注: 本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。
前言
在生产环境上,由于不规范的优化措施,数据库中可能存在大量的索引,并且相当一部分的索引重未被使用过,今天带大家如何找出这些索引。
一、存在大量未使用的索引带来的危害
在PostgreSQL中,存在大量未使用的索引可能会带来以下几个问题:
1. 性能下降:每当对表进行插入、删除或更新操作时,相关的索引都需要被更新。如果有大量未使用的索引,这些索引的维护工作可能会消耗大量的CPU和I/O资源,导致数据库性能下降。
2. 占用存储空间:索引本身会占用存储空间。如果有大量未使用的索引,这些索引会浪费大量的磁盘空间,可能导致存储成本增加。
3. 影响查询优化器的决策:PostgreSQL的查询优化器在决定查询执行计划时,会考虑所有可用的索引。如果有大量未使用的索引,可能会增加查询优化器的计算复杂度,影响其决策的效率和准确性。
4. 备份和恢复时间增加:如果有大量未使用的索引,备份和恢复数据库的时间可能会增加,因为索引数据也需要被备份和恢复。
因此,定期审查和清理未使用的索引是一个很好的数据库维护实践。但在删除索引之前,需要确保这些索引真的不再需要,因为有些索引可能只在特定的查询或特定的时间(如每月的报表生成)中被使用。
二、实战案例
接下来,我们以实际案例来演示索引过多带来的性能影响
2.1 创建带索引的表

2.2 创建不带索引的表

2.3 插入数据测试
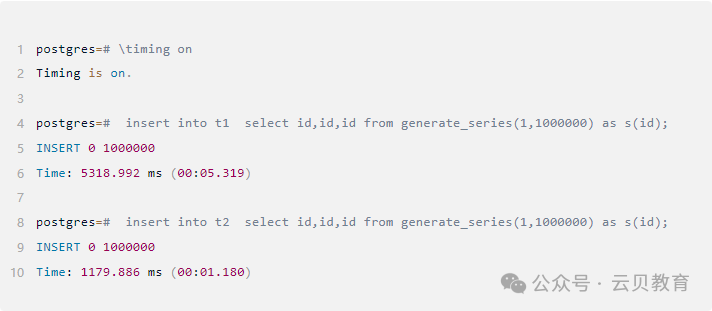
上面结果可以看出,同样结构的表,插入数据的操作,有无索引的性能相关近5倍!
2.4 修改数据测试
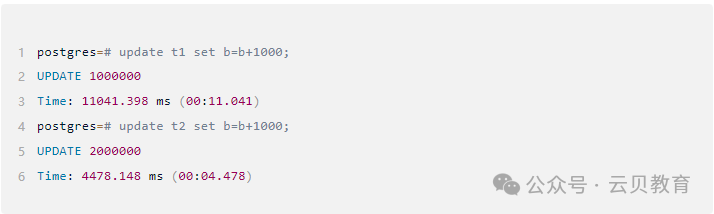
上面结果可以看出,同样结构的表,修改数据的操作,有无索引的性能相关近3倍!
2.5 查看此时表的体积
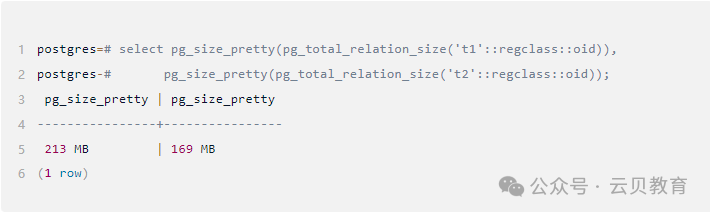
因为索引的原因,t1的体积更大。
三、索引使用的规则
PostgreSQL的查询优化器使用一种称为成本优化的方法来决定是否使用索引,以及选择使用哪个索引。以下是一些影响PostgreSQL使用索引的主要因素:
1. 查询的选择性:索引对于高选择性的查询最有用。选择性是指查询结果返回的记录占表中总记录的比例。例如,如果你正在查询一个人口为几十亿的国家中的一小部分人,这个查询就有很高的选择性,使用索引会很有帮助。相反,如果你正在查询的数据占总数据的大部分,那么全表扫描可能会更快。
2. 索引类型:PostgreSQL支持多种类型的索引,包括B-tree、Hash、GiST、SP-GiST、GIN和BRIN。每种索引类型都有其特定的用途和优势。例如,B-tree索引适用于等于、大于、小于等操作,而GIN索引适用于数组和全文搜索。
3. 数据分布:如果表中的数据分布不均匀,索引可能会更有效。例如,如果一个字段的值大部分都是唯一的,那么对这个字段创建索引可能会很有帮助。
4. 索引大小和深度:大的索引需要更多的磁盘I/O操作来读取,而深的索引需要更多的磁盘I/O操作来遍历。因此,如果一个索引很大或很深,查询优化器可能会选择不使用它。
5. 硬件和系统配置:硬件的性能(如CPU速度、内存大小、磁盘速度等)和PostgreSQL的配置(如工作内存、随机页面成本等)也会影响查询优化器的决策。
6. 统计信息:PostgreSQL的查询优化器使用统计信息来估计查询的成本。这些统计信息包括表的大小、索引的大小、数据的分布等。如果这些统计信息不准确,查询优化器可能会做出错误的决策。
最后,要注意的是,查询优化器的目标是尽可能快地返回查询结果,而不一定是尽可能少地读取磁盘页面。因此,有时候即使存在索引,查询优化器也可能选择全表扫描,因为它认为这样会更快。
四、如何找出未使用的索引
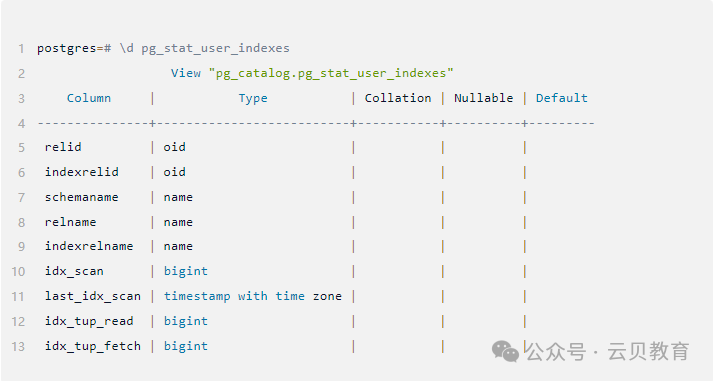
在pgv16的版本中,有一个视图pg_stat_user_indexes可以查看索引使用情况
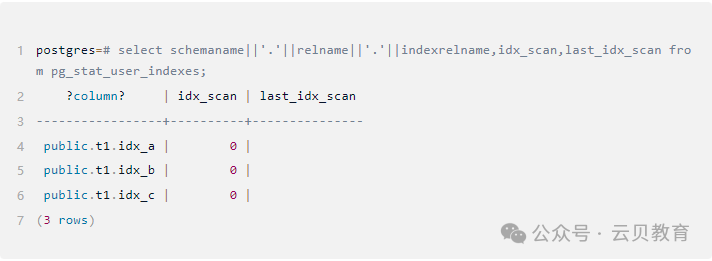
查看当前索引使用的频率
调用索引再次查看

