【Python】科研代码学习:八 FineTune PretrainedModel [用 trainer,用 script] LLM文本生成
- 自己整理的 HF 库的核心关系图
- 用 trainer 来微调一个预训练模型
- 用 script 来做训练任务
- 使用 LLM 做生成任务
- 可能犯的错误,以及解决措施
自己整理的 HF 库的核心关系图
- 根据前面几期,自己整理的核心库的使用/继承关系

用 trainer 来微调一个预训练模型
- HF官网API:FT a PretrainedModel
今天讲讲FT训练相关的内容吧
这里就先不提用keras或者native PyTorch微调,直接看一下用trainer微调的基本流程 - 第一步:加载数据集和数据集预处理
使用datasets进行加载 HF 数据集
from datasets import load_dataset
dataset = load_dataset("yelp_review_full")
另外,需要用 tokenizer 进行分词。自定义分词函数,然后使用 dataset.map() 可以把数据集进行分词。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
也可以先选择其中一小部分的数据单独拿出来,做测试或者其他任务
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
- 第二步,加载模型,选择合适的
AutoModel或者比如具体的LlamaForCausalLM等类。
使用model.from_pretrained()加载
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
- 第三步,加载 / 创建训练参数
TrainingArguments
from transformers import TrainingArguments
training_args = TrainingArguments(output_dir="test_trainer")
- 第四步,指定评估指标。
trainer在训练的时候不会去自动评估模型的性能/指标,所以需要自己提供一个
※ 这个evaluate之前漏了,放后面学,这里先摆一下 # TODO
import numpy as np
import evaluate
metric = evaluate.load("accuracy")
- 第五步,使用
trainer训练,提供之前你创建好的:
model模型,args训练参数,train_dataset训练集,eval_dataset验证集,compute_metrics评估方法
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
- 完整代码,请替换其中的必要参数来是配置自己的模型和任务
from datasets import load_dataset
from transformers import (
LlamaTokenizer,
LlamaForCausalLM,
TrainingArguments,
Trainer,
)
import numpy as np
import evaluate
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
"""
Load dataset, tokenizer, model, training args
preprosess into tokenized dataset
split training dataset and eval dataset
"""
dataset = load_dataset("xxxxxxxxxxxxxxxxxxxx")
tokenizer = LlamaTokenizer.from_pretrained("xxxxxxxxxxxxxxxxxxxxxxxxxx")
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
model = LlamaForCausalLM.from_pretrained("xxxxxxxxxxxxxxx")
training_args = TrainingArguments(output_dir="xxxxxxxxxxxxxx")
"""
define metrics
set trainer and train
"""
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
用 script 来做训练任务
- 我们在很多项目中,都会看到启动脚本是一个
.sh文件,一般里面可能会这么写:
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
- 或者最近看到的一个
OUTPUT_DIR=${1:-"./alma-7b-dpo-ft"}
pairs=${2:-"de-en,cs-en,is-en,zh-en,ru-en,en-de,en-cs,en-is,en-zh,en-ru"}
export HF_DATASETS_CACHE=".cache/huggingface_cache/datasets"
