint8"))
img_array = tf.expand_dims(imges[i],0)
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")
plt.show()
四、pytorch 代码
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
data_dir = "E:/TF环境/ResNet50/bird_photos"
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[4] for path in data_paths]
print(classeNames)
train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]
)
])
total_data = datasets.ImageFolder("E:/TF环境/ResNet50/bird_photos",transform = train_transforms)
print(total_data)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset)
print(test_dataset)
batch_size = 8
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
#num_workers=1
)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
#num_workers=1
)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
from torch import nn
from torch.nn import functional as F
import torch.nn.functional as F
# 构造ResNet50模型
class ResNetblock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResNetblock, self).__init__()
self.blockconv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels * 4, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels * 4)
)
if stride != 1 or in_channels != out_channels * 4:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * 4, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels * 4)
)
def forward(self, x):
residual = x
out = self.blockconv(x)
if hasattr(self, 'shortcut'): # 如果self中含有shortcut属性
residual = self.shortcut(x)
out += residual
out = F.relu(out)
return out
class ResNet50(nn.Module):
def __init__(self, block, num_classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Sequential(
nn.ZeroPad2d(3),
nn.Conv2d(3, 64, kernel_size=7, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d((3, 3), stride=2)
)
self.in_channels = 64
# ResNet50中的四大层,每大层都是由ConvBlock与IdentityBlock堆叠而成
self.layer1 = self.make_layer(ResNetblock, 64, 3, stride=1)
self.layer2 = self.make_layer(ResNetblock, 128, 4, stride=2)
self.layer3 = self.make_layer(ResNetblock, 256, 6, stride=2)
self.layer4 = self.make_layer(ResNetblock, 512, 3, stride=2)
self.avgpool = nn.AvgPool2d((7, 7))
self.fc = nn.Linear(512 * 4, num_classes)
# 每个大层的定义函数
def make_layer(self, block, channels, num_blocks, stride=1):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, channels, stride))
self.in_channels = channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
model = ResNet50(block=ResNetblock, num_classes=len(classeNames)).to(device)
model
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))
def train(dataloader,model,optimizer,loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_acc,train_loss = 0,0
