前面整合遇到的一些问题有的记录在下面了,有的当时忘了记录下来,希望下面的能帮到你们
1:Linux安装ES
下载安装:
参考文章:连接1
连接2
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.12.2-linux-x86_64.tar.gz
解压:tar -zxvf elasticsearch-8.12.2-linux-x86_64.tar.gz
这里注意,在bin目录下启动报错,因为不能通过root账户启动,需要新建账户
创建新用户给ES使用:adduser els
修改密码:echo 123456 | passwd --stdin els 或者:sudo passwd newpassword
然后将解压的es 目录赋予新创建的用户
sudo chown -R els:els /home/cdszwy/elasticsearch/elasticsearch-8.12.2
切换到新创建用户
su - els
然后进入解压目录的/bin 执行 ./elasticsearch -d 运行es
然后 执行curl http://127.0.0.1:9200显示
先要在防火墙打开该端口才能访问
安装遇到的问题:
- Password: su: Permission denied
添加用户修改密码后,切换到新用户环境,再切换到root环境提示异常:Password: su: Permission denied
使用su命令时输入密码后提示权限限制,确认密码是正确的
即:
su root
Password:
su: permission denied
解决:
1.改变用户分组,将用户添加进wheel分组
#语法
#usermod [-G] [GroupName] [UserName]
usermod -G wheel username
2.修改/etc/pam.d/su
注释行:auth required pam_wheel.so use_uid
3:查看当前用户分组:
#语法
#id username
id els
#执行结果如下
uid=1001(els) gid=1001(els) groups=1001(els),10(wheel)
- vm.max_map_count [65530] is too low
解决vm.max_map_count [65530] is too low问题
编辑 /etc/sysctl.conf 文件来永久更改该值。在文件的末尾添加下面一行并保存:vm.max_map_count=262144
然后可以通过运行以下命令重新加载配置文件:sudo sysctl -p
修改ES的配置:
修改配置:elasticsearch.yml
绑定到0.0.0.0,允许任何ip来访问
network.host: 0.0.0.0
#浏览器可直接访问
xpack.security.http.ssl:
enabled: false
末尾添加:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
修改配置:jvm.options
-Xms1g
-Xmx1g
设置用户名密码:
在bin目录下执行:./elasticsearch-reset-password -u elskib -i
添加新用户给kibana使用
添加用户:./elasticsearch-users useradd elskib
分配绝俗: ./elasticsearch-users roles -a superuser elskib
账号:elskib
密码:qwe123
在启动ES
使用命令查看进程:
查看是否成功:ps -ef|grep elastic
IK分词器安装:https://github.com/infinilabs/analysis-ik/releases
下载再执行
在bin目录下执行命令:./elasticsearch-plugin install file:///home/cdszwy/elasticsearch/elasticsearch-analysis-ik-8.12.2.zip
2.springboot 整合ES
这里有一个区别:下面会有两种快速接口调用ES,分别是:使用RestHighLevelClient,使用ElasticsearchClient,先讲使用RestHighLevelClient
使用RestHighLevelClient
- 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
配置ES基础信息:
es:
ip: 192.34.21.129
port: 9200
username: elskib
password: qwe123
添加Java配置:
@Configuration
public class ElasticSearchConfig {
@Value("${es.ip}")
private String esIp;
@Value("${es.port}")
private Integer port;
@Value("${es.username}")
private String username;
@Value("${es.password}")
private String password;
/**
* 注册 rest高级客户端
* @date 2024/3/5 16:01
**/
@Bean
public RestHighLevelClient restHighLevelClient() {
// 创建CredentialsProvider,并设置用户名密码
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(username,password));
// 创建RestHighLevelClient实例,并设置CredentialsProvider
return new RestHighLevelClient(
RestClient.builder(new HttpHost(esIp, port, "http"))
.setHttpClientConfigCallback(httpAsyncClientBuilder ->
httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
)
);
}
添加方法的实现类:
import cn.test.vo.DocumentInfoPageVo;
import cn.test.vo.DocumentInfoVo;
import cn.hutool.json.JSONUtil;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.core.TimeValue;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.Scroll;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.ScoreSortBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.search.suggest.SuggestBuilder;
import org.elasticsearch.search.suggest.completion.CompletionSuggestion;
import org.elasticsearch.search.suggest.completion.CompletionSuggestionBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* Description: 多条件操作文档
* @version 1.0
* @ClassName RestHighLevelServiceImpl
* @date 2024/3/7 11:12
**/
@Service
public class RestHighLevelServiceImpl {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 判断索引是否存在
*/
