为什么要做接口自动化框架
1、业务与配置的分离
2、数据与程序的分离;数据的变更不影响程序
3、有日志功能,实现无人值守
4、自动发送测试报告
5、不懂编程的测试人员也可以进行测试
正常接口测试的流程是什么?
确定接口测试使用的工具----->配置需要的接口参数----->进行测试----->检查测试结果----->生成测试报告
测试的工具:python+requests
接口测试用例:excel
一、接口框架如下:
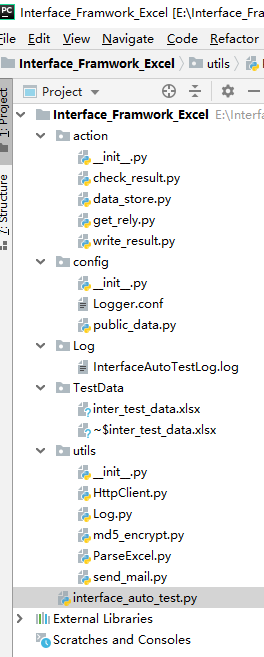
1、action包:用来存放关键字函数
2、config包:用来存放配置文件
3、TestData:用来存放测试数据,excel表
4、Log包:用来存放日志文件
5、utils包:用来存放公共的类
6、运行主程序interface_auto_test.py
7、Readme.txt:告诉团队组员使用改框架需要注意的地方
二、接口的数据规范设计---Case设计
一个sheet对应数据库里面一张表

APIsheet存放
编号;从1开始
接口的名称(APIName);
请求的url(RequestUrl);
请求的方法(RequestMethod);
传参的方式(paramsType):post/get请求方法不一样
用例说明(APITestCase)
是否执行(Active)部分接口已测通,下次不用测试,直接把这里设置成N,跳过此接口
post与get的区别
查看post详情
post请求参数一般是json串,参数放在from表单里面;参数一般不可见,相对来说安全性高些
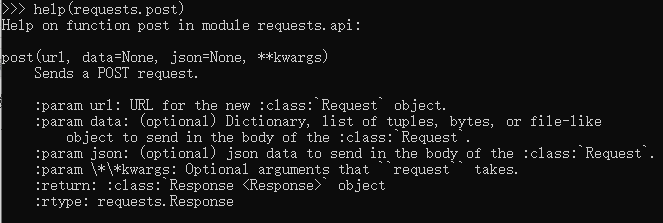
查看get详情
get请求参数一般直接放在url里面

2.1注册接口用例

RequestData:请求的数据
(开发制定的传参方式)
RelyData:数据依赖
ResponseCode:响应code
ResponseData:响应数据
DataStore:存储的依赖数据;如果存在数据库里面,在表里增加一个字段用来存依赖的数据
(存储的方式是编写接口自动化的人员来设定的存储方式)
CheckPoint:检查点
Active:是否执行
Status:执行用例的状态,方便查看用例是否执行成功
ErrorInfo:case运行失败,失败的错误信息;eg:是也本身的原因还是case设置失败,还是其他原因
2.2登录接口用例

RequestData:请求的数据
(开发制定的传参方式)
RelyData:数据依赖
(存储的方式是编写接口自动化的人员来设定的存储方式)
ResponseCode:响应code
ResponseData:响应数据
DataStore:存储的依赖数据;如果存在数据库里面,在表里增加一个字段用来存依赖的数据
(存储的方式是编写接口自动化的人员来设定的存储方式)
CheckPoint:检查点
Active:是否执行
Status:执行用例的状态,方便查看用例是否执行成功
ErrorInfo:case运行失败,失败的错误信息;eg:是也本身的原因还是case设置失败,还是其他原因
重点说明下RelyData:数据依赖
采取的是字典:key:value来存储数据格式;
{"request":{"username":"register->1","password":"register->1"},"response":{"code":"register->1"}}
格式化之后:
| 1 2 3 4 5 6 7 8 9 |
|
三、创建utils包:用来存放公共的类
3.1 ParseExcel.py 操作封装excel的类(ParseExcel.py)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 |
|
3.2 封装get/post请求(HttpClient.py)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
3.3 封装MD5(md5_encrypt)
| 1 2 3 4 5 6 7 8 9 10 |
|
3.4 封装Log
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
3.5 封装发送Email类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
四、 创建config包 用来存放公共的参数、配置文件、长时间不变的变量值
创建public_data.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
五、创建TestData目录,用来存放测试文件
inter_test_data.xlsx
六、创建action包,用来存放关键字函数
6.1 解决数据依赖 (GetRely.py)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
|
6.2 解决数据存储(RelyDataStore.py)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
|
6.3 校验数据结果(CheckResult.py)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
6.4 往excel里面写结果
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
七、创建Log目录用来存放日志
八、主函数
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
|
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】






![[java——基础] 双亲委派机制](https://img-blog.csdnimg.cn/direct/af60d2796b1148c48361151c636b8318.png)