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model(X)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_acc,train_loss
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-2
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
import copy
epochs = 10
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss = train(train_dl,model,opt,loss_fn)
model.eval()
epoch_test_acc,epoch_test_loss = test(test_dl,model,loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = opt.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = 'E:/pythonProject pytorch/J1_birds_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)
print('Done')
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
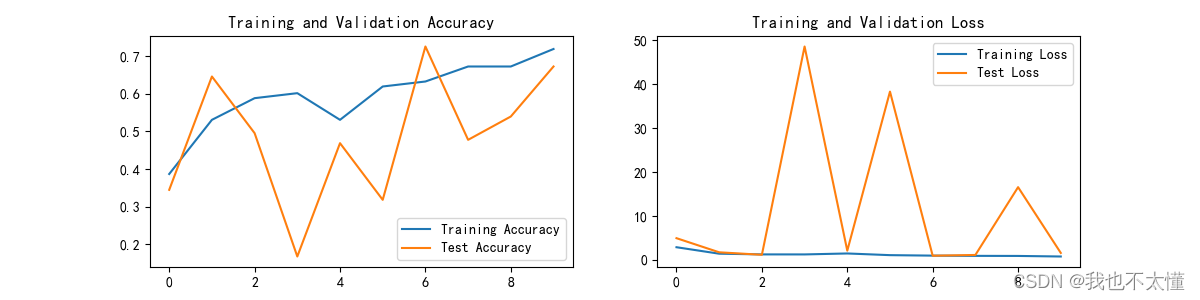
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Layer (type) Output Shape Param #
================================================================
ZeroPad2d-1 [-1, 3, 230, 230] 0
Conv2d-2 [-1, 64, 112, 112] 9,472
BatchNorm2d-3 [-1, 64, 112, 112] 128
ReLU-4 [-1, 64, 112, 112] 0
MaxPool2d-5 [-1, 64, 55, 55] 0
Conv2d-6 [-1, 64, 55, 55] 4,160
BatchNorm2d-7 [-1, 64, 55, 55] 128
ReLU-8 [-1, 64, 55, 55] 0
Conv2d-9 [-1, 64, 55, 55] 36,928
BatchNorm2d-10 [-1, 64, 55, 55] 128
ReLU-11 [-1, 64, 55, 55] 0
Conv2d-12 [-1, 256, 55, 55] 16,640
BatchNorm2d-13 [-1, 256, 55, 55] 512
Conv2d-14 [-1, 256, 55, 55] 16,640
BatchNorm2d-15 [-1, 256, 55, 55] 512
ResNetblock-16 [-1, 256, 55, 55] 0
Conv2d-17 [-1, 64, 55, 55] 16,448
BatchNorm2d-18 [-1, 64, 55, 55] 128
ReLU-19 [-1, 64, 55, 55] 0
Conv2d-20 [-1, 64, 55, 55] 36,928
BatchNorm2d-21 [-1, 64, 55, 55] 128
ReLU-22 [-1, 64, 55, 55] 0
Conv2d-23 [-1, 256, 55, 55] 16,640
BatchNorm2d-24 [-1, 256, 55, 55] 512
ResNetblock-25 [-1, 256, 55, 55] 0
Conv2d-26 [-1, 64, 55, 55] 16,448
BatchNorm2d-27 [-1, 64, 55, 55] 128
ReLU-28 [-1, 64, 55, 55] 0
Conv2d-29 [-1, 64, 55, 55] 36,928
BatchNorm2d-30 [-1, 64, 55, 55] 128
ReLU-31 [-1, 64, 55, 55] 0
Conv2d-32 [-1, 256, 55, 55] 16,640
BatchNorm2d-33 [-1, 256, 55, 55] 512
ResNetblock-34 [-1, 256, 55, 55] 0
Conv2d-35 [-1, 128, 28, 28] 32,896
BatchNorm2d-36 [-1, 128, 28, 28] 256
ReLU-37 [-1, 128, 28, 28] 0
Conv2d-38 [-1, 128, 28, 28] 147,584
BatchNorm2d-39 [-1, 128, 28, 28] 256
ReLU-40 [-1, 128, 28, 28] 0
Conv2d-41 [-1, 512, 28, 28] 66,048
BatchNorm2d-42 [-1, 512, 28, 28] 1,024
Conv2d-43 [-1, 512, 28, 28] 131,584
BatchNorm2d-44 [-1, 512, 28, 28] 1,024
ResNetblock-45 [-1, 512, 28, 28] 0
Conv2d-46 [-1, 128, 28, 28] 65,664
BatchNorm2d-47 [-1, 128, 28, 28] 256
ReLU-48 [-1, 128, 28, 28] 0
Conv2d-49 [-1, 128, 28, 28] 147,584
BatchNorm2d-50 [-1, 128, 28, 28] 256