public Boolean indexExists(String indexName) throws Exception {
GetIndexRequest request = new GetIndexRequest(indexName);
return restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
}
/**
* 创建 ES 索引
*/
public CreateIndexResponse createIndex(String indexName, Settings.Builder settings, XContentBuilder mappings) throws Exception {
//将 Settings 和 Mappings 封装到一个Request 对象中
CreateIndexRequest request = new CreateIndexRequest(indexName)
.settings(settings)
.mapping(mappings);
//通过 client 对象去连接ES并执行创建索引
return restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 批量创建 ES 文档
*/
public IndexResponse createDoc(String indexName, String id, String json) throws Exception {
//准备一个Request对象
IndexRequest request = new IndexRequest(indexName);
//手动指定ID
request.id(id);
request.source(json, XContentType.JSON);
//request.opType(DocWriteRequest.OpType.INDEX); 默认使用 OpType.INDEX,如果 id 重复,会进行 覆盖更新, resp.getResult().toString() 返回 UPDATE
//request.opType(DocWriteRequest.OpType.CREATE); 如果ID重复,会报异常 => document already exists
//通过 Client 对象执行添加
return restHighLevelClient.index(request, RequestOptions.DEFAULT);
}
/**
* 批量创建 ES 文档
*
* @param jsonMap Key = id,Value = json
*/
public BulkResponse batchCreateDoc(String indexName, Map<String, String> jsonMap) throws Exception {
//准备一个Request对象
BulkRequest bulkRequest = new BulkRequest();
for (String id : jsonMap.keySet()) {
IndexRequest request = new IndexRequest(indexName)
//手动指定ID
.id(id)
.source(jsonMap.get(id), XContentType.JSON);
bulkRequest.add(request);
}
//通过 Client 对象执行添加
return restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
}
/**
* 自动补全 根据用户的输入联想到可能的词或者短语
*
* @param indexName 索引名称
* @param field 搜索条件字段
* @param keywords 搜索关键字
* @param size 匹配数量
* @return
* @throws Exception
*/
public List<String> suggest(String indexName, String field, String keywords, int size) throws Exception {
//定义返回
List<String> suggestList = new ArrayList<>();
//构建查询请求
SearchRequest searchRequest = new SearchRequest(indexName);
//通过查询构建器定义评分排序
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));
//构造搜索建议语句,搜索条件字段
CompletionSuggestionBuilder completionSuggestionBuilder = new CompletionSuggestionBuilder(field);
//搜索关键字
completionSuggestionBuilder.prefix(keywords);
//去除重复
completionSuggestionBuilder.skipDuplicates(true);
//匹配数量
completionSuggestionBuilder.size(size);
searchSourceBuilder.suggest(new SuggestBuilder().addSuggestion("article-suggest", completionSuggestionBuilder));
//article-suggest为返回的字段,所有返回将在article-suggest里面,可写死,sort按照评分排序
searchRequest.source(searchSourceBuilder);
//定义查找响应
SearchResponse suggestResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//定义完成建议对象
CompletionSuggestion completionSuggestion = suggestResponse.getSuggest().getSuggestion("article-suggest");
List<CompletionSuggestion.Entry.Option> optionsList = completionSuggestion.getEntries().get(0).getOptions();
//从optionsList取出结果
if (!CollectionUtils.isEmpty(optionsList)) {
optionsList.forEach(item -> suggestList.add(item.getText().toString()));
}
return suggestList;
}
/**
* 前缀查询,可以通过一个关键字去指定一个Field的前缀,从而查询到指定的文档
*/
public SearchResponse prefixQuery(String indexName, String searchField, String searchKeyword) throws Exception {
//创建Request对象
SearchRequest request = new SearchRequest(indexName);
//XX开头的关键词查询
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.prefixQuery(searchField, searchKeyword));
request.source(builder);
//执行查询
return restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
/**
* 通过 QueryBuilder 构建多字段匹配如:QueryBuilders.multiMatchQuery("人工智能","title","content")
* multi_match => https://www.cnblogs.com/vipsoft/p/17164544.html
