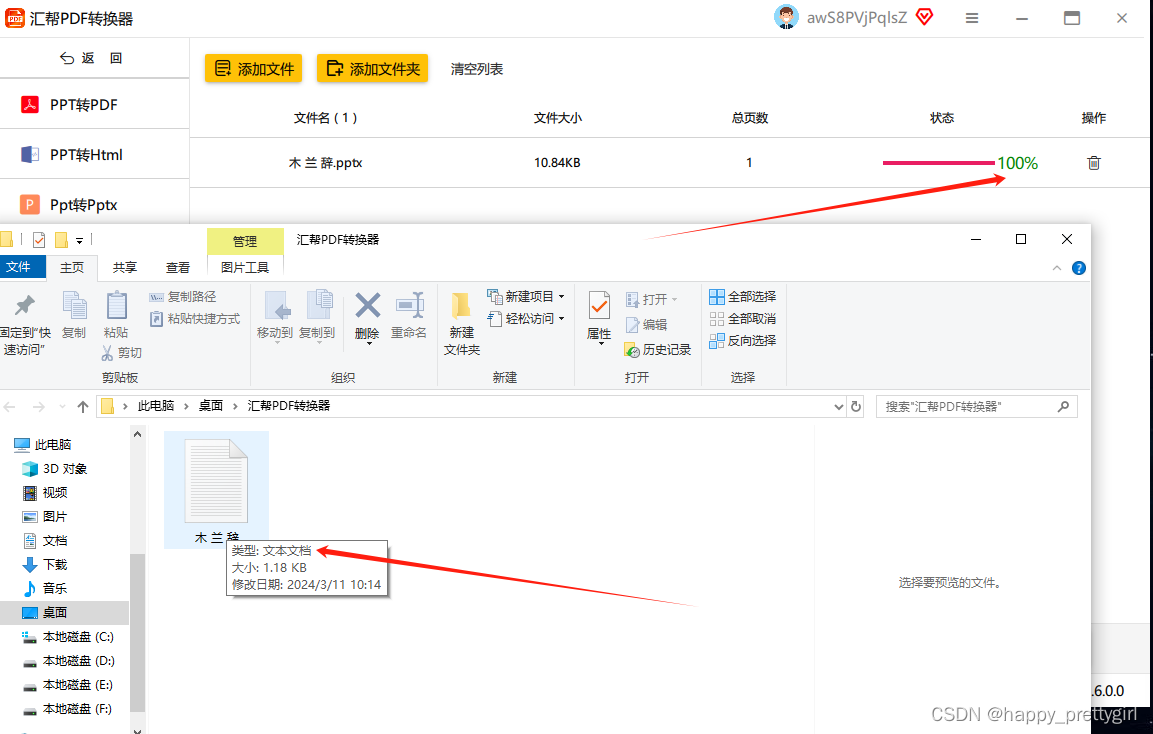
股市变换莫测,任何一点风吹草动都可能影响股票的走势,面对这种不确定性,投资者们常常感到无所适从。
于是研究者们盯上了如今大火的大模型技术,试图通过高效地处理和分析海量的股市数据,挖掘出其中的隐藏规律和趋势,快速捕捉到新信息对市场的即时影响,预测未来股价的走势,为投资者提供决策支持。
例如,前不久小瑶就跟大家分享过一篇论文《碾压华尔街,GPT-4 选股收益超40%》。
今天再跟大家分享一篇近期发表在信息检索顶级会议WWW2024上的一篇论文,不仅收益率达到恐怖的16.6%,超越了ChatGPT,而且还能给出合理的决策解释!