ReLU-51 [-1, 128, 28, 28] 0
Conv2d-52 [-1, 512, 28, 28] 66,048
BatchNorm2d-53 [-1, 512, 28, 28] 1,024
ResNetblock-54 [-1, 512, 28, 28] 0
Conv2d-55 [-1, 128, 28, 28] 65,664
BatchNorm2d-56 [-1, 128, 28, 28] 256
ReLU-57 [-1, 128, 28, 28] 0
Conv2d-58 [-1, 128, 28, 28] 147,584
BatchNorm2d-59 [-1, 128, 28, 28] 256
ReLU-60 [-1, 128, 28, 28] 0
Conv2d-61 [-1, 512, 28, 28] 66,048
BatchNorm2d-62 [-1, 512, 28, 28] 1,024
ResNetblock-63 [-1, 512, 28, 28] 0
Conv2d-64 [-1, 128, 28, 28] 65,664
BatchNorm2d-65 [-1, 128, 28, 28] 256
ReLU-66 [-1, 128, 28, 28] 0
Conv2d-67 [-1, 128, 28, 28] 147,584
BatchNorm2d-68 [-1, 128, 28, 28] 256
ReLU-69 [-1, 128, 28, 28] 0
Conv2d-70 [-1, 512, 28, 28] 66,048
BatchNorm2d-71 [-1, 512, 28, 28] 1,024
ResNetblock-72 [-1, 512, 28, 28] 0
Conv2d-73 [-1, 256, 14, 14] 131,328
BatchNorm2d-74 [-1, 256, 14, 14] 512
ReLU-75 [-1, 256, 14, 14] 0
Conv2d-76 [-1, 256, 14, 14] 590,080
BatchNorm2d-77 [-1, 256, 14, 14] 512
ReLU-78 [-1, 256, 14, 14] 0
Conv2d-79 [-1, 1024, 14, 14] 263,168
BatchNorm2d-80 [-1, 1024, 14, 14] 2,048
Conv2d-81 [-1, 1024, 14, 14] 525,312
BatchNorm2d-82 [-1, 1024, 14, 14] 2,048
ResNetblock-83 [-1, 1024, 14, 14] 0
Conv2d-84 [-1, 256, 14, 14] 262,400
BatchNorm2d-85 [-1, 256, 14, 14] 512
ReLU-86 [-1, 256, 14, 14] 0
Conv2d-87 [-1, 256, 14, 14] 590,080
BatchNorm2d-88 [-1, 256, 14, 14] 512
ReLU-89 [-1, 256, 14, 14] 0
Conv2d-90 [-1, 1024, 14, 14] 263,168
BatchNorm2d-91 [-1, 1024, 14, 14] 2,048
ResNetblock-92 [-1, 1024, 14, 14] 0
Conv2d-93 [-1, 256, 14, 14] 262,400
BatchNorm2d-94 [-1, 256, 14, 14] 512
ReLU-95 [-1, 256, 14, 14] 0
Conv2d-96 [-1, 256, 14, 14] 590,080
BatchNorm2d-97 [-1, 256, 14, 14] 512
ReLU-98 [-1, 256, 14, 14] 0
Conv2d-99 [-1, 1024, 14, 14] 263,168
BatchNorm2d-100 [-1, 1024, 14, 14] 2,048
ResNetblock-101 [-1, 1024, 14, 14] 0
Conv2d-102 [-1, 256, 14, 14] 262,400
BatchNorm2d-103 [-1, 256, 14, 14] 512
ReLU-104 [-1, 256, 14, 14] 0
Conv2d-105 [-1, 256, 14, 14] 590,080
BatchNorm2d-106 [-1, 256, 14, 14] 512
ReLU-107 [-1, 256, 14, 14] 0
Conv2d-108 [-1, 1024, 14, 14] 263,168
BatchNorm2d-109 [-1, 1024, 14, 14] 2,048
ResNetblock-110 [-1, 1024, 14, 14] 0
Conv2d-111 [-1, 256, 14, 14] 262,400
BatchNorm2d-112 [-1, 256, 14, 14] 512
ReLU-113 [-1, 256, 14, 14] 0
Conv2d-114 [-1, 256, 14, 14] 590,080
BatchNorm2d-115 [-1, 256, 14, 14] 512
ReLU-116 [-1, 256, 14, 14] 0
Conv2d-117 [-1, 1024, 14, 14] 263,168
BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
ResNetblock-119 [-1, 1024, 14, 14] 0
Conv2d-120 [-1, 256, 14, 14] 262,400
BatchNorm2d-121 [-1, 256, 14, 14] 512
ReLU-122 [-1, 256, 14, 14] 0
Conv2d-123 [-1, 256, 14, 14] 590,080