*/
public SearchResponse search(String indexName, QueryBuilder query, int currPage, int pageSize) throws Exception {
SearchRequest request = new SearchRequest(indexName);
SearchSourceBuilder builder = new SearchSourceBuilder();
int start = (currPage - 1) * pageSize;
builder.from(start);
builder.size(pageSize);
builder.query(query);
request.source(builder);
return restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
/**
* Description:根据条件查询文档信息
* 分页问题:《不能实现跳转分页》
* @date 2024/3/7 11:19
* @param indexName 索引名称
* @param queryBuilder 查询条件
* @param pageSize 每页数量
* @param page 页码
* @param scrollId 下一页的请求ID
* @return List<DocumentInfo> 返回所有文档信息
**/
// @Override
public Object getDocPageList(String indexName, QueryBuilder queryBuilder, Integer pageSize, Integer page, String scrollId) throws IOException {
List<Object> list = new ArrayList<>();
//指定scroll信息,2分钟过期
//失效时间为2min
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(2));
Long totalCount = null;
//首次查询scrollId为空
if(StringUtils.isEmpty(scrollId)){
//指定搜索索引
SearchRequest searchRequest = new SearchRequest(indexName);
//封存快照
searchRequest.scroll(scroll);
//指定条件对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//指定查询条件
sourceBuilder.size(pageSize);
sourceBuilder.sort("reportDate", SortOrder.DESC);
sourceBuilder.query(queryBuilder);
searchRequest.source(sourceBuilder);
//参数 1:搜索请求对象 参数2: 请求配置对象 返回值:查询结果对象
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//计算总数量
totalCount = searchResponse.getHits().getTotalHits().value;
// //得到总页数
// page = (int) Math.ceil((float) totalCount / 2);
//多次遍历分页,获取结果
scrollId = searchResponse.getScrollId();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("id: "+hit.getId()+" source: "+hit.getSourceAsString());
list.add(JSONUtil.toBean(JSONUtil.parseObj(hit.getSourceAsString()), Object.class));
}
} else {
System.out.println("第二次查询");
//TODO 只能连续分页查询,不能进行分页跳转查询
//获取到该id
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(scroll);
SearchResponse response = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
//打印数据
SearchHits searchHits = response.getHits();
scrollId = response.getScrollId();
for (SearchHit hit : searchHits) {
System.out.println("id: "+hit.getId()+" source: "+hit.getSourceAsString());
list.add(JSONUtil.toBean(JSONUtil.parseObj(hit.getSourceAsString()), Object.class));
}
}
Object vo = new Object();
vo.setTotal(totalCount);
// vo.setScrollId(scrollId);
vo.setList(list);
return vo;
}
}
这里的Object可以替换为你的实体类,想要解析的对象
使用ElasticsearchClient
- 添加依赖:
<!-- Elasticsearch8.12版本(Java API Client),使用ElasticsearchClient-->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.12.2</version>
<exclusions>
<exclusion>
<artifactId>jakarta.json-api</artifactId>
<groupId>jakarta.json</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.12.2</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.1.1</version>
</dependency>
- 添加配置
package cn.test.configs;
import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
/**
* Description: es配置累
* @version 1.0
* @ClassName ElasticSearchConfig
* @date 2024/3/5 15:58
**/
@Configuration
public class ElasticSearchConfig {
@Value("${es.ip}")
private String esIp;
@Value("${es.port}")
private Integer port;
@Value("${es.username}")
private String username;
@Value("${es.password}")
private String password;
@Bean
public ElasticsearchClient esRestClientWithCred(){
final String scheme = "http";
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
// 配置连接ES的用户名和密码,如果没有用户名和密码可以不加这一行
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(esIp, port, scheme))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) {
return httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
RestClient restClient = restClientBuilder.build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
/**
* 异步方式
*
* @return
*/
@Bean
public ElasticsearchAsyncClient elasticsearchAsyncClient() {
HttpHost[] httpHosts = toHttpHost();
RestClient restClient = RestClient.builder(httpHosts).build();
RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
return new ElasticsearchAsyncClient(transport);
}
/**
* 解析配置的字符串hosts,转为HttpHost对象数组
*
* @return
*/
private HttpHost[] toHttpHost() {
if (!StringUtils.hasLength(esIp)) {
throw new RuntimeException("invalid elasticsearch configuration. elasticsearch.hosts不能为空!");
}
// 多个IP逗号隔开
String[] hostArray = esIp.split(",");
HttpHost[] httpHosts = new HttpHost[hostArray.length];
HttpHost httpHost;
for (int i = 0; i < hostArray.length; i++) {
String[] strings = hostArray[i].split(":");
httpHost = new HttpHost(strings[0], port, "http");
httpHosts[i] = httpHost;
}
return httpHosts;
}
}
- 实现类
索引操作
import cn.test.service.ElasticSearchIndexService;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch._types.mapping.Property;
import co.elastic.clients.elasticsearch._types.mapping.TypeMapping;
import co.elastic.clients.elasticsearch.indices.*;
import co.elastic.clients.util.ObjectBuilder;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.HashMap;
import java.util.function.Function;
/**
* Description: ES索引操作
* @version 1.0
* @ClassName ElasticSearchIndexServiceImpl
* @date 2024/3/6 14:05
**/
@Service
@Slf4j
public class ElasticSearchIndexServiceImpl implements ElasticSearchIndexService {
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* Description:根据索引名称创建索引
* @date 2024/3/6 14:09
* @param name 索引名称
**/
@Override
public void createIndex(String name) throws IOException {
//ApplicationContext applicationContext;
CreateIndexResponse response = elasticsearchClient.indices().create(c -> c.index(name));
log.info("createIndex方法,acknowledged={}", response.acknowledged());
}
/**
* Description:索引创建
* @date 2024/3/6 14:15
* @param name 索引名称
* @param settingFn 索引属性设置
* @param mappingFn mapping属性设置
**/
@Override
public void createIndex(String name,
Function<IndexSettings.Builder, ObjectBuilder<IndexSettings>> settingFn,
Function<TypeMapping.Builder, ObjectBuilder<TypeMapping>> mappingFn) throws IOException {
CreateIndexResponse response = elasticsearchClient
.indices()
.create(c -> c
.index(name)
.settings(settingFn)
.mappings(mappingFn)
);
log.info("createIndex方法,acknowledged={}", response.acknowledged());
}
/**
* Description:根据索引名称删除索引
* @date 2024/3/6 14:10
* @param name 索引名称
**/
@Override
public void deleteIndex(String name) throws IOException {
DeleteIndexResponse response = elasticsearchClient.indices().delete(c -> c.index(name));
log.info("deleteIndex方法,acknowledged={}", response.acknowledged());
}
/**
* Description:根据索引名称设置mapping
* @date 2024/3/6 14:12
* @param name 索引名称
* @param propertyMap 属性
**/
@Override
public void updateIndexProperty(String name, HashMap<String, Property> propertyMap) throws IOException {
PutMappingResponse response = elasticsearchClient.indices()
.putMapping(typeMappingBuilder ->
typeMappingBuilder
.index(name)
.properties(propertyMap)
);
log.info("updateIndexMapping方法,acknowledged={}", response.acknowledged());
}
/**
* Description:获取所有索引信息
* @date 2024/3/6 14:13
**/
@Override
public GetIndexResponse getIndexList() throws IOException {
//使用 * 或者 _all都可以
GetIndexResponse response = elasticsearchClient.indices().get(builder -> builder.index("_all"));
