urllib是Python自带的标准库中用于网络请求的库 ,无需安装,直接引用即可。通常用于爬虫开发、API(应用程序编程接口)数据获取和测试。
urllib库的几个模块:
- urllib.request :用于打开和读取URL
- urllib.error:包含提出的例外(异常)urllib.request
- urllib.parse:用于解析URL
- urllib.robotparser:用于解析robots.txt文件
import urllib.request
# 请求 URL
response = urllib.request.urlopen('http://www.example.com')
# 获取响应内容
content = response.read()
# 打印响应内容前 100 个字符
print(content[:100]) urllib.parse 模块可以用来解析 URL:
from urllib.parse import urlparse, parse_qs
# 解析 URL
url = 'http://www.example.com/path?name=John&age=30'
parsed_url = urlparse(url)
# 获取 URL 的各个组成部分
scheme = parsed_url.scheme
netloc = parsed_url.netloc
path = parsed_url.path
params = parsed_url.params
query = parsed_url.query
fragment = parsed_url.fragment
# 解析查询字符串
query_dict = parse_qs(query)
print(f"Scheme: {scheme}")
print(f"Netloc: {netloc}")
print(f"Path: {path}")
print(f"Params: {params}")
print(f"Query: {query}")
print(f"Fragment: {fragment}")
print(f"Query dictionary: {query_dict}")发送请求
- urllib.request库 模拟浏览器发起一个HTTP请求,并获取请求响应结果。
- urllib.request.urlopen urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None)
data:默认值为None,urllib判断参数data是否为None从而区分请求方式。
urlopen函数返回的结果是一个http.client.HTTPResponse对象
写一个爬虫程序:
- 导入 urllib.request
- 打开url
- 读取响应内容
IP代理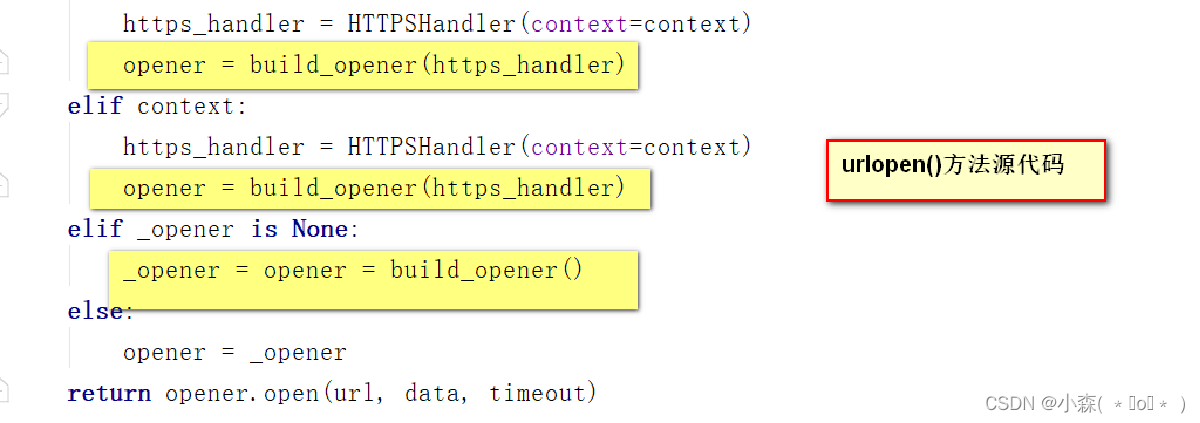
IP代理:假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理。
IP代理的分类 :
- 透明代理:目标网站知道你使用了代理且知道你的源IP地址
- 匿名代理:匿名程序比较低,也就是网站知道你使用了代理,但是并不知道你的源IP地址
- 高匿代理:最保险的方式,目录网站既不知道你使用了代理更不知道你的源IP
使用Cookie
为什么需要使用Cookie 解决http的无状态性
- 实例化MozillaCookieJar (保存cookie)
- 创建 handler对象(cookie的处理器)
- 创建opener对象
- 打开网页(发送请求获取响应)
- 保存cookie文件
异常处理主要用到两大类
