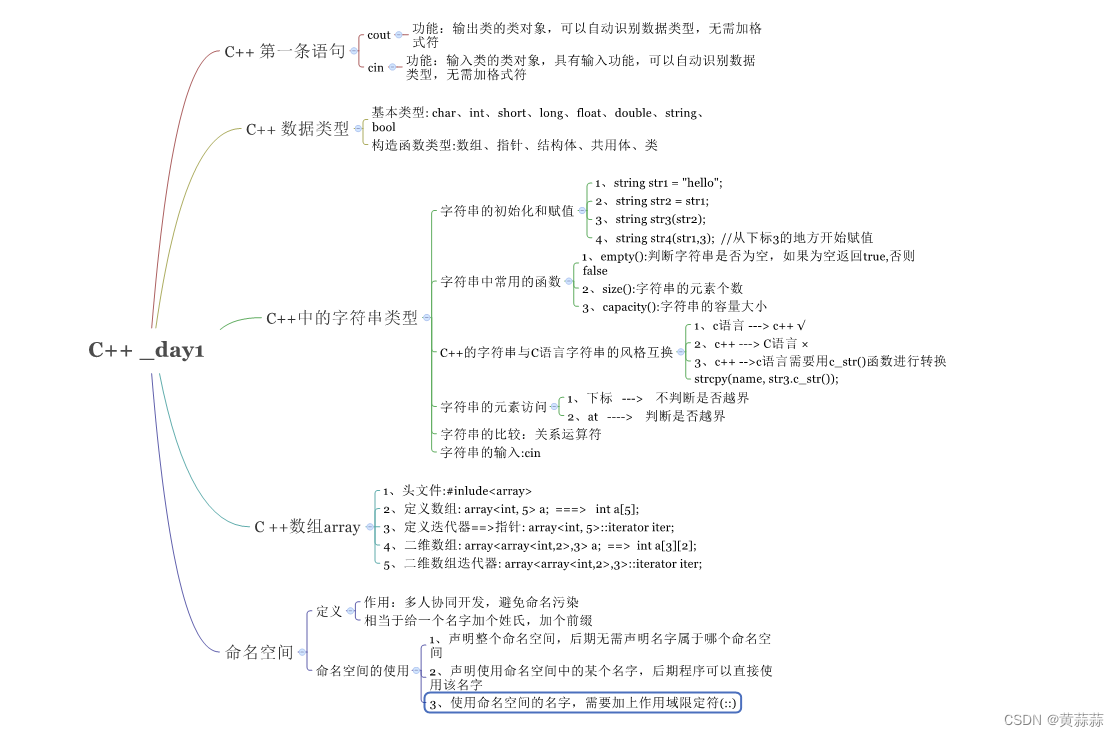
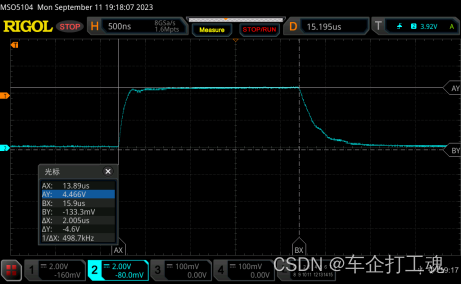
业务hang住,后台查看事件都是“latch: shared pool”

根据堵塞的blocking_session检查sid为1873的会话

发现都是MMAN进程堵塞,我们都知道Oracle的MMAN进程(Memory Manager Process,内存管理进程)会根据系统负载的变化和内存需要,自动调整SGA中各个组件的内存大小。
检查awr的内存调整

shared pool大小从开始的8640M调整到了8512M,但buffer cache却从8448M到8576M,说明buffer cache的内存需求增大,挤占了shared pool的内存。当两个内存资源都不足的情况下,就会调用MMAN进程一直协调资源。
看buffer pool调优资源表:

我们发现8576M是当前自动调整的buffer pool内存,甚至到16640M,评估物理读一直变化很大。
检查shared pool 资源变化,发现shared被挤压严重:
select a.instance_number,to_char(b.end_interval_time,'yyyy-mm-dd hh24:mi:ss'),pool,sum(bytes)/1024/1024 from dba_hist_sgastat a,dba_hist_snapshot b
where a.snap_id=b.snap_id
and a.pool ='shared pool' group by a.instance_number,to_char(b.end_interval_time,'yyyy-mm-dd hh24:mi:ss'),pool
order by 1,2;
也就是两个内存资源均不够了,导致性能下降,所以最好的解决方式是增加物理内存和sga,或者优化sql降低内存消耗。