log.info("getIndexList方法,response.result()={}", response.result().toString());
return response;
}
/**
* Description:根据索引名称获取所有详情
* @date 2024/3/6 14:13
* @param name 索引名称
* @return GetIndexResponse 返回信息
**/
@Override
public GetIndexResponse getIndexDetail(String name) throws IOException {
GetIndexResponse response = elasticsearchClient.indices().get(builder -> builder.index(name));
log.info("getIndexDetail方法,response.result()={}", response.result().toString());
return response;
}
/**
* Description:根据索引名称判断索引是否存在
* @date 2024/3/6 14:13
* @param name 索引名称
* @return boolean 返回存在的布尔值
**/
@Override
public boolean indexExists(String name) throws IOException {
return elasticsearchClient.indices().exists(b -> b.index(name)).value();
}
}
文档类
package cn.goktech.workbench.service.impl;
import cn.test.configs.PublicConfig;
import cn.test.entity.docmanagement.po.DocumentInfo;
import cn.test.entity.docmanagement.vo.DocumentInfoPageVo;
import cn.test.entity.docmanagement.vo.DocumentInfoVo;
import cn.test.service.ElasticSearchDocService;
import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch._types.SortOrder;
import co.elastic.clients.elasticsearch._types.query_dsl.Query;
import co.elastic.clients.elasticsearch.core.*;
import co.elastic.clients.elasticsearch.core.search.Hit;
import com.fasterxml.jackson.databind.node.ObjectNode;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.function.BiConsumer;
/**
* Description: es操作文档的接口
* @version 1.0
* @ClassName ElasticSearchDocServiceImpl
* @date 2024/3/6 17:44
**/
@Service
@Slf4j
public class ElasticSearchDocServiceImpl implements ElasticSearchDocService {
@Autowired
private ElasticsearchClient elasticsearchClient;
@Autowired
private ElasticsearchAsyncClient elasticsearchAsyncClient;
/**
* 新增一个文档并返回ID
* @param indexName 索引名称
* @param document 文档对象
* @return IndexResponse
* @throws Exception 抛出操作异常
*/
@Override
public String createByFluentDsl(String indexName, DocumentInfo document) throws Exception {
return elasticsearchClient.index(idx -> idx
.index(indexName)
.id(document.getDocId())
.document(document)).id();
}
/**
* 新增一个文档
* @param indexName 索引名称
* @param document 文档对象 需要的字段自己创建一个实体类
* @return IndexResponse
* @throws Exception 抛出操作异常
*/
@Override
public String createByBuilderPattern(String indexName, DocumentInfo document) throws Exception {
IndexRequest.Builder<Object> indexReqBuilder = new IndexRequest.Builder<>();
indexReqBuilder.index(indexName);
indexReqBuilder.id(document.getDocId());
indexReqBuilder.document(document);
return elasticsearchClient.index(indexReqBuilder.build()).id();
}
/**
* 用JSON字符串创建文档
* @param indexName 索引名称
* @param idxId 索引id
* @param jsonContent json字符串
* @return IndexResponse
* @throws Exception 抛出操作异常
*/
@Override
public String createByJson(String indexName, String idxId, String jsonContent) throws Exception {
return elasticsearchClient.index(i -> i
.index(indexName)
.id(idxId)
.withJson(new StringReader(jsonContent))).id();
}
/**
* 异步新增文档
* @param indexName 索引名称
* @param idxId 索引id
* @param document 文档内容 需要的字段自己创建一个实体类
* @param action 属性
*/
@Override
public void createAsync(String indexName, String idxId, DocumentInfo document, BiConsumer<IndexResponse, Throwable> action) {
elasticsearchAsyncClient.index(idx -> idx
.index(indexName)
.id(idxId)
.document(document)
).whenComplete(action);
}
/**
* 批量增加文档
* @param indexName 索引名称
* @param documents 要增加的对象集合 需要的字段自己创建一个实体类
* @return 批量操作的结果
* @throws Exception 抛出操作异常
*/
@Override
public BulkResponse bulkCreate(String indexName, List<DocumentInfo> documents) throws Exception {