BatchNorm2d-124 [-1, 256, 14, 14] 512
ReLU-125 [-1, 256, 14, 14] 0
Conv2d-126 [-1, 1024, 14, 14] 263,168
BatchNorm2d-127 [-1, 1024, 14, 14] 2,048
ResNetblock-128 [-1, 1024, 14, 14] 0
Conv2d-129 [-1, 512, 7, 7] 524,800
BatchNorm2d-130 [-1, 512, 7, 7] 1,024
ReLU-131 [-1, 512, 7, 7] 0
Conv2d-132 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-133 [-1, 512, 7, 7] 1,024
ReLU-134 [-1, 512, 7, 7] 0
Conv2d-135 [-1, 2048, 7, 7] 1,050,624
BatchNorm2d-136 [-1, 2048, 7, 7] 4,096
Conv2d-137 [-1, 2048, 7, 7] 2,099,200
BatchNorm2d-138 [-1, 2048, 7, 7] 4,096
ResNetblock-139 [-1, 2048, 7, 7] 0
Conv2d-140 [-1, 512, 7, 7] 1,049,088
BatchNorm2d-141 [-1, 512, 7, 7] 1,024
ReLU-142 [-1, 512, 7, 7] 0
Conv2d-143 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-144 [-1, 512, 7, 7] 1,024
ReLU-145 [-1, 512, 7, 7] 0
Conv2d-146 [-1, 2048, 7, 7] 1,050,624
BatchNorm2d-147 [-1, 2048, 7, 7] 4,096
ResNetblock-148 [-1, 2048, 7, 7] 0
Conv2d-149 [-1, 512, 7, 7] 1,049,088
BatchNorm2d-150 [-1, 512, 7, 7] 1,024
ReLU-151 [-1, 512, 7, 7] 0
Conv2d-152 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-153 [-1, 512, 7, 7] 1,024
ReLU-154 [-1, 512, 7, 7] 0
Conv2d-155 [-1, 2048, 7, 7] 1,050,624
BatchNorm2d-156 [-1, 2048, 7, 7] 4,096
ResNetblock-157 [-1, 2048, 7, 7] 0
AvgPool2d-158 [-1, 2048, 1, 1] 0
Linear-159 [-1, 4] 8,196
================================================================
Total params: 23,542,788
Trainable params: 23,542,788
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 230.18
Params size (MB): 89.81
Estimated Total Size (MB): 320.56
----------------------------------------------------------------
Epoch: 1, Train_acc:38.7%, Train_loss:2.877, Test_acc:34.5%, Test_loss:4.936, Lr:1.00E-02
Epoch: 2, Train_acc:53.1%, Train_loss:1.403, Test_acc:64.6%, Test_loss:1.721, Lr:1.00E-02
Epoch: 3, Train_acc:58.8%, Train_loss:1.243, Test_acc:49.6%, Test_loss:1.154, Lr:1.00E-02
Epoch: 4, Train_acc:60.2%, Train_loss:1.238, Test_acc:16.8%, Test_loss:48.591, Lr:1.00E-02
Epoch: 5, Train_acc:53.1%, Train_loss:1.455, Test_acc:46.9%, Test_loss:2.093, Lr:1.00E-02
Epoch: 6, Train_acc:61.9%, Train_loss:1.073, Test_acc:31.9%, Test_loss:38.314, Lr:1.00E-02
Epoch: 7, Train_acc:63.3%, Train_loss:0.964, Test_acc:72.6%, Test_loss:0.938, Lr:1.00E-02
Epoch: 8, Train_acc:67.3%, Train_loss:0.911, Test_acc:47.8%, Test_loss:1.117, Lr:1.00E-02
Epoch: 9, Train_acc:67.3%, Train_loss:0.892, Test_acc:54.0%, Test_loss:16.555, Lr:1.00E-02
Epoch:10, Train_acc:71.9%, Train_loss:0.765, Test_acc:67.3%, Test_loss:1.575, Lr:1.00E-02
Done




![[C语言] 数据存储](https://img-blog.csdnimg.cn/bd3b92d83f8b4542ab34c4a71256281e.png)