export TRANSFORMERS_CACHE=".cache/models/"
# random port between 30000 and 50000
port=$(( RANDOM % (50000 - 30000 + 1 ) + 30000 ))
accelerate launch --main_process_port ${port} --config_file configs/deepspeed_train_config_bf16.yaml \
run_cpo_llmmt.py \
--model_name_or_path haoranxu/ALMA-13B-Pretrain \
--tokenizer_name haoranxu/ALMA-13B-Pretrain \
--peft_model_id haoranxu/ALMA-13B-Pretrain-LoRA \
--cpo_scorer kiwi_xcomet \
--cpo_beta 0.1 \
--use_peft \
--use_fast_tokenizer False \
--cpo_data_path haoranxu/ALMA-R-Preference \
--do_train \
--language_pairs ${pairs} \
--low_cpu_mem_usage \
--bf16 \
--learning_rate 1e-4 \
--weight_decay 0.01 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type inverse_sqrt \
--warmup_ratio 0.01 \
--ignore_pad_token_for_loss \
--ignore_prompt_token_for_loss \
--per_device_train_batch_size 2 \
--evaluation_strategy no \
--save_strategy steps \
--save_total_limit 1 \
--logging_strategy steps \
--logging_steps 0.05 \
--output_dir ${OUTPUT_DIR} \
--num_train_epochs 1 \
--predict_with_generate \
--prediction_loss_only \
--max_new_tokens 256 \
--max_source_length 256 \
--seed 42 \
--overwrite_output_dir \
--report_to none \
--overwrite_cache
- 玛雅,这么多
--xxx,看着头疼,也不知道怎么搞出来这么多参数作为启动文件的。
这种就是通过script启动任务了 - github:transformers/examples
看一下 HF github 给的一些任务的 examples 学习例子,就会发现
在main函数中,会有这样的代码
这个就是通过argparser来获取参数
貌似还有parser和HfArgumentParser,这些都可以打包解析参数,又是挖个坑 # TODO
这样的话,就可以通过.sh来在启动脚本中提供相关参数了
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument("--prompt", type=str, default="")
parser.add_argument("--length", type=int, default=20)
parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
# ....... 太长省略
- 用脚本启动还有什么好处呢
可以使用accelerate launch run_summarization_no_trainer.py进行加速训练
再给accelerate挖个坑 # TODO - 所以,在
.shscript 启动脚本中具体能提供哪些参数,取决于这个入口.py文件的parser打包解析了哪些参数,然后再利用这些参数做些事情。
使用 LLM 做生成任务
- HF官网API:Generation with LLMs
官方都特地给这玩意儿单独开了一节,就说明其中有些很容易踩的坑… - 对于
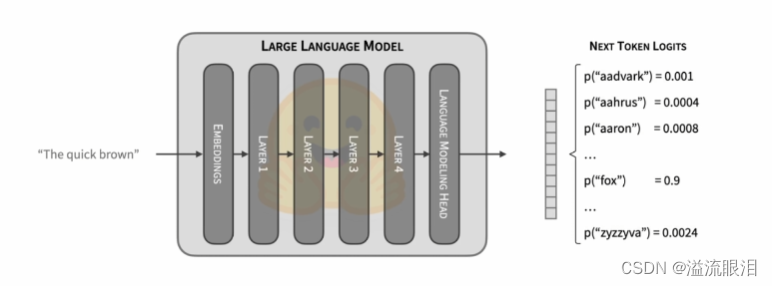
CausalLM,首先看一下 next token 的生成逻辑:输入进行分词与嵌入后,通过多层网络,然后进入到一个LM头,最终获得下一个 token 的概率预测 - 那么生成句子的逻辑,就是不断重复这个过程,获得 next token 概率预测后,通过一定的算法选择下一个 token,然后再重复该操作,就能生成整个句子了。
- 那什么时候停止呢?要么是下一个token选择了
eos,要么是到达了之前定义的max token length
- 接下来看一下代码逻辑
- 第一步,加载模型
device_map:控制模型加载在GPUs上,不过一般我会使用os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" 以及 os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