BulkRequest.Builder br = new BulkRequest.Builder();
//可以将 Object定义为一个文档基类。比如 ESDocument类
// 将每一个product对象都放入builder中
documents.stream().forEach(esDocument -> br
.operations(op -> op
.index(idx -> idx
.index(indexName)
.id(esDocument.getDocId())
.document(esDocument))));
return elasticsearchClient.bulk(br.build());
}
/**
* 根据文档id查找文档
* @param indexName 索引名称
* @param docId 文档id
* @return Object类型的查找结果
* @throws IOException 抛出操作异常
*/
@Override
public Object getById(String indexName, String docId) throws IOException {
GetResponse<Object> response = elasticsearchClient.get(g -> g
.index(indexName)
.id(docId),
Object.class);
return response.found() ? response.source() : null;
}
/**
* 根据文档id查找文档,返回类型是ObjectNode
* @param indexName 索引名称
* @param docId 文档id
* @return ObjectNode类型的查找结果
* @throws IOException 抛出操作异常
*/
@Override
public ObjectNode getObjectNodeById(String indexName, String docId) throws IOException {
GetResponse<ObjectNode> response = elasticsearchClient.get(g -> g
.index(indexName)
.id(docId),
ObjectNode.class);
return response.found() ? response.source() : null;
}
/**
* 根据文档id删除文档
* @param indexName 索引名称
* @param docId 文档id
* @return Object类型的查找结果
* @throws IOException 抛出操作异常
*/
@Override
public Boolean deleteById(String indexName, String docId) throws IOException {
DeleteResponse delete = elasticsearchClient.delete(d -> d
.index(indexName)
.id(docId));
return delete.forcedRefresh();
}
/**
* 批量删除文档
* @param indexName 索引名称
* @param docIds 要删除的文档id集合
* @return BulkResponse
* @throws Exception 抛出操作异常
*/
@Override
public BulkResponse bulkDeleteByIds(String indexName, List<String> docIds) throws Exception {
BulkRequest.Builder br = new BulkRequest.Builder();
// 将每一个对象都放入builder中
docIds.stream().forEach(id -> br
.operations(op -> op
.delete(d -> d
.index(indexName)
.id(id))));
return elasticsearchClient.bulk(br.build());
}
/**
* Description:修改文档信息
* @date 2024/3/7 10:09
* @param indexName 索引名称
* @param documentInfo 文档信息 需要的字段自己创建一个实体类
**/
@Override
public void updateDocById(String indexName, DocumentInfo documentInfo) throws IOException {
final UpdateResponse<DocumentInfo> response = elasticsearchClient.update(builder -> builder
.index(indexName)
.id(documentInfo.getDocId())
.doc(documentInfo), DocumentInfo.class);
System.err.println(response.shards().successful());
}
public void getDocPageList(String indexName, Integer pageNum, Integer pageSize) throws IOException {
/*
* 分页查询,查询所有
* sort 排序
*/
final SearchResponse<DocumentInfo> response = elasticsearchClient.search(builder ->
builder.index(indexName)
.query(q->q.matchAll(v->v))
.size(pageSize)
.from(pageNum)
.sort(builder1 -> builder1.field(f->f.field("reportDate").order(SortOrder.Desc)))
, DocumentInfo.class);
List<Hit<DocumentInfo>> hitList = response.hits().hits();
System.err.println(hitList);
}
public void getDocPageListBySearchWords(String indexName, Integer pageNum, Integer pageSize, String searchWords) throws IOException {
/*
* 分页查询,可根据输入文字搜索
* sort 排序
*/
final SearchResponse<DocumentInfoVo> response = elasticsearchClient.search(builder ->
builder.index(indexName)
.query(q->q.multiMatch(v->v.query(searchWords).fields("docTitle", "docContent")))
.size(pageSize)
.from(pageNum)
.sort(builder1 -> builder1.field(f->f.field("reportDate").order(SortOrder.Desc)))
, DocumentInfoVo.class);
System.err.println(response);
}
public void getDocPageListByTitle(String indexName, Integer pageNum, Integer pageSize, String type) throws IOException {
/*
* 分页查询,可根据类型搜索
* query 查询条件
* sort 排序
*/
final SearchResponse<DocumentInfoVo> response = elasticsearchClient.search(builder ->