SQL的执行计划中显示调用了索引idx_a ,查询pg_stat_user_indexes结果显示索引的扫描次数没有增加,为什么?原来explain并未真正执行SQL。
那加上analyze参数
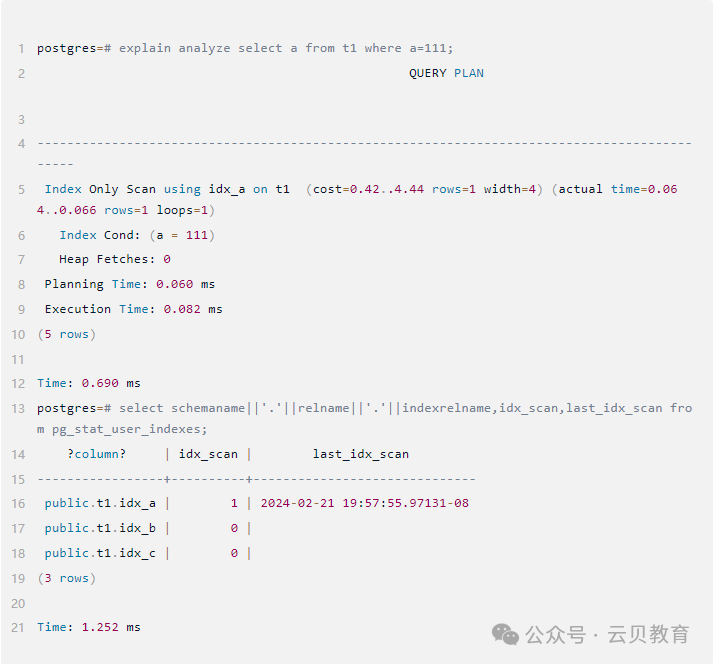
在v16之前的版本中,pg_stat_user_indexes.last_idx_scan字段是没有的,只能通过手工编写脚本来记录索引扫描时间,也可以通过SELECT pg_stat_reset()函数重置索引的使用记录,人工观察一周来排查。这里不再赘述。
五、总结
通过以上实验,我们知道了表上索引过多的危害及如何定位未使用索引的方法,对pg数据库的索引有进一步的了解。