urllib.error.URLError :用于捕获由urllib.request产生的异常,使用reason属性返回错误原因。
urllib.error.HTTPError :用于处理HTTP与HTTPS请求的错误,它有三个属性:
- code:请求返回的状态码
- reason:返回错误的原因
- headers:请求返回的响应头信息
requests库
Requests 是Python一个很实用的HTTP客户端,完全满足如今网络爬虫的需求
requests库的安装
- windows:pip install requests
- Mac : pip3 install requests
- Linux:sudo pip install requests
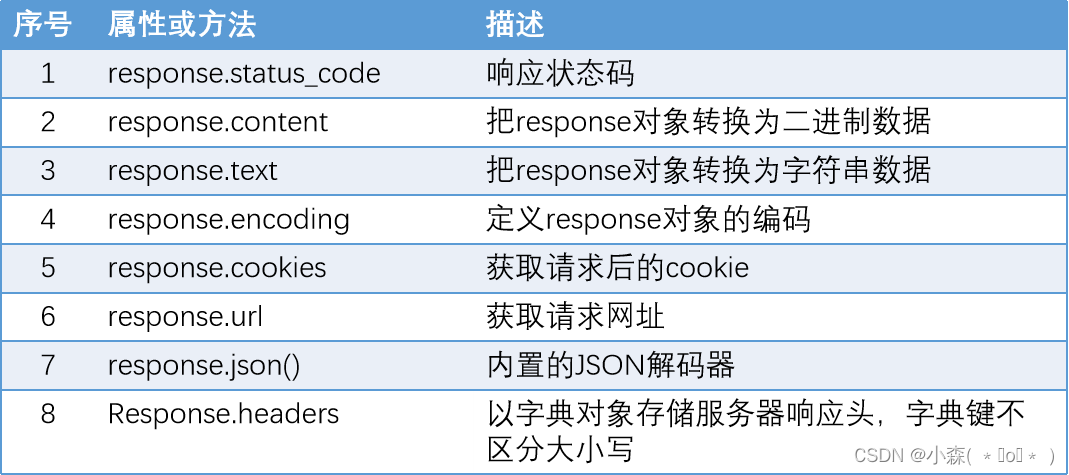
| 方法 | 描述 | |
| requests.request(url) | 构造一个请求,支持以下各种方法 | |
| requests.get() | 发送Get请求 | |
| requests.post() | 发送Post请求 | |
| requests.head() | 获取HTML的头部信息 | |
| requests.put() | 发送Put请求 | |
| requests.patch() | 提交局部修改的请求 | |
| requests.delete() | 提交删除请求 |
语法结构: requests.get(url, params=None)
- url:需要爬取的网站的网址
- params:请求参数
post请求
requests.post( url, data=None, json=None)
- url:需要爬取的网站的网址
- data:请求数据
- json :json格式的数据
POST请求和GET请求区别
- 数据传输方式:GET请求通常将参数包含在URL中,而POST请求则通过request body传递参数。这意味着GET请求的参数直接附加在URL之后,而POST请求的参数则放在请求体中。
- 安全性:由于GET请求的参数直接暴露在URL中,所以隐私性和安全性较差。POST请求的参数不在URL中,因此相对更加安全。
- 数据长度限制:GET请求的数据长度受到URL长度的限制,不同的浏览器和服务器对URL长度有不同的限制,一般限制在2~8K之间,更常见的是1K以内。POST请求没有长度限制,因为请求数据是放在body中的。
- 缓存和历史记录:GET请求可以被缓存,而POST请求不会被缓存。GET请求会被保存在浏览器的历史记录中,可以被收藏为书签,但POST请求不会。
- 影响服务器状态:GET请求通常用于获取信息,不应对服务器状态产生影响。POST请求通常用于提交数据,可能会改变服务器上的状态。
- 浏览器兼容性:GET请求可以直接在浏览器地址栏中输入URL来访问,而POST请求通常需要通过表单提交或其他客户端代码来实现。
- 重试和刷新:GET请求可以安全地进行重试和刷新,因为它只是获取数据。POST请求在刷新时可能会重复提交数据,导致多次执行相同的操作。
session发请求
- 获取session对象:requests.session()
- session对象.post() 发送post请求
import requests
# 创建一个Session对象
session = requests.Session()
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
# 发送GET请求
response = session.get('https://www.example.com', headers=headers)
# 打印响应内容
print(response.text)
# 关闭Session
session.close()