builder.index(indexName)
.query(q->q.term(t ->t.field("docType.keyword").value(type)))
.size(pageSize)
.from(pageNum)
.sort(builder1 -> builder1.field(f->f.field("reportDate").order(SortOrder.Desc)))
, DocumentInfoVo.class);
System.err.println(response);
List<Hit<DocumentInfoVo>> hitList = response.hits().hits();
}
/**
* Description:TODOmethod
* @date 2024/3/8 10:26
* @param indexName 索引名称
* @param pageNum 页码
* @param pageSize 每页数量
* @param queryList 查询条件query
* @return DocumentInfoPageVo 返回分页数据
* @throws IOException 抛出操作异常
**/
@Override
public DocumentInfoPageVo getDocPageList(String indexName, Integer pageNum, Integer pageSize, List<Query> queryList) throws IOException {
List<DocumentInfoVo> list = new ArrayList<>();
SearchResponse<DocumentInfoVo> response = elasticsearchClient.search(s -> s
.index(indexName)
.query(q -> q.bool(b -> b.must(queryList)))
//高亮
.highlight(h -> h
.preTags("<span>")
.postTags("</span>")
.requireFieldMatch(false)
.fields("docTitle", hf -> hf)
.fields("docContent", hf -> hf))
//排序
.sort(sort -> sort.field(f -> f.field("reportDate").order(SortOrder.Desc)))
// //查询字段过滤
// .source(sc -> sc.filter(f -> f.includes(sources)))
//分页
.from((pageNum - 1) * pageSize)
.size(pageSize),
DocumentInfoVo.class
);
DocumentInfoPageVo vo = new DocumentInfoPageVo();
vo.setTotal(response.hits().total() != null ? response.hits().total().value() : PublicConfig.ZERO);
System.err.println(response);
List<Hit<DocumentInfoVo>> hitList = response.hits().hits();
for (Hit<DocumentInfoVo> hit : hitList) {
DocumentInfoVo infoVo = hit.source();
if(Objects.nonNull(infoVo)){
Map<String, List<String>> map = hit.highlight();
//设置返回高亮的字段进行原字段替换
infoVo.setDocTitle(CollectionUtils.isEmpty(map.get("docTitle")) ? infoVo.getDocTitle() : map.get("docTitle").get(PublicConfig.ZERO));
infoVo.setDocContent(CollectionUtils.isEmpty(map.get("docContent")) ? infoVo.getDocContent() : map.get("docContent").get(PublicConfig.ZERO));
list.add(infoVo);
}
}
vo.setList(list);
return vo;
}
}
这里我想在分页多条件查询,使用方式:
try {
//sources 为你过滤的字段,也就是你想要查询出来的字段,配置了那些字段才会返回那些字段
// List<String> sources = new ArrayList<>();
//queryList 为你想要的查询条件封装,每种查询方式的条件query不一样
List<Query> queryList = new ArrayList<>();
//根据文档类型筛选查询
if(StringUtils.isNotEmpty(dto.getTypeName())){
Query query = TermQuery.of(m -> m.field("docType.keyword").value(dto.getTypeName()))._toQuery();
queryList.add(query);
}
//根据输入内容查询文档标签和文档内容
if(StringUtils.isNotEmpty(dto.getSearchWord())){
Query query = MultiMatchQuery.of(v -> v.query(dto.getSearchWord()).fields("docTitle", "docContent"))._toQuery();
queryList.add(query);
}
//根据时间范围查询
if(StringUtils.isNotEmpty(dto.getStartDate()) && StringUtils.isNotEmpty(dto.getEndDate())){
long startTime = DateUtil.parse(dto.getStartDate()).getTime();
Query startQuery = RangeQuery.of(r -> r.field("reportDate")
.gte(JsonData.of(startTime))
)._toQuery();
queryList.add(startQuery);
long endTime = DateUtil.parse(dto.getEndDate()).getTime();
Query endQuery = RangeQuery.of(r -> r.field("reportDate")
.lte(JsonData.of(endTime))
)._toQuery();
queryList.add(endQuery);
}
DocumentInfoPageVo pageVo = elasticSearchDocService.getDocPageList(DOC_INDEX, dto.getPage(), dto.getLimit(), queryList);
return new PageResult<>(pageVo.getList(), pageVo.getTotal());
上面是我的分页查询,这里docType.keyword是为了匹配查询,如mysql中的 name=张三,我这里的docType在ES文档中的type就是keyword,MultiMatchQuery这个是我多字段分词查询,后面是范围查询。
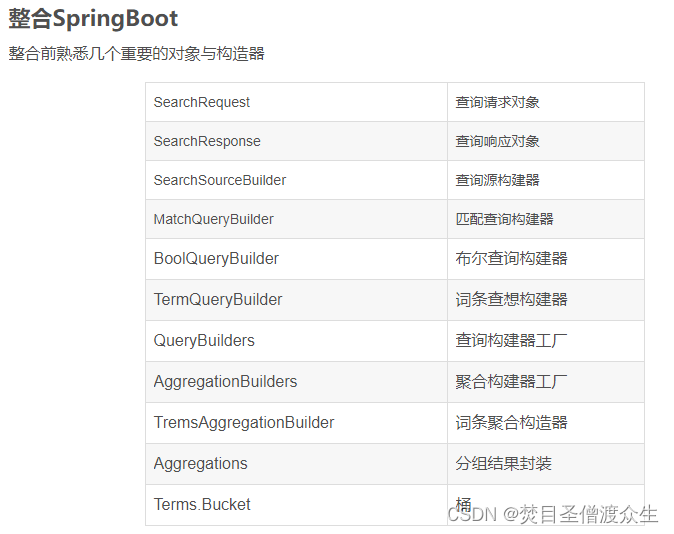
上面这块可以看文章:这里讲了很多知识
文章查询并高亮显示可查看此文章
Elasticsearch Java API
ES的term查询无返回结果
学习和整合时推荐
ElasticSearch 所有知识总结
ElasticSearch(提高篇)
中文分词器(IK Analyzer)及自定义词库
以上简洁整理只是记录下,便于后期使用,希望对大家有所帮助