load_in_4bit设置加载量化
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
)
- 第二步,加载分词器和分词
记得分词的向量需要加载到cuda中
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
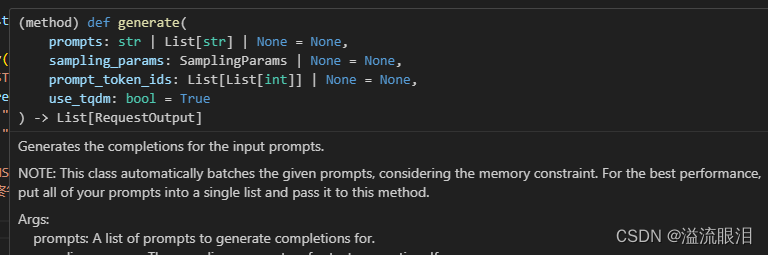
- 但这个是否需要分词取决于特定的
model.generate()方法的参数
就比如disc模型的generate()方法的参数为:
也就是说,我输入的 prompt 只用提供字符串即可,又不需要进行分词或者分词器了。
- 第三步,通常的
generate方法,输入是 tokenized 后的数组,然后获得 ids 之后再 decode 变成对应的字符结果
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
- 当然我也可以批处理,一次做多个操作,批处理需要设置pad_token
tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
model_inputs = tokenizer(
["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
可能犯的错误,以及解决措施
- 控制输出句子的长度
需要在generate方法中提供max_new_tokens参数
model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
# By default, the output will contain up to 20 tokens
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Setting `max_new_tokens` allows you to control the maximum length
generated_ids = model.generate(**model_inputs, max_new_tokens=50)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
-
生成策略修改
有时候默认使用贪心策略来获取 next token,这个时候容易出问题(循环生成等),需要设置do_sample=True
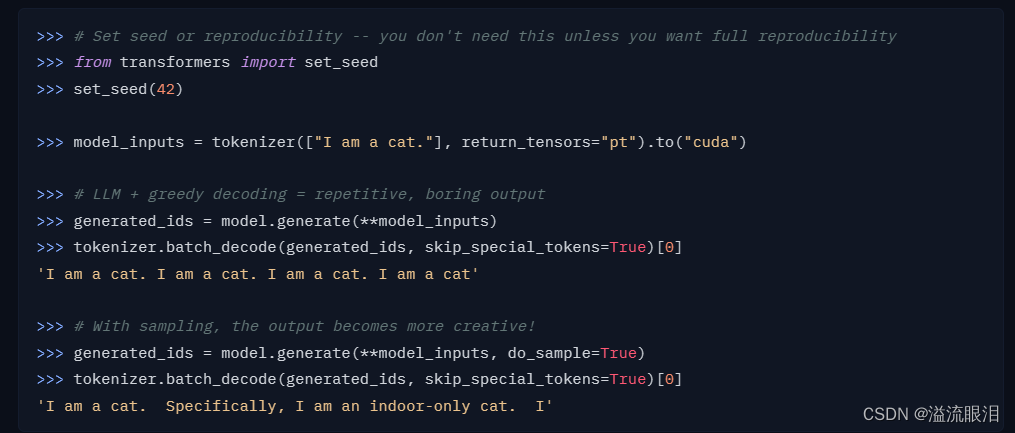
-
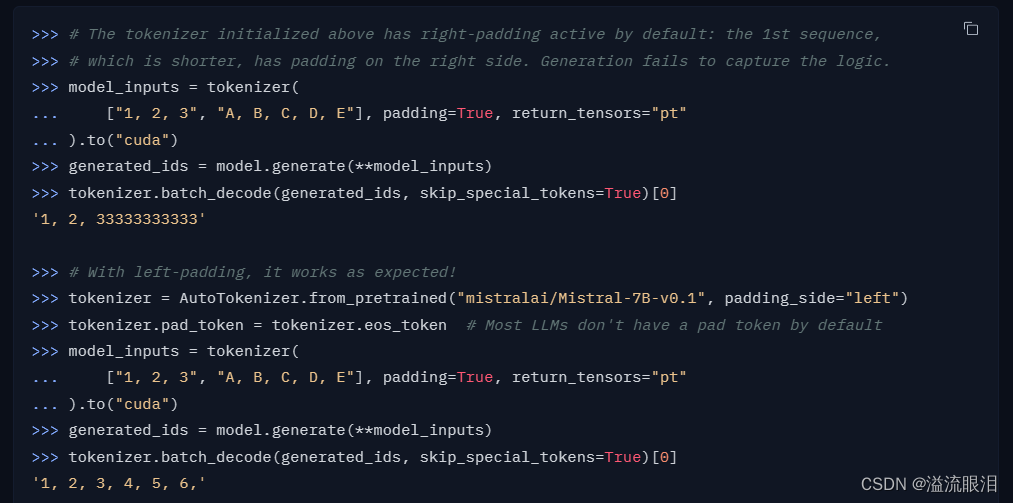
pad 对齐方向
如果输入不等长,那么会进行pad操作
由于默认是右侧padding,而LLM在训练时没有学会从pad_token接下来的生成策略,所以会出问题
所以需要设置padding_side="left "
-
如果没有使用正确的
prompt(比如训练时的prompt格式),得到的结果就会不如预期
(in one sitting = 一口气) (thug = 暴徒)
这里需要参考 HF对话模型的模板 以及 HF LLM prompt 指引

比如说,QA的模板就像这样。
更高级的还有few shot和COT技巧。
torch.manual_seed(4)
prompt = """Answer the question using the context below.
Context: Gazpacho is a cold soup and drink made of raw, blended vegetables. Most gazpacho includes stale bread, tomato, cucumbers, onion, bell peppers, garlic, olive oil, wine vinegar, water, and salt. Northern recipes often include cumin and/or pimentón (smoked sweet paprika). Traditionally, gazpacho was made by pounding the vegetables in a mortar with a pestle; this more laborious method is still sometimes used as it helps keep the gazpacho cool and avoids the foam and silky consistency of smoothie versions made in blenders or food processors.
Question: What modern tool is used to make gazpacho?
Answer:
"""
sequences = pipe(
prompt,
max_new_tokens=10,
do_sample=True,
top_k=10,
return_full_text = False,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")