论文标题:
Learning to Generate Explainable Stock Predictions using Self-Reflective Large Language Models
论文链接为:
https://arxiv.org/pdf/2401.18058.pdf
这篇论文提出了一个“总结-解释-预测”Summarize-Explain-Predict (SEP)的框架,该框架利用了一种模型自反思思想和近端策略优化(PPO),使LLM能够自主学习如何生成可解释的股票预测。
通过自反思过程,模型学习如何解释过去的股票波动。PPO训练过程中的训练样本来自反思过程中生成的响应,无需人工标注,极大得节省了人力,增大了生成的解释质量,并进一步提高股票预测的正确性。
任务定义:可解释的股票预测
给定一只股票及其过去天的相关文本语料库,目标是为下一个交易日生成一则股票预测,其中包括了一个二进制价格变动 和一个可读的解释。
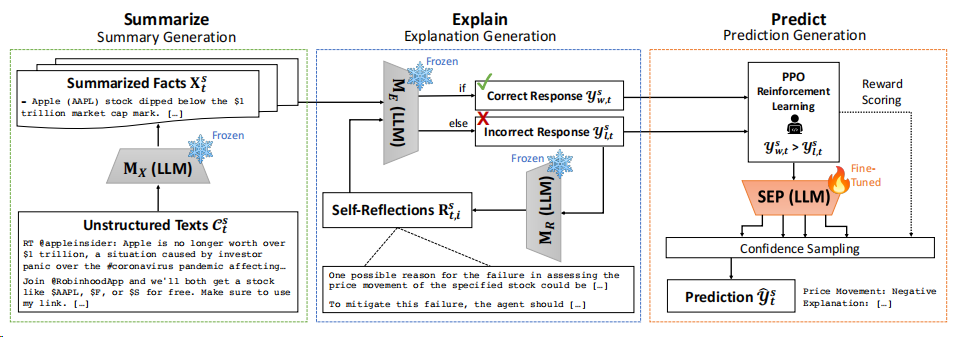
Summarize-Explain-Predict(SEP)框架
SEP框架包含三个主要组件,如下图所示:
-
总结:从非结构化文本输入中生成事实信息的摘要;
-
解释:通过迭代的自反思过程生成股票预测的解释并进行改进;
-
预测::通过微调语言模型后使用自动生成的注释样本生成基于置信度的预测。
1. 自我总结模块:从海量文本中提取关键信息
鉴于𝑇天的原始文本中的信息会超过字符限制,自我总结模块利用LLMs强大的摘要能力,将大量文本输入数据转换为事实信息的要点摘要。提示包过两个可变输入:指定的股票,和每天的非结构化文本输入。然后LLM 生成影响股票的新闻摘要,例如“包括苹果(AAPL)、谷歌、亚马逊和Facebook在内的大型科技股票超出了盈利预期”。可以表示为:
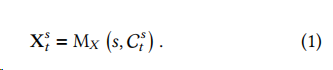
2. 自我解释模块:通过自反思过程生成股价解释
自我解释模块的目标是双重的:一方面生成清晰的股票预测解释,另一方面通过迭代的自反思过程改进LLM自身的预测。
解释模块的提示包含两个变量输入:指定的股票和前一个模块生成的一系列提取信息的序列。给定这些输入,LLM 生成响应,其中应包含下一交易日的价格变动 和一个可读的解释。形式化为:
![]()
在此过程中,还加入了自我反思循坏迭代改进回复,如下图所示:
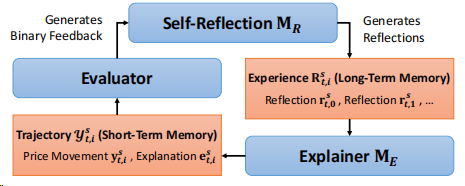
从生成的价格变动中,通过评估其与实际情况的一致性获得二进制反馈。对于错误的样本,引入LLM 为每一次迭代生成一个口头反馈。
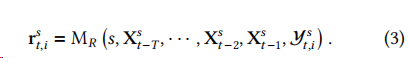
对于每一次迭代,每个反思代表LLM从失败中学到的教训,将其表示为一组反思,连同原始输入再次输入LLM ,以生成下一次迭代的价格变动和解释。
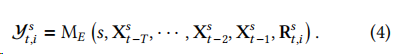
通过这个过程,能够获得每个成功的反思所对应的正确和错误回答的一对。分别将其定义为和,用于后续模块预测股票走势。
3. 自我预测模块:利用PPO训练优化预测能力
自我预测模块使用自我解释模块构建的数据样本微调LLM,以便在测试期间生成最可能的股票预测和解释。具体流程如图所示:

-
收集演示数据:从初始迭代中的正确预测中获取的,没有相应的“错误”回答。这些样本用于使用监督微调(SFT)方法训练一个监督策略。
-
收集比较数据:其中包含每个结构化输入的配对正确和错误回答和。是模型成功反思的正负样本对,用于训练一个奖励模型,为正确的回答给予更高的奖励分数。
-
使用有监督的策略初始化模型,然后利用它为整体数据集中随机选择的样本生成预测。接下来,奖励模型用于为每个回复生成奖励。通过最大化总体奖励来优化PPO模型。
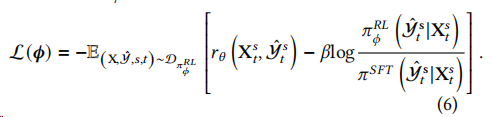
在推理过程中,首先使用预训练的LLM对无结构化输入文本进行总结。然后,使用训练好的策略从总结的事实生成下一天的预测。对于生成预测,使用一个最佳采样器,在生成个响应之后,使用奖励模型的分数选择最佳响应。
实验设计
1. 数据集构建
本文遵循ACL18 StockNet数据集的收集方法,原始数据集的持续时间跨越2014年至2016年,作者又采集了2020年至2022年的更新版本。选择了11个行业中市值最高的前5只股票,共计55只股票。股价数据从Yahoo Finance收集,而推文数据则通过Twitter API获取。由于每天的推文数量庞大,作者采用了BERTopic聚类来识别每天的代表性推文,这些推文将作为所有模型的文本输入。
2. 评估指标
本文采用预测准确性和Matthews相关系数(MCC)作为评估指标,用于二元股票分类任务。准确性指标衡量模型预测的准确度,而MCC则考虑了真正例和假正例的比率,是一个更全面的性能指标。此外,还通过定性分析来评估模型生成解释的质量。
实验结果
1. 预测准确性
在预测准确性方面,SEP框架经过实验验证,能够在预测准确性和MCC方面超越传统深度学习和LLM方法,如表1所示。
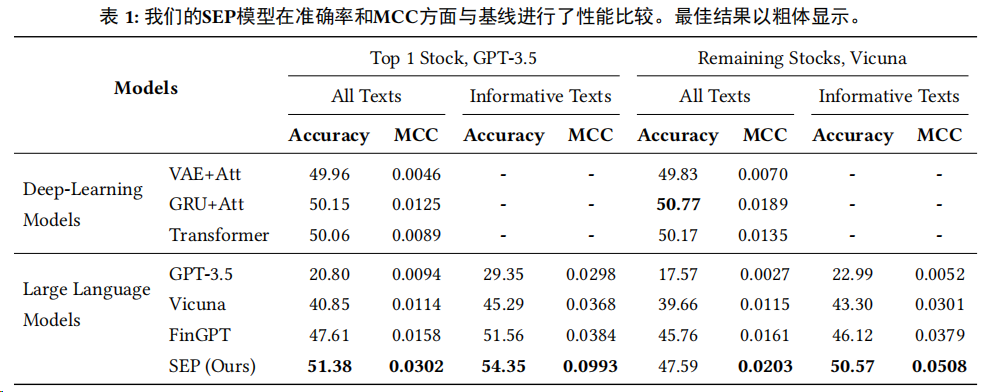
在使用GPT生成的解释进行微调的SEP模型中,预测准确性比最强基线(GRU+Attention)提高了2.4%。
在MCC指标上,SEP模型在所有设置下都优于所有模型,展示了模型在考虑随机猜测后理解自然语言文本对股票走势影响的真实能力。
2. 解释质量的提升
除了生成更好的预测外,使用LLM而不是传统深度学习方法的一个自然优势是它们能够为预测生成解释。而SEP模型在使用自我反思数据微调后,相比一般的LLM能够更加果断地权衡新闻信息,给出质量更高的解释。
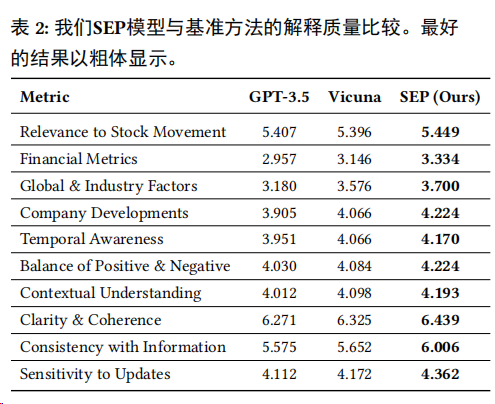
作者创建了一组解释质量指标,并使用GPT-4对样本进行评分。这些指标包括与股票运动的相关性、财务指标、全球和行业因素、公司发展、时间意识、正负信息的平衡、情境理解、清晰度和连贯性、信息一致性以及对更新的敏感性,对比结果如下表所示,可以看到SEP模型在所有指标上都取得了最高分。
组件效能分析:各模块对SEP框架性能的贡献
SEP有三个核心组件:总结、解释‘预测’模块。这些模块共同构成了SEP框架,它们各自的功能和对整体性能的贡献是不可或缺的。
1.总结模块
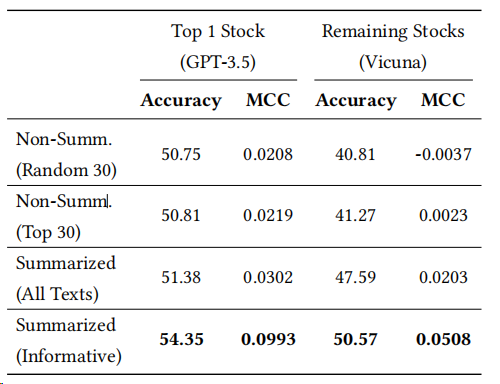
通过摘要,模型能够提取出最关键的信息,为后续的预测和解释提供了坚实的基础。作者将SEP与未经总结和经过总结的输入文本进行比较,还比较了分享最多前30篇文本和随机抽取30篇文本之间的信心量的影响,如下表所示:
-
使用最常分享的文本要比随机抽样更好。
-
总结的文本提供了更好的结果。这也表明总结过程没有丢失任何可能导致退化的重要信息。
-
总结时删除一些非信息性的文本,可以提高表现。
2.解释模块
解释模块的目标是生成清晰的股票预测解释,并通过迭代的自我反思过程来提炼这些解释。
为了调整LLM以产生预测和解释,解释模块必须首先通过二进制反馈和自省尝试生成正确注释的样本。为了展示其效果,作者绘制了每次反思迭代后生成的“决定性”和“正确”预测数目的变化百分比,如下图:
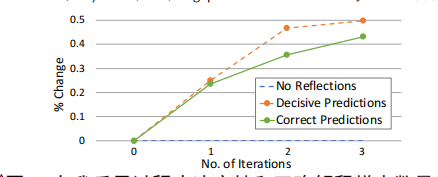
可以看到随着多次自反思迭代,模型生成了越来越多的明确正确的注释样本。这凸显了解释模块在生成标注样本方面的有效性,而无需人工专家的帮助。
3.预测模块
预测模块的目标是通过使用PPO算法微调LLM,以便在测试期间生成最可能的股票预测和解释。
作者对每个变体删除了一个附加组件,即在推理中没有𝑛-shot采样[SEP(1-shot)];没有使用PPO增强学习[SEP(no PPO)];以及没有解释[SEP(binary)],即简单地将LLM调整为进行二元的上升/下降预测。
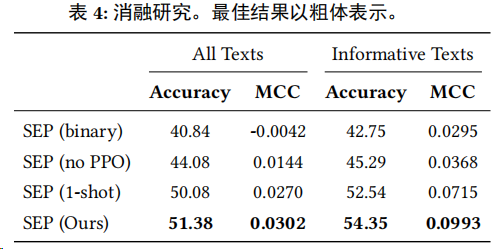
-
在指令调整过程中增加解释组件,即从SEP(binary)到(binary),模型平均改进了6.9%。
-
PPO强化学习的加入显著提高了模型的预测准确性,平均改进了14.8%,这突显了预测模块在提升SEP框架性能中的关键作用。
综上所述,SEP框架中的每个组件都对性能有着显著的贡献。总结模块通过提取关键信息减少了输入的噪声,解释模块通过自我反思生成了高质量的训练样本,而预测模块则通过PPO训练提高了预测的准确性。这些组件的协同工作使得SEP框架在股票预测任务中表现出色。
跨任务泛化能力:SEP框架在投资组合构建任务中的应用
SEP框架不仅在股票预测任务中表现出色,其泛化能力也在投资组合构建任务中得到了验证。
对于投资组合任务,采用与上述相同的方法来微调LLM。输入信息是每天股票篮子的所有生成解释。对于这个实验任务,仅筛选出具有正预测的股票,以减少LLM需要评估的股票数量,并防止产生负权重。然后,提示LLM根据每个给定股票的前景生成投资组合权重,如下图所示:

在每次自我反思迭代中,向反思型LLM提供投资组合权重和对应的总体利润,引导其思考如何提高预测准确性来增加利润。基于这些反思,LLM生成新的权重。接着,将新旧权重输入PPO训练器,选择利润更高的权重作为优化方向。
结果如下表所示:
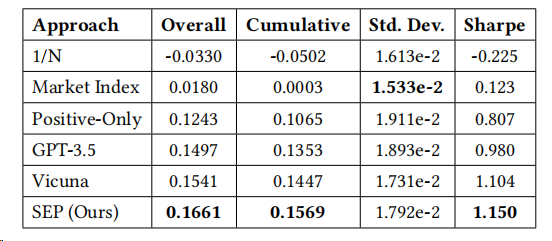
SEP模型在多个投资组合性能指标上表现出色,包括总收益、累计收益、收益的标准差和年化夏普比率。这些结果表明,SEP框架能够有效地将股票预测任务中学到的信息量化权衡,用于投资组合构建任务。
结论
本文研究了利用自反思大型语言模型进行股市预测的可解释性任务,并提出了SEP框架。该框架结合自反思代理和近端策略优化(PPO)技术,让LLM自主学习生成可解释的股票预测。实验结果显示,SEP框架在预测准确性和生成解释的质量方面均优于传统方法和LLM。在投资组合构建任务上的测试也证明了其泛化能力。
未来研究可关注减少SEP框架的累积误差、利用更多数据源提高预测质量,并改进股票解释的评估指标。